【原】linux内核RCU锁
rcu_read_lock() 是 Linux 内核 RCU(Read-Copy-Update)机制中标记读临界区开始的核心函数,其实现原理围绕 “轻量级标记活跃读者” 展开,确保写者能安全等待所有读者离开临界区后再释放旧数据。
rcu_read_lock() 的实现原理:
rcu_read_lock() 的具体实现依赖于内核配置(如是否支持抢占)和 CPU 架构,但核心逻辑一致,可概括为:
1. 维护 per-CPU 的读计数器
内核为每个 CPU 维护一个 rcu_read_count 计数器(per-CPU 变量),用于记录当前 CPU 上活跃的 RCU 读临界区数量:
- 调用
rcu_read_lock()时,计数器 递增(表示进入一个新的读临界区)。 - 调用
rcu_read_unlock()时,计数器 递减(表示退出读临界区)。
写者在等待 “宽限期(Grace Period)” 时,会检查所有 CPU 的 rcu_read_count:若所有计数器均为 0,说明已无活跃读者,可安全释放旧数据。
2. 禁止抢占(可选,取决于配置)
在支持抢占的内核中(CONFIG_PREEMPT=y),rcu_read_lock() 会额外禁止当前进程被抢占:
- 原因:若读者在临界区中被抢占(调度到其他 CPU),原 CPU 的
rcu_read_count仍为非零,可能导致写者误判 “该 CPU 仍有读者”,延长宽限期。 - 实现:通过
preempt_disable()禁止抢占,rcu_read_unlock()时通过preempt_enable()恢复。
3. 架构相关优化
不同 CPU 架构会对计数器操作进行优化,例如:
- x86 架构:利用
this_cpu_inc宏直接操作 per-CPU 变量(通过段寄存器快速访问),避免原子指令。 - ARM 架构:通过本地 CPU 寄存器或专用指令优化计数器更新,确保低延迟。
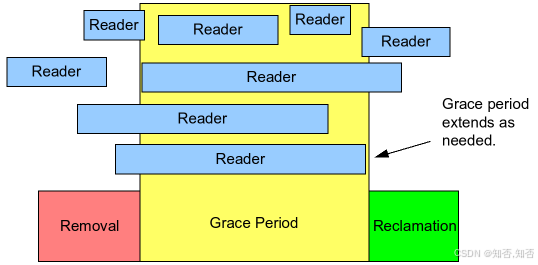
1. 角色与阶段划分
- Reader(读者):图中多个蓝色的 “Reader” 块代表并发的读操作。RCU 的核心优势是读操作无需加锁,可以自由地访问共享数据,这些读操作的时间跨度可能各不相同。
- Removal(移除阶段):红色块代表写者的 “移除” 动作 —— 写者需要更新共享数据时,不会直接修改原数据,而是先复制一份数据副本,在副本上完成修改后,原子性地替换原指针(此时旧数据仍可能被未完成的读者访问)。
- Grace Period(宽限期):黄色块是 RCU 的 “宽限期”,它的持续时间由最晚完成的读者决定(图中箭头标注 “Grace period extends as needed”,即宽限期会根据读者的结束时间动态延长)。在宽限期内,写者会等待所有访问旧数据的读者都退出读临界区。
- Reclamation(回收阶段):绿色块代表 “回收” 动作 —— 宽限期结束后,旧数据不再被任何读者访问,写者可以安全地释放旧数据的内存。
2. RCU 的核心逻辑(结合图的流程)
- 读操作(Reader):读者通过
rcu_read_lock()和rcu_read_unlock()标记读临界区,期间可无锁访问共享数据。这些读操作可以和写操作完全并行,互不阻塞。 - 写操作(Removal + Reclamation):
- 写者先 “复制” 数据并修改副本,再 “更新” 指针指向新副本(这一步是原子的)。
- 随后进入 “宽限期”,等待所有访问旧数据的读者都完成读操作(即所有 “Reader” 块都退出)。
- 宽限期结束后,写者 “回收” 旧数据的内存,整个更新流程完成。
3. 核心优势
- 读操作极致高效:读操作无需加锁、无原子指令开销,在 “读多写少” 场景下性能远超传统锁(如互斥锁、自旋锁)。
- 读写完全并行:读操作不会被写操作阻塞,写操作也不会阻塞读操作(仅延迟回收旧数据)。
- 适用场景明确:特别适合内核中频繁读取、偶尔更新的共享数据(如路由表、进程链表、设备列表等)。
这张图清晰地体现了 RCU“读无锁、写延迟回收” 的设计哲学,是理解 RCU 机制的经典可视化参考。