学习路程十二 langchain核心Agent
前序
之前了解过大模型训练数据有截止时间,如果要查询之后发生的内容。要么是一些内部私域数据向量化用于查询,要么是一些网上公开的可以通过浏览器查询到的数据。这里就需要借助于搜索工具与llm进行配合了。
在langchain中,Agent就是实现这些功能的。
Agent简介
代理(Agent)是使用LLM作为思考工具,决定当前要做什么。我们会给代理一系列的工具,代理根据我们的输入判断用哪些工具可以完成这个目标,然后不断的运行工具,来完成目标。代理(Agent)可以看做是增强版的Chain,不仅绑定模板、LLM,还可以给代理添加一些外部工具。
代理(Agent)还是构建智能体的基础,它负责根据用户输入和应用场景,在一系列可用工具中选择合适的工具进行操作。Agent可以根据任务的复杂性,采用不同的策略来决定如何执行操作。
langchain中主要提供了有两种类型的Agent:
- 动作代理(Action Agents):这种代理一次执行一个动作,然后根据结果决定下一步的操作。
- 计划-执行代理(Plan-and-Execute Agents):这种代理首先决定一系列要执行的操作,然后根据上面判断的列表逐个执行这些操作。
对于简单的任务,动作代理(Action Agents)更为常见且易于实现。对于更复杂或长期运行的任务,计划-执行代理的初始规划步骤有助于维持长期目标并保持关注。但这会以更多调用和较高延迟为代价。这两种代理并非互斥,可以让动作代理负责执行计划-执行代理的计划。
LangChain 中内置了一系列常用的 Agent工具,这些工具提供的Agent都属于Action Agent。
Agent内部涉及的核心概念如下:
- 代理(Agent):这是应用程序主要逻辑。代理暴露一个接口,接受用户输入和代理已执行的操作列表,并返回AgentAction或AgentFinish。
- 工具(Tools):这是代理可以采取的动作。比如发起HTTP请求,发邮件,执行命令。
- 工具包(Toolkits):这些是为特定用例设计的一组工具。例如,为了让代理以最佳方式与SQL数据库交互,它可能需要一个执行查询的工具和另一个查看表格的工具。可以看做是工具的集合。
- 代理执行器(Agent Executor):将代理与一系列工具包装在一起。它负责迭代运行代理,直到满足停止条件。
在LangChain框架中,智能代理(Agent)通常按照观察(Observation)- 思考(Thought)- 行动(Action)的模式来处理任务,这个模式叫ReAct思考框架。Agent的执行流程:
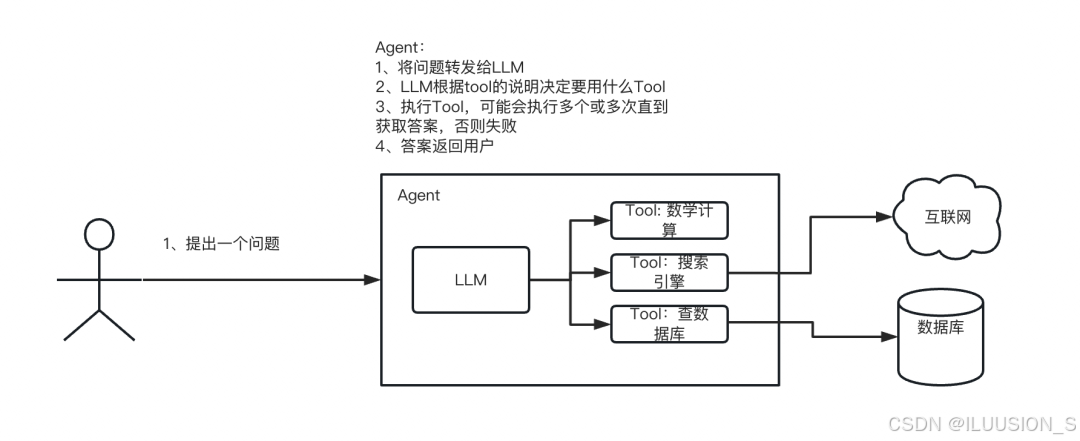
在LangChain中,ReAct框架的实现流程如下:
- 任务:Agent的起点是一个任务,如一个用户查询、一个目标或一个需要解决的特定问题。
- 大模型:任务被输入大模型中。大模型使用训练好的模型进行推理。
- 工具:大模型可能会决定使用一系列的工具来辅助完成任务。
- 行动:Agent根据大模型的推理结果采取行动。
