从分词器构建到强化学习:nanochat开源项目下载与部署全流程教程,教你一步步训练ChatGPT语言模型
手把手教你从零训练一个ChatGPT模型:全面解析nanochat开源项目|从分词器构建到强化学习,详细解析训练ChatGPT模型的每个步骤

OpenAI联合创始人Andrej Karpathy(安德烈·卡帕西)发布了一个名为 “nanochat” 的开源项目,助力开发者从零开始训练ChatGPT模型。
这个创新项目通过全面的流程,带你从基础的分词器构建、预训练,到中间训练、监督微调(SFT)和强化学习(RL),一步步实现一个类似ChatGPT的大型语言模型。
在AI与机器学习领域,nanochat 被认为是一个零基础入门的绝佳资源,适合从初学者到进阶开发者全面理解大模型的训练过程。
项目亮点:
- 全流程覆盖:从分词器到强化学习,完整训练流程一手掌握。
- 简单易懂:即使你是完全小白,也能通过简单步骤完成训练。
- 无门槛挑战:虽然存在一定技术门槛,但通过本教程,你将轻松克服并理解大模型的核心概念。
跟随本篇教程,你将:
- 快速掌握基础操作:只需30分钟,便可完成ChatGPT模型的训练。
- 了解大模型训练全程:深入学习从零开始构建AI模型的每一个步骤。
本教程将帮助你快速上手, 即使你是从未接触过机器学习的初学者,也能通过简单的步骤,完成自己的ChatGPT训练模型。在接下来的内容中,我们将带你一步一步完成模型训练,从租赁服务器到配置环境,再到实际的训练操作,整个过程将不再神秘,而是清晰可见。
无需担心复杂的原理, 我们将专注于每一步操作,你只需跟随步骤进行,即使遇到问题,AI也能为你提供帮助,解决99%的常见问题。
即使你是技术新人,只需按照本文的清晰指引,逐步执行每个操作,你就能顺利完成属于你自己的ChatGPT训练模型。如果在执行过程中有疑问,AI工具将帮助你解决99%的技术问题。
教程概览:
- 租赁一台带显卡的服务器,准备计算资源。
- 配置服务器环境,确保一切准备就绪。
- 跟随代码进行训练,从预训练到微调,全程操作指导。
原项目地址:nanochat GitHub
整个教程预计用时:1-2小时(包含训练时间)。
文章目录
- 手把手教你从零训练一个ChatGPT模型:全面解析nanochat开源项目|从分词器构建到强化学习,详细解析训练ChatGPT模型的每个步骤
- **一、租用云服务器**
