星Day-33 基础补充、建立简单神经网络
深度学习项目中借助ai提问注意事项
见环境安装与配置文档
流程图绘制
https://app.diagrams.net/
ppt配图绘制
App - Napkin AI
命令行基础指令
# 进入路径,意为Change Directory切换目录
cd <路径>
# 返回上一路径,支持相对路径切换
cd ..
# 创建新文件夹
mkdir <文件夹名>
# 显示当前目录和所有子目录的结构,帮助了解项目布局
tree
# 查看当前目录
dir#深度学习常用
# 清空屏幕,意思为Clear Screen
cls
# 运行python脚本呢
python <脚本名>.py
# 查看显卡使用情况
nvidia-smi
技巧:
Tab 键:自动补全文件名或目录名。输入文件名的前几个字母,按Tab,CMD会自动帮你补全。
↑ / ↓ 箭头:快速调出您之前输入过的历史命令,无需重复打字
R语言与matlab的配置与基础
见文档
ipynb转HTML
ipynb转PDF
见文档
ipynb文件转py
jupyter 代码转为 py 文件教程_哔哩哔哩_bilibili
以后做笔记用
typora
pytorch安装
cuda:CUDA是NVIDIA推出的并行计算平台和API模型,它使得显卡可以用于图像渲染和计算以外的目的,例如通用并行计算。PyTorch通过CUDA可以充分利用GPU的计算能力,加速深度神经网络的学习和推理过程
gpu
cpu
pytorch-gpu与cpu
简单神经网络
数据准备
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_splitiris=load_iris()
x=iris.data
y=iris.target
x_train,y_train,x_teat,y_test=train_test_split(x,y,test_size=0.2,random_state=42)from sklean.preprocessing import MinMaxScaler
scaler=MinMaxScaler()
x_train=scaler.fit_transform(x_train)
x_test=scaler.transform(x_test)x_train=torch.FloatTensor(x_train)
y_train=torch.LongTensor(y_train)
x_test=torch.FloatTensor(x_test)
y_test=torch.LongTensor(y_test)- 看数据本身:输入特征几乎都是浮点型
FloatTensor - 看任务类型:
- 分类任务(标签是类别索引,如 0/1/2)标签用
LongTensor - 回归任务(标签是连续数值,如 3.14、95.5)标签用
FloatTensor
- 分类任务(标签是类别索引,如 0/1/2)标签用
模型架构定义
import torch
import torch.nn as nn
import torch.optim as optimclass MLP(nn,Module):#定义一个多层感知机 def __init__(self):#类中的初始化函数super(MLP,self).__init__()#调用MLP的父类的初始化函数
#6行八股文self.fc1=nn.Linear(4,10)#定义输入+隐藏层self.relu=nn.ReLU()#relu也可以不写,在后面前向传播的时候计算下即可,因为relu其实不算一个层,只是个计算而已。self.fc2=nn.Linear(10,3)
# 输出层不需要激活函数,因为后面会用到交叉熵函数cross_entropy,是成本函数的一种,交叉熵函数内部有softmax函数,会把输出转化为概率def forward(self,x):out=self.fc1(x)out=self.relu(out)out=self.fc2(out)model=MLP()1. import torch
- 作用:导入 PyTorch 库的主模块。
torch是 PyTorch 的核心库,包含了张量(Tensor)操作、自动求导(autograd)、GPU 加速等核心功能。- 类比理解:就像用 Python 处理数据时需要
import pandas一样,用 PyTorch 做深度学习必须先导入这个核心库。 - 后续使用时,需要通过
torch.xxx的形式调用其功能,例如创建张量torch.tensor([1,2,3])。
2. import torch.nn as nn
- 作用:导入 PyTorch 的神经网络(Neural Network)模块,并给它起了一个简称
