MySQL索引原理
目录
索引
存储方式
案例
理解page
多个page
B树 VSB +树
聚簇索引 VS 非聚簇索引
聚簇索引
非聚簇索引
innodb对比MYISAM
MYISAM
innodb
索引
用于提高数据库的性能,不需要增加内存与其他的sql语句就可以让查询速度提升许多倍。
但是这种提升是以修改作为代价的。
我们可以通过数据结构:vector、list进行对比
链表不支持随机访问,也就是没有索引,需要访问某一个数据需要从头开始遍历直到找到符合条件的数据。
顺序表支持随机访问,也就是有索引。访问某个数据时直接就可以计算出对应数据的地址进行快速访问。
但是一旦涉及到修改,顺序表的效率比起链表就会慢很多,这就是快速检索的“代价”
存储方式
我们知道操作系统中管理数据是以‘块’为单位(4KB进行IO),MySQL同样如此,MySQL一次读取硬盘数据的基本单位为16KB(innodb存储引擎)。
为了提高效率,我们要做的就是尽量减少io次数,因为数据库的数据存储在硬盘上,而不是内存中。硬盘io效率要远远低于内存效率。
案例
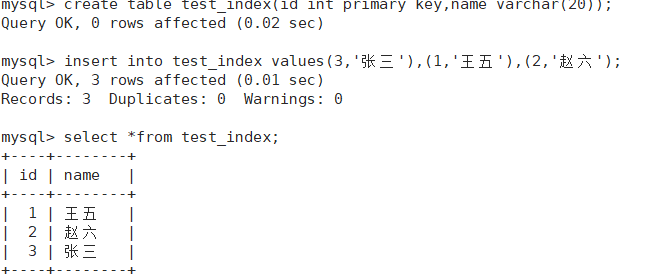