- **二、服务器配置**
- **三、训练环境配置**
- **四、进入训练**
- 后台下载更多训练数据(约24GB,这会需要较长时间)
- 训练一个超小模型(大约10-15分钟完成)
- **五、结束与展望**
- **六、致谢**
一、租用云服务器
因为我并不是真的想要训练一个多么可用的模型,我只是想体验完整的训练流程,所以原项目完成整个训练需要8张A100显卡跑4个小时才可以完成,我把步数和深度在训练时做了调整,我们来训练一个小模型,只需要A100跑15-20分钟即可。
那么,也就是说 你体验整个训练流程的成本,不过是:50块钱左右。
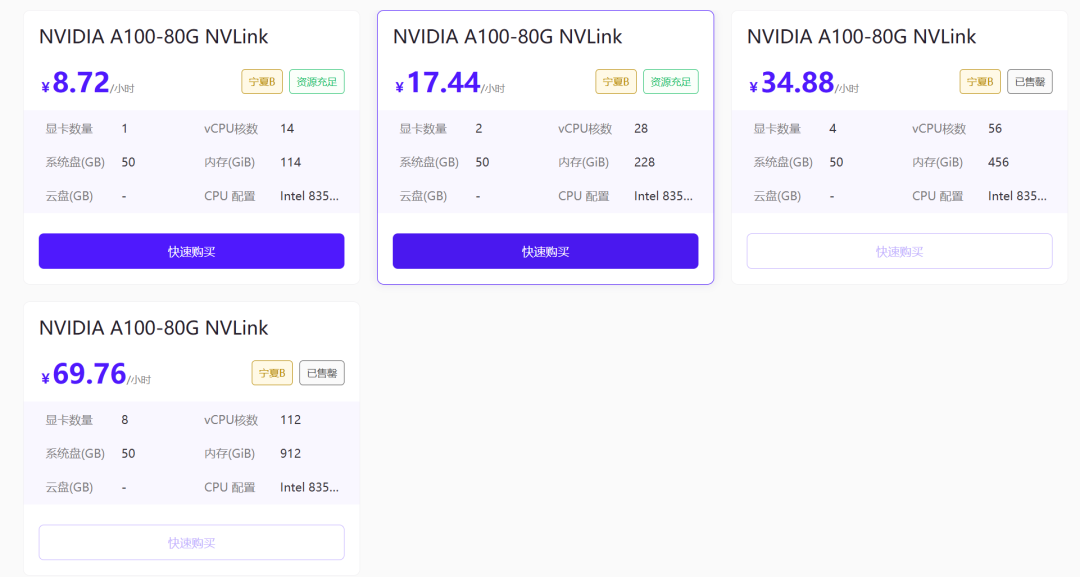
如果你本身没有显卡,那么你可以去:星海智算、火山云、阿里云、腾讯云、无问芯穹等平台租用一台挂载A100显卡的机器即可。
需要注意的是:系统盘最低也要50G,因为训练的时候需要下载24G的训练数据。其他的配置并没有太多要求,大家根据预算自行选择。
本教程推荐使用星海算力平台(新用户可免费体验):https://gpu.spacehpc.com/user/register?inviteCode=52872508
我有A100显卡和服务器可用,所以我就直接使用这台服务器进行操作和演示,这个服务器和在云厂商租用的没有任何区别。
具体如何购买的操作,大家可以参考各厂商的购买指引,我就不做演示了。
(后续如果有需要,再出一个专门的指引,本篇先专注于训练教程)
二、服务器配置
各个服务器厂商的操作位置都差不多,大家找找在哪登录就好,登录完成后就都一样了。以下使用的我之前的服务器为例。
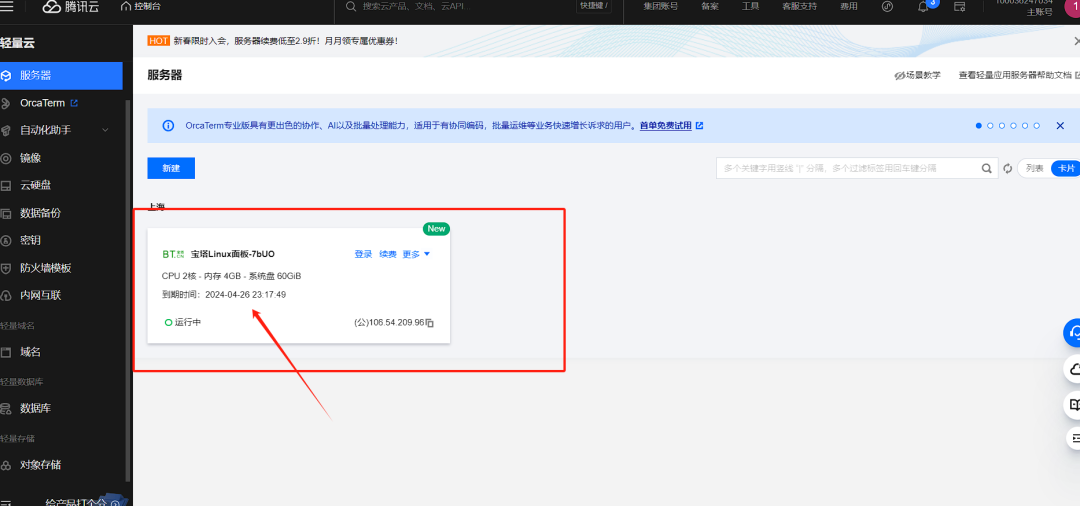
1、 添加端口
在控制台,找到你购买的服务器,点击图中,箭头指示的空白区域。
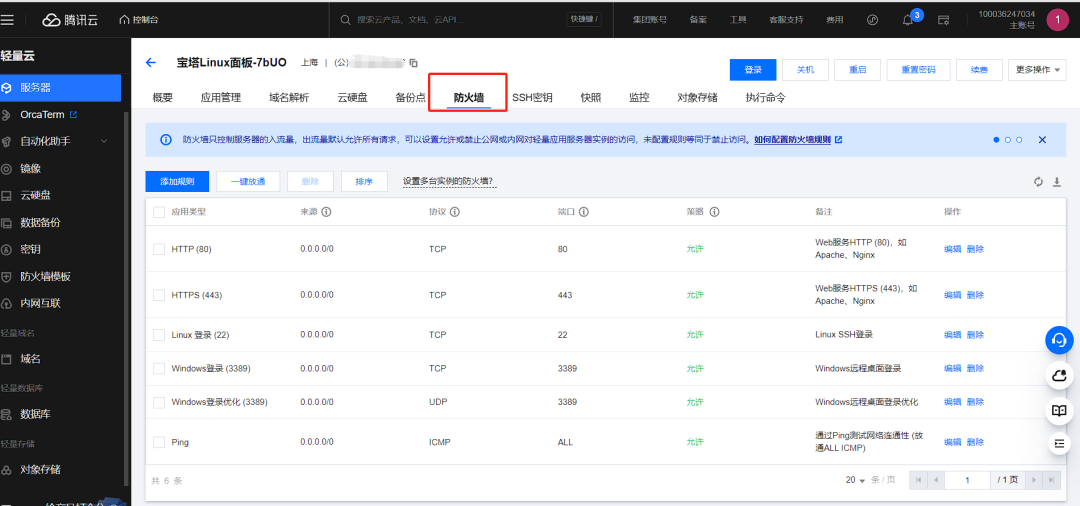
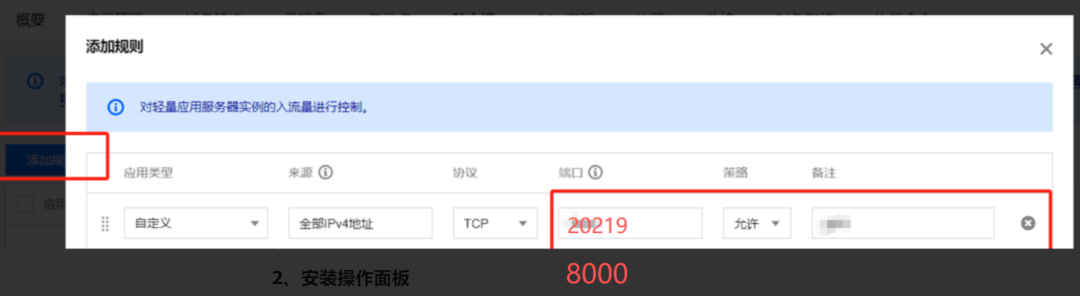
选择“防火墙”菜单栏,点击【添加规则】按钮,添加【20219】和【8000】端口并确定。
2、安装操作面板
然后点击右上角的登录:
直接粘贴命令到命令行中,点击回车开始执行:
curl -sSL https://resource.fit2cloud.com/1panel/package/quick_start.sh -o quick_start.sh && sudo bash quick_start.sh
