【C++】STL简介 + string1
1. STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的
组件库,而且是一个包罗数据结构与算法的软件框架。
STL的六大组件:
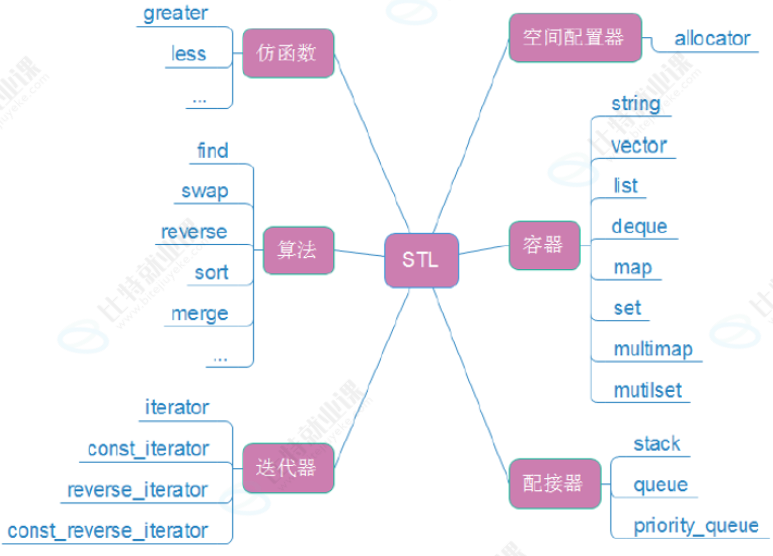
STL的版本

网上有句话说:“不懂STL,不要说你会C++”。STL是C++中的优秀作品,有了它的陪伴,许多底层
的数据结构以及算法都不需要自己重新造轮子,站在前人的肩膀上,健步如飞的快速开发。
如何学习STL?
第一境界:熟用STL
第二境界:了解泛型技术的内涵与STL的学理乃至实作
第三境界:扩充STL
简单总结一下:学习STL的三个境界:能用,明理,能扩展 。
2. string
2.1 为什么学习string类?
C语言中的字符串:
C语言中,字符串是以'\0'结尾的一些字符的集合,为了操作方便,C标准库中提供了一些str系列
的库函数,但是这些库函数与字符串是分离开的,不太符合OOP的思想,而且底层空间需要用户
自己管理,稍不留神可能还会越界访问。
在OJ中,有关字符串的题目基本以string类的形式出现,而且在常规工作中,为了简单、方便、
快捷,基本都使用string类,很少有人去使用C库中的字符串操作函数。
2.2 标准库中的string类
string类的文档介绍:http://www.cplusplus.com/reference/string/string/?kw=string
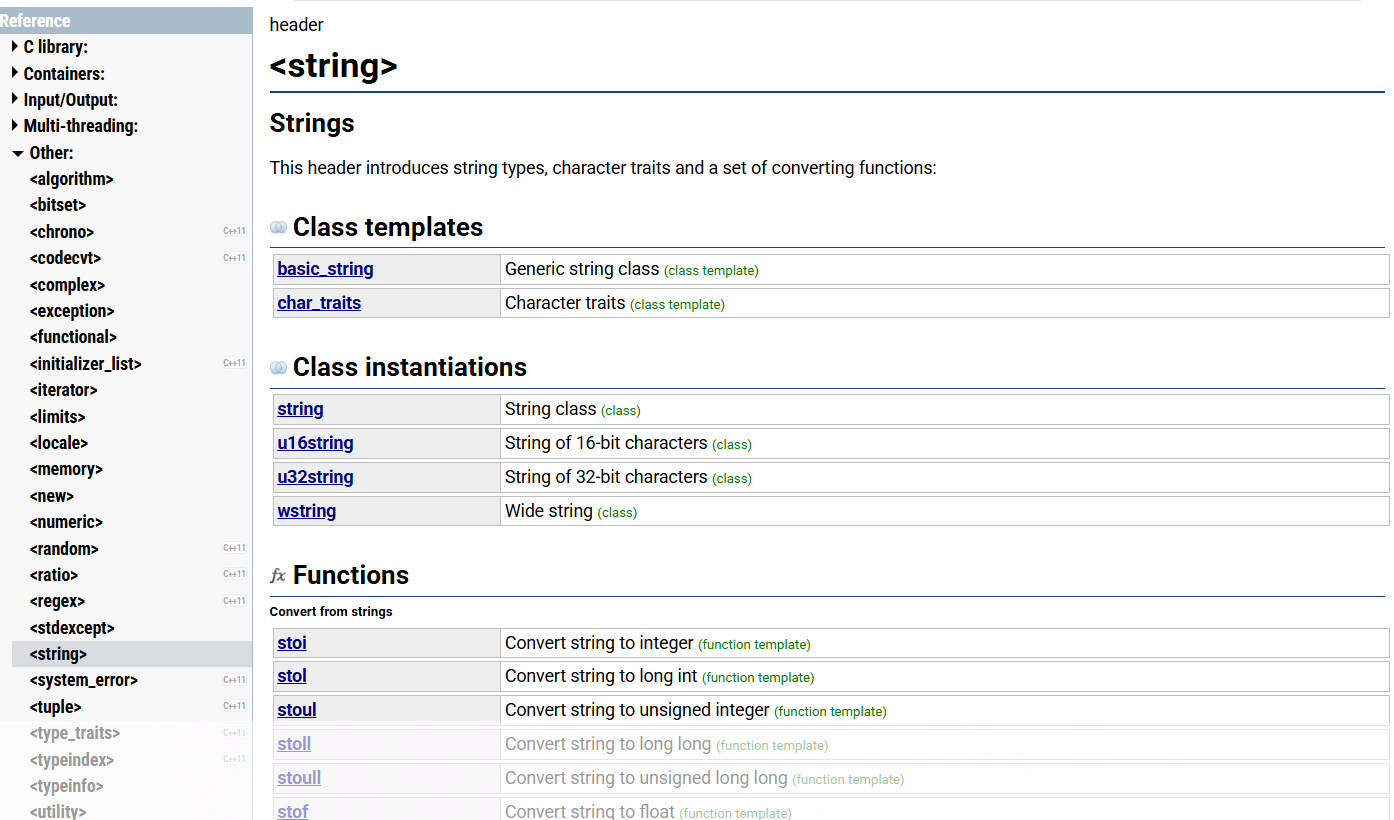
每个函数比如说构造函数点进去,会有详细的功能介绍
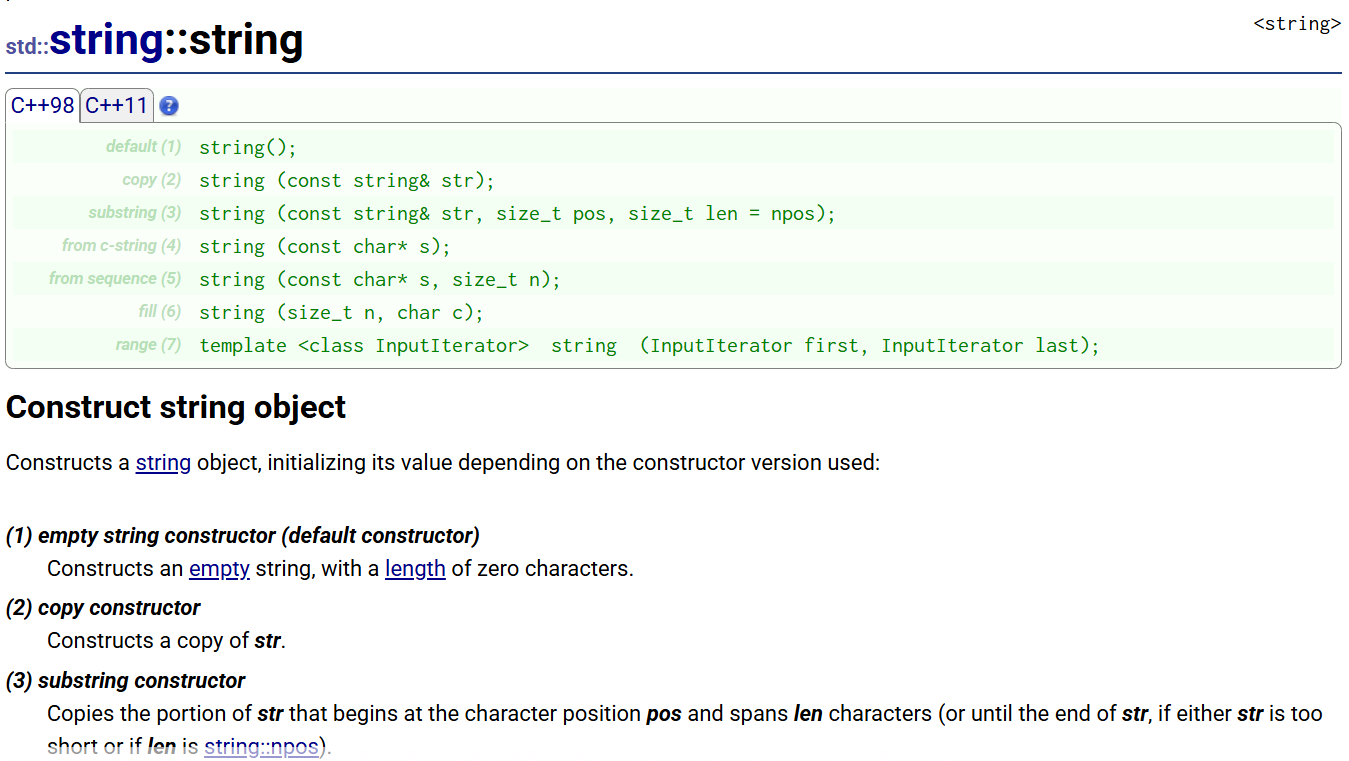
后续的学习主要是看文档
https://legacy.cplusplus.com/reference/ -> 它不是C++的标准文档,但是这个方便看(日常中,看这个文档)
https://en.cppreference.com/w/ -> C++的官方文档,但是这个没有上面的看着舒服和方便
