TensorFlow Implementation of Content-Based Filtering|基于内容过滤的TensorFlow实现
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
----------------------------------------------------------------------------------------------
一、引言
基于内容的过滤(Content-based Filtering)直接利用用户特征与物品特征来完成个性化推荐:把它们编码成向量,在同一空间里做匹配。相比只看行为的协同过滤,这种方法能在冷启动或侧信息丰富的场景下发挥优势。本文将用 TensorFlow/Keras 实现一个经典的双塔模型(two-tower):分别学习用户向量 vu 与物品向量 vm,通过点积得到偏好分数,并以可复用的代码框架串起建模 → 训练 → 评估 → 部署的完整闭环。读完后,你可以把自己的特征喂进去,快速落地一个可上线的内容检索与排序模块。
二、模型结构:双塔
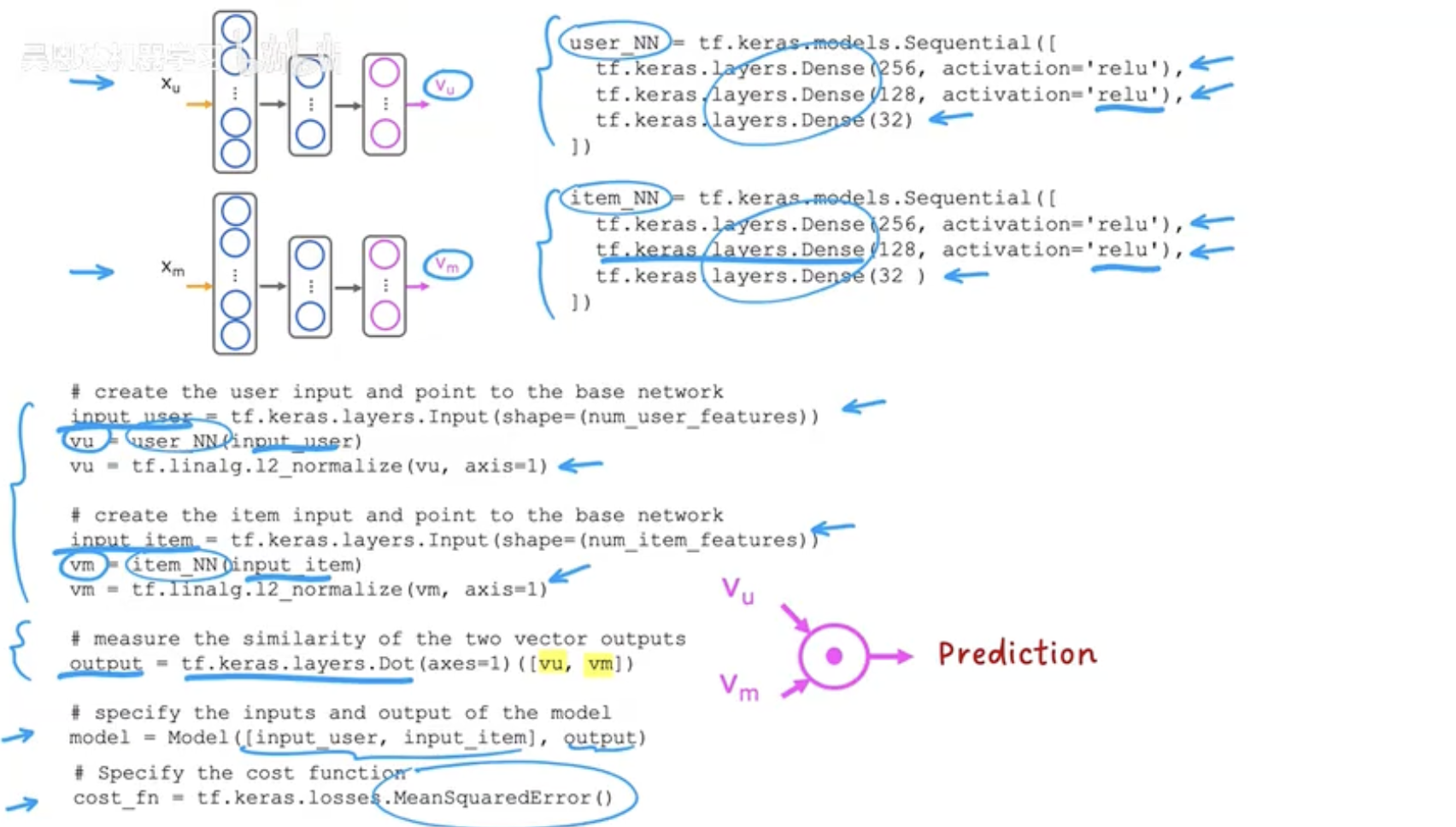
在内容过滤的推荐任务中,我们希望用户与物品都能被映射到同一个向量空间,从而可以直接比较它们的相似性。最常见的实现方式就是双塔模型(two-tower architecture),它由两部分组成:
-
用户网络(User Network)
输入用户特征向量 xu,经过多层全连接网络(Dense layers)逐步压缩维度,得到最终的用户嵌入 vu。在图示例中,维度从 128 → 64 → 32。 -
物品网络(Item/Movie Network)
输入物品特征向量 xm,同样通过多层全连接层得到物品嵌入 vm。这里的维度变化是 256 → 128 → 32。
最终,我们得到两个 32 维向量 vuvu 与 vmvm。这两个向量的**点积(dot product)**或相似度函数就代表了用户与物品的匹配程度,值越大代表越可能喜欢。
预测公式如下:
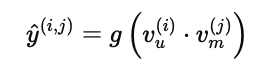
其中,g(⋅) 可以是恒等函数(用于评分预测)或 sigmoid(用于点击/购买概率预测)。
三、搭建子网络(Keras Sequential 建模)
双塔模型的核心是两个结构相似但参数各自独立的多层感知机(MLP):
3.1 设计要点
-
层数与宽度
-
用户塔:
128 → 64 → 32(示例) -
物品塔:
256 → 128 → 32(示例)
末层 32 维即我们的嵌入维度(embedding dim),可按业务改成 16、64 等。
-
-
激活函数
隐藏层使用ReLU,训练稳定、计算高效;输出层不加激活(作为向量表示)。 -
正则化(可选)
可在隐藏层加入kernel_regularizer=tf.keras.regularizers.l2(...)或Dropout,防止过拟合。 -
批归一化(可选)
对高维稀疏特征可加BatchNormalization,但不强制。
3.2 代码
import tensorflow as tf
from tensorflow.keras import layers, modelsEMBED_DIM = 32 # 嵌入维度# 用户塔:128 -> 64 -> 32
user_NN = models.Sequential([layers.Dense(128, activation='relu'),layers.Dense(64, activation='relu'),layers.Dense(EMBED_DIM) # 输出v_u
], name="user_NN")# 物品塔:256 -> 128 -> 32
item_NN = models.Sequential([layers.Dense(256, activation='relu'),layers.Dense(128, activation='relu'),layers.Dense(EMBED_DIM) # 输出v_m
], name="item_NN")
3.3 为什么末层不加激活?
-
末层的目标是输出方向可比较的实数向量,便于做点积/余弦相似度;
-
若加非线性(如
tanh),会把值强行挤压到固定区间,可能减弱表达能力; -
如果后续用 L2 归一化,则数值范围问题也不大。
3.4 嵌入维度如何选?
-
小维度(16/32):计算快、存储省,但表达力有限;
-
大维度(64/128):表达力强,但计算和检索成本上升;
实际可通过离线验证或 A/B 测试挑选最优。