- 环境:行动会影响环境,而环境将以某种形式响应这些行动。
- 结果:将行动导致的结果反馈给Agent。
Agent工具函数
| 创建Agent的工具函数 | |
|---|---|
| create_react_agent | 构建一个基于ReAct思考框架的智能体,只允许有1个参数 |
| create_structured_chat_agent | 构建一个支持多个任务对话处理的智能体,允许有多个参数 |
| create_json_agent | 构建一个支持返回json数据结构的智能体,不管返回得到内容或者接受的参数都支持json结构 |
| create_sql_agent | 构建一个能与SQL数据库交互的智能体,可用于创建一个能够处理SQL任务、自动化数据库操作或提供数据库连接管理的服务或组件 |
| create_openai_functions_agent | 构建一个基于OpenAI functions风格的智能体,能够与OpenAI提供的API函数进行交互 |
| create_tool_calling_agent | 构建一个基于大模型API接口的智能体,能够与OpenAI以外的其他本地或在线大模型的API进行交互【部分本地大模型无法兼容】 |
代码示例
langchain内置的工具函数
# # 获取当前langchian中内置提供的所有Agent工具函数
from langchain_community.agent_toolkits.load_tools import get_all_tool_names
print(get_all_tool_names())
"""
['sleep', 'wolfram-alpha', 'google-search', 'google-search-results-json', 'searx-search-results-json', 'bing-search', 'metaphor-search',
'ddg-search', 'google-books', 'google-lens', 'google-serper', 'google-scholar', 'google-finance', 'google-trends', 'google-jobs', 'google-serper-results-json', 'searchapi', 'searchapi-results-json', 'serpapi',
'dalle-image-generator', 'twilio', 'searx-search', 'merriam-webster', 'wikipedia', 'arxiv', 'golden-query', 'pubmed', 'human', 'awslambda', 'stackexchange', 'sceneXplain', 'graphql', 'openweathermap-api',
'dataforseo-api-search', 'dataforseo-api-search-json', 'eleven_labs_text2speech', 'google_cloud_texttospeech', 'read_file',
