大语言模型,一个巨大的矩阵
目录
一、向量和矩阵——大模型的基座
1.1 向量:万事万物的“数字密码”
1.2 向量的维度
1.3 矩阵:操控向量的“精密模具”
1.4 大模型:矩阵与向量的融合
二、数据的“消化”——从字符到数字矩阵
2.1 Tokenization:文本到Token序列的过程
2.2 Embeddings:TokenID到语义向量的过程
2.3 位置向量:让词向量变的有语义
2.4 Transformer模型的具体处理
三、热点名词科普
3.1 大模型幻觉
3.2 大模型量化
3.3 大模型蒸馏
3.4 大模型微调
四、参考内容
一、向量和矩阵——大模型的基座
1.1 向量:万事万物的“数字密码”
定义:向量表示形式类似于数组,但是值只能为数字,如:[1,2,3,4]。向量用来通过一组特征来描述一个事物。
例子:婴儿第一次看到苹果,是怎么记住这种东西就是苹果呢?
婴儿会从不同维度描述苹果的特征(如:纹理、颜色、形状、大小等) 假设大脑的工作机制,是将不同维度的特征用数字表达并存储,这些维度的特征值就是向量了。



婴儿看到新的苹果,大脑也会将新苹果的特征提取为向量。大苹果、小苹果,从颜色、大小、形状、纹理等等维度是很相似的,显然,把这些苹果抽象成多个向量,这些向量在向量空间中的距离肯定是很近的。
这就是信息向量化,在机器学习中,一张图片的所有像素值、一段文本的数值化表示,都可以被拉直成一个极高维的向量。这时,向量就是承载信息的数据结构。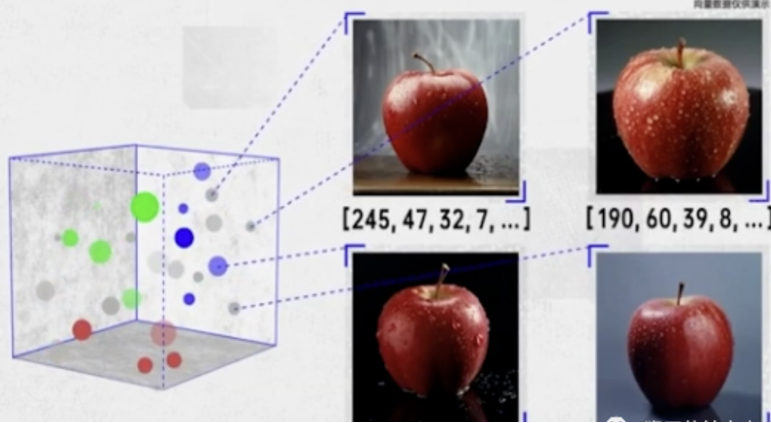
1.2 向量的维度
定义:描述一个事物所需的最基本特征的个数。
例子: 想象我们用三个数字(一个三维向量)来大致描述一个水果:
[甜度, 酸度, 硬度]
那么,
“苹果”可能被表示为 [0.7, 0.3, 0.6] 而
“柠檬”可能被表示为 [0.2, 0.8, 0.4]
在大语言模型中,文字(单词、句子)会被转换成非常高维的向量(通常是几百到几千维),这个过程称为向量化或嵌入,GPT-3中的向量维度高达12288维。模型【矩阵】通过在这些高维空间中计算向量之间的“距离”或“夹角”来判断词的语义相似度。
| 维度 | 直观比喻 | 数学表示 | 可能含义(在大语言模型中) |
|---|---|---|---|
| 1维 | 一条数轴上的一个点 |
| 单一特征,如“情感极值” |
| 2维 | 平面地图上的一个点 (x, y) |
| 两个特征,如“情感倾向+主题” |
