从零开始读懂Transformer:架构解析与PyTorch实现
从零开始读懂Transformer:架构解析与PyTorch实现
引言:为什么我们要学习 Transformer?
在深度学习领域,尤其是自然语言处理(NLP)中,Transformer 已经成为当今绝大多数大模型的基础架构。无论是 BERT、GPT 系列,还是如今火爆的 LLM(大语言模型),其核心都离不开 Transformer。
它彻底改变了传统 RNN/LSTM 的序列依赖计算方式,引入了全新的 “注意力机制”,实现了高效并行训练和对长距离语义依赖的精准捕捉。
本文将带你:
- 深入理解 Transformer 的设计思想
- 图解其整体架构
- 分模块讲解输入、编码器、解码器、输出部分
- 使用 PyTorch 实现关键组件
- 最终构建一个完整的 Encoder-Decoder 模型
阅读建议:配合文中代码实践 + 动手调试 = 掌握更牢固!
一、Transformer 背景介绍:一场 NLP 的革命
论文起源
Transformer 架构首次提出于 2017 年 Google 发表的经典论文《Attention is All You Need》,这篇论文彻底颠覆了 NLP 领域的发展方向。
在此之前,主流模型如 LSTM 和 GRU 采用循环结构逐词处理文本,存在两大问题:
- 无法并行化训练 → 训练速度慢
- 难以捕捉长距离依赖 → 句子过长时性能急剧下降
而 Transformer 完全摒弃了 RNN 结构,仅依靠 自注意力机制(Self-Attention) 来建模全局上下文关系。
后续影响
- 2018年 BERT 出现:基于 Transformer 的双向预训练模型,在 11 项 NLP 任务上刷新 SOTA。
- GPT 系列诞生:以 Transformer 解码器为基础,开启生成式 AI 新纪元。
- 如今的大模型时代:ChatGPT、通义千问、Claude 等均源于 Transformer 架构。
总结一句话:Transformer 是现代 NLP 的基石,不懂它就等于不懂 AI 的现在与未来。
二、 认识 Transformer 架构:总览图解
下面是 Transformer 的经典架构图:
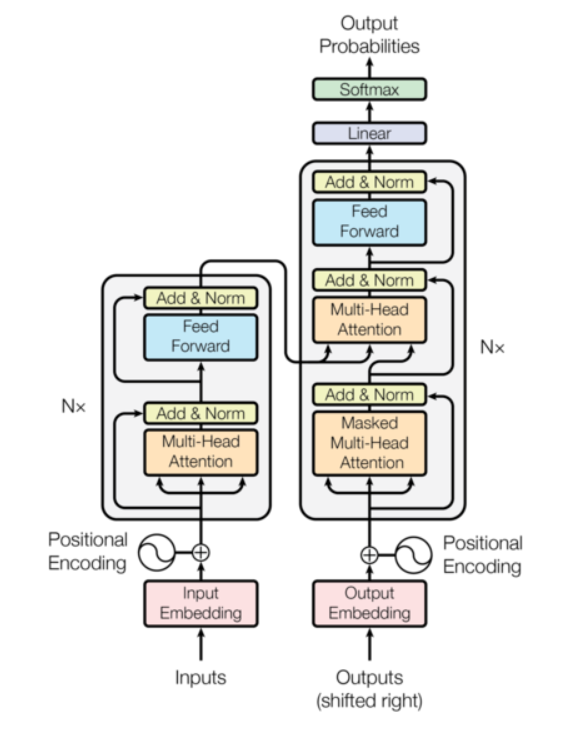
四大组成部分:
输入部分
输入部分包含:
- 源文本嵌入层及其位置编码器
- 目标文本嵌入层及其位置编码器
编码器部分
编码器的组成:
- 由N个(一般为6个)编码器层堆叠而成
- 每个编码器层由两个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
解码器部分
解码器的组成:
- 由N个解码器层堆叠而成
- 每个解码器层由三个子层连接结构组成
- 第一个子层连接结构包括一个多头自注意力子层和规范化层以及一个残差连接
- 第二个子层连接结构包括一个多头注意力子层和规范化层以及一个残差连接
- 第三个子层连接结构包括一个前馈全连接子层和规范化层以及一个残差连接
输出部分
输出部分包含:
- 线性层
- softmax层
各部分作用简介
| 组件 | 功能说明 |
|---|---|
| 输入部分 | 将原始文本转换为向量表示,并加入位置信息 |
| 编码器部分 | 对输入序列进行特征提取,生成上下文感知的表示 |
| 解码器部分 | 根据编码结果和已生成内容,逐步预测下一个词 |
| 输出部分 | 将解码器输出映射到词汇表概率分布 |
下面我们逐个拆解实现!