然后一路点击回车就可以了。
3、最后到这一步,记住你自己的登录地址和账号密码。复制出来保存好。
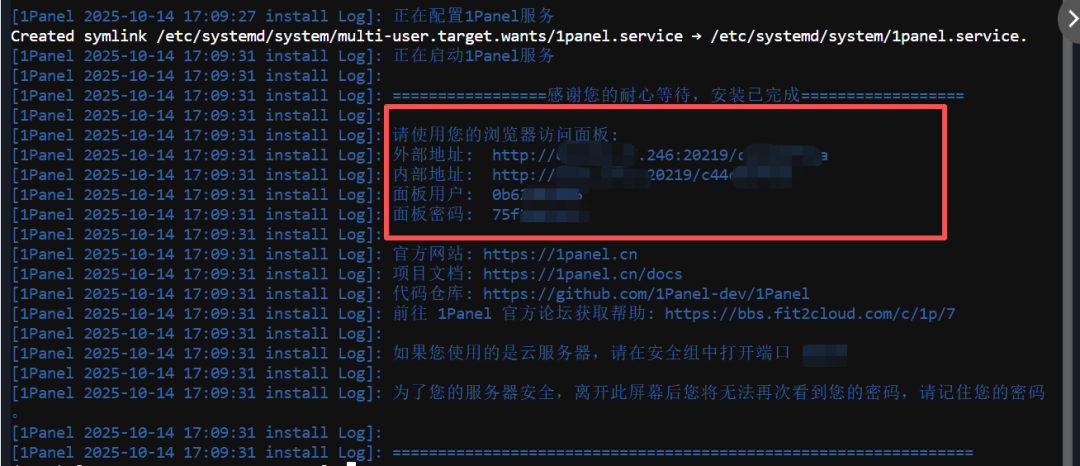
使用「外部地址」,输入面板用户和密码,来登录即可。

好,到这里你已经可以开始方便的使用服务器了。
三、训练环境配置
我们的命令都在终端执行,直接在管理面板,打开左侧的终端,来粘贴命令:
⚠️注意:
- 下边将出现代码,复制的时候,注意复制全。
- 代码我已经分好步骤,每次只需要粘贴一行代码,然后点击一次回车。 中文字符的是解释不需要复制粘贴,每次只复制和粘贴“代码”部分即可。
- 回车后,只有最左边显示[ ]中括号时,才是上一个命令执行完毕了。 没有出现[ ]中括号对话前缀时,不要操作。
- 如果你发现 ctrl+v 粘贴不进去,试试 shift+ctrl+v 粘贴。
1、我们来检查一下你租用的服务器配置:
# 检查NVIDIA驱动是否正确安装
nvidia-smi
# 查看CUDA版本
nvcc --version
# 检查GPU内存和使用情况
nvidia-smi --query-gpu=memory.total,memory.used --format=csv
2、为了防止有的小伙伴的服务器使用的CUDA版本不行,我们都更新一遍
# 更新软件包列表
sudo apt update
# 安装NVIDIA驱动和CUDA工具包
sudo apt install -y nvidia-driver-550 nvidia-cuda-toolkit
# 重启系统使驱动生效
sudo reboot
3、上一步会重启,等待1-2分钟,刷新页面,继续操作即可。
# 验证安装情况
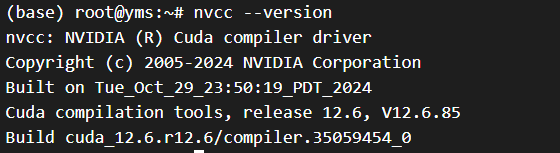
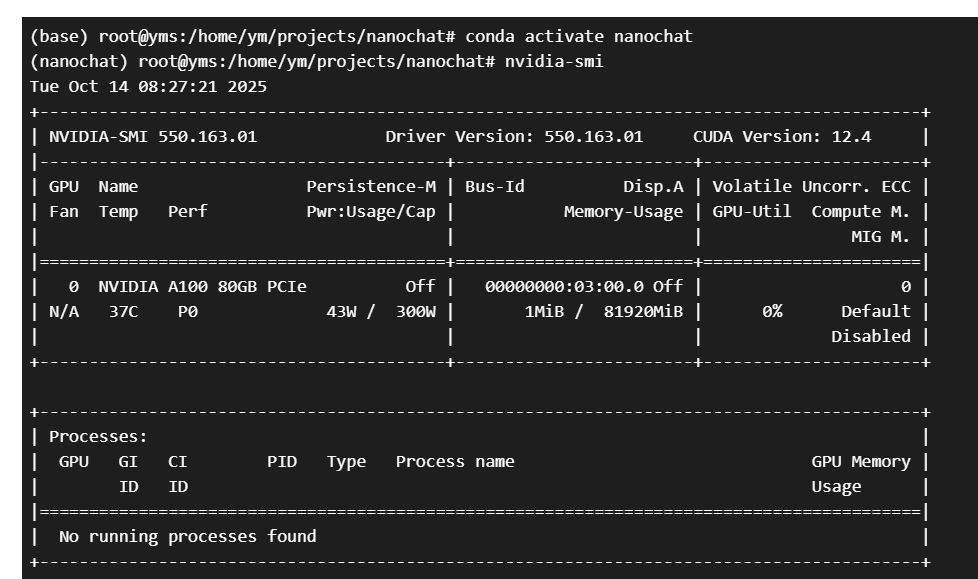
nvcc --version
# 验证GPU可用
nvidia-smi
输出这个就是可以了:
4、安装PyTorch对应的CUDA
pip uninstall torch -ypip install torch --index-url https://download.pytorch.org/whl/cu121