在使用string类时,必须包含#include头文件以及using namespace std;
这个世界的所有信息都可以用字符串去存储表示,那为什么还需要int、double....?? -> 因为需要运算
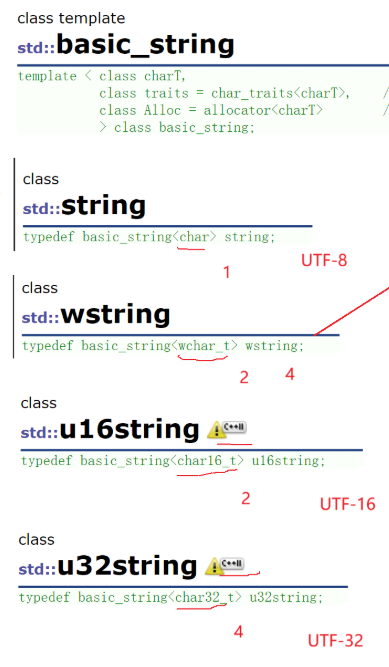
2.3 字符编码
编码:值和符号的映射关联集合
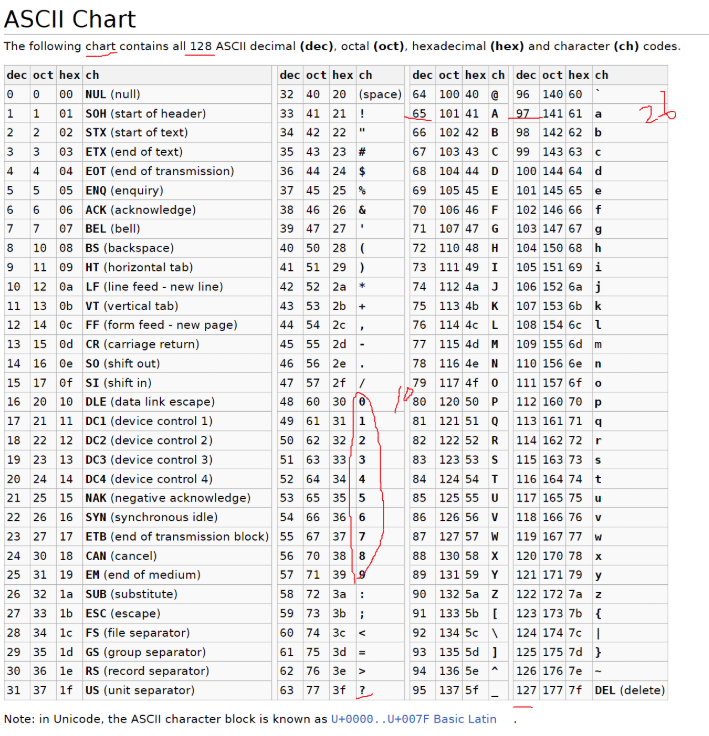
1. ASII码:
char:字符型数据,属于整型数据的一种,占用一个字节
2. 单一码/万国码(Unicode)

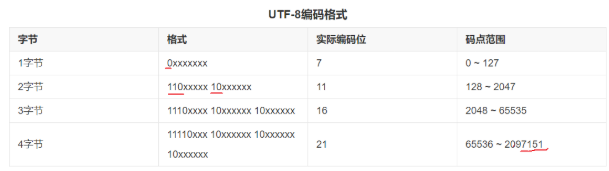

2.3 GBK
GBK是我们中国的编码,把日文你和韩文也编进去了
GBK用两个字节就可以编我们的汉字;GBK不是随意乱编的,它是把同音字编到一起了
windows下,很多时候就是GBK
GBK也兼容ASCII,GBK跟UTF-8类似,所以GBK、UTF-8都可以用string存储
int main()
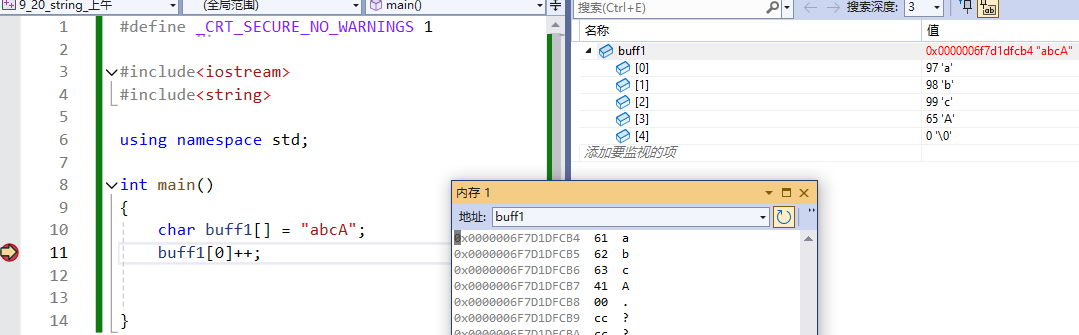
{char buff1[] = "abcA";buff1[0]++;char buff2[] = "比特abc"; //8(一个汉字占两个字节)cout << sizeof(buff2) << endl; buff2[1]++;cout << buff2 << endl; //鄙特abcbuff2[1]++;cout << buff2 << endl; //笔特abcbuff2[3]++;cout << buff2 << endl; //笔藤abcbuff2[3]++;cout << buff2 << endl; //笔腾abcreturn 0;}2.4 string类的常用接口说明
1. 构造函数
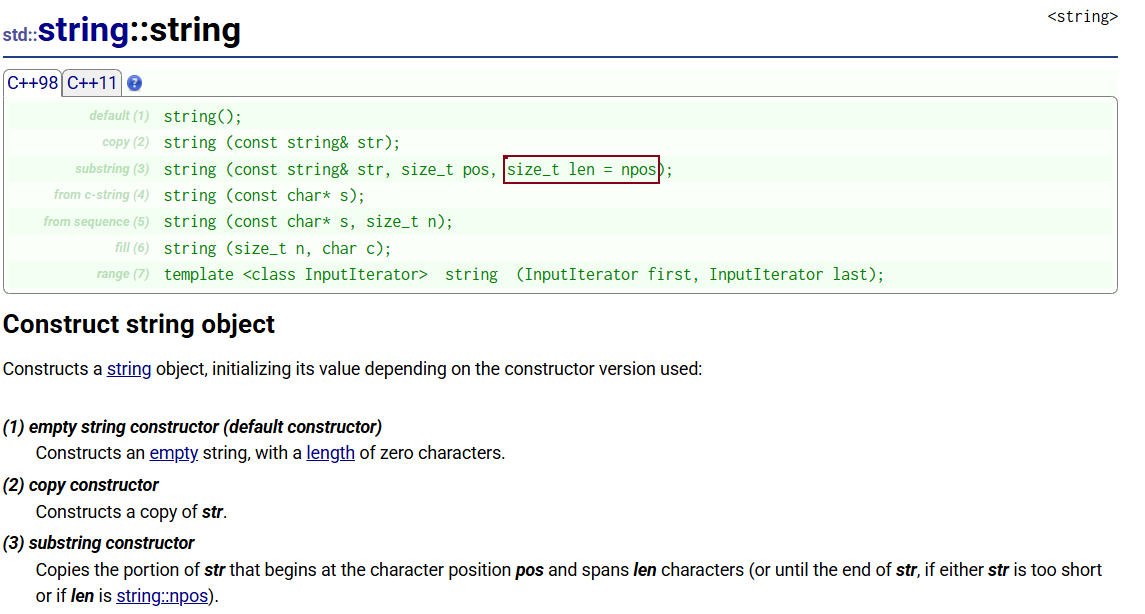
知识点:
①string也可以用常量字符串来构造(第4点),给一个字符串数组的指针,常量字符串本质上是字符数组,数组传参会转换成指针