我们可以观察到,在我们设置了主键之后,就算我们插入数据的顺序并没有按照顺序来,但是当我们进行查找是可以发现他们是有序的,这是为什么?
设想,当我们访问一个数据时,有没有可能访问与这个数据相关的其他数据?由于局部性原理,我们访问时有很大可能会用到该数据附近的数据,因此我们如果可以一次性将某数据周围的数据页读取出来,那么下次进行访问时,就不需要访问磁盘进行io了,这样也就提高了效率。
这样主要是用于解释为什么mysql一次的读取单位为16KB,目的是为了减少io提高效率。
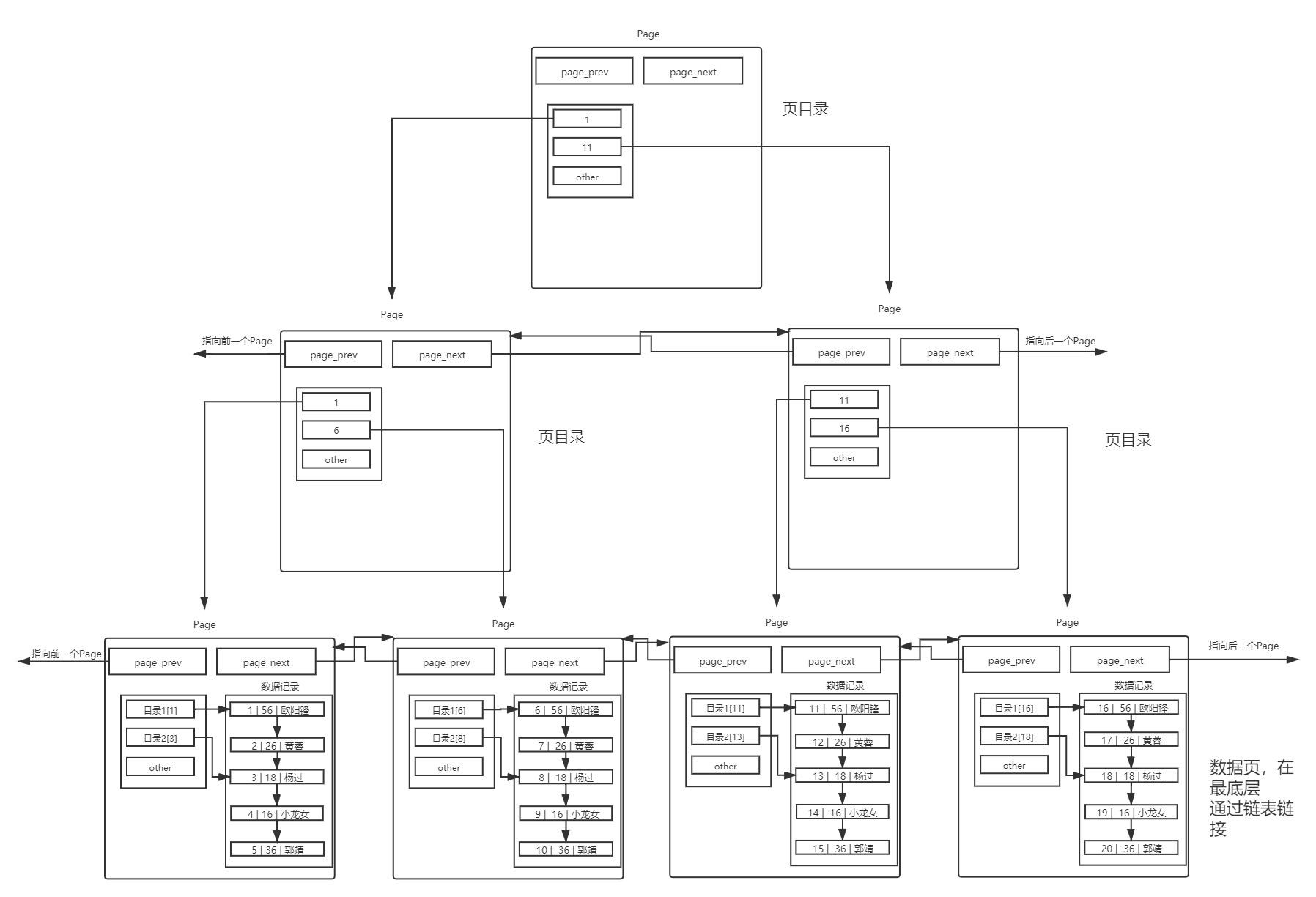
理解page
不同的 page,在mysql中都是16KB,采用两个指针构成双向链表
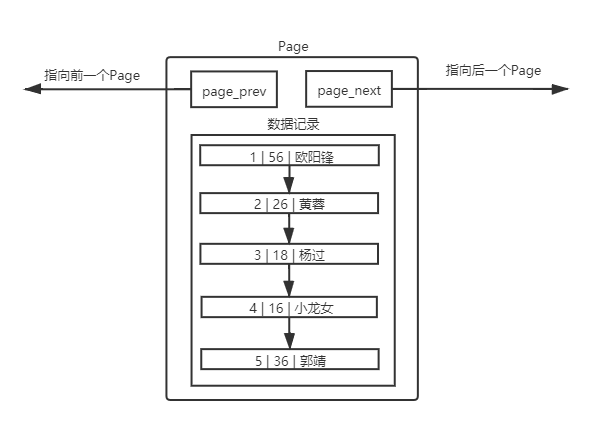
上文中对数据进行排序主要是因为有主键的问题,从上面的例子中我们也可以发现,每个数据都是按照主键顺序进行有序排列的。
而这种操作的主要目的则是上文的提升效率。如果因为排序而可以提前结束查找,那么效率就提升了。
多个page
好了,这样让我们再次设想一下,如果数据很多的话,一个一个page进行遍历查找,效率是不是很低?那么我们有没有什么办法提升效率?