5、测试CUDA是否可用
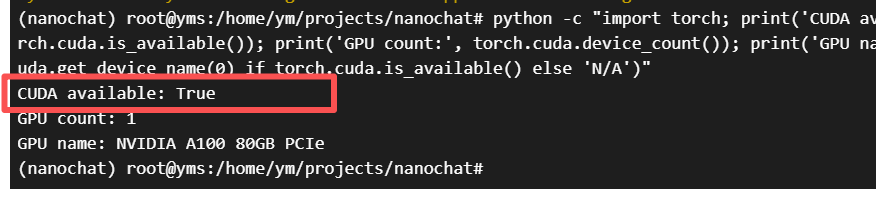
python -c "import torch; print('CUDA available:', torch.cuda.is_available()); print('GPU count:', torch.cuda.device_count()); print('GPU name:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'N/A')"
如果最后的测试输出如下,那么就是可以了:
6、安装环境管理工具
然后我们安装一个环境管理工具,下方两行粘贴进入,然后点击回车,等待下载完成。
echo "开始安装 Anaconda..."wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
(如果这里有了卡点,直接报错发给AI解决即可,这里只是在安装一个环境工具)
7、再粘贴下方代码,出现下图,就代表在执行中了。
bash Anaconda3-2021.05-Linux-x86_64.sh -b -p /root/anaconda
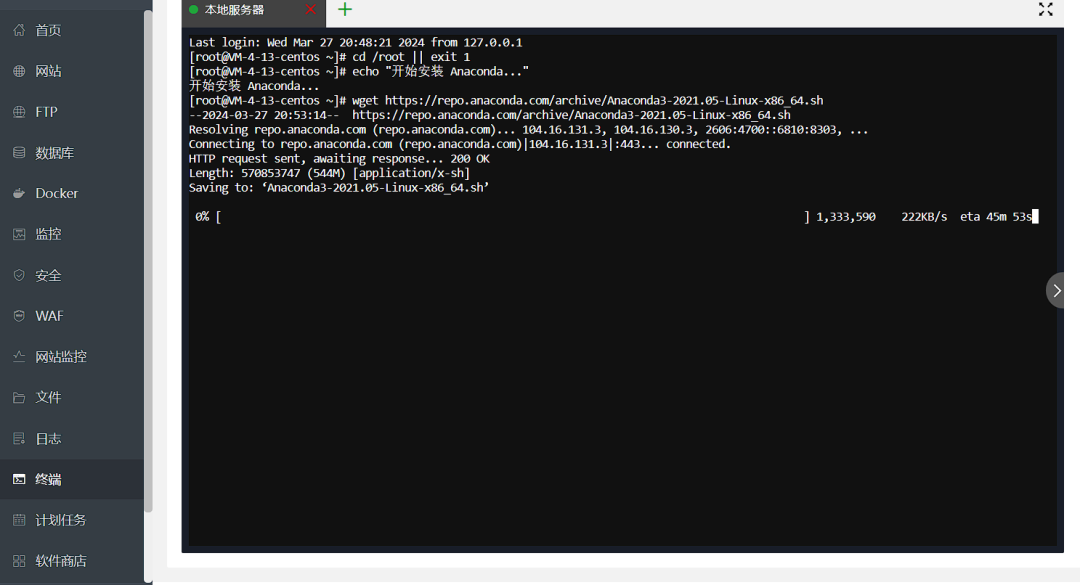
8、然后把下边这行粘贴进去,点击回车。
rm -f Anaconda3-2021.05-Linux-x86_64.sh
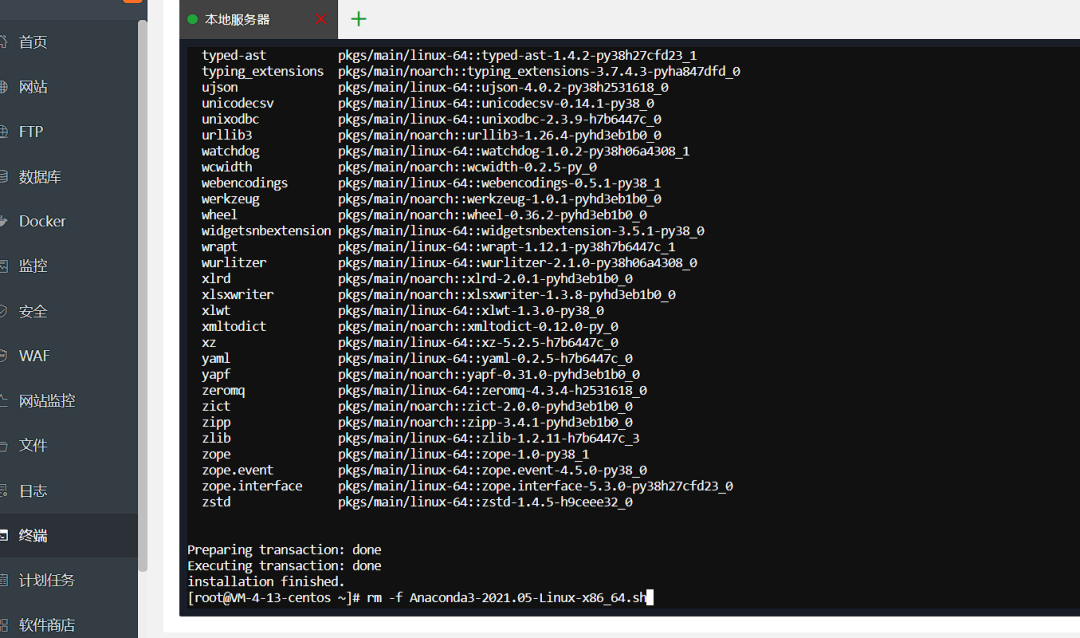
9、然后创建一个训练环境
# 创建新的conda环境
conda create -n nanochat python=3.10 -yconda activate nanochat
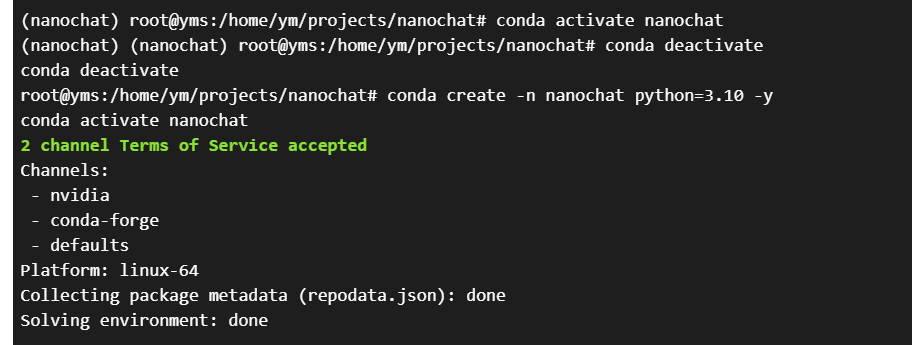
至此,环境配置和检查完成。
四、进入训练
1、 继续粘贴,首先创建项目目录:
mkdir -p ~/projectscd ~/projects
2、 下载AK大神的项目:
git clone https://github.com/karpathy/nanochat.gitcd nanochat
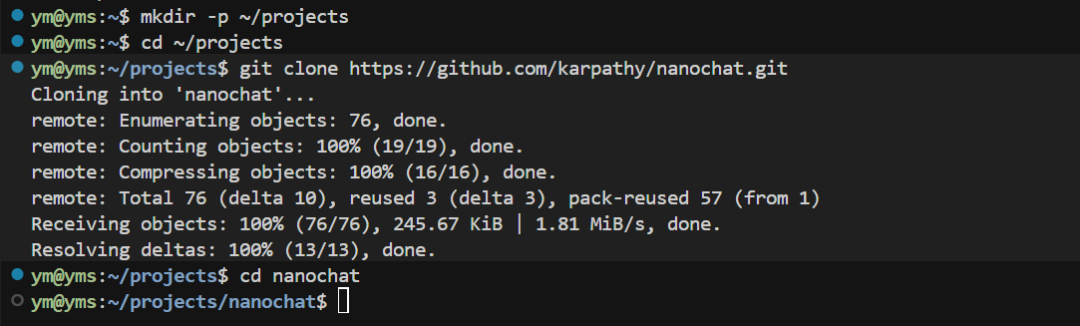
3、 继续安装
# 安装项目依赖
pip install -e .