nn(约定俗成的写法,方便后续调用)。 torch.nn是构建神经网络的核心模块,包含了各种常用组件:- 层(Layers):如全连接层
nn.Linear、卷积层nn.Conv2d、循环层nn.LSTM等; - 激活函数:如
nn.ReLU、nn.Sigmoid等; - 损失函数:如
nn.CrossEntropyLoss(分类用)、nn.MSELoss(回归用)等; - 模型容器:如
nn.Sequential(快速搭建简单模型)等。
- 层(Layers):如全连接层
- 举例:之前定义的
MLP类继承的nn.Module,就是来自这个模块。
3. import torch.optim as optim
- 作用:导入 PyTorch 的优化器(Optimizer)模块,简称
optim(同样是约定俗成的简写)。 - 优化器是用于神经网络训练的关键组件,作用是根据模型计算的梯度(通过反向传播得到)来更新网络参数,从而让模型 “学习” 到数据中的规律。
- 常用的优化器有:
optim.SGD:随机梯度下降(基础优化器);optim.Adam:目前最常用的优化器之一,收敛速度快且稳定;- 其他如
optim.RMSprop、optim.Adagrad等。
- 后续训练模型时,需要用这里的优化器来定义 “如何更新参数”。
第一行:class MLP(nn.Module):
语法解析:
class:Python 中定义 “类” 的关键字。类可以理解为一个 “模板”,里面包含了数据(变量)和操作数据的方法(函数)。MLP:这是我们自定义的类名,这里代表 “多层感知机”(Multi-Layer Perceptron),是一种简单的神经网络。(nn.Module):表示MLP类 “继承” 自nn.Module类。- 继承:这是面向对象编程的核心概念之一。简单说,就是 “子承父业”——
MLP作为子类,可以直接使用父类nn.Module中已经写好的代码(变量和方法),不用自己重新写。 nn.Module:是 PyTorch 中所有神经网络模块的 “基类”(父类),所有自定义的模型都必须继承它才能使用 PyTorch 的各种功能(比如训练、保存模型等)。
- 继承:这是面向对象编程的核心概念之一。简单说,就是 “子承父业”——
第二行:def __init__(self):
语法解析:
def:Python 中定义函数的关键字。__init__:这是类的 “初始化方法”(也叫构造函数),当你创建这个类的实例(对象)时,会自动执行这个方法。它的作用是初始化类的属性(变量)。self:这是类方法的第一个参数,必须写。它代表 “类的实例本身”,通过self可以访问类中的其他属性和方法。
作用:
定义 MLP 类的初始化函数,用于在创建模型时初始化神经网络的层(比如输入层、隐藏层等)。
第三行:super(MLP, self).__init__()
语法解析:
super():这是一个用于调用父类方法的函数。super(MLP, self).__init__():表示调用MLP类的父类(即nn.Module)的初始化方法__init__()。
为什么要写这行?
因为 MLP 继承了 nn.Module,而 nn.Module 本身有很多初始化工作要做(比如记录网络中的层、参数等)。这行代码的作用是 “先让父类完成它自己的初始化”,之后我们才能在子类中添加自己的内容。
总结:
这三行(class ...、def __init__...、super...)是 PyTorch 中定义神经网络模型的 “固定套路”
第五行:self.fc1 = nn.Linear(4, 10)
语法解析:
self.fc1:在类中通过self.属性名定义的变量,称为 “实例属性”,整个类的方法都可以访问它。这里fc1是 “第一个全连接层” 的名字(fc 是 fully connected 的缩写)。nn.Linear(4, 10):PyTorch 提供的 “线性层”(也叫全连接层),数学上相当于y = wx + b(w 是权重,b 是偏置)。- 参数
4:输入特征的维度(即这一层的输入有 4 个值)。 - 参数
10:输出特征的维度(即这一层的输出有 10 个值)。
- 参数
第六行:self.relu = nn.ReLU()
语法解析:
nn.ReLU():PyTorch 提供的 “激活函数层”,ReLU 函数的作用是引入非线性(公式:y = max(0, x),即把负数变成 0,正数不变)。
第七行:self.fc2 = nn.Linear(10, 3)
解析:
- 类似第五行,
fc2是 “第二个全连接层”。 - 参数
10:输入维度(与上一层的输出维度 10 对应,确保数据能流通)。 - 参数
3:输出维度(最终输出 3 个值,通常对应分类任务中的 3 个类别)。
第九 - 十三行:def forward(self, x): ...