'reddit_search', 'news-api', 'tmdb-api', 'podcast-api', 'memorize', 'llm-math', 'open-meteo-api',
'requests', 'requests_get', 'requests_post', 'requests_patch', 'requests_put', 'requests_delete', 'terminal']
"""
官网文档
基于维基百科实现联网搜索Agent
# 运行时报错,让安装,那就装一个呗
pip install wikipedia
# 实例化大模型
import os
# 请求超时,设置以下代理,可以有效减缓超时的情况
# os.environ["http_proxy"] = "http://127.0.0.1:7890"
# os.environ["https_proxy"] = "http://127.0.0.1:7890"
os.environ['DEEPSEEK_API_KEY'] = "sk-e24324xxx"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat")
# 原生调用tools工具
# from langchain_community.tools import WikipediaQueryRun
# from langchain_community.utilities import WikipediaAPIWrapper
# tools = [WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())]
# 通过load_tools工具函数加载wikipedia代理工具
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(['wikipedia'])
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}""")
# 实例化ReAct智能体
# create_react_agent 创建一个ReAct风格智能体
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
# 基于create_react_agent提供的Agent创建代理执行器,只支持使用一个参数
# verbose=True列出大模型执行过程的执行细节
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
response = agent_executor.invoke({"input": "乌克兰现任总统是谁?"})
print(response)
运行这个我一直超时,找了好多解决方法也没用。不知道怎么搞。不用维基百科就是了,我换其他的就是了。烦死了。
解决方法:https://blog.csdn.net/binbinczsohu/article/details/135087296