②npos:npos属于类域,string定义的const静态成员变量,不传npos,就会拷贝到结尾
常见构造:
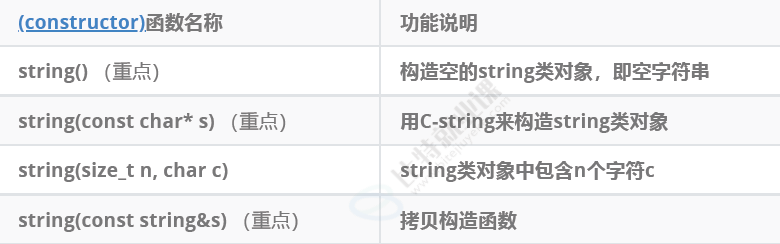
void test_string1()
{// 构造string s1; // 构造空的string类对象s1string s2("hello world"); // 用C格式字符串构造string类对象s2string s3(s2); //拷贝构造
}2. string类对象的析构:
构造是很重要的,析构不重要(我们要了解析构的功能,但是它不重要,因为它自动调用)
3. string类对象的赋值:

void test_string1()
{// 构造string s1; // 构造空的string类对象s1string s2("hello world"); // 用C格式字符串构造string类对象s2string s3(s2); //拷贝构造cout << s1 << endl;cout << s2 << endl;cout << s3 << endl;string s4(s2, 0, 5);cout << s4 << endl;//pos位置拷贝到结尾string s5(s2, 6, 15);cout << s5 << endl;string s6(s2, 6);cout << s6 << endl;string s7("hello world", 6);cout << s7 << endl;string s8(10, '*');cout << s8 << endl;//赋值s7 = "xxxxx";cout << s7 << endl;
}4. string类对象的访问及遍历操作

operator[](重点)

它是为了让我们的对象像数组一样去使用,string、vector它们底层都是数组,这里的pos就是下标
class string
{
public:char& operator[] (size_t pos){return _str[pos]; //返回pos位置的字符}