语法解析:
def forward(self, x):定义了 “前向传播方法”,x是输入数据(比如特征值)。- 前向传播:是神经网络的核心逻辑,描述了数据从输入到输出的计算过程(即信号如何在网络中 “流动”)。
逐行解释:
out = self.fc1(x):把输入x传入第一个全连接层fc1,得到中间结果out(10 维)。out = self.relu(out):把fc1的输出传入 ReLU 激活函数,进行非线性变换(仍然是 10 维)。out = self.fc2(out):把激活后的结果传入第二个全连接层fc2,得到最终输出(3 维)。return out:返回最终输出。
注意:
在 PyTorch 中,只需定义 forward 方法,反向传播(用于训练的梯度计算)会自动通过 autograd 机制实现,不用手动写。
最后一行:model = MLP()
解析:
MLP():创建MLP类的一个实例(即一个具体的模型对象),此时会自动执行__init__方法,初始化网络中的各个层。model:这个实例的名字,后续可以用model来调用模型(比如输入数据进行预测、训练等)。
作用:
实例化了一个多层感知机模型,现在 model 就是我们定义的神经网络了。
模型训练(CPU)
criterion=nn.CrossEntropyLoss()#标准
optimizer=optim.SGD(model.parameters(),lr=0.01)#实例化优化器,指定了需要被优化器更新的模型及参数
#或optimizer=optim.Adam(model.parameters(),lr=0.01)# 训练模型
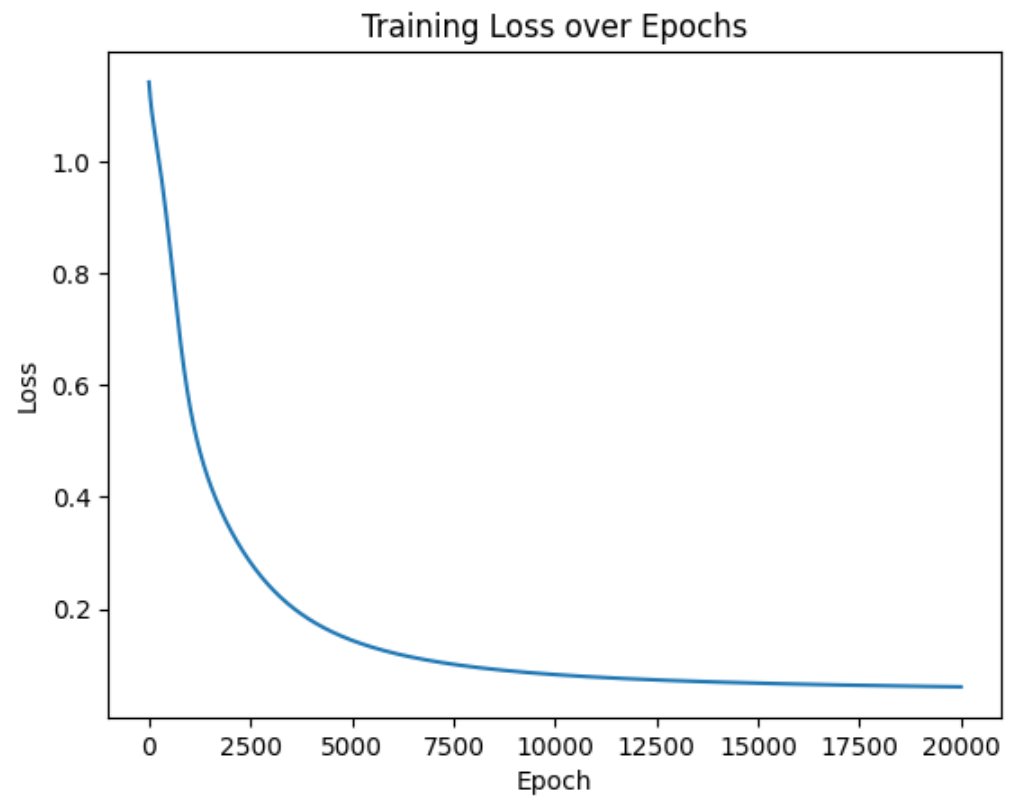
num_epochs = 20000 # 训练的轮数# 用于存储每个 epoch 的损失值
losses = []for epoch in range(num_epochs): # range是从0开始,所以epoch是从0开始# 前向传播outputs = model.forward(X_train) # 显式调用forward函数# outputs = model(X_train) # 常见写法隐式调用forward函数,其实是用了model类的__call__方法loss = criterion(outputs, y_train) # output是模型预测值,y_train是真实标签# 反向传播和优化optimizer.zero_grad() #梯度清零,因为PyTorch会累积梯度,所以每次迭代需要清零,梯度累计是那种小的bitchsize模拟大的bitchsizeloss.backward() # 反向传播计算梯度optimizer.step() # 更新参数# 记录损失值,loss.item():将 PyTorch 的张量(loss 是一个单元素张量)转换为 Python 的普通数值(比如从 tensor(0.5) 变成 0.5)losses.append(loss.item())# 打印训练信息if (epoch + 1) % 100 == 0: # range是从0开始,所以epoch+1是从当前epoch开始,每100个epoch打印一次print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')import matplotlib.pyplot as plt
# 可视化损失曲线
plt.plot(range(num_epochs), losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss over Epochs')
plt.show()