基于searchapi的Agnet
这个注册后,每月有100次免费搜索次数。
搜索工具的账号注册:https://serpapi.com/search-api
import os
os.environ['SERPAPI_API_KEY'] = 'c6b0xxx'
os.environ['DEEPSEEK_API_KEY'] = "sk-e24xxx"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat")
# 加载所需工具,包括serpapi和llm-math
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(["llm-math", "serpapi"], llm=llm)
# 初始化代理对象,设定代理类型为ZERO_SHOT_REACT_DESCRIPTION,输出详细信息
from langchain.agents import initialize_agent, AgentType
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
handle_parsing_errors=True
)
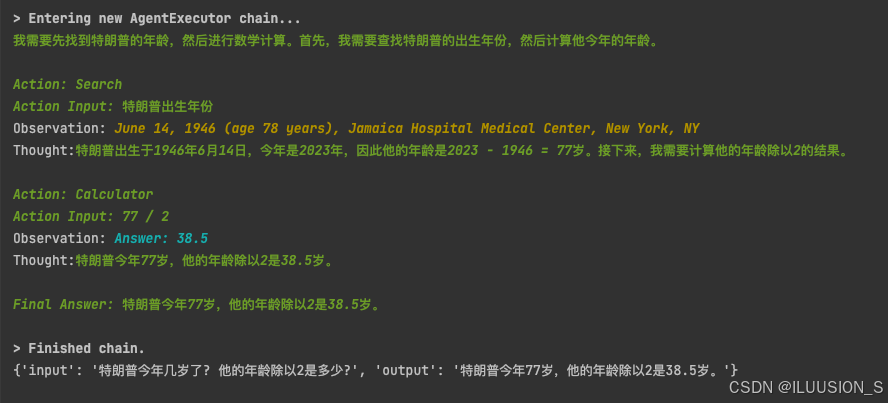
# 运行代理对象,向其提问特朗普的年龄和年龄除以2的结果
response = agent.invoke({"input": "特朗普今年几岁了? 他的年龄除以2是多少?"})
print(response)
这回答还是有点问题,这个是基于deepseek-chat模型回答的,他的训练数据是2023的。所以认为今年是2023年。这个在后面可以自定义获取时间的工具来获取更准确的信息
基于langchain的python执行器
需要安装
pip install langchain_experimental
from langchain.agents import Tool
from langchain_experimental.tools.python.tool import PythonAstREPLTool
# 创建Python解释器
python_repl_tool = PythonAstREPLTool()
# python代码
query_value = """
def add(a,b):
return a+b
print(add(100,200))
"""
# 基本使用
repl_tool = Tool(
name="python_repl",
description="一个Python shell。使用它来执行python命令。输入应该是一个有效的python命令。一个值的输出,应该用`print(...)`打印出来。",
func=python_repl_tool.run,
)
response = repl_tool.invoke(query_value)
print(response)
"""
300
"""
