使用Spring Boot构建数据访问层
06 基础规范:如何理解 JDBC 关系型数据库访问规范?
从今天开始,我们将进入 Spring Boot 另一个核心技术体系的讨论,即数据访问技术体系。无论是互联网应用还是传统软件,对于任何一个系统而言,数据的存储和访问都是不可缺少的。
数据访问层的构建可能会涉及多种不同形式的数据存储媒介,本课程关注的是最基础也是最常用的数据存储媒介,即关系型数据库,针对关系型数据库,Java 中应用最广泛的就是 JDBC 规范,今天我们将对这个经典规范展开讨论。
JDBC 是 Java Database Connectivity 的全称,它的设计初衷是提供一套能够应用于各种数据库的统一标准,这套标准需要不同数据库厂家之间共同遵守,并提供各自的实现方案供 JDBC 应用程序调用。
作为一套统一标准,JDBC 规范具备完整的架构体系,如下图所示:
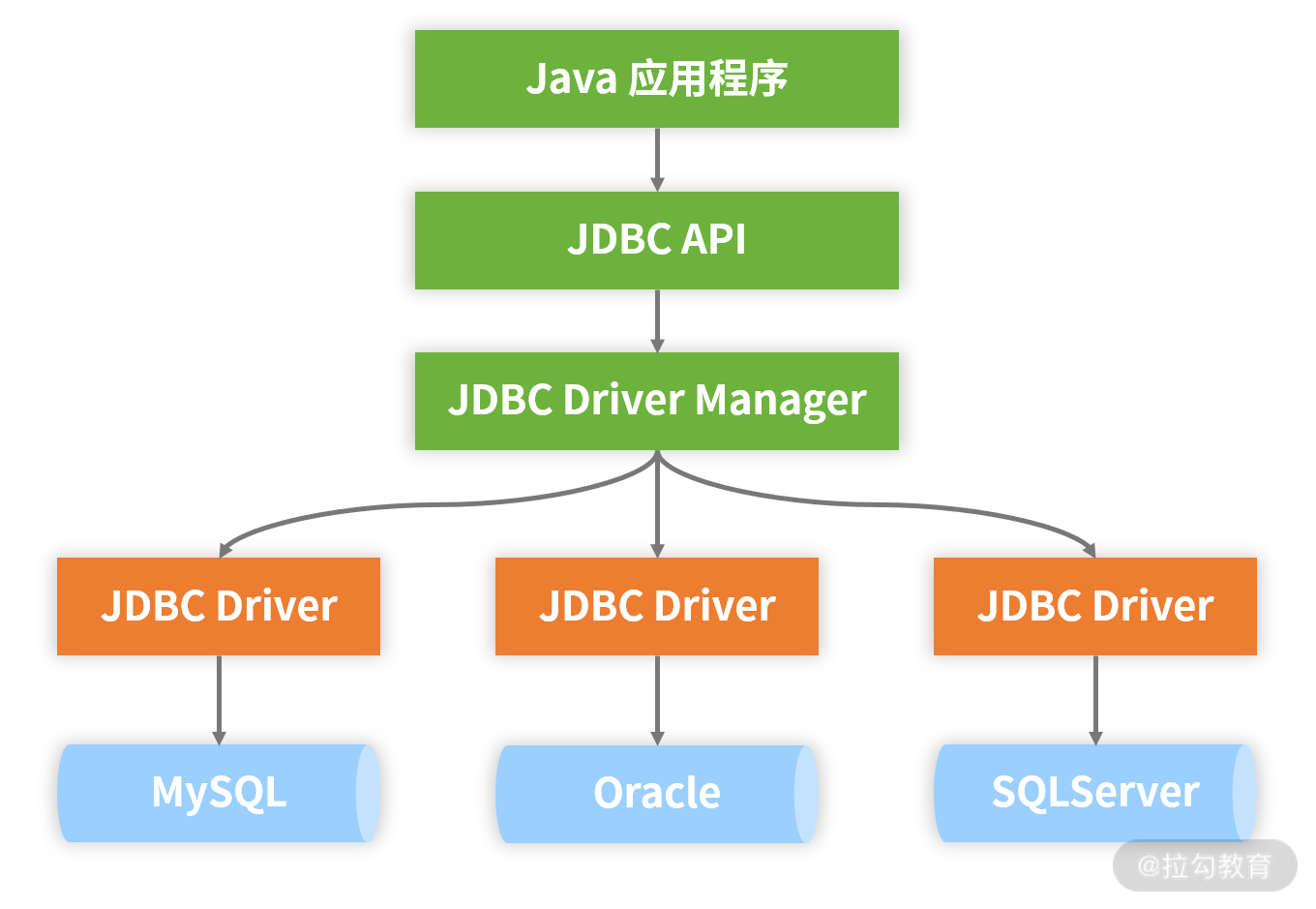
JDBC 规范整体架构图
从上图中可以看到,Java 应用程序通过 JDBC 所提供的 API 进行数据访问,而这些 API 中包含了开发人员所需要掌握的各个核心编程对象,下面我们一起来看下。
JDBC 规范中有哪些核心编程对象?
对于日常开发而言,JDBC 规范中的核心编程对象包括 DriverManger、DataSource、Connection、Statement,及 ResultSet。
DriverManager
正如前面的 JDBC 规范整体架构图中所示,JDBC 中的 DriverManager 主要负责加载各种不同的驱动程序(Driver),并根据不同的请求向应用程序返回相应的数据库连接(Connection),应用程序再通过调用 JDBC API 实现对数据库的操作。
JDBC 中的 Driver 定义如下,其中最重要的是第一个获取 Connection 的 connect 方法:
public interface Driver {//获取数据库连接Connection connect(String url, java.util.Properties info)throws SQLException;boolean acceptsURL(String url) throws SQLException;DriverPropertyInfo[] getPropertyInfo(String url, java.util.Properties info)throws SQLException;int getMajorVersion();int getMinorVersion();boolean jdbcCompliant();public Logger getParentLogger() throws SQLFeatureNotSupportedException;
}
针对 Driver 接口,不同的数据库供应商分别提供了自身的实现方案。例如,MySQL 中的 Driver 实现类如下代码所示:
public class Driver extends NonRegisteringDriver implements java.sql.Driver {// 通过 DriverManager 注册 Driverstatic {try {java.sql.DriverManager.registerDriver(new Driver());} catch (SQLException E) {throw new RuntimeException("Can't register driver!");}}…
}
这里就使用用了 DriverManager,而 DriverManager 除提供了上述用于注册 Driver 的 registerDriver 方法之外,还提供了 getConnection 方法用于针对具体的 Driver 获取 Connection 对象。
DataSource
通过前面的介绍,我们知道在 JDBC 规范中可直接通过 DriverManager 获取 Connection,我们也知道获取 Connection 的过程需要建立与数据库之间的连接,而这个过程会产生较大的系统开销。
为了提高性能,通常我们首先会建立一个中间层将 DriverManager 生成的 Connection 存放到连接池中,再从池中获取 Connection。
而我们可以认为 DataSource 就是这样一个中间层,它作为 DriverManager 的替代品而推出,是获取数据库连接的首选方法。
DataSource 在 JDBC 规范中代表的是一种数据源,核心作用是获取数据库连接对象 Connection。在日常开发过程中,我们通常会基于 DataSource 获取 Connection。DataSource 接口的定义如下代码所示:
public interface DataSource extends CommonDataSource, Wrapper {Connection getConnection() throws SQLException;Connection getConnection(String username, String password)throws SQLException;
}
从上面我们可以看到,DataSource 接口提供了两个获取 Connection 的重载方法,并继承了 CommonDataSource 接口。CommonDataSource 是 JDBC 中关于数据源定义的根接口,除了 DataSource 接口之外,它还有另外两个子接口,如下图所示:
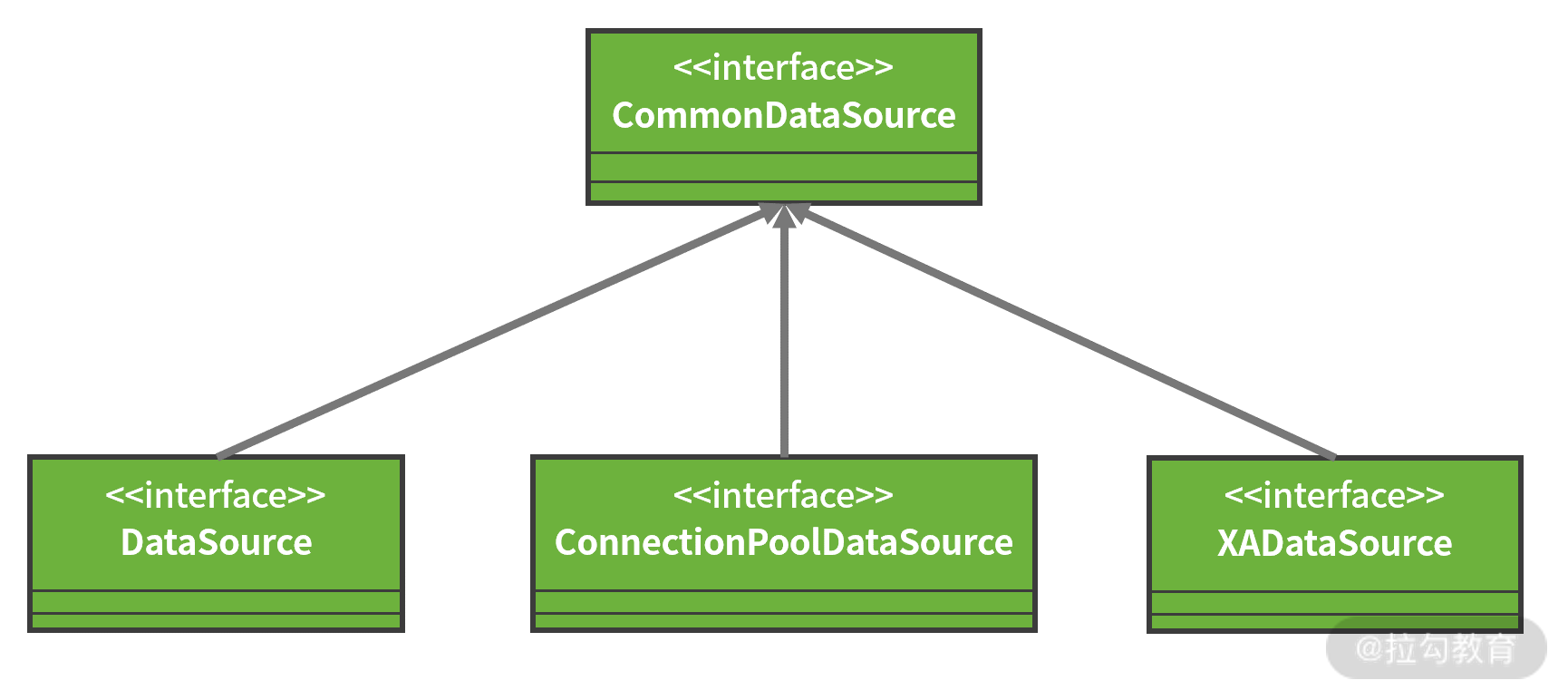
DataSource 类层结构图
其中,DataSource 是官方定义的获取 Connection 的基础接口,XADataSource 用来在分布式事务环境下实现 Connection 的获取,而 ConnectionPoolDataSource 是从连接池 ConnectionPool 中获取 Connection 的接口。
所谓的 ConnectionPool 相当于预先生成一批 Connection 并存放在池中,从而提升 Connection 获取的效率。
请注意 DataSource 接口同时还继承了一个 Wrapper 接口。从接口的命名上看,我们可以判断该接口起到一种包装器的作用。事实上,因为很多数据库供应商提供了超越标准 JDBC API 的扩展功能,所以 Wrapper 接口可以把一个由第三方供应商提供的、非 JDBC 标准的接口包装成标准接口。
以 DataSource 接口为例,如果我们想自己实现一个定制化的数据源类 MyDataSource,就可以提供一个实现了 Wrapper 接口的 MyDataSourceWrapper 类来完成包装和适配,如下图所示:
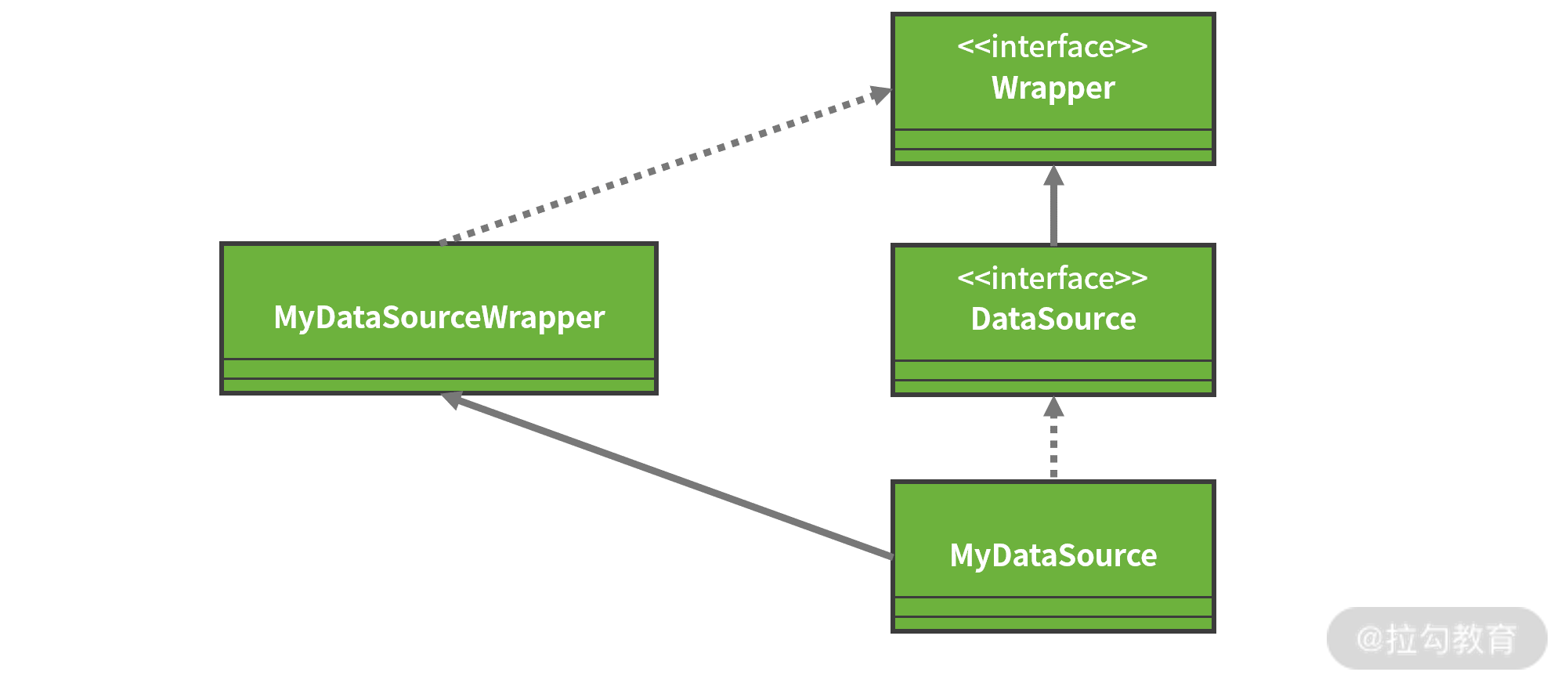
通过 Wrapper 接口扩展 JDBC 规范示意图
在 JDBC 规范中,除了 DataSource 之外,Connection、Statement、ResultSet 等核心对象也都继承了这个 Wrapper 接口。
作为一种基础组件,它同样不需要开发人员自己实现 DataSource,因为业界已经存在了很多优秀的实现方案,如 DBCP、C3P0 和 Druid 等。
例如 Druid 提供了 DruidDataSource,它不仅提供了连接池的功能,还提供了诸如监控等其他功能,它的类层结构如下图所示:
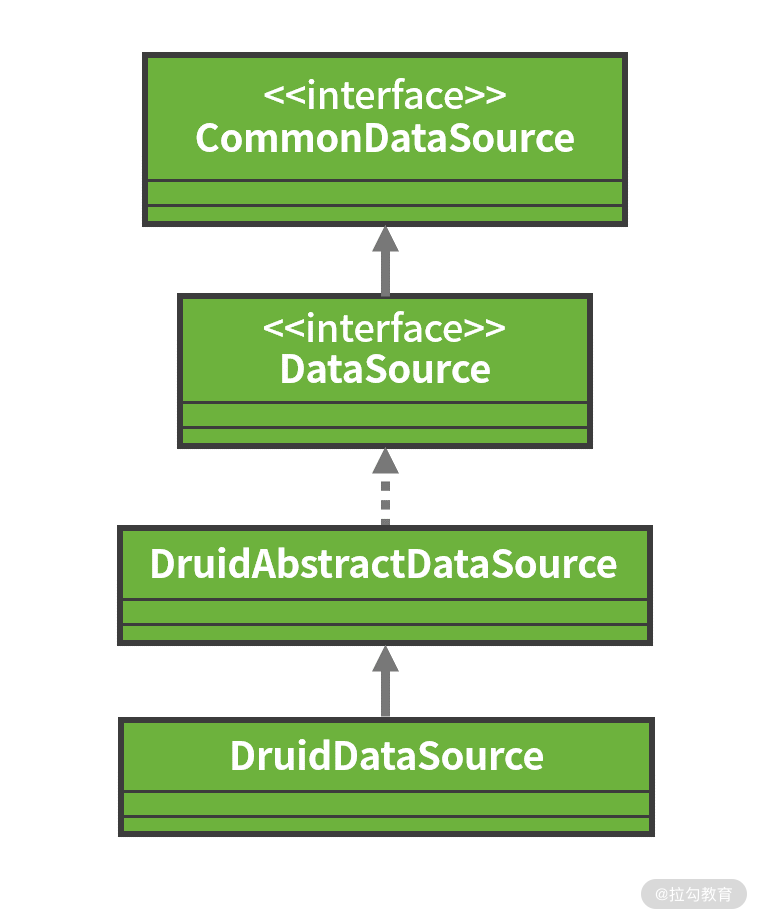
DruidDataSource 的类层结构
Connection
DataSource 的目的是获取 Connection 对象。我们可以把 Connection 理解为一种会话(Session)机制,Connection 代表一个数据库连接,负责完成与数据库之间的通信。
所有 SQL 的执行都是在某个特定 Connection 环境中进行的,同时它还提供了一组重载方法分别用于创建 Statement 和 PreparedStatement。另一方面,Connection 也涉及事务相关的操作。
Connection 接口中定义的方法很丰富,其中最核心的几个方法如下代码所示:
public interface Connection extends Wrapper, AutoCloseable {//创建 StatementStatement createStatement() throws SQLException;//创建 PreparedStatementPreparedStatement prepareStatement(String sql) throws SQLException;//提交void commit() throws SQLException;//回滚void rollback() throws SQLException;//关闭连接void close() throws SQLException;
}
这里涉及具体负责执行 SQL 语句的 Statement 和 PreparedStatement 对象,我们接着往下看。
Statement/PreparedStatement
JDBC 规范中的 Statement 存在两种类型,一种是普通的 Statement,一种是支持预编译的 PreparedStatement。
所谓预编译,是指数据库的编译器会对 SQL 语句提前编译,然后将预编译的结果缓存到数据库中,下次执行时就可以通过替换参数并直接使用编译过的语句,从而大大提高 SQL 的执行效率。
当然,这种预编译也需要一定成本,因此在日常开发中,如果对数据库只执行一次性读写操作时,用 Statement 对象进行处理会比较合适;而涉及 SQL 语句的多次执行时,我们可以使用 PreparedStatement。
如果需要查询数据库中的数据,我们只需要调用 Statement 或 PreparedStatement 对象的 executeQuery 方法即可。
这个方法以 SQL 语句作为参数,执行完后返回一个 JDBC 的 ResultSet 对象。当然,Statement 或 PreparedStatement 还提供了一大批执行 SQL 更新和查询的重载方法,我们无意一一展开。
以 Statement 为例,它的核心方法如下代码所示:
public interface Statement extends Wrapper, AutoCloseable {//执行查询语句ResultSet executeQuery(String sql) throws SQLException; //执行更新语句int executeUpdate(String sql) throws SQLException; //执行 SQL 语句boolean execute(String sql) throws SQLException; //执行批处理int[] executeBatch() throws SQLException;
}
这里我们同样引出了 JDBC 规范中最后一个核心编程对象,即代表执行结果的 ResultSet。
ResultSet
一旦我们通过 Statement 或 PreparedStatement 执行了 SQL 语句并获得了 ResultSet 对象,就可以使用该对象中定义的一大批用于获取 SQL 执行结果值的工具方法,如下代码所示:
public interface ResultSet extends Wrapper, AutoCloseable {//获取下一个结果boolean next() throws SQLException;//获取某一个类型的结果值Value getXXX(int columnIndex) throws SQLException;...
}
ResultSet 提供了 next() 方法便于开发人员实现对整个结果集的遍历。如果 next() 方法返回为 true,意味着结果集中存在数据,可以调用 ResultSet 对象的一系列 getXXX() 方法来取得对应的结果值。
如何使用 JDBC 规范访问数据库?
对于开发人员而言,JDBC API 是我们访问数据库的主要途径,如果我们使用 JDBC 开发一个访问数据库的执行流程,常见的代码风格如下所示(省略了异常处理):
// 创建池化的数据源
PooledDataSource dataSource = new PooledDataSource ();// 设置 MySQL Driver
dataSource.setDriver ("com.mysql.jdbc.Driver");// 设置数据库 URL、用户名和密码
dataSource.setUrl ("jdbc:mysql://localhost:3306/test");
dataSource.setUsername("root");
dataSource.setPassword("root");// 获取连接
Connection connection = dataSource.getConnection();// 执行查询
PreparedStatement statement = connection.prepareStatement ("select * from user");// 获取查询结果进行处理
ResultSet resultSet = statement.executeQuery();while (resultSet.next()) {...