# 安装maturin
pip install maturin
确保Rust环境变量已加载source “$HOME/.cargo/env”# 构建tokenizer
maturin develop --release --manifest-path rustbpe/Cargo.toml
4、创建缓存目录
mkdir -p ~/.cache/nanochat
5、下载初始数据集并训练tokenizer
下载初始数据集(约800MB,这可能需要几分钟)
python -m nanochat.dataset -n 8
大家可能好奇这个数据集里都有什么,我打开来给大家看一下。
原始内容其实就是一些Json格式的纯文本数据。
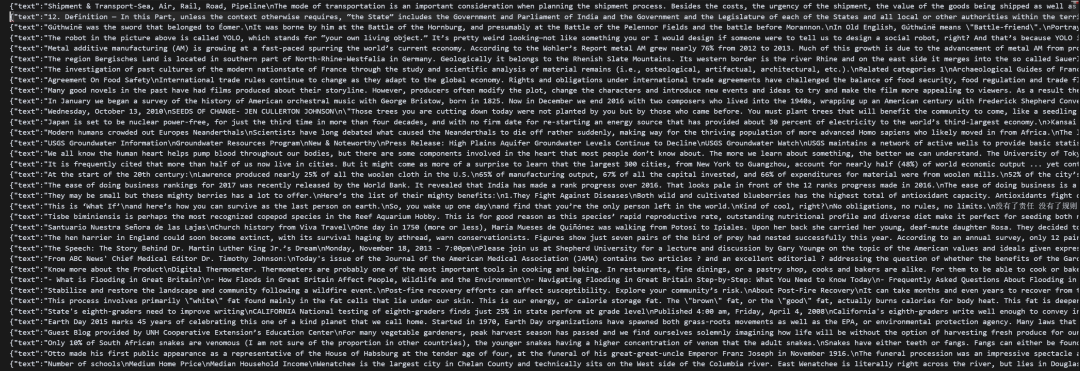
每一行其实都很长,大概有个五六千字。我把第一行复制出来翻译了一下,大家可以看下,是一篇关于运输与物流的文本。
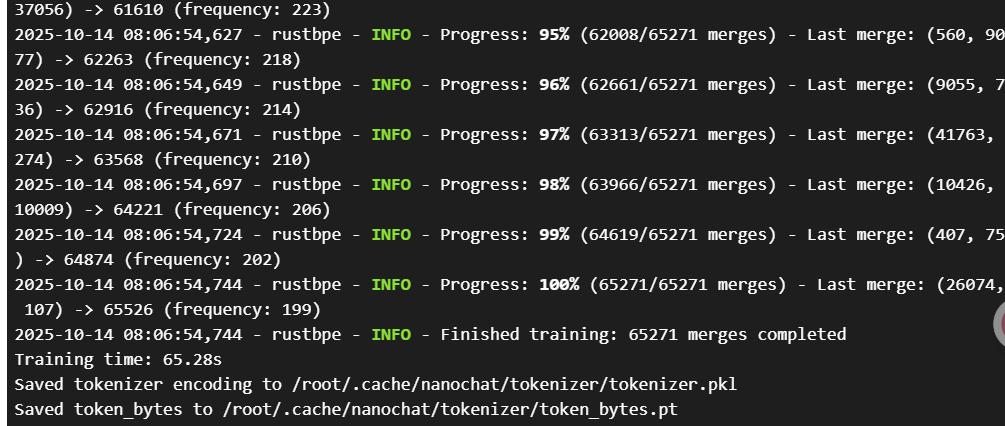
6、等上一步执行完成后,我们继续训练tokenizer。
这也需要一些时间
python -m scripts.tok_train --max_chars=2000000000
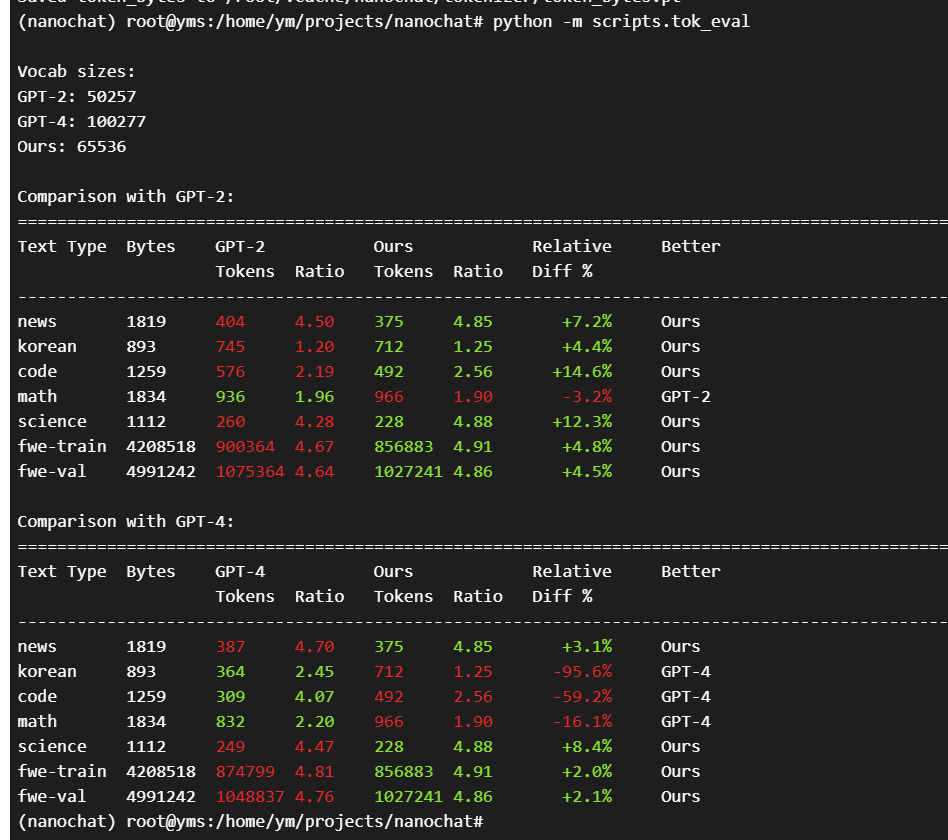
7、评估tokenizer
python -m scripts.tok_eval
8、下载更多训练数据和评估数据
后台下载更多训练数据(约24GB,这会需要较长时间)
python -m nanochat.dataset -n 240 &DATASET_DOWNLOAD_PID=$!
出现这个就是下载完成了。