结合searchiapi与python代码执行器完成文件操作
# -*- coding: utf-8 -*-
# @Author : John
# @Time : 2025/03/03
# @File : python解释器.py
import os
os.environ['SERPAPI_API_KEY'] = 'c6b02xx'
os.environ['DEEPSEEK_API_KEY'] = "sk-e2432xxx"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat")
# 加载所需工具
from langchain_community.agent_toolkits.load_tools import load_tools
# python
from langchain.agents import Tool
from langchain_experimental.tools.python.tool import PythonAstREPLTool
python_repl_ast = Tool(
name="python_repl_ast",
description="一个Python shell。使用它来执行python命令。输入应该是一个有效的python命令。一个值的输出,应该用`print(...)`打印出来。",
func=PythonAstREPLTool().run,
)
# allow_dangerous_tools 小心使用,给出创建删除等权限
tools = load_tools(["serpapi"], allow_dangerous_tools=True)
tools += [python_repl_ast]
# 提示词
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}""")
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, handle_parsing_errors=True)
response = agent_executor.invoke(
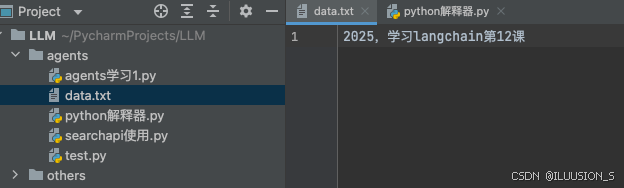
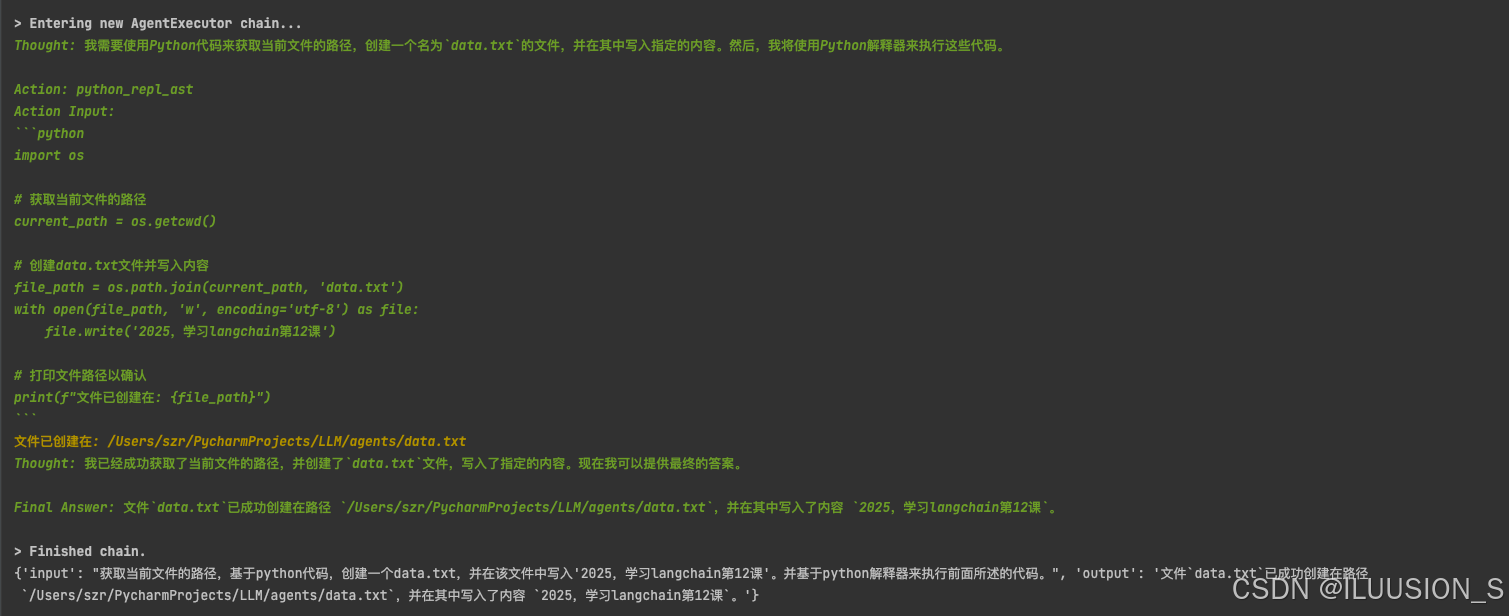
{"input": "获取当前文件的路径,基于python代码,创建一个data.txt,并在该文件中写入'2025,学习langchain第12课'。并基于python解释器来执行前面所述的代码。"})
print(response)
提示词Hub
之前的提示词都是别人写好复制过来的,也可以通过langchain hub拉取提示词。
地址:https://smith.langchain.com/hub
例如之前用到的提示词就是这个
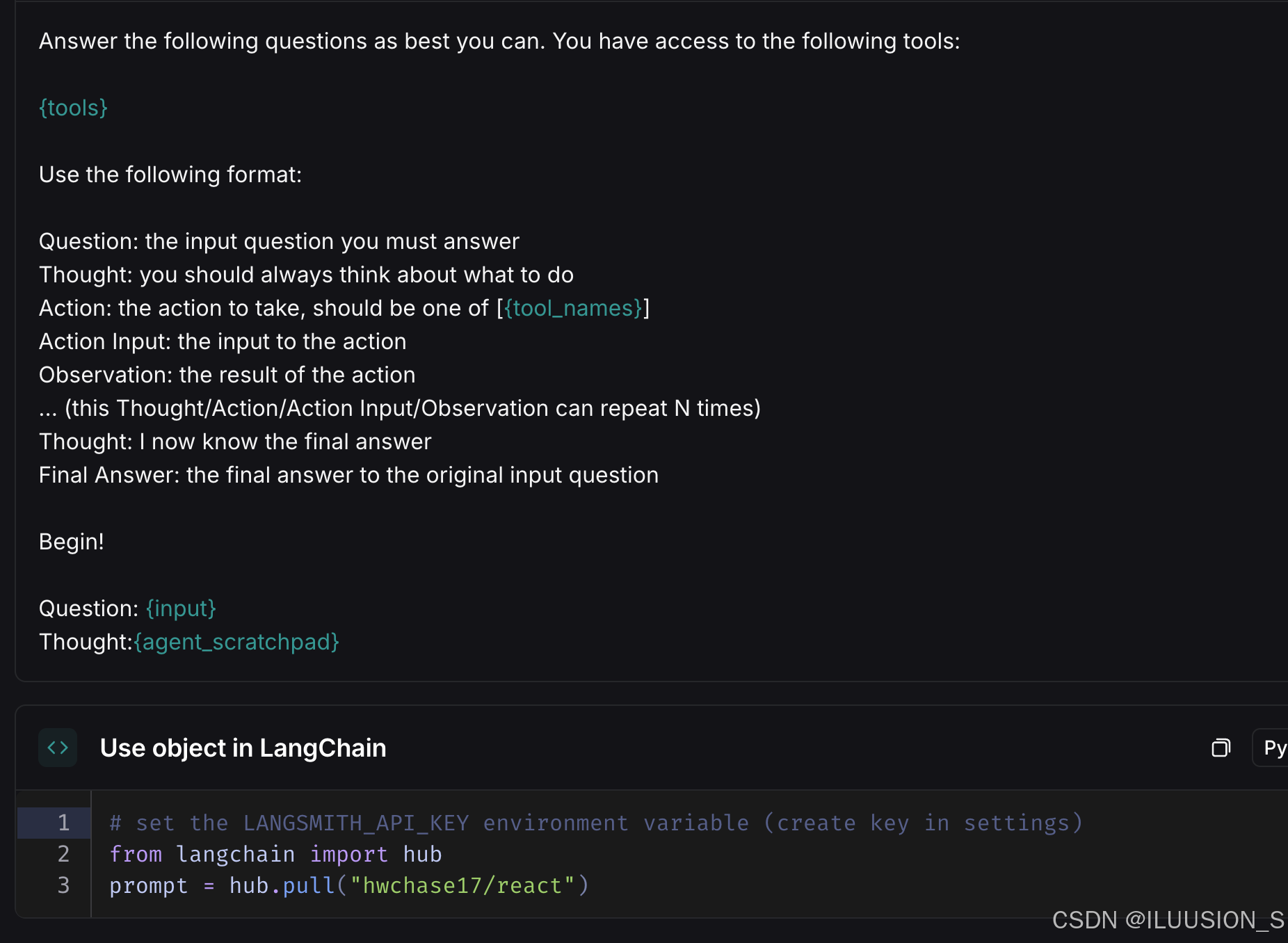
结合searchapi和ChatMessageHistory的对话agent
import os