}// 关闭资源
statement.close();
resultSet.close();
connection.close();
这段代码中完成了对基于前面介绍的 JDBC API 中的各个核心编程对象的数据访问。上述代码主要面向查询场景,而针对用于插入数据的处理场景,我们只需要在上述代码中替换几行代码,即将“执行查询”和“获取查询结果进行处理”部分的查询操作代码替换为插入操作代码就行。
最后,我们梳理一下基于 JDBC 规范进行数据库访问的整个开发流程,如下图所示:
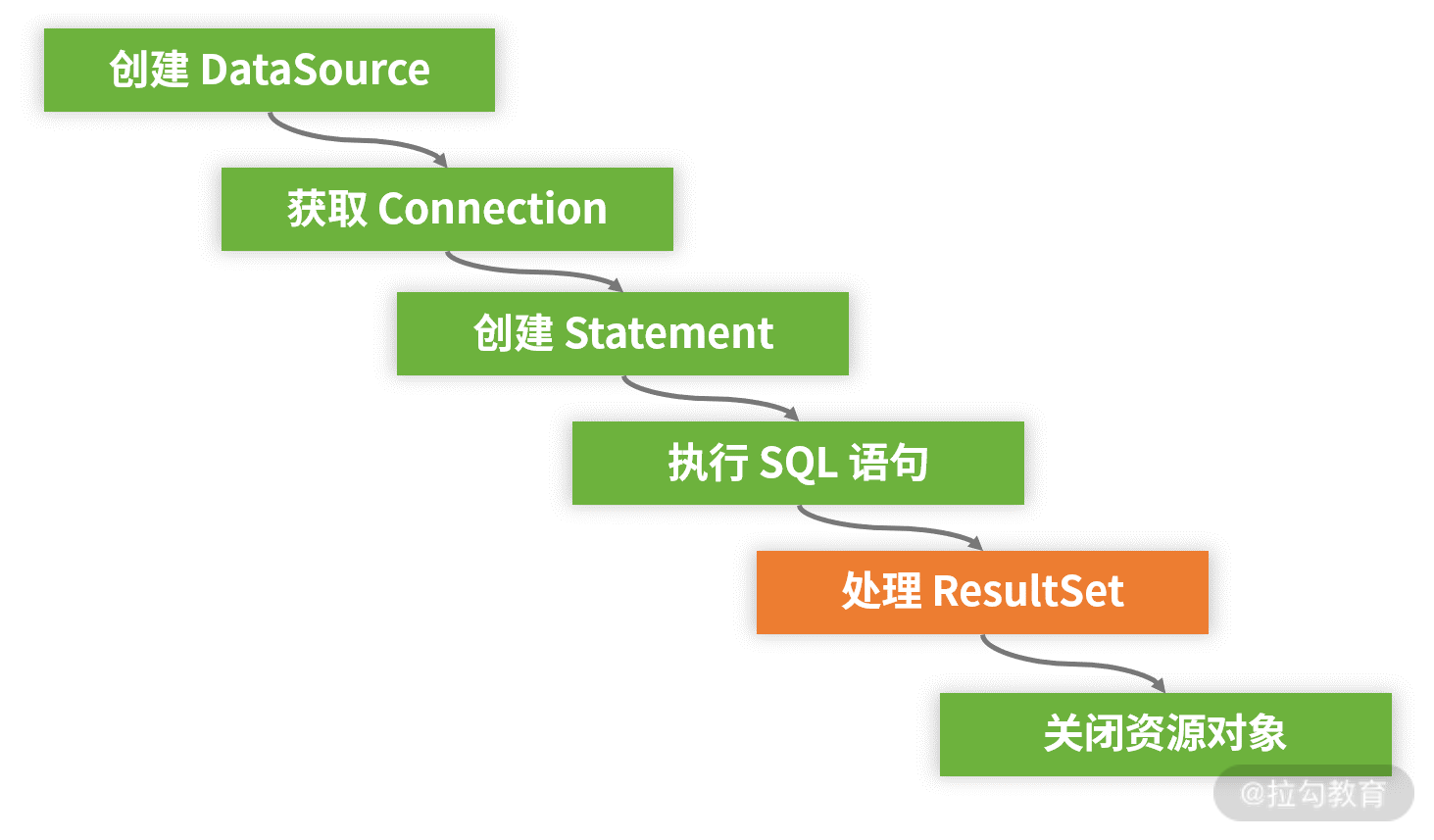
基于 JDBC 规范进行数据库访问的开发流程图
针对前面所介绍的代码示例,我们明确地将基于 JDBC 规范访问关系型数据库的操作分成两大部分:一部分是准备和释放资源以及执行 SQL 语句,另一部分则是处理 SQL 执行结果。
而对于任何数据访问而言,前者实际上都是重复的。在上图所示的整个开发流程中,事实上只有“处理 ResultSet ”部分的代码需要开发人员根据具体的业务对象进行定制化处理。这种抽象为整个执行过程提供了优化空间。诸如 Spring 框架中 JdbcTemplate 这样的模板工具类就应运而生了,我们会在 07 讲中会详细介绍这个模板工具类。
小结与预告
JDBC 规范是 Java EE 领域中进行数据库访问的标准规范,在业界应用非常广泛。今天的课程中,我们分析了该规范的核心编程对象,并梳理了使用 JDBC 规范访问数据库的开发流程。希望你能熟练掌握这部分知识,因为熟练掌握 JDBC 规范是我们理解后续内容的基础。
07 数据访问:如何使用 JdbcTemplate 访问关系型数据库?
06 讲我们详细介绍了 JDBC 规范的相关内容,JDBC 规范是 Java 领域中使用最广泛的数据访问标准,目前市面上主流的数据访问框架都是构建在 JDBC 规范之上。
因为 JDBC 是偏底层的操作规范,所以关于如何使用 JDBC 规范进行关系型数据访问的实现方式有很多(区别在于对 JDBC 规范的封装程度不同),而在 Spring 中,同样提供了 JdbcTemplate 模板工具类实现数据访问,它简化了 JDBC 规范的使用方法,今天我们将围绕这个模板类展开讨论。
数据模型和 Repository 层设计
引入 JdbcTemplate 模板工具类之前,我们回到 SpringCSS 案例,先给出 order-service 中的数据模型为本讲内容的展开做一些铺垫。
我们知道一个订单中往往涉及一个或多个商品,所以在本案例中,我们主要通过一对多的关系来展示数据库设计和实现方面的技巧。而为了使描述更简单,我们把具体的业务字段做了简化。Order 类的定义如下代码所示:
public class Order{private Long id; //订单Idprivate String orderNumber; //订单编号private String deliveryAddress; //物流地址private List<Goods> goodsList; //商品列表//省略了 getter/setter
}
其中代表商品的 Goods 类定义如下:
public class Goods {private Long id; //商品Idprivate String goodsCode; //商品编号private String goodsName; //商品名称private Double price; //商品价格//省略了 getter/setter
}
从以上代码,我们不难看出一个订单可以包含多个商品,因此设计关系型数据库表时,我们首先会构建一个中间表来保存 Order 和 Goods 这层一对多关系。在本课程中,我们使用 MySQL 作为关系型数据库,对应的数据库 Schema 定义如下代码所示:
DROP TABLE IF EXISTS `order`;
DROP TABLE IF EXISTS `goods`;
DROP TABLE IF EXISTS `order_goods`;create table `order` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`order_number` varchar(50) not null,`delivery_address` varchar(100) not null,`create_time` timestamp not null DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`)
);create table `goods` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`goods_code` varchar(50) not null,`goods_name` varchar(50) not null,`goods_price` double not null,`create_time` timestamp not null DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`)
);create table `order_goods` (`order_id` bigint(20) not null,`goods_id` bigint(20) not null,foreign key(`order_id`) references `order`(`id`),foreign key(`goods_id`) references `goods`(`id`)
);
基于以上数据模型,我们将完成 order-server 中的 Repository 层组件的设计和实现。首先,我们需要设计一个 OrderRepository 接口,用来抽象数据库访问的入口,如下代码所示:
public interface OrderRepository {Order addOrder(Order order);Order getOrderById(Long orderId);Order getOrderDetailByOrderNumber(String orderNumber);
}
这个接口非常简单,方法都是自解释的。不过请注意,这里的 OrderRepository 并没有继承任何父接口,完全是一个自定义的、独立的 Repository。
针对上述 OrderRepository 中的接口定义,我们将构建一系列的实现类。
- OrderRawJdbcRepository:使用原生 JDBC 进行数据库访问
- OrderJdbcRepository:使用 JdbcTemplate 进行数据库访问
- OrderJpaRepository:使用 Spring Data JPA 进行数据库访问
上述实现类中的 OrderJpaRepository 我们会放到 10 讲《ORM 集成:如何使用 Spring Data JPA 访问关系型数据库?》中进行展开,而 OrderRawJdbcRepository 最基础,不是本课程的重点,因此 07 讲我们只针对 OrderRepository 中 getOrderById 方法的实现过程重点介绍,也算是对 06 讲的回顾和扩展。
OrderRawJdbcRepository 类中实现方法如下代码所示:
@Repository("orderRawJdbcRepository")
public class OrderRawJdbcRepository implements OrderRepository {@Autowiredprivate DataSource dataSource;@Overridepublic Order getOrderById(Long orderId) {Connection connection = null;PreparedStatement statement = null;ResultSet resultSet = null;try {connection = dataSource.getConnection();statement = connection.prepareStatement("select id, order_number, delivery_address from `order` where id=?");statement.setLong(1, orderId);resultSet = statement.executeQuery();Order order = null;if (resultSet.next()) {order = new Order(resultSet.getLong("id"), resultSet.getString("order_number"),resultSet.getString("delivery_address"));}return order;} catch (SQLException e) {System.out.print(e);} finally {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {}}if (statement != null) {try {statement.close();} catch (SQLException e) {}}if (connection != null) {try {connection.close();} catch (SQLException e) {}}}return null;}//省略其他 OrderRepository 接口方法实现
}
这里,值得注意的是,我们首先需要在类定义上添加 @Repository 注解,标明这是能够被 Spring 容器自动扫描的 Javabean,再在 @Repository 注解中指定这个 Javabean 的名称为”orderRawJdbcRepository”,方便 Service 层中根据该名称注入 OrderRawJdbcRepository 类。
可以看到,上述代码使用了 JDBC 原生 DataSource、Connection、PreparedStatement、ResultSet 等核心编程对象完成针对“order”表的一次查询。代码流程看起来比较简单,其实也比较烦琐,学到这里,我们可以结合上一课时的内容理解上述代码。
请注意,如果我们想运行这些代码,千万别忘了在 Spring Boot 的配置文件中添加对 DataSource 的定义,如下代码所示:
spring:datasource:driver-class-name: com.mysql.cj.jdbc.Driverurl: jdbc:mysql://127.0.0.1:3306/appointmentusername: rootpassword: root
回顾完原生 JDBC 的使用方法,接下来就引出今天的重点,即 JdbcTemplate 模板工具类,我们来看看它如何简化数据访问操作。
使用 JdbcTemplate 操作数据库
要想在应用程序中使用 JdbcTemplate,首先我们需要引入对它的依赖,如下代码所示:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
JdbcTemplate 提供了一系列的 query、update、execute 重载方法应对数据的 CRUD 操作。
使用 JdbcTemplate 实现查询
基于 SpringCSS 案例,我们先来讨论一下最简单的查询操作,并对 OrderRawJdbcRepository 中的 getOrderById 方法进行重构。为此,我们构建了一个新的 OrderJdbcRepository 类并同样实现了 OrderRepository 接口,如下代码所示:
@Repository("orderJdbcRepository")
public class OrderJdbcRepository implements OrderRepository {private JdbcTemplate jdbcTemplate;@Autowiredpublic OrderJdbcRepository(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}
}
可以看到,这里通过构造函数注入了 JdbcTemplate 模板类。
而 OrderJdbcRepository 的 getOrderById 方法实现过程如下代码所示:
@Override
public Order getOrderById(Long orderId) {Order order = jdbcTemplate.queryForObject("select id, order_number, delivery_address from `order` where id=?",this::mapRowToOrder, orderId);return order;
}
显然,这里使用了 JdbcTemplate 的 queryForObject 方法执行查询操作,该方法传入目标 SQL、参数以及一个 RowMapper 对象。其中 RowMapper 定义如下:
public interface RowMapper<T> {T mapRow(ResultSet rs, int rowNum) throws SQLException;
}
从 mapRow 方法定义中,我们不难看出 RowMapper 的作用就是处理来自 ResultSet 中的每一行数据,并将来自数据库中的数据映射成领域对象。例如,使用 getOrderById 中用到的 mapRowToOrder 方法完成对 Order 对象的映射,如下代码所示:
private Order mapRowToOrder(ResultSet rs, int rowNum) throws SQLException {return new Order(rs.getLong("id"), rs.getString("order_number"), rs.getString("delivery_address"));
}
讲到这里,你可能注意到 getOrderById 方法实际上只是获取了 Order 对象中的订单部分信息,并不包含商品数据。
接下来,我们再来设计一个 getOrderDetailByOrderNumber 方法,根据订单编号获取订单以及订单中所包含的所有商品信息,如下代码所示:
@Override
