机器学习基础入门(第五篇):半监督学习与强化学习
一、前言

在前几篇文章中,我们学习了机器学习的两大基本类型:监督学习(Supervised Learning) 与 无监督学习(Unsupervised Learning)。
监督学习依赖大量带标签的数据,适用于分类、回归等任务;
无监督学习则无需标签,常用于聚类、降维、模式发现等问题。
然而,在现实世界中,标注数据往往稀缺而昂贵。例如,为成千上万张医学影像打上疾病标签,需要专业医生的时间与经验;而未标注的数据(例如海量图片、视频、日志信息)却极其丰富。
于是,一种“折中”的方法——半监督学习(Semi-supervised Learning) 应运而生。它结合了监督学习与无监督学习的优势:用少量标注数据引导大量未标注数据学习。
除此之外,还有一种完全不同的学习范式——强化学习(Reinforcement Learning)。它不依赖标签,而是让智能体(Agent)在环境中不断试错,通过“奖励”机制学会最优策略。
本文将详细介绍这两种重要的学习方法,它们构成了现代智能系统的基础。
二、半监督学习(Semi-supervised Learning)
1. 半监督学习的动机
传统的监督学习假设所有数据都有标签,但在许多实际问题中,这个假设并不现实。例如:
医学影像识别中,标注一张CT图像可能需要医生几分钟甚至几十分钟;
网络安全检测中,确定哪些流量是“恶意攻击”需要人工分析;
语音识别中,大量语音数据没有文字转录。
而另一方面,大量未标注数据往往可以轻易获得。半监督学习的目标,就是通过同时利用少量标注数据和大量未标注数据,来提升模型的泛化能力。
2. 半监督学习的基本思想
半监督学习的核心假设有三个:
平滑假设(Smoothness Assumption):在特征空间中,距离较近的样本往往属于同一类别。
聚类假设(Cluster Assumption):样本自然分布在若干簇中,同一簇的样本具有相同的标签。
流形假设(Manifold Assumption):高维数据分布在一个低维流形上,模型应学习到这一结构。
利用这些假设,模型可以将少量标注数据的信息“传播”给未标注数据,从而形成更全面的学习。
3. 常见的半监督学习方法
(1)自训练(Self-training)
最早期也是最直观的方法。
首先用少量标注数据训练初始模型;
然后用模型预测未标注数据的标签;
将置信度高的预测结果加入训练集,继续迭代训练。
例如在文本分类中,如果模型对某些未标注新闻的预测置信度达到 95%,则可以将它们作为“伪标签”数据加入下一轮训练。
优点:简单易实现;
缺点:容易积累错误标签(即“伪标签污染”)。
(2)协同训练(Co-training)
由 Blum 和 Mitchell 在 1998 年提出,适用于具有两个独立特征视图的数据。
用不同特征视角分别训练两个模型;
两个模型互相给对方提供置信度高的伪标签样本;
不断迭代,共同提升性能。
常用于网页分类、情感分析等场景。
(3)图半监督学习(Graph-based SSL)
将样本视为图中的节点,节点间的边表示相似度。已标注节点的标签可沿边传播给未标注节点。
代表方法:标签传播(Label Propagation)、图卷积网络(GCN) 等。
(4)生成模型方法
如基于变分自编码器(VAE)、**生成对抗网络(GAN)**的半监督学习,通过生成模型增强数据分布理解。
(5)现代半监督学习(深度伪标签)
在深度学习时代,Google 提出的 Pseudo Label、MixMatch、FixMatch 等算法成为主流。
它们通过数据增强、置信度过滤和一致性正则化(Consistency Regularization)等手段,实现高效的半监督训练。
4. 半监督学习的应用领域
医学影像分析(少量医生标注 + 大量未标注图像)
网络安全与入侵检测
文本分类与情感分析
视频动作识别
自动驾驶感知系统(未标注图像大量存在)
5. 面临的挑战
如何避免伪标签错误的累积?
如何度量未标注样本的不确定性?
不同分布的数据如何有效融合?
三、强化学习(Reinforcement Learning)
1. 基本概念
强化学习(Reinforcement Learning, RL)是一种完全不同的学习范式。
它不依赖标签,而是通过与环境(Environment)交互,不断试错,以最大化**长期奖励(Reward)**为目标。
强化学习的核心理念可以用一句话概括:
“在试错中学习最优策略。”
常见的类比是:
一个小孩学骑自行车,不会有人告诉他“正确姿势”,而是靠摔倒、调整、再尝试,直到学会平衡。
2. 强化学习的组成要素
一个强化学习系统通常包含以下五个核心组件:
| 组件 | 含义 |
|---|---|
| Agent(智能体) | 学习者或决策者 |
| Environment(环境) | 智能体所处的世界 |
| State(状态) | 当前环境的描述 |
| Action(动作) | 智能体可执行的操作 |
| Reward(奖励) | 执行动作后的反馈信号 |
学习的目标是找到一个最优策略 π,使得智能体获得的累计奖励最大化:
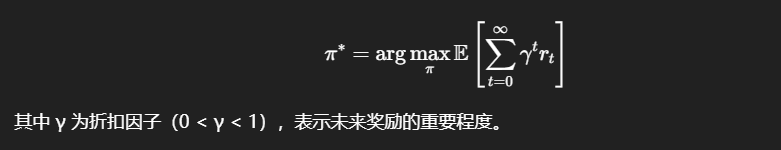
3. 强化学习的主要类型
(1)基于值的方法(Value-based)
通过学习一个“状态-动作”价值函数 ( Q(s,a) ),估计在状态 s 下执行动作 a 的期望奖励。
代表算法:
Q-learning
Deep Q-Network (DQN) —— 结合深度神经网络进行价值估计,是 DeepMind 的突破性成果。
(2)基于策略的方法(Policy-based)
直接学习一个策略函数 π(a|s),即在状态 s 下选择动作 a 的概率。
代表算法:
REINFORCE
PPO(Proximal Policy Optimization) —— 被 OpenAI 广泛使用。
(3)Actor-Critic 方法
结合了上述两种思想:Actor 负责输出策略,Critic 负责评估动作的好坏。
代表算法有:A2C、A3C、DDPG 等。
4. 强化学习的经典应用
游戏智能体:AlphaGo、AlphaStar、OpenAI Five
机器人控制:机械臂操作、自动驾驶导航
推荐系统:基于用户反馈动态优化推荐
金融交易策略优化
能源调度与智能制造
强化学习在需要“长期决策”的问题上展现出巨大潜力。

5. 强化学习的挑战
尽管强化学习成果显著,但在现实落地中仍面临以下难题:
样本效率低:需要大量交互才能收敛;
探索与利用的平衡:如何在尝试新策略与利用已知最优策略之间权衡;
环境复杂性高:真实环境往往噪声大、不可预测;
奖励设计困难:定义合适的奖励函数是工程中的关键挑战。
四、半监督学习与强化学习的结合
现代研究趋势正在融合不同学习范式。例如:
半监督强化学习(Semi-supervised RL):利用未标注环境数据辅助策略优化;
自监督强化学习(Self-supervised RL):通过预测未来状态或特征变化来提升策略泛化。
这类方法在自动驾驶、智能机器人中展现出极大潜力。

五、总结
本文介绍了两种重要的机器学习方法:
半监督学习:通过少量标注 + 大量未标注数据进行学习,是解决数据稀缺问题的重要方向;
强化学习:让智能体通过试错和奖励信号,自主学习最优策略,是构建智能决策系统的核心技术。
两者在现代人工智能中的地位举足轻重,既是理论研究的热点,也是实际应用的关键支撑。