四、输入、归一化与相似度(Inputs, L2 Norm & Dot)
4.1 定义输入张量
用户与物品各有一组特征,通常是数值化/编码后的向量:
num_user_features = 128 # 举例:与数据前处理一致
num_item_features = 256input_user = layers.Input(shape=(num_user_features,), name="input_user")
input_item = layers.Input(shape=(num_item_features,), name="input_item")
4.2 通过子网络得到向量表示
vu = user_NN(input_user) # 形状: (None, EMBED_DIM)
vm = item_NN(input_item) # 形状: (None, EMBED_DIM)
4.3 L2 归一化
-
目的:让向量的方向主导匹配,削弱长度差异带来的影响;
-
有利于余弦相似度 ≈ 点积的等价性,并提升训练稳定性/检索一致性。
vu = tf.linalg.l2_normalize(vu, axis=1) # 每个样本的向量单位化
vm = tf.linalg.l2_normalize(vm, axis=1)
4.4 相似度/匹配分数(Dot)
最常用的是点积;若你要显式用余弦相似度,L2 归一化后两者等价。
score = layers.Dot(axes=1, name="similarity")([vu, vm]) # 形状: (None, 1)
说明:
评分回归(如预测打分 1–5)通常直接用
score(可再缩放);二分类概率(如点击/购买概率)通常在外面再加一个
sigmoid:prob = layers.Activation('sigmoid', name='prob')(score)
4.5 组装前向图
# 回归(MSE/RMSE等)场景
output = score
model = tf.keras.Model([input_user, input_item], output, name="content_based_tower")# 或:二分类(CTR/CVR 等)场景
# output = layers.Activation('sigmoid', name='prob')(score)
# model = tf.keras.Model([input_user, input_item], output, name="content_based_tower_cls")五、模型组装与损失函数(Model & Loss)
5.1 回归任务(预测评分/相似度)
适用:预测打分(如 1–5)、回归型偏好值。
from tensorflow.keras import optimizers, losses, metricsmodel = tf.keras.Model([input_user, input_item], score, name="cbf_reg") # score: Dot 输出
model.compile(optimizer=optimizers.Adam(learning_rate=1e-3),loss=losses.MeanSquaredError(),metrics=[metrics.RootMeanSquaredError(name="rmse")]
)
何时选 MSE:当标签是连续值(评分/分数),或你用点积作为“相对强弱”回归目标。
5.2 二分类任务(点击/购买/喜欢 概率)
适用:CTR/CVR/Like 预测(0/1)。
prob = tf.keras.layers.Activation('sigmoid', name='prob')(score)
model_cls = tf.keras.Model([input_user, input_item], prob, name="cbf_cls")
model_cls.compile(optimizer=optimizers.Adam(learning_rate=1e-3),loss=losses.BinaryCrossentropy(from_logits=False),metrics=[metrics.AUC(name="auc"), metrics.BinaryAccuracy(name="acc")]
)
何时选 BCE:当标签是二元 0/1 且输出为概率。
小贴士:正负样本极不均衡时,可用
class_weight={0: w0, 1: w1}或 focal loss。
5.3 正则化与稳定性
-
L2 正则:在