public Order getOrderDetailByOrderNumber(String orderNumber) {//获取 Order 基础信息Order order = jdbcTemplate.queryForObject("select id, order_number, delivery_address from `order` where order_number=?", this::mapRowToOrder,orderNumber);if (order == null)return order;//获取 Order 与 Goods 之间的关联关系,找到给 Order 中的所有 GoodsIdLong orderId = order.getId();List<Long> goodsIds = jdbcTemplate.query("select order_id, goods_id from order_goods where order_id=?",new ResultSetExtractor<List<Long>>() {public List<Long> extractData(ResultSet rs) throws SQLException, DataAccessException {List<Long> list = new ArrayList<Long>();while (rs.next()) {list.add(rs.getLong("goods_id"));}return list;}}, orderId);//根据 GoodsId 分别获取 Goods 信息并填充到 Order 对象中for (Long goodsId : goodsIds) {Goods goods = getGoodsById(goodsId);order.addGoods(goods);}return order;
}
上述代码有点复杂,我们分成几个部分来讲解。
首先,我们获取 Order 基础信息,并通过 Order 中的 Id 编号从中间表中获取所有 Goods 的 Id 列表,通过遍历这个 Id 列表再分别获取 Goods 信息,最后将 Goods 信息填充到 Order 中,从而构建一个完整的 Order 对象。
这里通过 Id 获取 Goods 数据的实现方法也与 getOrderById 方法的实现过程一样,如下代码所示:
private Goods getGoodsById(Long goodsId) {return jdbcTemplate.queryForObject("select id, goods_code, goods_name, price from goods where id=?",this::mapRowToGoods, goodsId);
}private Goods mapRowToGoods(ResultSet rs, int rowNum) throws SQLException {return new Goods(rs.getLong("id"), rs.getString("goods_code"), rs.getString("goods_name"),rs.getDouble("price"));
}
使用 JdbcTemplate 实现插入
在 JdbcTemplate 中,我们可以通过 update 方法实现数据的插入和更新。针对 Order 和 Goods 中的关联关系,插入一个 Order 对象需要同时完成两张表的更新,即 order 表和 order_goods 表,因此插入 Order 的实现过程也分成两个阶段,如下代码所示的 addOrderWithJdbcTemplate 方法展示了这一过程:
private Order addOrderDetailWithJdbcTemplate(Order order) {//插入 Order 基础信息Long orderId = saveOrderWithJdbcTemplate(order);order.setId(orderId);//插入 Order 与 Goods 的对应关系List<Goods> goodsList = order.getGoods();for (Goods goods : goodsList) {saveGoodsToOrderWithJdbcTemplate(goods, orderId);}return order;
}
可以看到,这里同样先是插入 Order 的基础信息,然后再遍历 Order 中的 Goods 列表并逐条进行插入。其中的 saveOrderWithJdbcTemplate 方法如下代码所示:
private Long saveOrderWithJdbcTemplate(Order order) {PreparedStatementCreator psc = new PreparedStatementCreator() {@Overridepublic PreparedStatement createPreparedStatement(Connection con) throws SQLException {PreparedStatement ps = con.prepareStatement("insert into `order` (order_number, delivery_address) values (?, ?)",Statement.RETURN_GENERATED_KEYS);ps.setString(1, order.getOrderNumber());ps.setString(2, order.getDeliveryAddress());return ps;}};KeyHolder keyHolder = new GeneratedKeyHolder();jdbcTemplate.update(psc, keyHolder);return keyHolder.getKey().longValue();
}
上述 saveOrderWithJdbcTemplate 的方法比想象中要复杂,主要原因在于我们需要在插入 order 表的同时返回数据库中所生成的自增主键,因此,这里使用了 PreparedStatementCreator 工具类封装 PreparedStatement 对象的构建过程,并在 PreparedStatement 的创建过程中设置了 Statement.RETURN_GENERATED_KEYS 用于返回自增主键。然后我们构建了一个 GeneratedKeyHolder 对象用于保存所返回的自增主键。这是使用 JdbcTemplate 实现带有自增主键数据插入的一种标准做法,你可以参考这一做法并应用到日常开发过程中。
至于用于插入 Order 与 Goods 关联关系的 saveGoodsToOrderWithJdbcTemplate 方法就比较简单了,直接调用 JdbcTemplate 的 update 方法插入数据即可,如下代码所示:
private void saveGoodsToOrderWithJdbcTemplate(Goods goods, long orderId) {jdbcTemplate.update("insert into order_goods (order_id, goods_id) " + "values (?, ?)", orderId, goods.getId());
}
接下来,我们需要实现插入 Order 的整个流程,先实现 Service 类和 Controller 类,如下代码所示:
@Service
public class OrderService {@Autowired@Qualifier("orderJdbcRepository")private OrderRepository orderRepository;public Order addOrder(Order order) {return orderRepository.addOrder(order);}
}@RestController
@RequestMapping(value="orders")
public class OrderController {@RequestMapping(value = "", method = RequestMethod.POST)public Order addOrder(@RequestBody Order order) {Order result = orderService.addOrder(order);return result;}
}
这两个类都是直接对 orderJdbcRepository 中的方法进行封装调用,操作非常简单。然后,我们打开 Postman,并在请求消息体中输入如下内容:
{"orderNumber" : "Order10002","deliveryAddress" : "test_address2","goods": [{"id": 1,"goodsCode": "GoodsCode1","goodsName": "GoodsName1","price": 100.0}]
}
通过 Postman 向http://localhost:8081/orders端点发起 Post 请求后,我们发现 order 表和 order_goods 表中的数据都已经正常插入。
使用 SimpleJdbcInsert 简化数据插入过程
虽然通过 JdbcTemplate 的 update 方法可以完成数据的正确插入,我们不禁发现这个实现过程还是比较复杂,尤其是涉及自增主键的处理时,代码显得有点臃肿。那么有没有更加简单的实现方法呢?
答案是肯定的,Spring Boot 针对数据插入场景专门提供了一个 SimpleJdbcInsert 工具类,SimpleJdbcInsert 本质上是在 JdbcTemplate 的基础上添加了一层封装,提供了一组 execute、executeAndReturnKey 以及 executeBatch 重载方法来简化数据插入操作。
通常,我们可以在 Repository 实现类的构造函数中对 SimpleJdbcInsert 进行初始化,如下代码所示:
private JdbcTemplate jdbcTemplate;
private SimpleJdbcInsert orderInserter;
private SimpleJdbcInsert orderGoodsInserter;public OrderJdbcRepository(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;this.orderInserter = new SimpleJdbcInsert(jdbcTemplate).withTableName("`order`").usingGeneratedKeyColumns("id");this.orderGoodsInserter = new SimpleJdbcInsert(jdbcTemplate).withTableName("order_goods");
}
可以看到,这里首先注入了一个 JdbcTemplate 对象,然后我们基于 JdbcTemplate 并针对 order 表和 order_goods 表分别初始化了两个 SimpleJdbcInsert 对象 orderInserter 和 orderGoodsInserter。其中 orderInserter 中还使用了 usingGeneratedKeyColumns 方法设置自增主键列。
基于 SimpleJdbcInsert,完成 Order 对象的插入就非常简单了,实现方式如下所示:
private Long saveOrderWithSimpleJdbcInsert(Order order) {Map<String, Object> values = new HashMap<String, Object>();values.put("order_number", order.getOrderNumber());values.put("delivery_address", order.getDeliveryAddress());Long orderId = orderInserter.executeAndReturnKey(values).longValue();return orderId;
}
我们通过构建一个 Map 对象,然后把需要添加的字段设置成一个个键值对。通过SimpleJdbcInsert 的 executeAndReturnKey 方法在插入数据的同时直接返回自增主键。同样,完成 order_goods 表的操作只需要几行代码就可以了,如下代码所示:
private void saveGoodsToOrderWithSimpleJdbcInsert(Goods goods, long orderId) {Map<String, Object> values = new HashMap<>();values.put("order_id", orderId);values.put("goods_id", goods.getId());orderGoodsInserter.execute(values);
}
这里用到了 SimpleJdbcInsert 提供的 execute 方法,我们可以把这些方法组合起来对 addOrderDetailWithJdbcTemplate 方法进行重构,从而得到如下所示的 addOrderDetailWithSimpleJdbcInsert 方法:
private Order addOrderDetailWithSimpleJdbcInsert(Order order) {//插入 Order 基础信息Long orderId = saveOrderWithSimpleJdbcInsert(order);order.setId(orderId);//插入 Order 与 Goods 的对应关系List<Goods> goodsList = order.getGoods();for (Goods goods : goodsList) {saveGoodsToOrderWithSimpleJdbcInsert(goods, orderId);}return order;
}
详细的代码清单可以参考课程的案例代码,你也可以基于 Postman 对重构后的代码进行尝试。
小结与预告
JdbcTemplate 模板工具类是一个基于 JDBC 规范实现数据访问的强大工具,是一个优秀的工具类。它对常见的 CRUD 操作做了封装并提供了一大批简化的 API。今天我们分别针对查询和插入这两大类数据操作给出了基于 JdbcTemplate 的实现方案,特别是针对插入场景,我们还引入了基于 JdbcTemplate 所构建的 SimpleJdbcInsert 简化这一操作。
08 数据访问:如何剖析 JdbcTemplate 数据访问实现原理?