以下是代码实现所需的包导入,后续示例中不再重复。请提前准备好这些依赖项。
import copy
import math
import numpy as np
import torch
import torch.nn as nn
from matplotlib import pyplot as plt
三、输入部分实现:词嵌入 + 位置编码
3.1 词嵌入层(Embeddings)
作用:将离散的单词 ID 映射为连续的高维向量。
如何构建词嵌入层?
class Embeddings(nn.Module):"""词嵌入层:将输入的token索引转换为词向量表示"""def __init__(self, vocab_size, d_model):"""初始化词嵌入层Args:vocab_size: 词汇表大小d_model: 模型维度"""super(Embeddings, self).__init__()self.vocab_size = vocab_sizeself.d_model = d_modelself.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=d_model)def forward(self, x):"""前向传播Args:x: 输入张量,形状为(batch_size, seq_len)Returns:嵌入后的张量,形状为(batch_size, seq_len, d_model)"""# 词嵌入后乘以sqrt(d_model)保持方差稳定return self.embedding(x) * math.sqrt(self.d_model)
小知识:乘以 sqrt(d_model) 是为了保持嵌入后的方差稳定,防止后续 attention 计算时数值过大。
阶段功能测试
建议在实现每个功能后立即进行测试,然后再开发后续功能。本次演示主要聚焦于Transformer架构的组成原理,因此仅使用简单数据进行测试展示。如有任何疑问,欢迎在评论区交流讨论。
def test_embeddings():vocab_size = 1000d_model = 512x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])print("输入的形状x.shape:>", x.shape)embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)print("嵌入后形状x.shape:>", x.shape)
3.2 位置编码(Positional Encoding)
由于 Transformer 没有循环结构,必须显式地添加位置信息。
为什么要加位置信息?
“我爱你” 和 “你爱我” 词语相同但顺序不同,含义完全不同!
RNN 天然有序列顺序,但 Transformer 是并行处理所有 token,所以需要手动加入位置信号。
如何构建位置编码?
使用正弦和余弦函数组合:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{model}}}\right) \\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{model}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)PE(pos,2i+1)=cos(100002i/dmodelpos)
class PositionalEncoding(nn.Module):"""位置编码层,为序列中的每个位置添加位置信息"""def __init__(self, d_model, dropout_rate, max_len=60):"""初始化位置编码层Args:d_model: 模型维度dropout_rate: Dropout概率max_len: 最大序列长度"""super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(p=dropout_rate)# 创建位置编码矩阵(max_len, d_model)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1) # (max_len,1)# 基于公式实现位置编码_2i = torch.arange(0, d_model, 2).float()# 奇数位置使用sin,偶数位置使用cospe[:, 0::2] = torch.sin(position / 10000 ** (_2i / d_model)) # 下标为偶数,位置位奇数位pe[:, 1::2] = torch.cos(position / 10000 ** (_2i / d_model)) # 下标为奇数,位置位偶数位# 添加批次维度并注册为缓冲区(1, max_len, d_model)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):"""前向传播Args:x: 输入张量,形状为(batch_size, seq_len, d_model)Returns:加上位置编码后的张量,形状为(batch_size, seq_len, d_model)"""x = x + self.pe[:, :x.size(1)]return self.dropout(x)
优点:
- 可学习长期位置模式
- 即使训练中未见过的位置也能外推
阶段功能测试
def test_positional_encoding():vocab_size = 1000d_model = 512x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model=d_model, dropout_rate=0.5)pe = positional_encoding(x)print("位置编码后形状pe.shape:>", pe.shape)