那就是换一种数据结构来对数据进行存储。
MySQL中对数据进行存储采用的数据结构是B+树
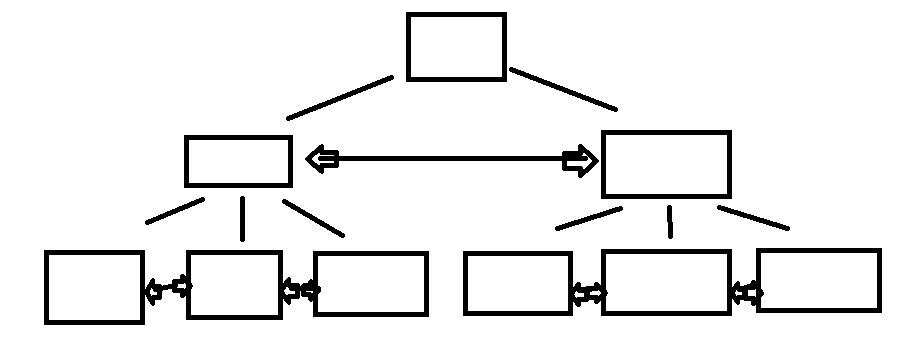
就是上面这样的结构,相邻的数据之间,通过指针进行连接,一个节点可以管理多个子节点。
与二叉树不同的是,二叉树只有左右两个节点,对于保存在磁盘中的数据,这样的查找方式会导致多次io,也就是效率会很低下。
但是B+树则可以一个父节点关联多个子节点,显著的减少了树高,也就减少了io次数,提升效率。
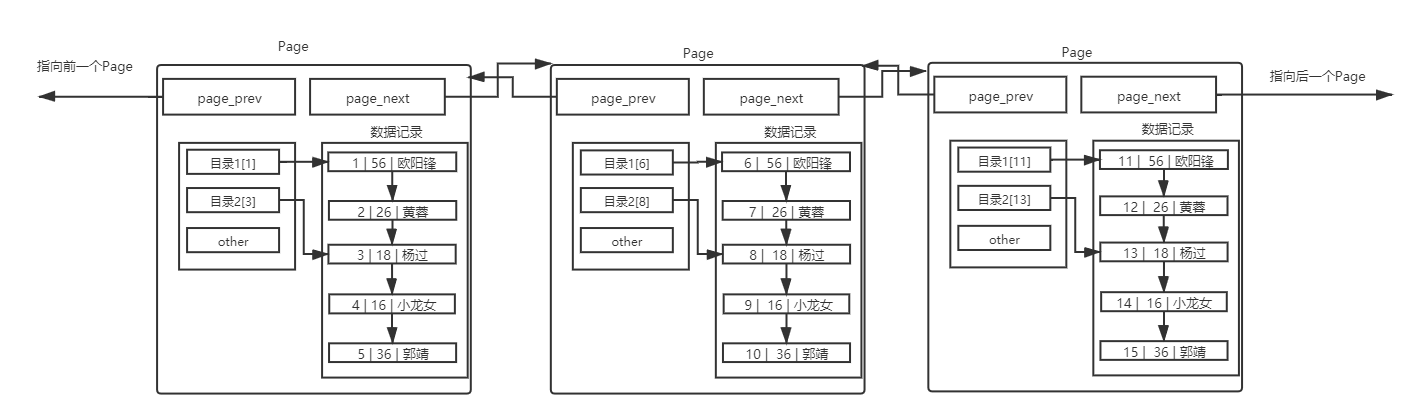
这样,我们只需要从最顶上节点开始,一次从磁盘中以Page为单位读取数据到内存中,然后向下去寻找目标Page,读取数据。
最终,我们形成的结构就是这样的,每一级父节点,都存储目标page索引(大索引,也就是分隔,比如第二层是以20为分隔(0,20,40),下一层就以4为分隔(0,4,8)。然后不同的索引处对应了不同的下一级节点地址,也就是存储的值)
通过计算来一层层获取到叶子节点,叶子节点中存储的就是实际的数据。
B树 VS B+树
我们从上面已经可以知道了B+树的结构是个什么样子,父节点存索引,叶子节点存数据,但这是B+树,还有一种树形结构,为B树,B+树实际上就是B树优化而来的。
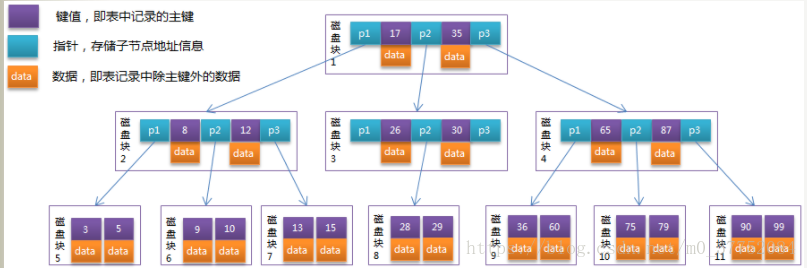
通过与B+树进行比较,我们可以发现,B+树是将所有的值存放在了叶子节点处,而B树则是在每一个节点中都会存放数据。这样会导致每一个page可以存放的数据量更少,也就会进一步导致树更高,io次数也会更多