07 讲中,我们介绍了使用 JdbcTemplate 模板工具类完成关系型数据库访问的详细实现过程,通过 JdbcTemplate 不仅简化了数据库操作,还避免了使用原生 JDBC 带来的代码复杂度和冗余性问题。
那么,JdbcTemplate 在 JDBC 基础上如何实现封装的呢?今天,我将带领大家从设计思想出发,讨论 JDBC API 到 JdbcTemplate 的演进过程,并剖析 JdbcTemplate 的部分核心源码。
从模板方法模式和回调机制说起
从命名上 JdbcTemplate 显然是一种模板类,这就让我们联想起设计模式中的模板方法模式。为了让你更好地理解 JdbcTemplate 的实现原理,我们先对这一设计模式进行简单说明。
模板方法设计模式
模板方法模式的原理非常简单,它主要是利用了面向对象中类的继承机制,目前应用非常广泛的,且在实现上往往与抽象类一起使用,比如 Spring 框架中也大量应用了模板方法实现基类和子类之间的职责分离和协作。
按照定义,完成一系列步骤时,这些步骤需要遵循统一的工作流程,个别步骤的实现细节除外,这时我们就需要考虑使用模板方法模式处理了。模板方法模式的结构示意图如下所示:
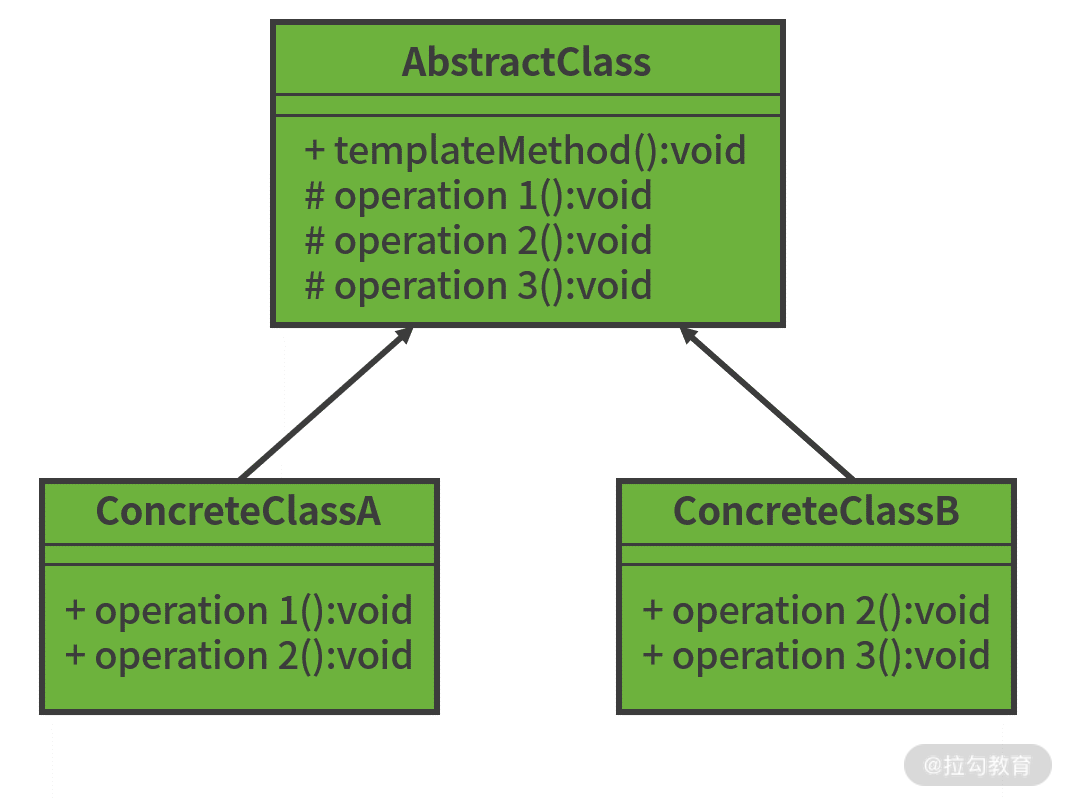
模板方法设计模式结构示意图
上图中,抽象模板类 AbstractClass 定义了一套工作流程,而具体实现类 ConcreteClassA 和 ConcreteClassB 对工作流程中的某些特定步骤进行了实现。
回调机制
在软件开发过程中,回调(Callback)是一种常见的实现技巧,回调的含义如下图所示:
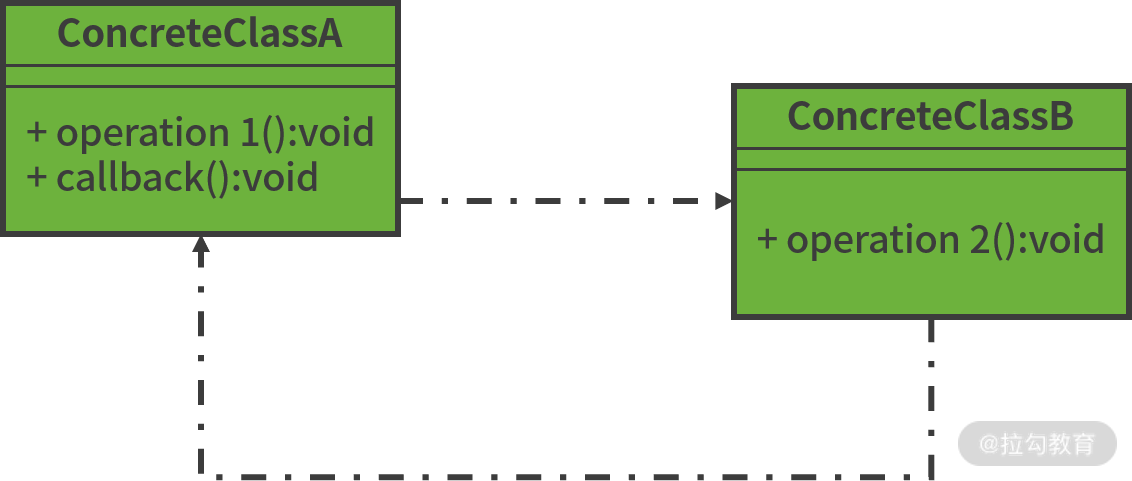
回调示意图
上图中,ClassA 的 operation1() 方法调用 ClassB 的 operation2() 方法,ClassB 的 operation2() 方法执行完毕再主动调用 ClassA 的 callback() 方法,这就是回调机制,体现的是一种双向的调用方式。
从上面描述可以看到,回调在任务执行过程中不会造成任何的阻塞,任务结果一旦就绪,回调就会被执行,显然在方法调用上这是一种异步执行的方式。同时,回调还是实现扩展性的一种简单而直接的模式。
在上图中,我们看到执行回调时,代码会从一个类中的某个方法跳到另一个类中的某个方法,这种思想同样可以扩展到组件级别,即代码从一个组件跳转到另一个组件。只要预留回调的契约,原则上我们可以实现运行时根据调用关系动态来实现组件之间的跳转,从而满足扩展性的要求。
事实上,JdbcTemplate 正是基于模板方法模式和回调机制,才真正解决了原生 JDBC 中的复杂性问题。
接下来,我们结合 07 讲中给出的 SpringCSS 案例场景从 JDBC 的原生 API 出发,讨论 JdbcTemplate 的演进过程。
JDBC API 到 JdbcTemplate 的演变
在 06《基础规范:如何理解 JDBC 关系型数据库访问规范?》讲中,我们给出了基于 JDBC 原生 API 访问数据库的开发过程,那如何完成 JDBC 到JdbcTemplate 呢?
在整个过程中,我们不难发现创建 DataSource、获取 Connection、创建 Statement 等步骤实际上都是重复的,只有处理 ResultSet 部分需要我们针对不同的 SQL 语句和结果进行定制化处理,因为每个结果集与业务实体之间的对应关系不同。
这样,我们的思路就来了,首先我们想到的是如何构建一个抽象类实现模板方法。
在 JDBC API 中添加模板方法模式
假设我们将这个抽象类命名为 AbstractJdbcTemplate,那么该类的代码结构应该是这样的:
public abstract class AbstractJdbcTemplate{@Autowiredprivate DataSource dataSource;public final Object execute(String sql) { Connection connection = null;Statement statement = null;ResultSet resultSet = null;try {connection = dataSource.getConnection();statement = connection.createStatement();resultSet = statement.executeQuery(sql);Object object = handleResultSet(resultSet); return object;} catch (SQLException e) {System.out.print(e);} finally {if (resultSet != null) {try {resultSet.close();} catch (SQLException e) {}}if (statement != null) {try {statement.close();} catch (SQLException e) {}}if (connection != null) {try {connection.close();} catch (SQLException e) {}}}return null;}protected abstract Object handleResultSet(ResultSet rs) throws SQLException;
}
AbstractJdbcTemplate 是一个抽象类,而 execute 方法主体代码我们都很熟悉,基本照搬了07 讲所构建的 OrderRawJdbcRepository 类中的代码。唯一需要注意的是,这里出现了一个模板方法 handleResultSet 用来处理 ResultSet。
下面我们再构建一个 AbstractJdbcTemplate 的实现类 OrderJdbcTemplate,如下代码所示:
public class OrderJdbcTemplate extends AbstractJdbcTemplate{@Overrideprotected Object handleResultSet(ResultSet rs) throws SQLException {List<Order> orders = new ArrayList<Order>();while (rs.next()) {Order order = new Order(rs.getLong("id"), rs.getString("order_number"), rs.getString("delivery_address"));orders.add(order);}return orders;}
}
显然,这里我们获取了 ResultSet 中的结果,并构建了业务对象进行返回。
我们再使用 OrderJdbcTemplate 执行目标 SQL 语句,如下代码所示:
AbstractJdbcTemplate jdbcTemplate = new OrderJdbcTemplate();
List<Order> orders = (List<Order>) jdbcTemplate.execute("select * from Order");
就这样,一个添加了模板方法模式的 JdbcTemplate 就构建完成了,是不是很简单?接下来,我们继续讨论如何对它进行进一步改进。
在 JDBC API 中添加回调机制
试想一下,如果我们需要对各种业务对象实现数据库操作,那势必需要提供各种类似 OrderJdbcTemplate 这样的实现类,这点显然很不方便。一方面我们需要创建和维护一批新类,另一方面如果抽象方法数量很多,子类就需要实现所有抽象方法,尽管有些方法中子类并不会用到,这时该如何解决呢?