os.environ['SERPAPI_API_KEY'] = 'c6xxx'
os.environ['DEEPSEEK_API_KEY'] = "sk-e24xxx"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat")
# 加载所需工具
from langchain_community.agent_toolkits.load_tools import load_tools
tools = load_tools(["serpapi"])
# 从 LangChain Hub 中拉取预训练的 ReAct 提示词模板:https://smith.langchain.com/hub/hwchase17/react-chat
from langchain import hub
prompt = hub.pull("hwchase17/react-chat")
# 实例化Agent
from langchain.agents import create_react_agent, AgentExecutor
agent = create_react_agent(llm, tools, prompt)
# 创建Agent执行器
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 创建对话历史管理对象
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
message_history = ChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: message_history,
input_messages_key="input",
history_messages_key="chat_history",
)
while True:
user = input("用户名:")
if user == "exit": break
while True:
query = input("问题:")
if query == "exit": break
response = agent_with_chat_history.invoke(
{"input": query},
config={"configurable": {"session_id": user}},
)
print(response)
第一次问题:
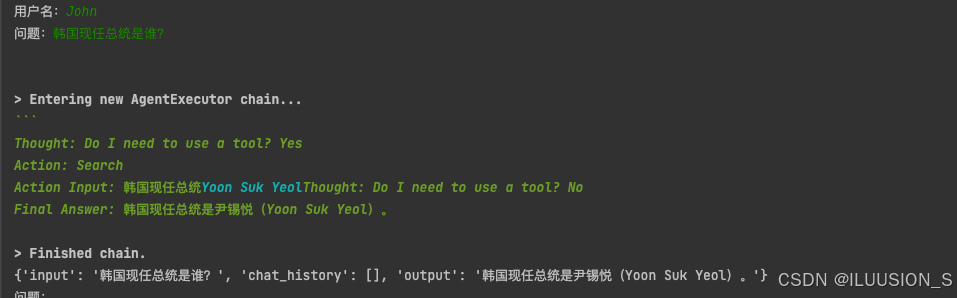
第二次问题:
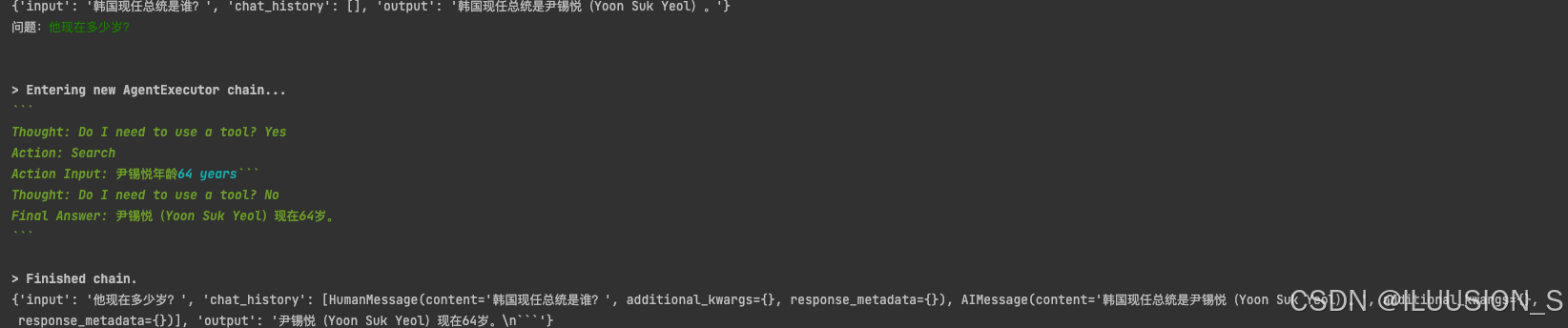
使用Travily Search
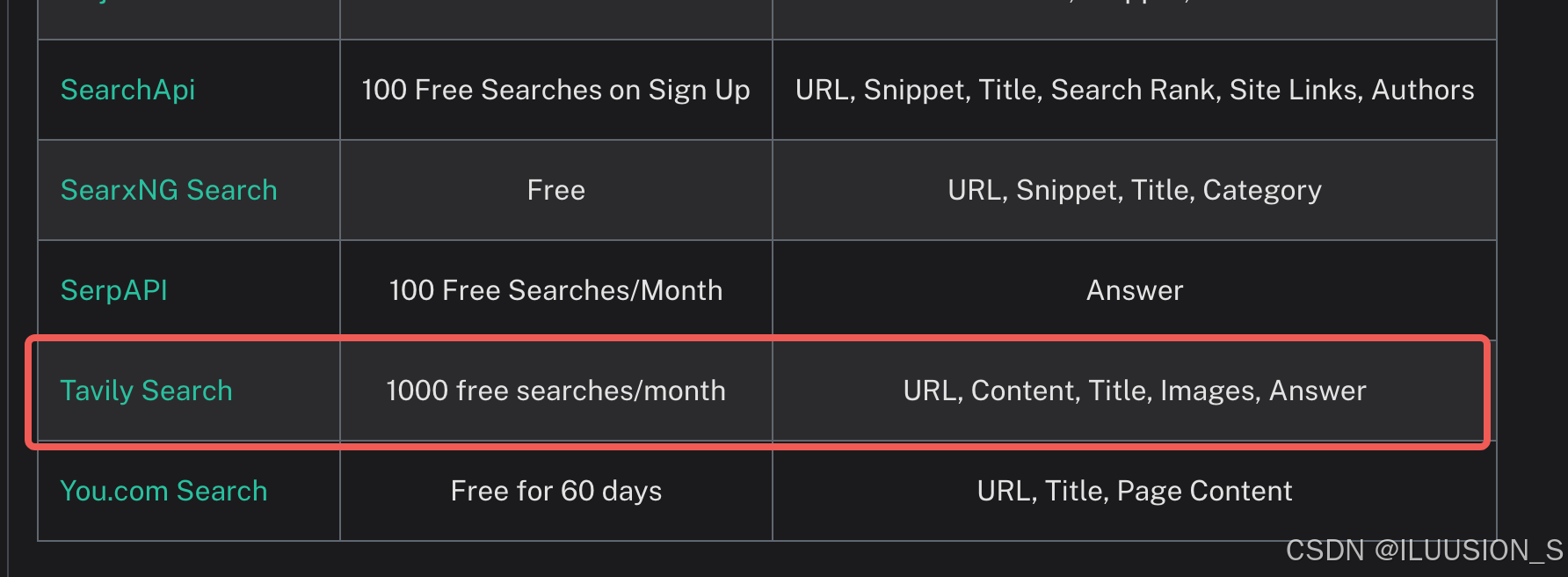
注册
地址:https://tavily.com/
需要安装一个authenticator,扫码。然后验证
基于create_react_agent使用
与之前使用的searchapi没什么区别,只是需要改一些配置