| 3维 | 三维空间中的一个点 (x, y, z) |
| 三个特征,如“情感、主题、文体” |
| 高维(如768维) | 一个拥有768个维度的“超空间”中的一个点 |
| 综合语义信息,如单词/句子的深层含义 |
1.3 矩阵:操控向量的“精密模具”
定义:矩阵可以被视为一个操作指令集或一个函数。它对一个或多个向量进行“加工”,从而改变它们,或者从它们中提取新的信息。
向量是对象静态的表示,向量是名词性的,是信息的静态载体。它回答了“是什么”的问题。 矩阵是动词性的,是动态的变换。它回答了“做什么”以及“怎么做”的问题。
例子:有点P(Xa,Ya),当坐标由 x –> y 旋转 θ 度后,求该点在新坐标轴的坐标是多少?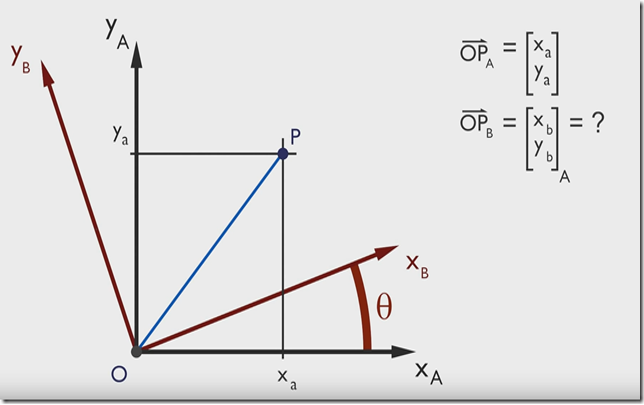
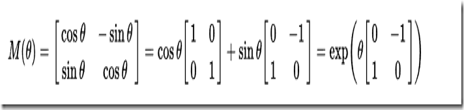
通过数学计算可以得到旋转矩阵M,任何一个二维的向量点乘这个旋转矩阵M都可以得到一个旋转后的向量。
1.4 大模型:矩阵与向量的融合
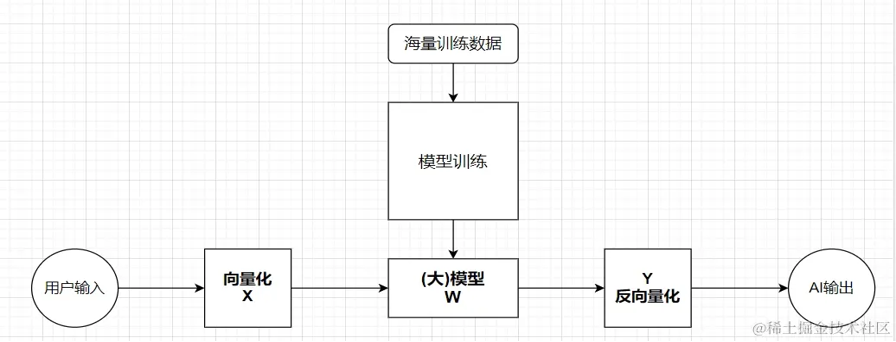
1)模型训练生成阶段:通过将海量数据输入到Transformer架构中进行训练计算,最终输出一个矩阵W,这就是训练的结果 —— 大模型。这个矩阵W中的参数量是以B(十亿)为单位的,比如DeepSeek-R1-671B,说明了这个矩阵的参数有惊人的6710亿个,可以想像这个函数【矩阵】的能力是很强的。
2)模型应用进化阶段:将用户输入的信息转化为向量X,模型W矩阵对用户的输入向量X进行各种计算,得到一个向量Y,再将Y反向量化为用户能看懂的信息(比如:文本)。在实际的应用过程中,模型会随着用户的使用交流,得到进化,本质上是矩阵W的某些数值会发生调整。
二、数据的“消化”——从字符到数字矩阵
2.1 Tokenization:文本到Token序列的过程
Token是语言处理的基本单元,类似于构成文本的"原子"。 它可以是: 一个字符(如 "a") 一个子词(如 "ing") 一个完整单词(如 "apple") 一个短语或符号
什么是Tokenization? Tokenization(分词)是将文本字符串转换为Token序列的过程: 文本 → Token序列 Token → 整数ID
特点:可逆转换过程 模型输入预处理
例子:
输入文本:Hello, world! This is a tokenization demo.