实际上,这种问题本质在于我们使用了抽象类。如果我们不想使用抽象类,则可以引入前面介绍的回调机制。使用回调机制的第一步,先定义一个回调接口来剥离业务逻辑,我们将其命名为 StatementCallback,如下代码所示:
public interface StatementCallback {Object handleStatement(Statement statement) throws SQLException;
}
然后,我们重新创建一个新的 CallbackJdbcTemplate 用来执行数据库访问,如下代码所示:
public class CallbackJdbcTemplate {@Autowiredprivate DataSource dataSource;public final Object execute(StatementCallback callback){ Connection connection = null;Statement statement = null;ResultSet resultSet = null;try {connection = dataSource.getConnection();statement = connection.createStatement();Object object = callback.handleStatement(statement);return object;} catch (SQLException e) {System.out.print(e);} finally {//省略异常处理}return null;}
}
注意,与 AbstractJdbcTemplate 类相比,CallbackJdbcTemplate 存在两处差异点。 首先,CallbackJdbcTemplate 不是一个抽象类。其次,execute 方法签名上传入的是一个 StatementCallback 对象,而具体的定制化处理是通过 Statement 传入到 Callback 对象中完成的,我们也可以认为是把原有需要子类抽象方法实现的功能转嫁到了 StatementCallback 对象上。
基于 CallbackJdbcTemplate 和 StatementCallback,我们可以构建具体数据库访问的执行流程,如下代码所示:
public Object queryOrder(final String sql) {class OrderStatementCallback implements StatementCallback {public Object handleStatement(Statement statement) throws SQLException {ResultSet rs = statement.executeQuery(sql);List<Order> orders = new ArrayList<Order>();while (rs.next()) {Order order = new Order(rs.getLong("id"), rs.getString("order_number"),rs.getString("delivery_address"));orders.add(order);}return orders;}}CallbackJdbcTemplate jdbcTemplate = new CallbackJdbcTemplate();return jdbcTemplate.execute(new OrderStatementCallback());
}
这里,我们定义了一个 queryOrder 方法并传入 SQL 语句中用来实现对 Order 表的查询。
注意到,在 queryOrder 方法中我们构建了一个 OrderStatementCallback 内部类,该类实现了 StatementCallback 接口并提供了具体操作 SQL 的定制化代码。然后我们创建了一个 CallbackJdbcTemplate 对象并将内部类 OrderStatementCallback 传入该对象的 execute 方法中。
针对这种场景,实际上我们也可以不创建 OrderStatementCallback 内部类,因为该类只适用于这个场景中,此时更为简单的处理方法是使用匿名类,如下代码所示:
public Object queryOrder(final String sql) {CallbackJdbcTemplate jdbcTemplate = new CallbackJdbcTemplate();return jdbcTemplate.execute(new StatementCallback() {public Object handleStatement(Statement statement) throws SQLException {ResultSet rs = statement.executeQuery(sql);List<Order> orders = new ArrayList<Order>();while (rs.next()) {Order order = new Order(rs.getLong("id"), rs.getString("order_number"),rs.getString("delivery_address"));orders.add(order);}return orders;}});
}
匿名类的实现方式比较简洁点,且在日常开发过程中,我们也经常使用这种方式实现回调接口。
JdbcTemplate 源码解析
理解了 JDBC API 到 JdbcTemplate 的演变过程,接下来我们真正进入 Spring Boot 所提供的 JdbcTemplate 模板工具类的源码部分,看看它是否采用了这种设计思路。
我们直接看 JdbcTemplate 的 execute(StatementCallback action) 方法,如下代码所示:
public <T> T execute(StatementCallback<T> action) throws DataAccessException {Assert.notNull(action, "Callback object must not be null");Connection con = DataSourceUtils.getConnection(obtainDataSource());Statement stmt = null;try {stmt = con.createStatement();applyStatementSettings(stmt);T result = action.doInStatement(stmt);handleWarnings(stmt);return result;}catch (SQLException ex) {String sql = getSql(action);JdbcUtils.closeStatement(stmt);stmt = null;DataSourceUtils.releaseConnection(con, getDataSource());con = null;throw translateException("StatementCallback", sql, ex);}finally {JdbcUtils.closeStatement(stmt);DataSourceUtils.releaseConnection(con, getDataSource());}
}
从以上代码中可以看出,execute 方法中同样接收了一个 StatementCallback 回调接口,然后通过传入 Statement 对象完成 SQL 语句的执行,这与前面我们给出的实现方法完全一致。
StatementCallback 回调接口定义代码如下:
public interface StatementCallback<T> {T doInStatement(Statement stmt) throws SQLException, DataAccessException;
}
同样,我们发现 StatementCallback 回调接口的定义也很类似。我们来看看上述 execute(StatementCallback action) 方法的具体使用方法。
**事实上,在 JdbcTemplate 中,还存在另一个 execute(final String sql) 方法,该方法中恰恰使用了 execute(StatementCallback action) 方法,**如下代码所示:
public void execute(final String sql) throws DataAccessException {if (logger.isDebugEnabled()) {logger.debug("Executing SQL statement [" + sql + "]");}class ExecuteStatementCallback implements StatementCallback<Object>, SqlProvider {@Override@Nullablepublic Object doInStatement(Statement stmt) throws SQLException {stmt.execute(sql);return null;}@Overridepublic String getSql() {return sql;}}execute(new ExecuteStatementCallback());
}
这里,我们同样采用了内部类的实现方式创建 StatementCallback 回调接口的实现类 ExecuteStatementCallback,然后通过传入 Statement 对象完成 SQL 语句的执行,最后通过调用 execute(StatementCallback<T> action) 方法实现整个执行过程。
从源码解析到日常开发
今天的内容与其说在讲 JdbcTemplate 的源码,不如说在剖析该类背后的设计思想,因此 08 讲中的很多知识点和实现方法都可以应用到日常开发过程中。
无论是模板方法还是回调机制,在技术实现上都没有难度,有难度的是应用的场景以及对问题的抽象。JdbcTemplate 基于 JDBC 的原生 API,把模板方法和回调机制结合在了一起,为我们提供了简洁且高扩展的实现方案,值得我们分析和应用。
小结与预告
JdbcTemplate 是 Spring 中非常具有代表性的一个模板工具类。今天的课程中,我们从现实应用场景出发,系统分析了原始 JDBC 规范到 JdbcTemplate 的演进过程,并给出了模板方法设计模式和回调机制在这一过程中所发挥的作用。我们先提供了 JdbcTemplate 的初步实现方案,然后结合 Spring Boot中 的 JdbcTemplate 源码做了类比。
09 数据抽象:Spring Data 如何对数据访问过程进行统一抽象?
事实上,JdbcTemplate 是相对偏底层的一个工具类,作为系统开发最重要的基础功能之一,数据访问层组件的开发方式在 Spring Boot 中也得到了进一步简化,并充分发挥了 Spring 家族中另一个重要成员 Spring Data 的作用。
前面我们通过两个课时介绍了 Spring 框架用于访问关系型数据库的 JdbcTemplate 模板类,今天我们将对 Spring Data 框架中所提供的数据访问方式展开讨论。
Spring Data 是 Spring 家族中专门用于数据访问的开源框架,其核心理念是对所有存储媒介支持资源配置从而实现数据访问。我们知道,数据访问需要完成领域对象与存储数据之间的映射,并对外提供访问入口,Spring Data 基于 Repository 架构模式抽象出一套实现该模式的统一数据访问方式。
Spring Data 对数据访问过程的抽象主要体现在两个方面:① 提供了一套 Repository 接口定义及实现;② 实现了各种多样化的查询支持,接下来我们分别看一下。
Repository 接口及实现
Repository 接口是 Spring Data 中对数据访问的最高层抽象,接口定义如下所示:
public interface Repository<T, ID> {
}
在以上代码中,我们看到 Repository 接口只是一个空接口,通过泛型指定了领域实体对象的类型和 ID。在 Spring Data 中,存在一大批 Repository 接口的子接口和实现类,该接口的部分类层结构如下所示:

Repository 接口的部分类层结构图
可以看到 CrudRepository 接口是对 Repository 接口的最常见扩展,添加了对领域实体的 CRUD 操作功能,具体定义如下代码所示:
public interface CrudRepository<T, ID> extends Repository<T, ID> {<S extends T> S save(S entity);<S extends T> Iterable<S> saveAll(Iterable<S> entities);Optional<T> findById(ID id);boolean existsById(ID id);Iterable<T> findAll();Iterable<T> findAllById(Iterable<ID> ids);long count();void deleteById(ID id);void delete(T entity);void deleteAll(Iterable<? extends T> entities);void deleteAll();
}
这些方法都是自解释的,我们可以看到 CrudRepository 接口提供了保存单个实体、保存集合、根据 id 查找实体、根据 id 判断实体是否存在、查询所有实体、查询实体数量、根据 id 删除实体 、删除一个实体的集合以及删除所有实体等常见操作,我们具体来看下其中几个方法的实现过程。
在实现过程中,我们首先需要关注最基础的 save 方法。通过查看 CrudRepository 的类层结构,我们找到它的一个实现类 SimpleJpaRepository,这个类显然是基于 JPA 规范所实现的针对关系型数据库的数据访问类。
save 方法如下代码所示:
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager em;@Transactional
public <S extends T> S save(S entity) {if (entityInformation.isNew(entity)) {em.persist(entity);return entity;} else {return em.merge(entity);}
}
显然,上述 save 方法依赖于 JPA 规范中的 EntityManager,当它发现所传入的实体为一个新对象时,就会调用 EntityManager 的 persist 方法,反之使用该对象进行 merge。关于 JPA 规范以及 EntityManager 我们在下一课时中会详细展开。
我们接着看一下用于根据 id 查询实体的 findOne 方法,如下代码所示:
public T findOne(ID id) {Assert.notNull(id, ID_MUST_NOT_BE_NULL);Class<T> domainType = getDomainClass();if (metadata == null) {return em.find(domainType, id);}LockModeType type = metadata.getLockModeType();Map<String, Object> hints = getQueryHints();return type == null ? em.find(domainType, id, hints) : em.find(domainType, id, type, hints);
}
在执行查询过程中,findOne 方法会根据领域实体的类型调用 EntityManager 的 find 方法来查找目标对象。需要注意的是,这里也会用到一些元数据 Metadata,以及涉及改变正常 SQL 执行效果的 Hint 机制的使用。
多样化查询支持
在日常开发过程中,数据查询的操作次数要远高于数据新增、数据删除和数据修改,因此在 Spring Data 中,除了对领域对象提供默认的 CRUD 操作外,我们还需要对查询场景高度抽象。而在现实的业务场景中,最典型的查询操作是 @Query 注解和方法名衍生查询机制。
@Query 注解
我们可以通过 @Query 注解直接在代码中嵌入查询语句和条件,从而提供类似 ORM 框架所具有的强大功能。
下面就是使用 @Query 注解进行查询的典型例子:
public interface AccountRepository extends JpaRepository<Account, Long> {@Query("select a from Account a where a.userName = ?1") Account findByUserName(String userName);
}
注意到这里的 @Query 注解使用的是类似 SQL 语句的语法,它能自动完成领域对象 Account 与数据库数据之间的相互映射。因我们使用的是 JpaRepository,所以这种类似 SQL 语句的语法实际上是一种 JPA 查询语言,也就是所谓的 JPQL(Java Persistence Query Language)。
JPQL 的基本语法如下所示:
SELECT 子句 FROM 子句
[WHERE 子句]
[GROUP BY 子句]
[HAVING 子句]
[ORDER BY 子句]
JPQL 语句是不是和原生的 SQL 语句非常类似?唯一的区别就是 JPQL FROM 语句后面跟的是对象,而原生 SQL 语句中对应的是数据表中的字段。
介绍完 JPQL 之后,我们再回到 @Query 注解定义,这个注解位于 org.springframework.data.jpa.repository 包中,如下所示:
package org.springframework.data.jpa.repository;public @interface Query {String value() default "";String countQuery() default "";String countProjection() default "";boolean nativeQuery() default false;String name() default "";String countName() default "";
}
@Query 注解中最常用的就是 value 属性,在前面示例中 JPQL 语句有使用到 。当然,如果我们将 nativeQuery 设置为 true,那么 value 属性则需要指定具体的原生 SQL 语句。
请注意,在 Spring Data 中存在一批 @Query 注解,分别针对不同的持久化媒介。例如 MongoDB 中存在一个 @Query 注解,但该注解位于 org.springframework.data.mongodb.repository 包中,定义如下:
package org.springframework.data.mongodb.repository;public @interface Query {String value() default "";String fields() default "";boolean count() default false;boolean exists() default false;boolean delete() default false;
}
与面向 JPA 的 @Query 注解不同的是,MongoDB 中 @Query 注解的 value 值是一串 JSON 字符串,用于指定需要查询的对象条件,这里我们就不具体展开了。
方法名衍生查询
方法名衍生查询也是 Spring Data 的查询特色之一,通过在方法命名上直接使用查询字段和参数,Spring Data 就能自动识别相应的查询条件并组装对应的查询语句。典型的示例如下所示:
public interface AccountRepository extends JpaRepository<Account, Long> {List<Account> findByFirstNameAndLastName(String firstName, String lastName);
}
在上面的例子中,通过 findByFirstNameAndLastname 这样符合普通语义的方法名,并在参数列表中按照方法名中参数的顺序和名称(即第一个参数是 fistName,第二个参数 lastName)传入相应的参数,Spring Data 就能自动组装 SQL 语句从而实现衍生查询。是不是很神奇?