private:char* _str;size_t _size; //表示有多少个字符,不包含\0size_t _capacity;
};void test_string2()
{string s1("hello world");s1[0] = 'x'; //[]运算符返回的是这个字符的引用,所以能读能写cout << s1 << endl;cout << s1[0] << endl;// 越界有严格断言检查//s1[12]; //断言//s1.at(12); // 抛异常
}
int main()
{test_string2();return 0;
}at:

at和[]的功能是一样的,唯一的区别:它们对错误处理的方式不同,如果越界了,at会抛异常,[]会断言,嫌断言(直接终止掉程序)太激烈了,可以用at(抛异常,可以被捕获,至少程序不会终止)
迭代器(重点)
迭代这个词本身就是用来遍历的
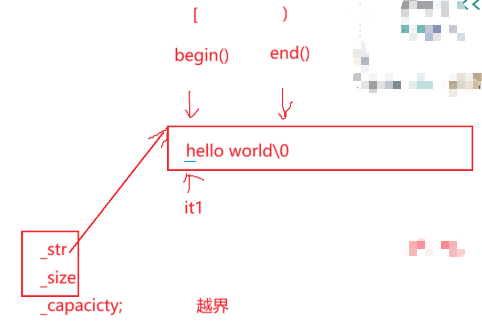
string::iterator it1 = s1.begin();在string这个类域里面有iterator的一个类型(iterator:迭代器类型)
在一个类域里面还有一个类型,无非就两种:1. 内部类 2. 在内部进行typedef出来的
知识点
begin:开始位置的迭代器(第一个有效数据)
end:最后一个字符的下一个位置,就是指向\0的位置(\0不算有效字符)
最后的\0叫标识字符,标识字符串的结束
它俩本质上构成一个左闭右开的区间 -> [begin,end)
所有容器都有迭代器,list也有
所有容器内部都有一个iterator的成员(内嵌)类型
void test_string2()