2.2 Embeddings:TokenID到语义向量的过程
Tokenization: 文本预处理步骤,将原始文本转换为模型可处理的Token序列和ID。 输入:原始文本字符串 输出:Token ID序列 特点:离散、可逆、无语义
Embeddings: 模型内部处理,将Token ID转换为包含语义信息的高维向量。 输入:Token ID 输出:语义向量 特点:连续、语义化、可训练

2.3 位置向量:让词向量变的有语义
例子:
“苹果手机质量不错,就是价格有点贵。”
“这个苹果很好吃,非常脆。”
“菠萝质量也还行,但是不如苹果支持的APP多。”
在上面的句子中,我们通过上下文可以推断出第一个“苹果"指的是苹果手机,第二个“苹果"指的是水果苹果,而第三个“菠萝"指的应该也是一个手机。
事实上,我们可以使用同样的方式训练词向量,让这些词向量具备表示语义信息的能力。
2.4 Transformer模型的具体处理
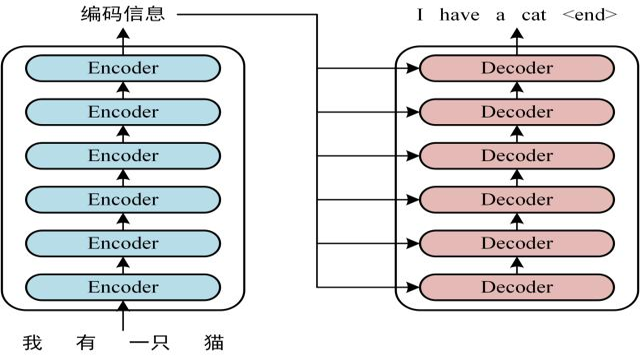
例子: 我有一只小猫 ----> I hava a cat , 在这个过程中,大模型矩阵是如何具体工作的。
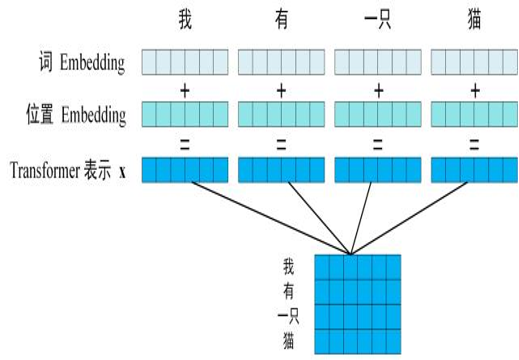
1)如下所示,句子先通过分词得到5个token的序列,token序列再通过嵌入得到词信息的向量和词在句子中的位置向量,通过向量相加得到模型需要的每个token的向量,这五个token的向量组合成词向量矩阵。
2)词向量矩阵通过大模型矩阵W即编码器和解码器,来预测下一个token可能的概率(这里面我们通过温度等参数可以稍微控制模型选择的输出)。[我有一只小猫I] 在根据这个矩阵接着预测下一个token直至预测到结束字符。
3)取模型预测的词向量矩阵,可逆回Token ID 和对应的字符。
三、热点名词科普
3.1 大模型幻觉
定义:大模型会生成看似合理但实际错误的信息。
原因:因为我们已经知道了大模型是预测类的矩阵W,输入了内容,必须会输出内容。因此,当问题不在大模型的预训练集合中,大模型预测的内容就是错误的。 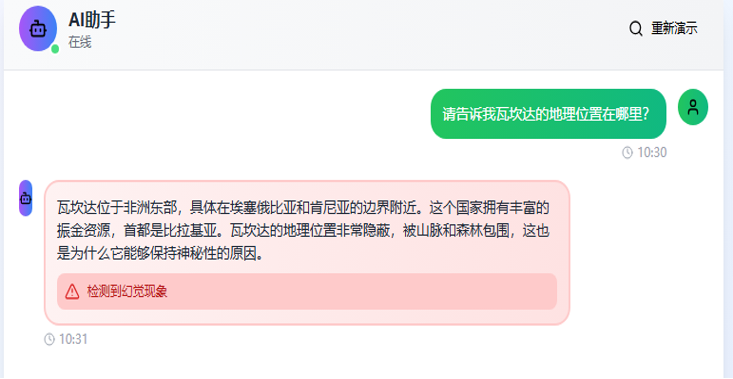
虚构了真实地理位置 编造了具体细节 提供了不存在的事实信息
3.2 大模型量化
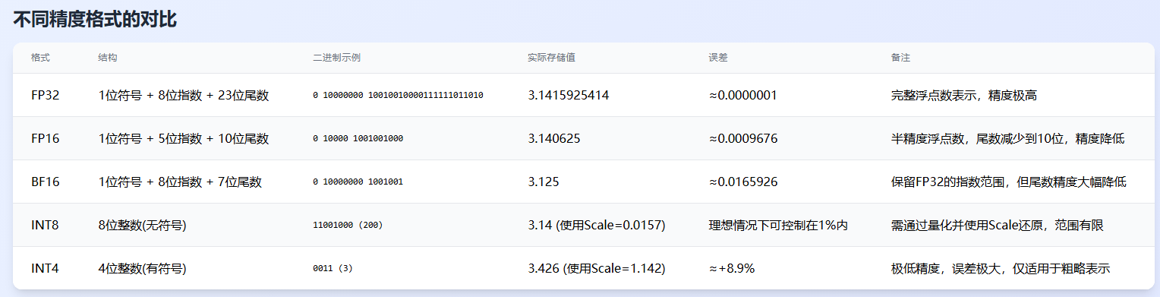