而想要使用方法名实现衍生查询,我们需要对 Repository 中定义的方法名进行一定约束。
首先我们需要指定一些查询关键字,常见的关键字如下表所示:
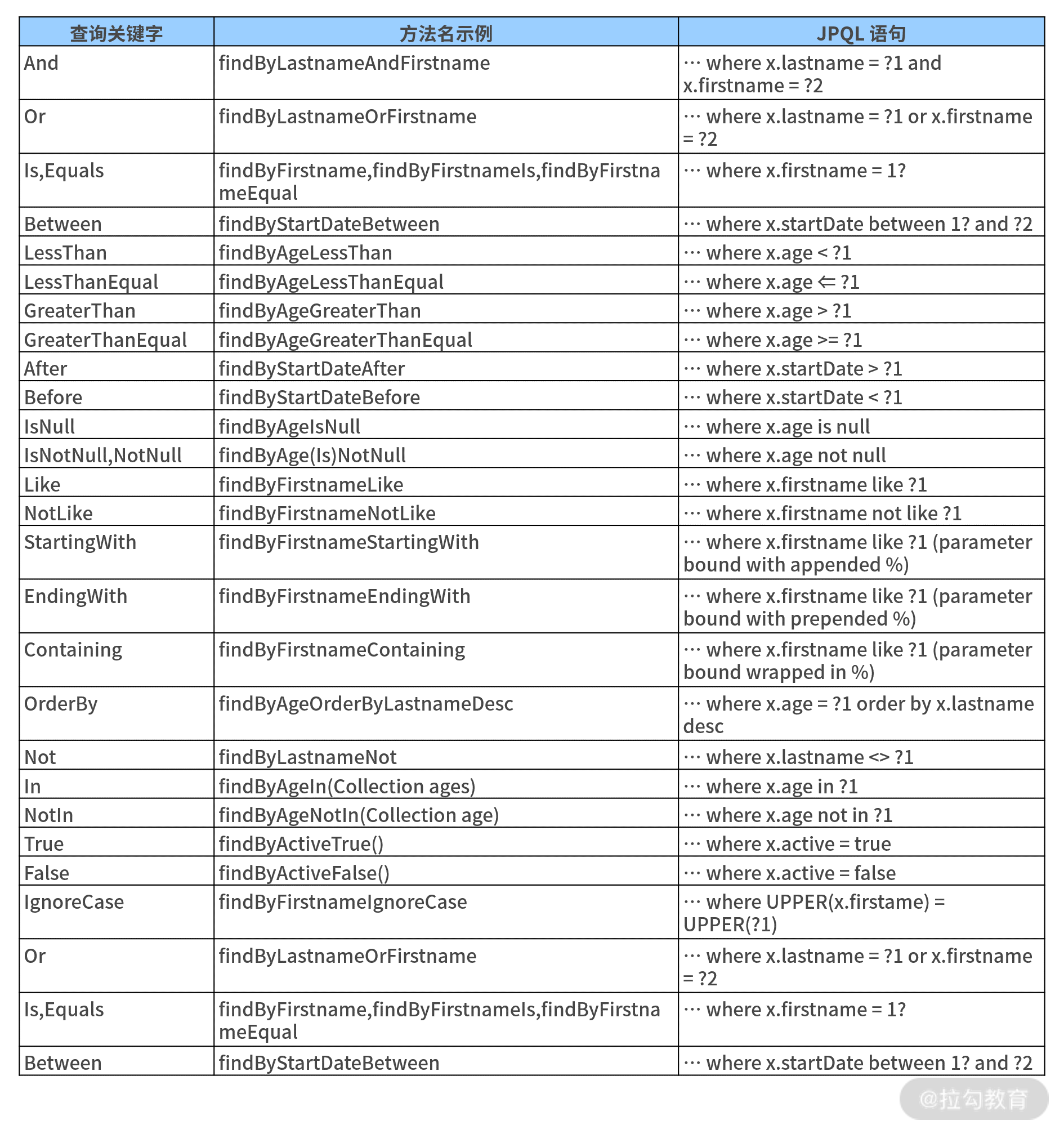
方法名衍生查询中查询关键字列表
有了这些查询关键字后,在方法命名上我们还需要指定查询字段和一些限制性条件。例如,在前面的示例中,我们只是基于“fistName”和“lastName”这两个字段做查询。
事实上,我们可以查询的内容非常多,下表列出了更多的方法名衍生查询示例,你可以参考下。
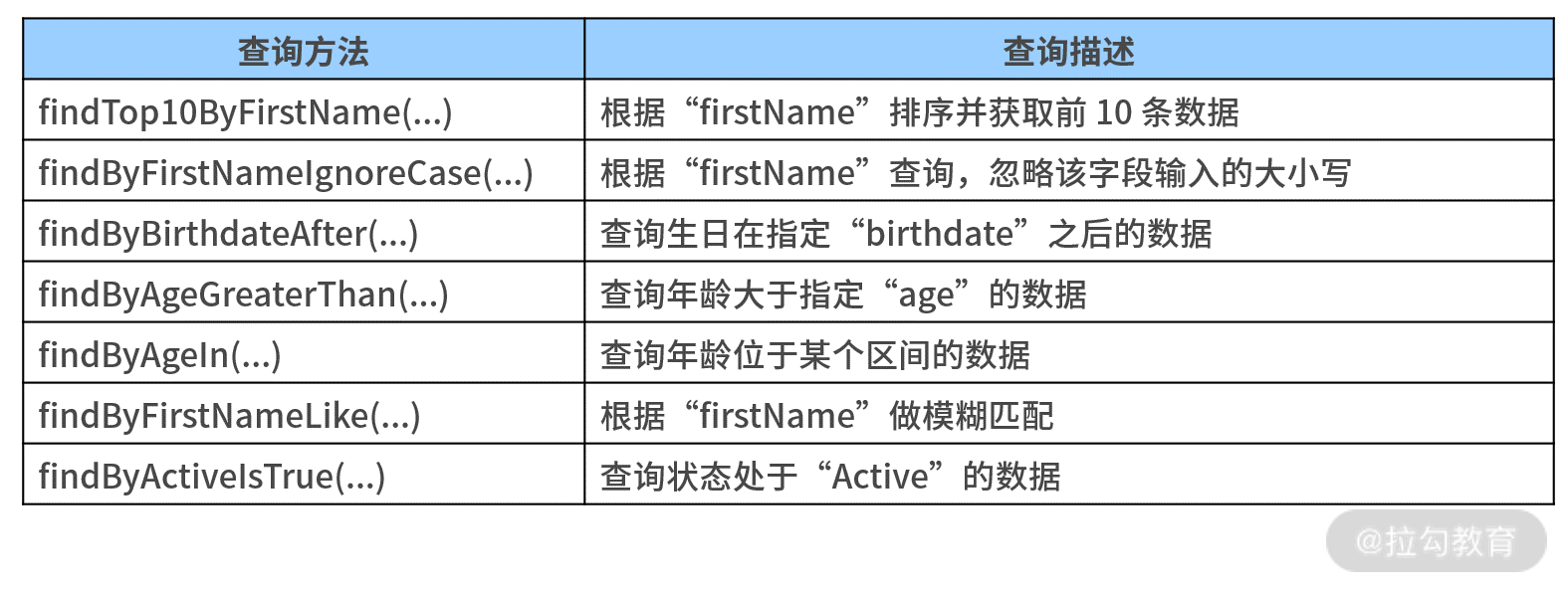
方法名衍生查询示例
在 Spring Data 中,方法名衍生查询的功能非常强大,上表中罗列的这些也只是全部功能中的一小部分而已。
讲到这里,你可能会问一个问题:如果我们在一个 Repository 中同时指定了 @Query 注解和方法名衍生查询,那么 Spring Data 会具体执行哪一个呢?要想回答这个问题,就需要我们对查询策略有一定的了解。
在 Spring Data 中,查询策略定义在 QueryLookupStrategy 中,如下代码所示:
public interface QueryLookupStrategy { public static enum Key {CREATE, USE_DECLARED_QUERY, CREATE_IF_NOT_FOUND;public static Key create(String xml) {if (!StringUtils.hasText(xml)) {return null;}return valueOf(xml.toUpperCase(Locale.US).replace("-", "_"));}}RepositoryQuery resolveQuery(Method method, RepositoryMetadata metadata, ProjectionFactory factory, NamedQueries namedQueries);
}
从以上代码中,我们看到 QueryLookupStrategy 分为三种,即 CREATE、USE_DECLARED_QUERY 和 CREATE_IF_NOT_FOUND。
这里的 CREATE 策略指的是直接根据方法名创建的查询策略,也就是使用前面介绍的方法名衍生查询。
而 USE_DECLARED_QUERY 指的是声明方式,主要使用 @Query 注解,如果没有 @Query 注解系统就会抛出异常。
而最后一种 CREATE_IF_NOT_FOUND 可以理解为是 @Query 注解和方法名衍生查询两者的兼容版。请注意,Spring Data 默认使用的是 CREATE_IF_NOT_FOUND 策略,也就是说系统会先查找 @Query 注解,如果查到没有,会再去找与方法名相匹配的查询。
Spring Data 中的组件
Spring Data 支持对多种数据存储媒介进行数据访问,表现为提供了一系列默认的 Repository,包括针对关系型数据库的 JPA/JDBC Repository,针对 MongoDB、Neo4j、Redis 等 NoSQL 对应的 Repository,支持 Hadoop 的大数据访问的 Repository,甚至包括 Spring Batch 和 Spring Integration 在内的系统集成的 Repository。
在 Spring Data 的官方网站https://spring.io/projects/spring-data 中,列出了其提供的所有组件,如下图所示:

Spring Data 所提供的组件列表(来自 Spring Data 官网)
根据官网介绍,Spring Data 中的组件可以分成四大类:核心模块(Main modules)、社区模块(Community modules)、关联模块(Related modules)和正在孵化的模块(Modules in Incubation)。例如,前面介绍的 Respository 和多样化查询功能就在核心模块 Spring Data Commons 组件中。
这里,我特别想强调下的是正在孵化的模块,它目前只包含一个组件,即 Spring Data R2DBC。 R2DBC 是Reactive Relational Database Connectivity 的简写,代表响应式关系型数据库连接,相当于是响应式数据访问领域的 JDBC 规范。
小结与预告
数据访问是一切应用系统的基础,Spring Boot 作为一款集成性的开发框架,专门提供了 Spring Data 组件实现对数据访问过程进行抽象。基于 Repository 架构模式,Spring Data 为开发人员提供了一系列用于完成 CRUD 操作的工具方法,尤其是对最常用的查询操作专门进行了提炼和设计,使得开发过程更简单、高效。