{string s1("hello world");s1[0] = 'x'; //[]运算符返回的是这个字符的引用,所以能读能写cout << s1 << endl;cout << s1[0] << endl;// 越界有严格断言检查//s1[12]; //断言//s1.at(12); // 抛异常// 计算长度时不包含/0cout << s1.length() << endl; // 推荐用size,对于二叉树,用length不合理cout << s1.size() << endl;// 遍历 or 修改for (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << s1 << endl;//迭代器, 行为像指针一样的东西string::iterator it1 = s1.begin();while (it1 != s1.end()){(*it1)--; // 解引用, 可以修改cout << *it1 << " ";++it1;}cout << endl;list<int> lt;lt.push_back(1);lt.push_back(2);lt.push_back(3);list<int>::iterator lit = lt.begin();while (lit != lt.end()){cout << *lit << " ";++lit;}cout << endl;}
迭代器有两种,一种iterator,一种是const(迭代器指向的对象是不可修改的)


反向迭代器
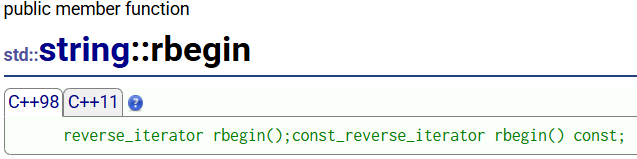
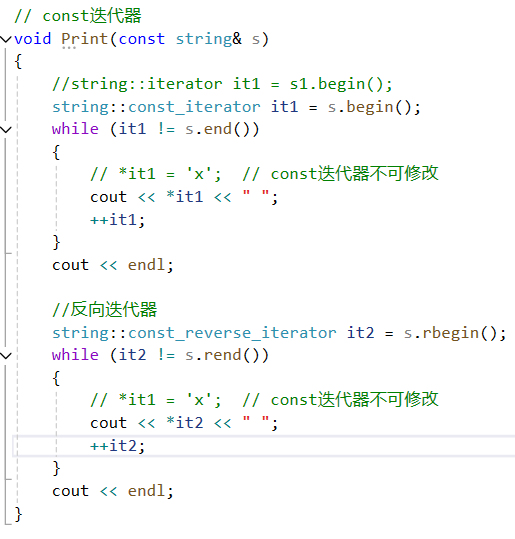
从底层实现的角度思考:迭代器的实现一定是依赖于指针实现的

cbegin、cend 是C++11增加的版本(更规范一点点),跟(const)begin、(const)end是一样的,平时用begin、end就可以
不同容器的迭代器虽然使用上没区别,但是底层原理各种方面还是有很大区别的:
迭代器最大的特点:
1. 提供统一的方式遍历修改容器
2. 算法可以泛型化,算法借助迭代器处理容器的数据
(迭代器也是算法和容器之间的桥梁)
STL里的算法,通用算法都写到了算法的头文件 #include <algorithm>,比如find
