Linux osq_lock
文章目录
- osq_lock函数
- 相关数据结构
- 11虚线处
- 22虚线处
- step A
- step B
- step C
- 为什么next指针不可靠
- 参考
内核版本:5.15
osq_lock(optimistic spin queue)当内核配置CONFIG_MUTEX_SPIN_ON_OWNER时,mutex支持乐观自旋,osq成员就是乐观自旋需要持有的MCS锁队列。
osq_lock函数
bool osq_lock(struct optimistic_spin_queue *lock)
{struct optimistic_spin_node *node = this_cpu_ptr(&osq_node);struct optimistic_spin_node *prev, *next;int curr = encode_cpu(smp_processor_id());int old;node->locked = 0;node->next = NULL;node->cpu = curr;old = atomic_xchg(&lock->tail, curr);if (old == OSQ_UNLOCKED_VAL)return true;prev = decode_cpu(old);node->prev = prev;smp_wmb();WRITE_ONCE(prev->next, node);
//------------------11------------------------if (smp_cond_load_relaxed(&node->locked, VAL || need_resched() ||vcpu_is_preempted(node_cpu(node->prev))))return true;
//------------------22------------------------/* unqueue *//** Step - A -- stabilize @prev*/for (;;) {if (data_race(prev->next) == node &&cmpxchg(&prev->next, node, NULL) == node)break;if (smp_load_acquire(&node->locked))return true;cpu_relax();prev = READ_ONCE(node->prev);}/** Step - B -- stabilize @next*/next = osq_wait_next(lock, node, prev);if (!next)return false;/** Step - C -- unlink*/WRITE_ONCE(next->prev, prev);WRITE_ONCE(prev->next, next);return false;
}
相关数据结构
//per cpu 变量
struct optimistic_spin_node {struct optimistic_spin_node *next, *prev;int locked; /* 1 if lock acquired */int cpu; /* encoded CPU # + 1 value */
};//cpu共享变量
struct optimistic_spin_queue {/** Stores an encoded value of the CPU # of the tail node in the queue.* If the queue is empty, then it's set to OSQ_UNLOCKED_VAL.*/atomic_t tail;
};
11虚线处
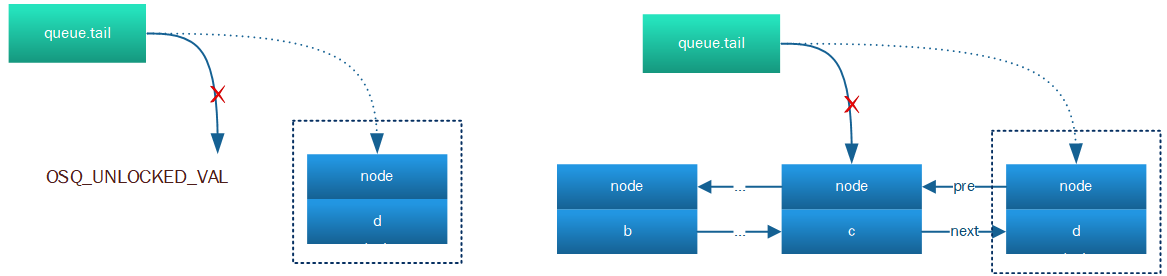
将本CPU所在percpu的node节点加入node链表的尾部,并修改queue类型的lock->tail指向自己,如下图的两种情况将节点d加入:
22虚线处
自选等待。如果node->locked==1,return true 即获得锁成功,直接返回;如果虚拟cpu被抢占或需要调度,smp_cond_load_relaxed函数返回false,其逻辑如下:
if (smp_cond_load_relaxed(&node->locked, VAL || need_resched() ||vcpu_is_preempted(node_cpu(node->prev))))return true;

往下走step A / step B / step C完成unqueue也即退出自旋。
step A
等待稳定前节点,然后断开前节点对自身的指向。
for (;;) {if (data_race(prev->next) == node && //为什么要做这个判断?cmpxchg(&prev->next, node, NULL) == node)break;if (smp_load_acquire(&node->locked))return true;cpu_relax();prev = READ_ONCE(node->prev);}
第一个if为什么要判断?因为会出现data_race(prev->next)==0的情况。原因请看为什么next指针不可靠章节
step B
等待稳定后节点,然后断开自己指向的后节点,如果lock->tail指向自己,修改为指向前一个或空。
osq_wait_next中的for循环:
for (;;) {if (atomic_read(&lock->tail) == curr &&atomic_cmpxchg_acquire(&lock->tail, curr, old) == curr) {break;}if (node->next) {next = xchg(&node->next, NULL);if (next)break;}cpu_relax();}
node->next已经不为空了,为什么还要if (next)的判断?原因请看为什么next指针不可靠章节
step C
断开自己,具体动作为将前后节点互相指向。
为什么next指针不可靠
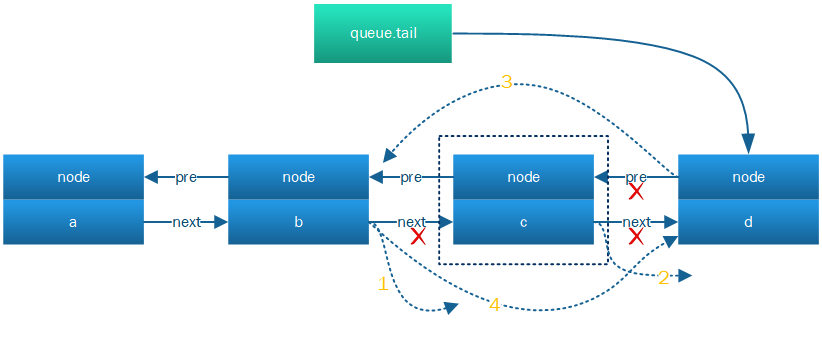
这里假定获得锁的是a,当前正在退出自旋的是c,它的退出过程是上图的1->2->3->4,具体对应的代码正是step A/B/C。
回到step A中data_race(prev->next)==0的情况是怎么出现的,此时c在退出队列,同时b也在自己的CPU上退出,也会经历跟c一样的1->2->3->4的过程,如果此时b
正发生了c中2,也即b->next=0,此时c就要等b完成退出并b的前后搭建好,就像c的3和4。
回到step B中node->next已经不为空了,还要if (next)判断的情况。
参考
【进程同步】osq锁