10 ORM 集成:如何使用 Spring Data JPA 访问关系型数据库?
在前面的课程中,我们详细介绍了如何使用 Spring 所提供的 JdbcTemplate 模板工具类实现数据访问的实现方法。相较 JDBC 所提供的原生 API,JdbcTemplate 做了一层封装,大大简化了数据的操作过程。而在 09 讲中,我们又进一步引入了 Spring Data 框架,可以说 Spring Data 框架是基于 JdbcTemplate 上另一层更高级的封装。
今天,我们将基于 Spring Data 中的 Spring Data JPA 组件介绍如何集成 ORM 框架实现关系型数据库访问。
引入 Spring Data JPA
如果你想在应用程序中使用 Spring Data JPA,首先需要在 pom 文件中引入 spring-boot-starter-data-jpa 依赖,如下代码所示:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
在介绍这一组件的使用方法之前,我们有必要对 JPA 规范进行一定的了解。
JPA 全称是 JPA Persistence API,即 Java 持久化 API,它是一个 Java 应用程序接口规范,用于充当面向对象的领域模型和关系数据库系统之间的桥梁,属于一种 ORM(Object Relational Mapping,对象关系映射)技术。
JPA 规范中定义了一些既定的概念和约定,集中包含在 javax.persistence 包中,常见的如对实体(Entity)定义、实体标识定义、实体与实体之间的关联关系定义,以及 09 讲中介绍的 JPQL 定义等,关于这些定义及其使用方法,一会儿我们会详细展开说明。
与 JDBC 规范一样,JPA 规范也有一大批实现工具和框架,极具代表性的如老牌的 Hibernate 及今天我们将介绍的 Spring Data JPA。
为了演示基于 Spring Data JPA 的整个开发过程,我们将在 SpringCSS 案例中专门设计和实现一套独立的领域对象和 Repository,接下来我们一起来看下。
实体类注解
我们知道 order-service 中存在两个主要领域对象,即 Order 和 Goods。为了与前面课时介绍的领域对象有所区分,本节课我们重新创建两个领域对象,分别命名为 JpaOrder 和 JpaGoods,它们就是 JPA 规范中的实体类。
我们先来看下相对简单的 JpaGoods,这里我们把 JPA 规范的相关类的引用罗列在了一起,JpaGoods 定义如下代码所示:
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;@Entity
@Table(name="goods")
public class JpaGoods {@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id; private String goodsCode;private String goodsName;private Float price; //省略 getter/setter
}
JpaGoods 中使用了 JPA 规范中用于定义实体的几个注解:最重要的 @Entity 注解、用于指定表名的 @Table 注解、用于标识主键的 @Id 注解,以及用于标识自增数据的 @GeneratedValue 注解,这些注解都比较直白,在实体类上直接使用即可。
接下来,我们看下比较复杂的 JpaOrder,定义如下代码所示:
@Entity
@Table(name="`order`")
public class JpaOrder implements Serializable {private static final long serialVersionUID = 1L;@Id@GeneratedValue(strategy = GenerationType.IDENTITY)private Long id;private String orderNumber;private String deliveryAddress;@ManyToMany(targetEntity=JpaGoods.class)@JoinTable(name = "order_goods", joinColumns = @JoinColumn(name = "order_id", referencedColumnName = "id"), inverseJoinColumns = @JoinColumn(name = "goods_id", referencedColumnName = "id"))private List<JpaGoods> goods = new ArrayList<>();//省略 getter/setter
}
这里除了引入了常见的一些注解,还引入了 @ManyToMany 注解,它表示 order 表与 goods 表中数据的关联关系。
在JPA 规范中,共提供了 one-to-one、one-to-many、many-to-one、many-to-many 这 4 种映射关系,它们分别用来处理一对一、一对多、多对一,以及多对多的关联场景。
针对 order-service 这个业务场景,我们设计了一张 order_goods 中间表存储 order 与 goods 表中的主键关系,且使用了 @ManyToMany 注解定义 many-to-many 这种关联关系,也使用了 @JoinTable 注解指定 order_goods 中间表,并通过 joinColumns 和 inverseJoinColumns 注解分别指定中间表中的字段名称以及引用两张主表中的外键名称。
定义 Repository
定义完实体对象后,我们再来提供 Repository 接口,这一步的操作非常简单,OrderJpaRepository 的定义如下代码所示:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>
{
}
从上面代码中我们发现,OrderJpaRepository 是一个继承了 JpaRepository 接口的空接口,基于 09 讲的介绍,我们知道 OrderJpaRepository 实际上已经具备了访问数据库的基本 CRUD 功能。
使用 Spring Data JPA 访问数据库
有了上面定义的 JpaOrder 和 JpaGoods 实体类,以及 OrderJpaRepository 接口,我们已经可以实现很多操作了。
比如我们想通过 Id 获取 Order 对象,首先可以通过构建一个 JpaOrderService 直接注入 OrderJpaRepository 接口,如下代码所示:
@Service
public class JpaOrderService {@Autowiredprivate OrderJpaRepository orderJpaRepository;public JpaOrder getOrderById(Long orderId) {return orderJpaRepository.getOne(orderId);}
}
然后,我们再通过构建一个 Controller 类嵌入上述方法,并通过 HTTP 请求查询 Id 为 1 的 JpaOrder 对象,获得的结果如下代码所示:
{"id": 1,"orderNumber": "Order10001","deliveryAddress": "test_address1","goods": [{"id": 1,"goodsCode": "GoodsCode1","goodsName": "GoodsName1","price": 100.0},{"id": 2,"goodsCode": "GoodsCode2","goodsName": "GoodsName2","price": 200.0}]
}
请注意,这里我们不仅获取了 order 表中的订单基础数据,还同时获取了 goods 表中的商品数据,这种效果是如何实现的呢?是因为在 JpaOrder 对象中,我们添加了 @ManyToMany 注解,该注解会自动从 order_goods 表中获取商品主键信息,并从 goods 表中获取商品详细信息。
了解了使用 Spring Data JPA 实现关系型数据库访问的过程,并对比《数据访问:如何使用 JdbcTemplate 访问关系型数据库?》中通过 JdbcTemplate 获取这部分数据的实现过程,我们发现使用 Spring Data JPA 更简单。
在多样化查询实现过程中,我们不仅可以使用 JpaRepository 中默认集成的各种 CRUD 方法,还可以使用 09 讲中介绍的 @Query 注解、方法名衍生查询等。今天,我们还将同时引入 QueryByExample 和 Specification 这两种机制来丰富多样化查询方式。
使用 @Query 注解
使用 @Query 注解实现查询的示例如下代码所示:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>
{@Query("select o from JpaOrder o where o.orderNumber = ?1")JpaOrder getOrderByOrderNumberWithQuery(String orderNumber);
}
这里,我们使用了 JPQL 根据 OrderNumber 查询订单信息。JPQL 的语法与 SQL 语句非常类似,09 讲中我们对 JPQL 进行了讨论,这里我们不再赘述,你可以前往回顾。
说到 @Query 注解,JPA 中还提供了一个 @NamedQuery 注解对 @Query 注解中的语句进行命名。@NamedQuery 注解的使用方式如下代码所示:
@Entity
@Table(name = "`order`")
@NamedQueries({ @NamedQuery(name = "getOrderByOrderNumberWithQuery", query = "select o from JpaOrder o where o.orderNumber = ?1") })
public class JpaOrder implements Serializable {
在上述示例中,我们在实体类 JpaOrder 上添加了一个 @NamedQueries 注解,该注解可以将一批 @NamedQuery 注解整合在一起使用。同时,我们还使用了 @NamedQuery 注解定义了一个“getOrderByOrderNumberWithQuery”查询,且指定了对应的 JPQL 语句。
如果你想使用这个命名查询,在 OrderJpaRepository 中定义与该命名一致的方法即可。
使用方法名衍生查询
使用方法名衍生查询是最方便的一种自定义查询方式,在这过程中开发人员唯一需要做的就是在 JpaRepository 接口中定义一个符合查询语义的方法。
比如我们希望通过 OrderNumber 查询订单信息,那么可以提供如下代码所示的接口定义:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>
{JpaOrder getOrderByOrderNumber(String orderNumber);
}
通过 getOrderByOrderNumber 方法后,我们就可以自动根据 OrderNumber 获取订单详细信息了。
使用 QueryByExample 机制
接下来我们将介绍另一种强大的查询机制,即 QueryByExample(QBE)机制。
针对 JpaOrder 对象,假如我们希望根据 OrderNumber 及 DeliveryAddress 中的一个或多个条件进行查询,按照方法名衍生查询的方式构建查询方法后,得到如下代码所示的方法定义:
List<JpaOrder> findByOrderNumberAndDeliveryAddress (String orderNumber, String deliveryAddress);
如果查询条件中使用的字段非常多,上面这个方法名可能非常长,且还需要设置一批参数,这种查询方法定义显然存在缺陷。
因为不管查询条件有多少个,我们都需要把所有参数进行填充,哪怕部分参数并没有被用到。而且,如果将来我们需要再添加一个新的查询条件,该方法必须做调整,从扩展性上讲也存在设计缺陷。为了解决这些问题,我们便可以引入 QueryByExample 机制。
QueryByExample 可以翻译为按示例查询,是一种用户友好的查询技术。它允许我们动态创建查询,且不需要编写包含字段名称的查询方法,也就是说按示例查询不需要使用特定的数据库查询语言来编写查询语句。
从组成结构上讲,QueryByExample 包括 Probe、ExampleMatcher 和 Example 这三个基本组件。其中, Probe 包含对应字段的实例对象,ExampleMatcher 携带有关如何匹配特定字段的详细信息,相当于匹配条件,Example 则由 Probe 和 ExampleMatcher 组成,用于构建具体的查询操作。
现在,我们基于 QueryByExample 机制重构根据 OrderNumber 查询订单的实现过程。
首先,我们需要在 OrderJpaRepository 接口的定义中继承 QueryByExampleExecutor 接口,如下代码所示:
@Repository("orderJpaRepository")
public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>, QueryByExampleExecutor<JpaOrder> {
然后,我们在 JpaOrderService 中实现如下代码所示的 getOrderByOrderNumberByExample 方法:
public JpaOrder getOrderByOrderNumberByExample(String orderNumber) {JpaOrder order = new JpaOrder();order.setOrderNumber(orderNumber);ExampleMatcher matcher = ExampleMatcher.matching().withIgnoreCase().withMatcher("orderNumber", GenericPropertyMatchers.exact()).withIncludeNullValues();Example<JpaOrder> example = Example.of(order, matcher);return orderJpaRepository.findOne(example).orElse(new JpaOrder());
}
上述代码中,我们首先构建了一个 ExampleMatcher 对象用于初始化匹配规则,然后通过传入一个 JpaOrder 对象实例和 ExampleMatcher 实例构建了一个 Example 对象,最后通过 QueryByExampleExecutor 接口中的 findOne() 方法实现了 QueryByExample 机制。
使用 Specification 机制
本节课中,最后我们想介绍的查询机制是 Specification 机制。
先考虑这样一种场景,比如我们需要查询某个实体,但是给定的查询条件不固定,此时该怎么办?这时我们通过动态构建相应的查询语句即可,而在 Spring Data JPA 中可以通过 JpaSpecificationExecutor 接口实现这类查询。相比使用 JPQL 而言,使用 Specification 机制的优势是类型安全。
继承了 JpaSpecificationExecutor 的 OrderJpaRepository 定义如下代码所示:
@Repository("orderJpaRepository")public interface OrderJpaRepository extends JpaRepository<JpaOrder, Long>, JpaSpecificationExecutor<JpaOrder>{
对于 JpaSpecificationExecutor 接口而言,它背后使用的就是 Specification 接口,且 Specification 接口核心方法就一个,我们可以简单地理解该接口的作用就是构建查询条件,如下代码所示:
Predicate toPredicate(Root<T> root, CriteriaQuery<?> query, CriteriaBuilder criteriaBuilder);
其中 Root 对象代表所查询的根对象,我们可以通过 Root 获取实体的属性,CriteriaQuery 代表一个顶层查询对象,用来实现自定义查询,而 CriteriaBuilder 用来构建查询条件。
基于 Specification 机制,我们同样对根据 OrderNumber 查询订单的实现过程进行重构,重构后的 getOrderByOrderNumberBySpecification 方法如下代码所示:
public JpaOrder getOrderByOrderNumberBySpecification(String orderNumber) {JpaOrder order = new JpaOrder();order.setOrderNumber(orderNumber);@SuppressWarnings("serial")Specification<JpaOrder> spec = new Specification<JpaOrder>() {@Overridepublic Predicate toPredicate(Root<JpaOrder> root, CriteriaQuery<?> query, CriteriaBuilder cb) {Path<Object> orderNumberPath = root.get("orderNumber");Predicate predicate = cb.equal(orderNumberPath, orderNumber);return predicate;}};return orderJpaRepository.findOne(spec).orElse(new JpaOrder());
}
从上面示例中可以看到,在 toPredicate 方法中,首先我们从 root 对象中获取了“orderNumber”属性,然后通过 cb.equal 方法将该属性与传入的 orderNumber 参数进行了比对,从而实现了查询条件的构建过程。
小结与预告
10 讲中,我们主要对通过 Spring Data JPA 进行数据操作的方法和技巧做了一一介绍。
在 Spring Boot 中,我极力推荐使用 Spring Data JPA 实现对关系型数据库访问,因为它不仅具有 ORM 框架的通用功能,同时还添加了 QueryByExample 和 Specification 机制等扩展性功能,应用上简单而高效。