提示:你可以用
matplotlib绘制不同维度的位置编码曲线,观察波长变化趋势。
3.3 绘图示例
def draw_pe_graph():draw_pe = PositionalEncoding(20, 0, 100)x = torch.zeros(1, 100, 20)y = draw_pe(x)plt.plot(np.arange(100), y[0, :, 4:8])plt.legend(["dim_%d" % p for p in [4, 5, 6, 7]], fontsize='small')plt.title("Positional Encoding Visualization")plt.xlabel("Position")plt.ylabel("Encoding Value")plt.show()
小结
文本嵌入层的作用是将词汇的离散数字表示转换为连续的向量表示,从而在高维空间中捕捉词汇之间的语义和语法关系。通过实现 Embeddings 类,利用 nn.Embedding 层将输入的词索引映射为稠密向量,并乘以 d model \sqrt{d_{\text{model}}} dmodel 进行缩放,以稳定梯度并控制数值范围。这一过程为模型后续处理语义信息奠定了基础。
为了弥补 Transformer 模型因并行计算而缺失的序列顺序信息,位置编码器被引入到嵌入层之后。PositionalEncoding 类通过正弦和余弦函数生成与位置相关的编码向量,并将其加到词嵌入上,使模型能够感知词汇在序列中的位置。由于正弦和余弦函数的值域在 [ − 1 , 1 ] [-1, 1] [−1,1] 之间,不仅保证了位置信息的平滑变化,也有效控制了整体嵌入数值的大小,有利于训练稳定性与梯度的高效传播。可视化结果显示,同一词汇在不同位置对应的向量呈现规律性变化,验证了位置编码的有效性。
四、编码器部分实现:堆叠的编码层
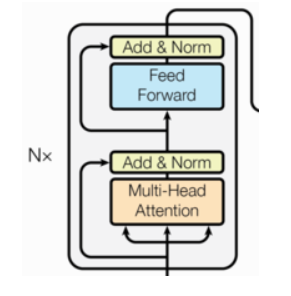
编码器由 N 个相同的编码器层 堆叠而成(原论文 N=6)。每层包含两个子层:
- 多头自注意力机制
- 前馈全连接网络(FFN)
每个子层后接 残差连接 + LayerNorm
子层连接结构(SublayerConnection)
先有个初步了解,后续将详细介绍
class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super().__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(dropout)def forward(self, x, sublayer):# 残差连接:x + sublayer(Norm(x))return x + self.dropout(sublayer(self.norm(x)))
4.1 自注意力机制(Scaled Dot-Product Attention)
公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中:
- Q Q Q: Query(查询)
- K K K: Key(键)
- V V V: Value(值)
def attention(query, key, value, mask=None, dropout=None):"""计算Scaled Dot-Product AttentionArgs:query: 查询张量,形状为(batch_size, seq_len, d_k)key: 键张量,形状为(batch_size, seq_len, d_k)value: 值张量,形状为(batch_size, seq_len, d_k)query = key = valuemask: 掩码张量(可选)dropout: Dropout层(可选)Returns:注意力输出和注意力权重"""d_k = query.size(-1)# 基于自注意力计算公式,得到scorescores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)# print("注意力分数矩阵scores:>", scores.shape)# 判断是否有maskif mask is not None:scores = scores.masked_fill(mask == 0, -1e9)# 让score经过softmax,得到注意力权重矩阵p_attn = torch.softmax(scores, dim=-1)# 判断是否有dropoutif dropout is not None:p_attn = dropout(p_attn)# 计算加权值return torch.matmul(p_attn, value), p_attn
# 测试自注意力机制函数
def test_attention():vocab_size = 1000d_model = 512x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model=d_model, dropout_rate=0.5)pe = positional_encoding(x)query = key = value = pemask = torch.zeros(2, 4, 4)p_attn, attn_weights = attention(query, key, value, mask)print('注意力输出形状p_attn:>', p_attn.shape)print('注意力权重形状attn_weights:>', attn_weights.shape)
为什么除以 √dk?