定义:对大模型矩阵里面的参数的精度减少,以便达到模型瘦身和推理速度加快的效果。
原因:我们已经知道了大模型的核心是一个大矩阵,这个矩阵的参数在预训练后就是固定不变的了。每个参数都是FP16的精度,这样存储就会大,运算的时候也会比较慢。对大部分参数的进度进行减小就可以解决上面的问题。
例子:计算单位圆的面积大小 对于参数 pi = 3.14 或者 pi = 3.1415926 对单位圆的结果误差不大。但是计算的难度和参数的存储大小都得到了大幅度的优化。
模型量化的过程就是类似,参数pi从3.1415926变成3.14的过程。
3.3 大模型蒸馏
定义:模型蒸馏是一种知识传递技术,让一个庞大的、能力强的“教师模型”去教导一个小的“学生模型”,实现知识从大模型向小模型的转移。
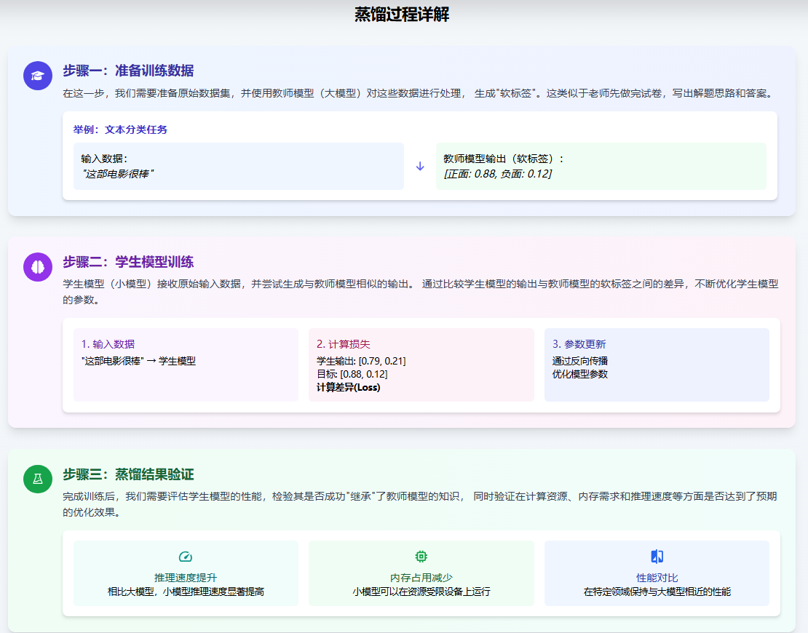
3.4 大模型微调
定义:对大模型矩阵里面的参数进行调整,以适配具体的任务场景。
原因:我们已经知道了大模型的核心是一个大矩阵,这个矩阵的参数在预训练后就是固定不变的了,如果我们拿私有的数据集作为样本去稍微调整大模型矩阵参数的数字,这样这个大模型就能更好“理解”我们的私有化知识了。
例子:把一个大学毕业的人比作大模型的话,他在哪个行业多学习知识,那他就会更理解这个行业的知识了。
微调的几个重要因素:
1. 模型本身对行业知识的理解能力够不够强。
2. 给模型训练的数据集质量够不够好。
3. 微调的方法和参数是否合理。
类比现实例子:
1. 这个人的学习理解强不强
2. 这个人学习的内容质量高不高
3. 这个人学习的方法和时间是否科学合理。

四、参考内容
(4 条消息) Transformer模型详解(图解最完整版) - 知乎
大语言模型LLM原理篇大模型本质上是一个维度非常巨大的矩阵,模型训练和微调本质上是调整模型矩阵的值。大模型回答用户问题, - 掘金
大模型解惑 - PamShao - 博客园
大语言模型中的向量化:概念、目的与作用_mb648c186b9844f的技术博客_51CTO博客
大模型词向量:解析语义,助你成为沟通达人_大模型向量化-CSDN博客
简单了解 GPT 模型-腾讯云开发者社区-腾讯云
科学网—从0实现并理解GPT - 李维的博文
独家 | 用初中数学从零开始理解大语言模型(上)