os.environ["TAVILY_API_KEY"] = "tvly-r8wxxx"
os.environ['LANGCHAIN_TRACING_V2'] = 'true' # 固定为'true'
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=1)]
其他一致
基于create_structured_chat_agent构建多任务智能体
import os
os.environ["TAVILY_API_KEY"] = "tvly-dev-8Uxxx"
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['DEEPSEEK_API_KEY'] = "sk-e2432xxx"
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(model="deepseek-chat")
# 加载Agent工具
from langchain_community.tools.tavily_search import TavilySearchResults
tools = [TavilySearchResults(max_results=1)]
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.agents import create_structured_chat_agent, AgentExecutor
def structured_chat(input):
## 提示词
system = '''你需要尽可能地帮助和准确地回答人类的问题。你可以使用以下工具:
{tools}
使用json blob通过提供action key(工具名称)和action_input key(工具输入)来指定工具。
"action"的有效取值为: "Final Answer" or {tool_names}
每个$JSON_BLOB只提供一个action,如下所示:
{{
"action": $TOOL_NAME,
"action_input": $INPUT
}}
```
遵循此格式:
Question: 用户输入的问题
Thought: 回答这个问题我需要做些什么,尽可能考虑前面和后面的步骤
Action: 回答问题所选取的工具
```
$JSON_BLOB
```
Observation: 工具返回的结果
... (这个思考/行动/行动输入/观察可以重复N次)
Thought: 我现在知道最终答案
Action: 工具返回的结果信息
```
{{
"action": "Final Answer",
"action_input": "原始输入问题的最终答案"
}}
```
开始!提醒始终使用单个操作的有效json blob进行响应。必要时使用工具. 如果合适,直接回应。格式是Action:“$JSON_BLOB”然后是Observation'''
human = '''{input}
{agent_scratchpad}
(提醒:无论如何都要在JSON blob中响应!)'''