避免点积结果过大导致 softmax 梯度消失。
4.2 多头注意力机制(Multi-Head Attention)
将注意力机制“分头”执行,增强模型捕捉多种语义关系的能力。
因为多头注意力机制中需要使用多个相同的线性层, 首先实现了克隆函数clones
def clones(model, N):"""克隆模块N次Args:model: 要克隆的模块N: 克隆次数Returns:包含N个克隆模块的ModuleList"""return nn.ModuleList([copy.deepcopy(model) for _ in range(N)])class MultiHeadAttention(nn.Module):"""多头注意力机制"""def __init__(self, num_heads, d_model, dropout_rate=0.1):"""初始化多头注意力层Args:num_heads: 注意力头数d_model: 模型维度dropout_rate: Dropout概率"""super(MultiHeadAttention, self).__init__()assert d_model % num_heads == 0self.d_k = d_model // num_headsself.num_heads = num_headsself.linears = clones(nn.Linear(d_model, d_model), 4)self.attn = Noneself.dropout = nn.Dropout(p=dropout_rate)def forward(self, query, key, value, mask=None):"""前向传播Args:query: 查询张量key: 键张量value: 值张量mask: 掩码张量(可选)Returns:多头注意力输出"""if mask is not None:mask = mask.unsqueeze(1)batch_size = query.size(0)# 线性变换并分头 (batch_size, seq_len, num_heads, d_model) -> (batch_size, num_heads, seq_len, d_model)query, key, value = [linear(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)for linear, x in zip(self.linears, (query, key, value))]# 应用自注意力机制层x, self.attn = attention(query=query, key=key, value=value, mask=mask, dropout=self.dropout)# 重新组合多头 (batch_size, num_heads, seq_len, d_k) -> (batch_size, seq_len, d_model)x = x.transpose(1, 2).reshape(batch_size, -1, self.num_heads * self.d_k)# 让x经过最后一个线性层return self.linears[-1](x)
# 测试多头注意力功能
def test_multi_head_attention():vocab_size = 1000d_model = 512num_heads = 8x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model=d_model, dropout_rate=0.5)pe = positional_encoding(x)query = key = value = pemultihead = MultiHeadAttention(num_heads=num_heads, d_model=d_model)x = multihead(query, key, value)print("多头注意力输出形状x:>", x.shape)
作用总结:
- 允许多个“专家”同时关注不同特征
- 提升表达能力,缓解单一注意力偏差
4.3 前馈全连接层(Feed-Forward Network)
作用:简单两层 MLP,增强非线性拟合能力
class FeedForward(nn.Module):"""初始化前馈全连接层"""def __init__(self, d_model, d_ff, dropout_rate=0.1):"""初始化前馈网络Args:d_model: 模型维度d_ff: 前馈网络隐藏层维度dropout_rate: Dropout概率"""super(FeedForward, self).__init__()# 额外增加2个线性层,增强模型的表达能力self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(p=dropout_rate)def forward(self, x):"""前向传播Args:x: 输入张量Returns:前馈网络输出"""return self.linear2(self.dropout(torch.relu(self.linear1(x))))
# 测试前馈全连接功能
def test_feed_forward():vocab_size = 1000d_model = 512num_heads = 8d_ff = 64x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model=d_model, dropout_rate=0.5)pe = positional_encoding(x)query = key = value = pemultihead = MultiHeadAttention(num_heads=num_heads, d_model=d_model)x = multihead(query, key, value)feedforward = FeedForward(d_model=d_model, d_ff=d_ff)x = feedforward(x)print("前馈网络输出形状x:>", x.shape)
常用配置:d_model=512, d_ff=2048,演示这里d_model=512,d_ff=64
4.4 规范化层(LayerNorm)
作用:在一定层数后连接接规范化层进行数值的规范化,使其特征数值在合理范围内。