同时B+树的叶子节点之间是通过指针相连的,这样的话,对于数据来说,范围查找也就更方便了
聚簇索引 VS 非聚簇索引
这个则是取决于存储引擎了,MySQL默认存储引擎为innodb(支持事务),也可以选择存储引擎为MYISAM(支持全文索引)。
这两种存储引擎除了功能上的区别外,就连存储方式也有所不同。
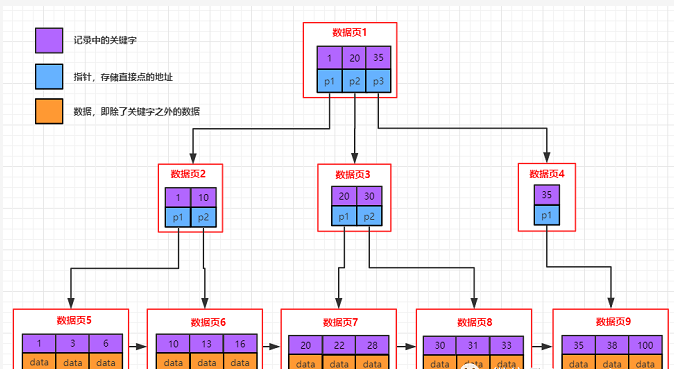
聚簇索引
叶子节点中存放的是具体的数据
非聚簇索引
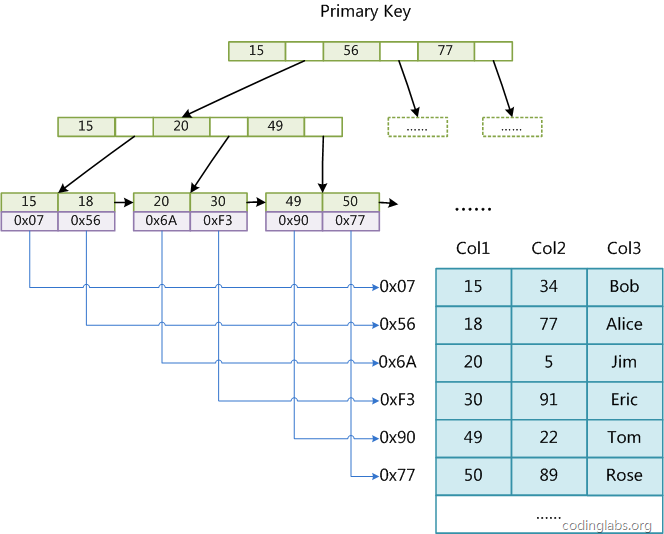
叶子节点中存放的是目标数据的物理地址(没错,最后找到的page页存放的不是实际数据,而是数据的存放地址)。
innodb对比MYISAM
上面的两种索引方式,是两种存储引擎的主键索引存储方式,然后就是两种存储引擎的普通索引存储方式。
MYISAM
存储方式和主键索引一样,也是叶子节点存储数据地址
innodb
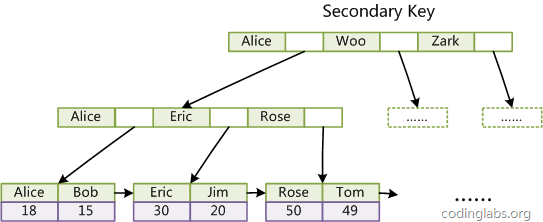
innodb的普通索引存储的就不是目标数据了,而是对应数据对应的主键索引。
设想,如果一个数据的数据量很大,如果我们将数据再次完完整整的复制一份,是不是非常的浪费空间,但是如果我们将数据采用主键索引的方式,再次去访问主键对应的B+树,就可以节省很多空间。
同时也不需要担心效率的问题,如果是高频访问到数据,那么该数据会进行缓存,而不是释放,读取内存的效率比起读取磁盘要高多了。