Dense(..., kernel_regularizer=tf.keras.regularizers.l2(1e-5))上加; -
Dropout:在隐藏层加
Dropout(0.1~0.3); -
梯度裁剪:
optimizer=Adam(..., clipnorm=1.0); -
学习率调度:
ReduceLROnPlateau或CosineDecay提升收敛稳定性。
六、训练、评估与部署(Training, Eval, Serving)
6.1 组织训练数据
# X_user: (N, num_user_features), X_item: (N, num_item_features)
# y_reg: (N, ) 连续分数;或 y_bin: (N, ) 0/1 标签
history = model.fit(x=[X_user, X_item],y=y_reg, # 或 y=y_bin 对 model_clsbatch_size=1024,epochs=10,validation_data=([X_user_val, X_item_val], y_val),callbacks=[tf.keras.callbacks.EarlyStopping(patience=2, restore_best_weights=True)],verbose=1
)
批大小:从 512/1024 起步,根据显存&吞吐调。
早停:避免过拟合,节省训练时间。
6.2 评估指标建议
-
回归:RMSE、MAE、皮尔逊相关;
-
二分类:AUC、PR-AUC、F1;
-
排序(强烈建议):Recall@K、NDCG@K(线下召回/排序效果更贴近线上体验)。
线下做 召回@K:对每个用户取 Top-K 结果,看有多少命中真实交互;再评估 NDCG@K 衡量排名质量。
6.3 导出与上线(Serving)
(a) 预计算物品向量
# 抽取物品塔输出(含 L2 归一化)
item_encoder = tf.keras.Model(input_item, vm, name="item_encoder") # vm 来自前文
item_vecs = item_encoder.predict(AllItemFeatures, batch_size=2048) # 形状: (M, EMBED_DIM)
# 持久化:np.save("item_vecs.npy", item_vecs) 及保存 item_id 对应关系
(b) 在线生成用户向量
user_encoder = tf.keras.Model(input_user, vu, name="user_encoder") # vu 来自前文
# 实时为某用户生成 v_u
vu_realtime = user_encoder.predict(UserFeatureVector[np.newaxis, :])
(c) 近邻检索(ANN)
-
小规模:直接
np.dot(vu, item_vecs.T)得分,Top-K; -
大规模:用 ANN(如 FAISS/ScaNN/NGT)建索引,毫秒级 Top-K。
(d) 端到端排序
-
两阶段实践:
1)检索:ANN 召回 200–1000 个候选;
2)精排:把候选对(user,item)喂入更复杂的打分模型(可加入上下文特征)得到最终 Top-N。
6.4 冷启动与特征工程要点
-
冷启动物品:尽量完善类别、标签、文本/图像特征(可用预训练模型提 embedding,拼接入 xmxm);
-
冷启动用户:引导式采集兴趣标签;利用上下文特征(地理、时间、设备);
-
特征规范化:数值特征标准化;类别特征用 one-hot/embedding;缺失值要有明确占位。
6.5 常见坑位与排查
-
训练/验证分布漂移:确保
X_user_val/X_item_val与线上一致; -
标签时延:交互标签要与特征对齐同一时刻;
-
召回-精排断层:召回的向量空间与精排特征空间需一致或有映射;
-
指标对齐:线下排序指标与线上业务 KPI(CTR、GMV、WatchTime)做好映射关系。
-----------------------------------------------------------------------------------------------
这是我在我的网站中截取的文章,有更多的文章欢迎来访问我自己的博客网站rn.berlinlian.cn,这里还有很多有关计算机的知识,欢迎进行留言或者来我的网站进行留言!!!
----------------------------------------------------------------------------------------------