class LayerNorm(nn.Module):"""规范化层"""def __init__(self, features, eps=1e-6):"""初始化层归一化Args:features: 特征维度eps: 防止除零的小值"""super(LayerNorm, self).__init__()self.a = nn.Parameter(torch.ones(features))self.b = nn.Parameter(torch.zeros(features))self.eps = epsdef forward(self, x):"""前向传播Args:x: 输入张量Returns:归一化后的张量"""mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a * (x - mean) / (std + self.eps) + self.b
# 测试规范化功能
def test_layer_norm():vocab_size = 1000d_model = 512num_heads = 8d_ff = 64x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size=vocab_size, d_model=d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model=d_model, dropout_rate=0.5)pe = positional_encoding(x)query = key = value = pemultihead = MultiHeadAttention(num_heads=num_heads, d_model=d_model)x = multihead(query, key, value)feedforward = FeedForward(d_model=d_model, d_ff=d_ff)x = feedforward(x)layernorm = LayerNorm(features=d_model)x = layernorm(x)print("规范化后的输出形状x:>", x.shape)4.5 子层连接层
为什么需要子层连接:
从架构图中可以看到,输入到每个子层以及规范化层的过程中,还使用了残差链接(跳跃连接),因此我们把这一部分结构整体叫做子层连接(代表子层及其链接结构),在每个编码器层中,都有两个子层,这两个子层加上周围的链接结构就形成了两个子层连接结构。在解码器中也是同理,只是解码器有三个子层。
class SublayerConnection(nn.Module):"""子层连接,实现残差连接和规范化"""def __init__(self, size, dropout_rate=0.1):"""初始化子层连接Args:size: 特征维度dropout_rate: Dropout概率"""super(SublayerConnection, self).__init__()self.norm = LayerNorm(size)self.dropout = nn.Dropout(p=dropout_rate)def forward(self, x, sublayer):"""前向传播Args:x: 输入张量sublayer: 子层函数Returns:残差连接后的输出"""return x + self.dropout(sublayer(self.norm(x)))
# 测试子层连接功能
def test_sublayer_connection():vocab_size = 1000d_model = 512x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size, d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model, dropout_rate=0.5)x = positional_encoding(x)query = key = value = xmultihead = MultiHeadAttention(num_heads=8, d_model=512)sublayer_connection = SublayerConnection(size=d_model)sublayer = lambda mha_x: multihead(query, key, value)x = sublayer_connection(x, sublayer)print("子层连接输出形状x:>", x.shape)
4.6 编码器层 & 编码器整体
编码器层:
class EncoderLayer(nn.Module):"""编码器层,包含自注意力和前馈全连接"""def __init__(self, size, self_attn, feed_forward, dropout_rate):"""初始化编码器层Args:size: 特征维度self_attn: 自注意力层feed_forward: 前馈网络层dropout_rate: Dropout概率"""super(EncoderLayer, self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout_rate), 2)self.size = sizedef forward(self, x, mask=None):"""前向传播Args:x: 输入张量mask: 掩码张量Returns:编码器层输出"""x = self.sublayer[0](x, lambda normed_x: self.self_attn(normed_x, normed_x, normed_x, mask))return self.sublayer[1](x, self.feed_forward)
原则上这里应该进行测试,这次就姑且跳过吧。
编码器整体:
class Encoder(nn.Module):"""编码器,由N个编码器层堆叠而成"""def __init__(self, layer, num_layers):"""初始化编码器Args:layer: 编码器层num_layers: 编码器层数"""super(Encoder, self).__init__()self.layers = clones(layer, num_layers)self.norm = LayerNorm(layer.size)def forward(self, x, mask=None):"""前向传播Args:x: 输入张量mask: 掩码张量Returns:编码器输出"""for layer in self.layers:x = layer(x, mask)return self.norm(x)