9、下载评估数据(约162MB)
curl -L -o eval_bundle.zip https://karpathy-public.s3.us-west-2.amazonaws.com/eval_bundle.zipunzip -q eval_bundle.zipmv eval_bundle ~/.cache/nanochat/rm eval_bundle.zip

10、至此环境和数据均已准备完成,我们开始训练“模型”。
训练一个超小模型(大约10-15分钟完成)
python -m scripts.base_train --depth=4 --device_batch_size=32 --num_iterations=500
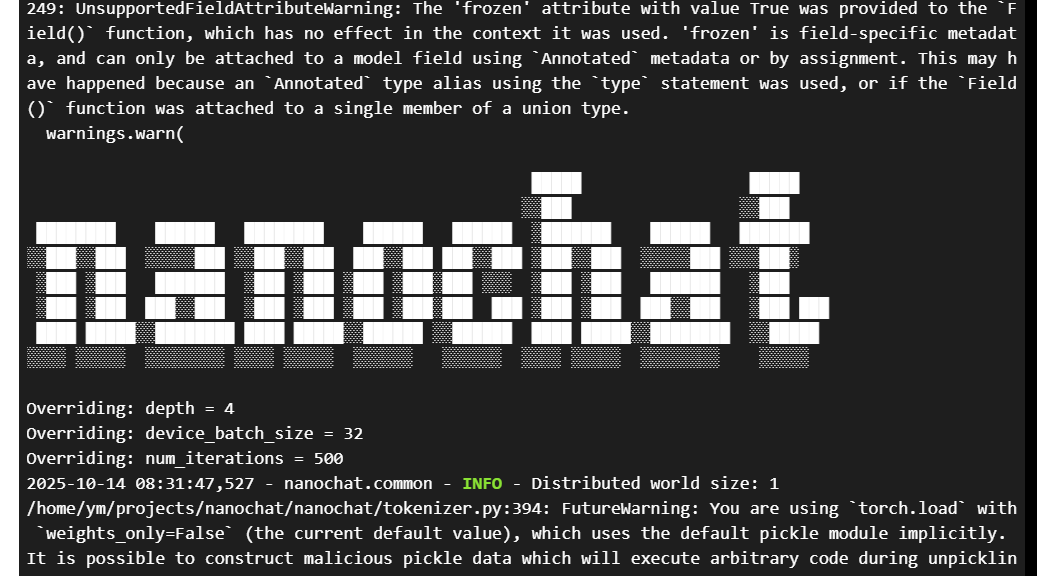
然后就是等待,此时你会看到命令行中不断输出。上图中的部分显示了程序正在覆盖某些默认配置参数,这些参数意思是:
depth = 4: 模型的层数(深度)被设置为4。
device_batch_size = 32: 每个设备(比如一张GPU卡)一次处理的数据批次大小为32。
num_iterations = 500: 总共要训练500个步数。
然后你会看到模型的训练步骤返回的日志:
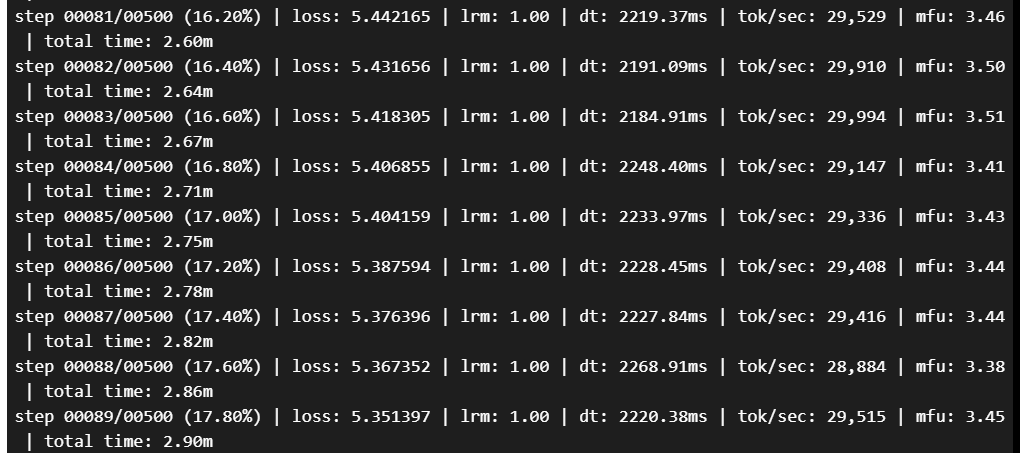
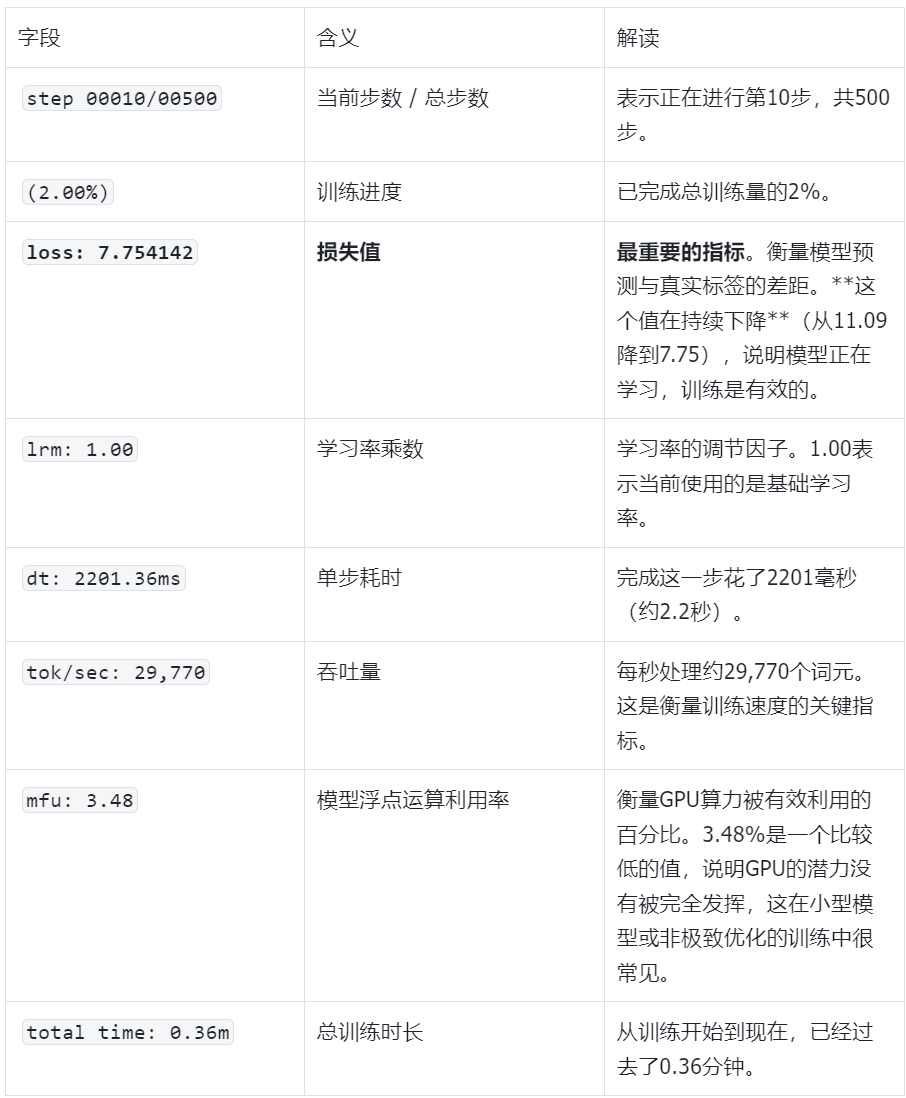
反正也是在等待,我们拿这一行举例解释一下都是什么意思:
看到下图就是训练完成了,我们用了18分钟进行训练。
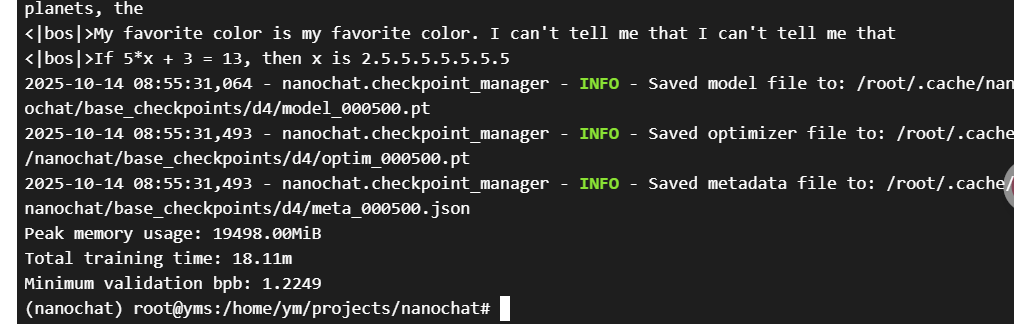
11、中间训练