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
MessagesPlaceholder("chat_history", optional=True),
("human", human),
]
)
agent = create_structured_chat_agent(llm=llm, tools=tools, prompt=prompt)
print(agent)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True,
handle_parsing_errors=True)
inputs = {"input": input}
response = agent_executor.invoke(inputs)
return response.get("output")
response = structured_chat("2025年中国除夕档的电影,最受欢迎的是哪些,请按票房排名输出,大的在前?")
print(response)
自定义工具函数
基于basetool自定义获取时间工具
https://docs.tavily.com/sdk/python/get-started
在之前create_structured_chat_agent稍加两行代码,增加一个获取时间的tool,让agent
import time
from langchain_core.tools import BaseTool
class Get_Time(BaseTool):
name: str = "get_time"
description: str = """获取当前时间"""
def _run(self) -> str:
"""调用工具"""
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
# 把获取时间的tool加载到tools
tools = [TavilySearchResults(max_results=1), Get_Time()]
...
# 提问
response = structured_chat("今年是公元多少年,现在的美国总统是谁?")
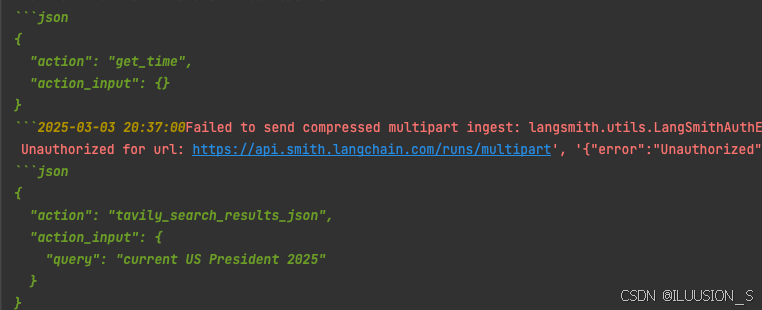
可以看到,使用了get_time来获取了当前时间,再使用当前时间去tavily查询获得结果。
基于tool装饰器构建工具
# 与上面很类似,只需改成如下即可
from langchain_core.tools import tool
@tool("get_time_func")
def get_time():
"""返回当前时间"""
return time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
tools = [TavilySearchResults(max_results=1), get_time]
...
# 提问
response = structured_chat("今年是公元多少年,现在的日本首相是谁?")
print(response)
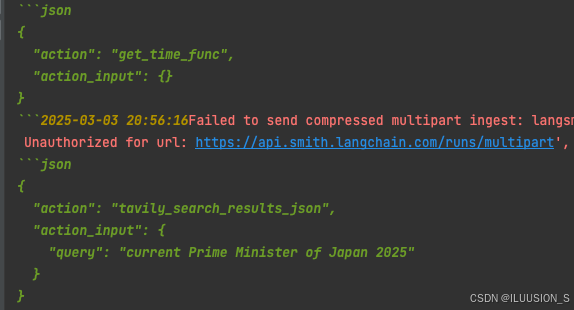
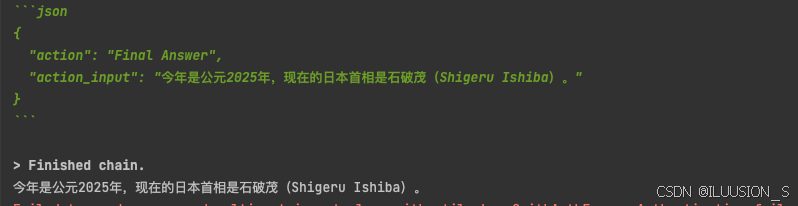
LangSmith
运行一直报警告,让弄langsmith,我这强迫症,就去弄了一下,然后就没有警告了。
具体操作可以参考下面这个
https://blog.csdn.net/qq_74929891/article/details/145007527