# 测试编码器功能
def test_encoder():vocab_size = 1000d_model = 512num_heads = 8num_layers = 6d_ff = 64x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]])embed = Embeddings(vocab_size, d_model)x = embed(x)positional_encoding = PositionalEncoding(d_model, dropout_rate=0.5)x = positional_encoding(x)multihead = MultiHeadAttention(num_heads=num_heads, d_model=d_model)feedforward = FeedForward(d_model=d_model, d_ff=d_ff)encoder_layer = EncoderLayer(size=d_model,self_attn=multihead,feed_forward=feedforward,dropout_rate=0.1)encoder = Encoder(layer=encoder_layer, num_layers=num_layers)encoder_x = encoder(x)print("编码器输出形状encoder_x:>", encoder_x.shape)
编码器部分到这里就结束了。在接下来的解码器部分,我们会复用很多相同的组件结构,因此无需担心新内容的复杂性。
小结
编码器由多个相同的子层堆叠而成(案例中为 6),每个子层包含两个主要组件:多头自注意力机制(Multi-Head Attention) 和 前馈神经网络(Feed Forward Network),两者之间均通过“残差连接 + 层归一化”(Add & Norm)增强训练稳定性。
- 多头自注意力:允许模型在不同表示子空间中并行关注输入序列的不同部分,提升对上下文的理解能力。
- 前馈网络:对每个位置独立进行非线性变换,增强模型表达能力。
注意点:编码器整体是无状态的,支持并行计算;残差连接有助于缓解梯度消失问题,提升训练效率
五、解码器部分实现:带掩码的逐步生成
解码器同样由 N 层组成,但每层有 三个子层:
- 掩码多头自注意力(防止看到未来信息)
- 编码器-解码器注意力(关注源序列)
- 前馈网络
5.1 掩码机制详解
在训练时,解码器一次性接收整个目标序列(如 <sos> I love you <eos>),但我们希望模型在预测第 t 个词时只能看到前 t-1 个词。
使用 下三角矩阵 实现:
def subsequent_mask(size):"""生成后续掩码(上三角矩阵),用于解码器自注意力机制Args:size: 掩码矩阵大小Returns:掩码张量,形状为(size, size)"""attn_shape = (1, size, size)masked = np.triu(np.ones(attn_shape), k=1).astype('uint8')return torch.tensor(1 - masked)
# 测试创建掩码矩阵功能
def test_subsequent_mask():masked = subsequent_mask(5)print('掩码矩阵:>\n', masked)plt.figure(figsize=(6, 6))plt.imshow(subsequent_mask(20)[0])plt.title("Subsequent Mask")plt.colorbar()plt.show()
输出:
[[1, 0, 0, 0, 0],[1, 1, 0, 0, 0],[1, 1, 1, 0, 0],[1, 1, 1, 1, 0],[1, 1, 1, 1, 1]]
1 表示可见,0 表示遮蔽。
5.2 解码器层&解码器整体实现
解码器层:
class DecoderLayer(nn.Module):"""解码器层,包含自注意力、源注意力和前馈网络"""def __init__(self, size, self_attn, src_attn, feed_forward, dropout_rate):"""初始化解码器层Args:size: 特征维度self_attn: 自注意力层src_attn: 源注意力层feed_forward: 前馈网络层dropout_rate: Dropout概率"""super(DecoderLayer, self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, dropout_rate), 3)def forward(self, x, memory, source_mask, target_mask):"""前向传播Args:x: 解码器输入memory: 编码器输出source_mask: 源序列掩码target_mask: 目标序列掩码Returns:解码器层输出"""x = self.sublayer[0](x, lambda normed_x: self.self_attn(normed_x, normed_x, normed_x, target_mask))x = self.sublayer[1](x, lambda normed_x: self.src_attn(normed_x, memory, memory, source_mask))return self.sublayer[2](x, self.feed_forward)
解码器整体:
class Decoder(nn.Module):"""解码器,由N个解码器层堆叠而成"""def __init__(self, layer, num_layers):"""初始化解码器Args:layer: 解码器层num_layers: 解码器层数"""super(Decoder, self).__init__()self.layers = clones(layer, num_layers)self.norm = LayerNorm(layer.size)def forward(self, x, memory, source_mask, target_mask):"""前向传播Args:x: 解码器输入memory: 编码器输出source_mask: 源序列掩码target_mask: 目标序列掩码Returns:解码器输出"""for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)