这一步是为了教会模型理解对话格式和特殊标记(大约15-20分钟)。这步我也更改了参数,原参数跑起来太慢了。我们只需要走一遍流程就好。同样的你也可以看到训练步骤。
python -m scripts.mid_train --device_batch_size=128
如果你不在乎时间,你也可以使用原参数训练,命令是:python -m scripts.mid_train
看到下方这个就是完成:
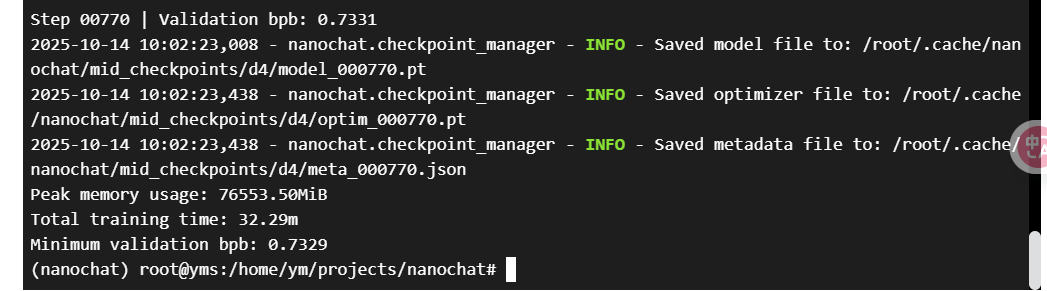
12、中间训练完成, 我们就进入到了最后一步的SFT(监督微调阶段),这一阶段会让模型更好的学会我们的语言习惯和方式
同样的,为了训练速度更快,我更改了训练参数,直接粘贴进去即可继续训练:
python -m scripts.chat_sft --device_batch_size=16
如果你不在乎时间,你也可以使用原参数训练,命令是:python -m scripts.chat_sft
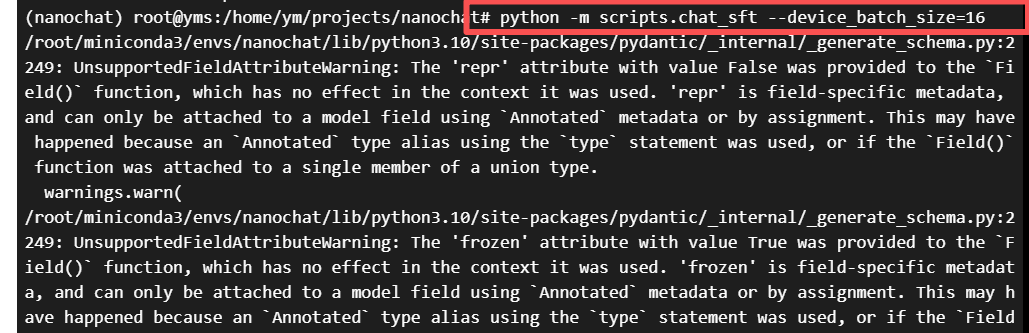
看到输出以下即表示训练完成!
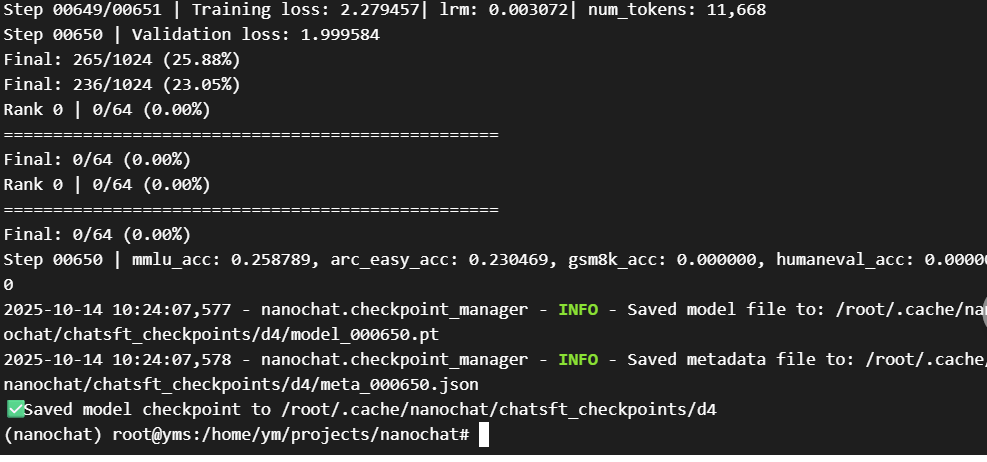
我们从评估结果可以看到:
MMLU准确率:25.88%
ARC-Easy准确率:23.05%
GSM8K和HumanEval:0%(这个小模型在数学和编程上还不行,正常现象)
这是个很小的模型,效果有限,但已经具备基本的对话能力了。
13、我们先开放一下8000端口:
sudo ufw allow 8000
14、然后继续在命令行输入:
python -m scripts.chat_web
你会看到以下输出:
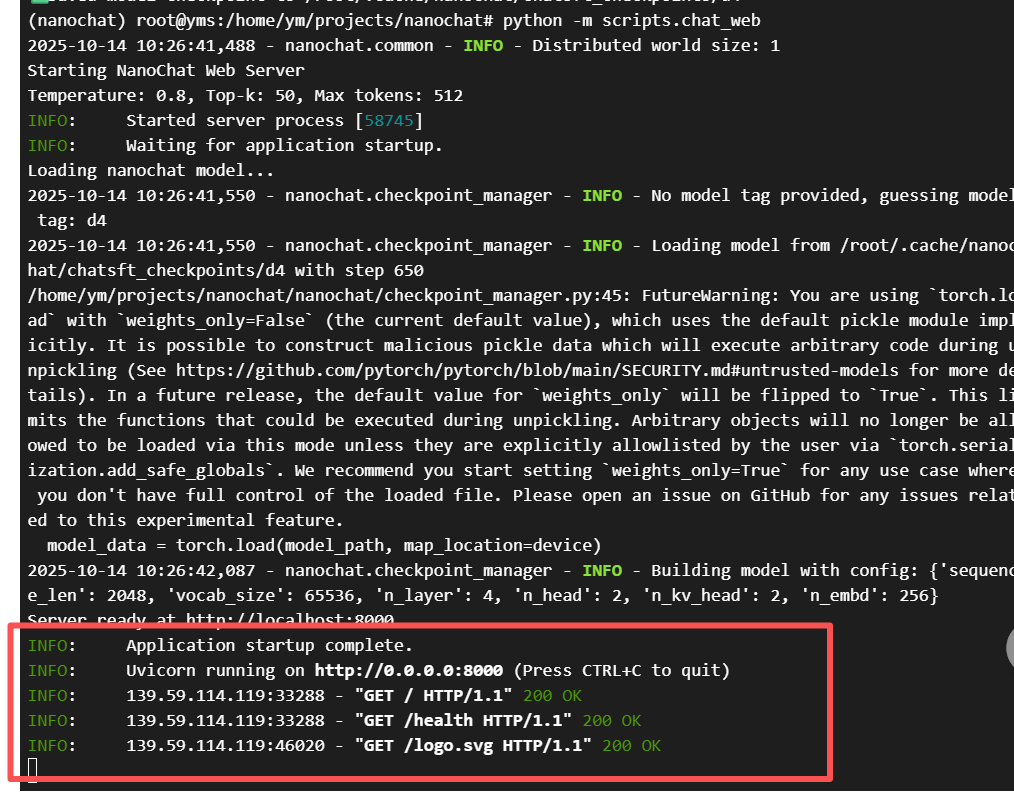
现在,只需要把中间的0.0.0.0 改成你的服务器IP地址即可。
假如我的是:12.45.748.105
那么拼接地址就是:http://12.45.748.105:8000/
把这个地址粘贴到你浏览器中,你就会打开这个页面:
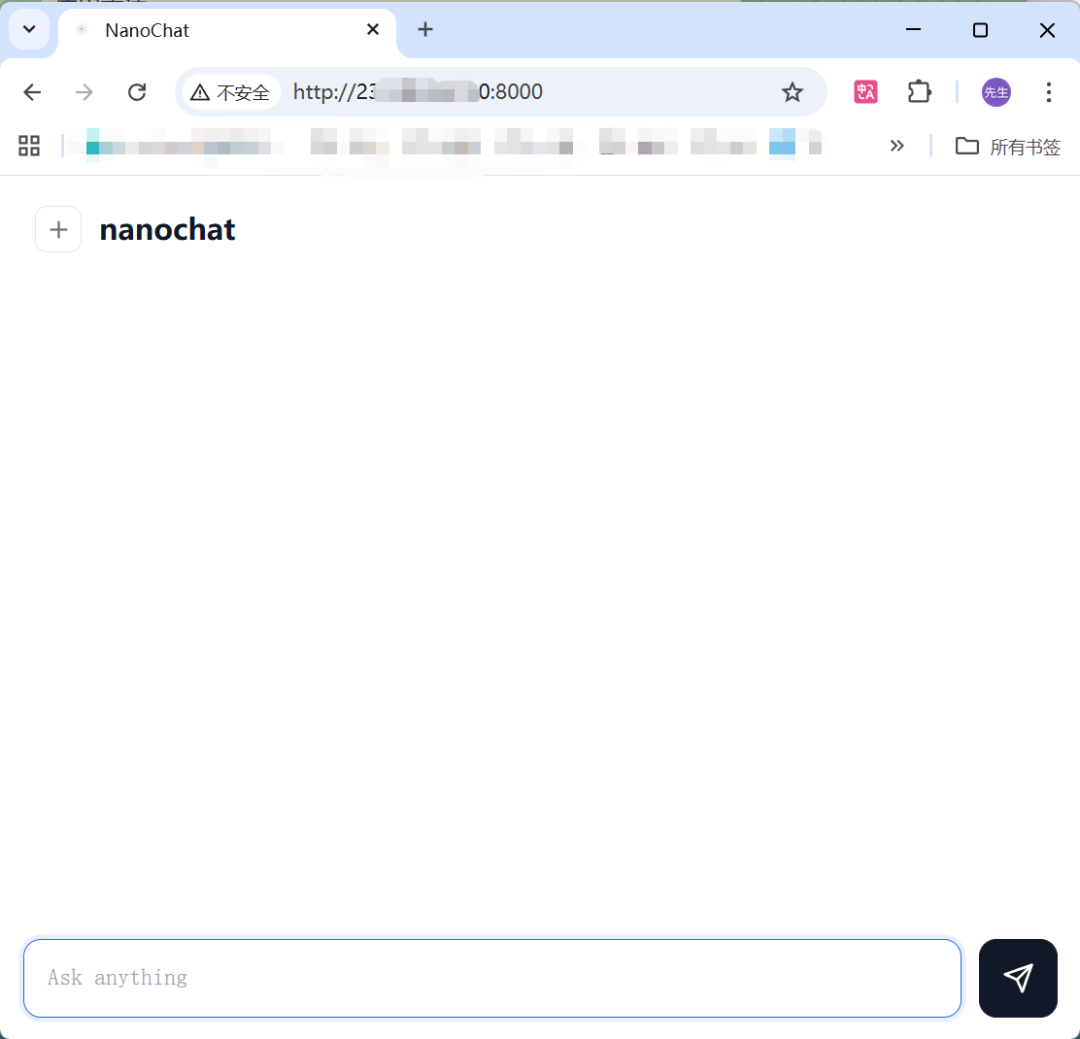
恭喜你,你已经从零完成了一个大模型的训练。
你现在可以与他对话,来唤醒这个刚刚问世的大模型了。
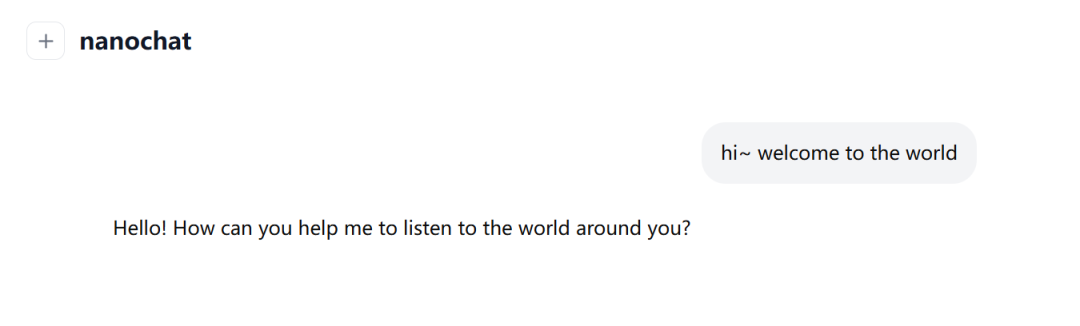
五、结束与展望
恭喜你!🎉
你已经成功完成了从零训练大语言模型的全过程!
通过本教程,你从分词器的构建,到预训练、中间训练,最后到监督微调(SFT),亲手完成了每个训练环节。在短短1-2小时的实践中,你不仅掌握了训练的基本步骤,更亲身体验了大型语言模型是如何一步步成长的。
现在,你可以通过自己训练的模型与AI进行对话,真正理解“大模型究竟是如何炼成的”。这项技能将为你未来的AI探索和开发打开无限可能。你不仅学会了如何训练模型,还理解了训练过程中每个环节的重要性。
如果你在过程中获得了成就感, 那就继续保持这份好奇心和求知欲,继续探索AI的奥秘,打造更加复杂和强大的模型。也期待你将自己的发现和进步分享给更多志同道合的朋友,共同推动AI技术的进步。
继续深耕下去,未来属于你!
六、致谢
特别感谢原创作者✍️的付出,原文如下:
本教程原文链接🔗:原创 张梦飞[梦飞 AI]:https://mp.weixin.qq.com/s/CToTaDDIEBTWZ_XrkNmukg?scene=1&click_id=11