# 测试解码器功能
def test_decoder():vocab_size = 1000target_vocab = 2000d_model = 512d_ff = 64N = 6c = copy.deepcopy# 创建测试输入x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]]) # [2, 4]embed = Embeddings(vocab_size, d_model)x = embed(x) # [2, 4, 512]positional_encoding = PositionalEncoding(d_model, dropout_rate=0.5)x = positional_encoding(x) # [2, 4, 512]mask = subsequent_mask(4)multihead = MultiHeadAttention(num_heads=8, d_model=512)feedforward = FeedForward(d_model=d_model, d_ff=d_ff)encoder_layer = EncoderLayer(size=d_model,self_attn=c(multihead),feed_forward=c(feedforward),dropout_rate=0.1)encoder = Encoder(encoder_layer, N)memory = encoder(x)print('编码器层输出形状memory:>', memory.shape)x = torch.tensor([[130, 234, 521, 598], [993, 938, 123, 261]])target_embed = Embeddings(target_vocab, d_model)target_x = target_embed(x)target_pe = PositionalEncoding(d_model=d_model, dropout_rate=0.1)target_x = target_pe(target_x)decoder_layer = DecoderLayer(size=d_model,self_attn=c(multihead),src_attn=c(multihead),feed_forward=c(feedforward),dropout_rate=0.1)decoder = Decoder(layer=decoder_layer, num_layers=N)decoder_result = decoder(x=target_x, memory=memory, target_mask=mask, source_mask=mask)print("解码器层输出形状decoder_result:>", decoder_result.shape)
memory 是编码器的最终输出,作为 KV 输入到第二层注意力。
小结
解码器同样由多个相同子层堆叠构成,但结构比编码器更复杂,包含三个关键组件:
- 掩码多头自注意力(Masked Multi-Head Attention):防止解码时当前词“偷看”未来词的信息,确保生成过程符合因果性。
- 编码器-解码器注意力(Encoder-Decoder Attention):让解码器关注编码器输出的相关信息,实现跨序列依赖建模。
- 前馈网络:与编码器结构一致,用于局部特征提取。
注意点:解码器的输入是右移一位的目标序列(shifted right),以保证训练时的自回归特性;掩码机制是实现正确预测的关键。
六、输出部分实现:从向量到概率
最后一步是将解码器输出转换为词汇表上的概率分布。
6.1 线性层 + Softmax
class Generator(nn.Module):"""输出层,将模型输出转换为词汇表概率分布"""def __init__(self, d_model, vocab_size):"""初始化输出层Args:d_model: 模型维度vocab_size: 词汇表大小"""super(Generator, self).__init__()self.linear = nn.Linear(d_model, vocab_size)def forward(self, x):"""前向传播Args:x: 输入张量Returns:词汇表概率分布"""return torch.log_softmax(self.linear(x), dim=-1)
# 测试输出部分功能
def test_generator():vocab_size = 1000target_vocab = 2000d_model = 512d_ff = 64N = 6c = copy.deepcopy# 创建测试输入x = torch.tensor([[100, 2, 421, 508], [491, 998, 1, 221]]) # [2, 4]embed = Embeddings(vocab_size, d_model)x = embed(x) # [2, 4, 512]positional_encoding = PositionalEncoding(d_model, dropout_rate=0.5)x = positional_encoding(x) # [2, 4, 512]mask = subsequent_mask(4)multihead = MultiHeadAttention(num_heads=8, d_model=512)feedforward = FeedForward(d_model=d_model, d_ff=d_ff)encoder_layer = EncoderLayer(size=d_model,self_attn=c(multihead),feed_forward=c(feedforward),dropout_rate=0.1)encoder = Encoder(encoder_layer, N)memory = encoder(x)print('编码器层输出形状memory:>', memory.shape)x = torch.tensor([[130, 234, 521, 598], [993, 938, 123, 261]])target_embed = Embeddings(target_vocab, d_model)target_x = target_embed(x)target_pe = PositionalEncoding(d_model=d_model, dropout_rate=0.1)target_x = target_pe(target_x)decoder_layer = DecoderLayer(size=d_model,self_attn=c(multihead),src_attn=c(multihead),feed_forward=c(feedforward),dropout_rate=0.1)decoder = Decoder(layer=decoder_layer, num_layers=N)decoder_result = decoder(x=target_x, memory=memory, target_mask=mask, source_mask=mask)print("解码器层输出形状decoder_result:>", decoder_result.shape)generator = Generator(d_model=d_model, vocab_size=target_vocab)output = generator(decoder_result)print("输出词汇表概率分布output:>", output.shape)
使用
log_softmax更利于数值稳定性,常用于配合nn.NLLLoss()损失函数。
该测试环节涵盖了从输入、编码、解码到输出的完整流程。通过完整实现架构图中的各个环节,相信你对Transformer架构已经有了较为深入的理解。
小结
解码器最终输出经过线性变换(Linear Layer)后,再通过 Softmax 函数转换为词汇表上每个词的概率分布,从而预测下一个词。
注意点:输出层通常与目标词表大小一致,Softmax 的输出可用于计算交叉熵损失,指导模型优化。
七、模型构建:组装完整系统
现在我们将所有部件拼接成完整的 Encoder-Decoder 模型:
class EncoderDecoder(nn.Module):def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):super().__init__()self.encoder = encoderself.decoder = decoderself.src_embed = src_embedself.tgt_embed = tgt_embedself.generator = generatordef forward(self, src, tgt, src_mask, tgt_mask):memory = self.encoder(self.src_embed(src), src_mask)output = self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)return self.generator(output)
构建完整模型函数
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):attn = MultiHeadAttention(h, d_model, dropout)ff = PositionwiseFeedForward(d_model, d_ff, dropout)position = PositionalEncoding(d_model, dropout)model = EncoderDecoder(Encoder(EncoderLayer(d_model, attn, ff, dropout), N),Decoder(DecoderLayer(d_model, attn, attn, ff, dropout), N),nn.Sequential(Embeddings(src_vocab, d_model), position),nn.Sequential(Embeddings(tgt_vocab, d_model), position),Generator(d_model, tgt_vocab))# 参数初始化for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)return model
测试模型是否能跑通:
model = make_model(500, 1000, N=2) # 小规模测试
src = torch.randint(1, 100, (2, 4))
tgt = torch.randint(1, 100, (2, 5))
src_mask = torch.ones(2, 1, 4)
tgt_mask = subsequent_mask(5)out = model.forward(src, tgt, src_mask, tgt_mask)
print(out.shape) # 应输出 [2, 5, 1000]
总结与展望
| 模块 | 核心思想 |
|---|---|
| 输入 | 词嵌入 + 位置编码 |
| 编码器 | 多头自注意力 + FFN + 残差连接 |
| 解码器 | 掩码注意力 + 交叉注意力 + FFN |
| 输出 | 线性映射 + 概率归一化 |
未来方向
- 学习 BERT(仅用编码器)
- 学习 GPT(仅用解码器)
- 尝试 Vision Transformer(ViT)
- 探索 LoRA 微调大模型
参考资料
- Vaswani et al., Attention Is All You Need, NeurIPS 2017
- Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018
- The Annotated Transformer (Harvard NLP Group)在线阅读地址、 GitHub 源码仓库
- HuggingFace Transformers 源码
写在最后
Transformer 不只是一个模型,更是一种思维方式 —— 用注意力代替递归,用并行战胜顺序。
掌握它的原理与实现,是你迈向高级 NLP 工程师或研究员的关键一步。
如果你觉得这篇文章对你有帮助,请点赞、收藏、分享!也欢迎留言讨论~我们下期见!