通用的查找算法(直接官方文档页面搜索find):
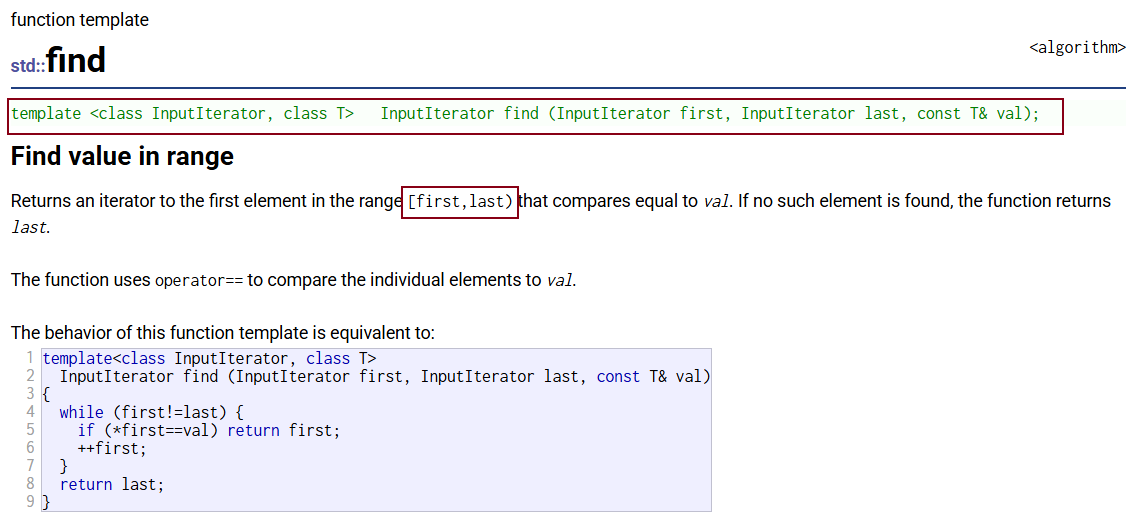
在算法里面迭代区间一定是左闭右开的
string::iterator ret1 = find(s1.begin(), s1.end(), 'x');
if (ret1 != s1.end())
{cout << "找到了x" << endl;
}list<int> ::iterator ret2 = find(lt.begin(), lt.end(), 2);
if (ret2 != lt.end())
{cout << "找到了2" << endl;
}auto和范围for
auto关键字
auto会通过右边的值自动推导它的类型,但是auto降低了程序的可读性
![]()
注意:
auto不要满天飞
void test_string2()
{//auto自动推导类型,C++11才有int i = 0;//通过初始化表达式类型自动推导对象类型 auto j = i;auto k = 10;//string::iterator ret1 = find(s1.begin(), s1.end(), 'x');//auto ret1 = find(s1.begin(), s1.end(), 'x');auto p1 = &i;// 指定一定是指针auto* p2 = &i;cout << p1 << endl;cout << p2 << endl;// 引用int& r1 = i;// r2不是int&引用,是intauto r2 = r1;// r3是int&引用auto& r3 = r1;cout << &r2 << endl;cout << &r1 << endl;cout << &i << endl;cout << &r3 << endl;// 范围for,C++11// 自动取容器数据赋值,自动迭代++,自动判断结束for (auto ch : s1){cout << ch << ' ';}cout << endl;for (auto e : lt){cout << e << endl;}cout << endl;}范围for:
用法类似与python

所以我们有三种遍历方式(对于string):
1. 下标+[]
2. 迭代器
3. 范围for
//C++11(现代C++)
//范围for(遍历)
//自动取容器数据赋值,自动迭代++,自动判断结束
//这个语法很多地方也把它叫做"语法糖"
//for (auto ch : s1)
for (char ch : s1) //遍历string ch是随便取的
{cout << ch << ' ';
}
cout << endl;for (auto e : lt) //遍历链表 这里面的auto不是必须用的(只是习惯去用auto,不用auto也可以)
{cout << e << ' ';
}
cout << endl;
用范围for要注意一下:
1. 如果你不修改它的数据,你就这样写
for (char ch : s1)
{cout << ch << ' ';
}
cout << endl;for (auto e : lt)
{cout << e << ' ';
}
cout << endl;如果你要修改,就要加个&(引用)
for (auto& ch : s1)
{ch -= 1;
}
cout << endl;如果你不修改,但是这个对象比较大,你不想让这个地方产生拷贝,你用引用,但尽量加上const -> 就是加const &
for (const auto& ch : s1)
{cout << ch << ' ';
}
cout << endl;范围for底层的原理是迭代器
//支持迭代器的容器,都可以用范围for
//数组也支持(特殊处理)
int a[10] = { 1,2,3 };
for (auto e : a)
{cout << e << " ";
}
cout << endl;for总结:
- 迭代器 可以遍历可以修改
- 范围for 可以遍历可以修改
- []+下标 可以遍历可以修改,at 也可以遍历可以修改
2.5 string类对象的容量操作
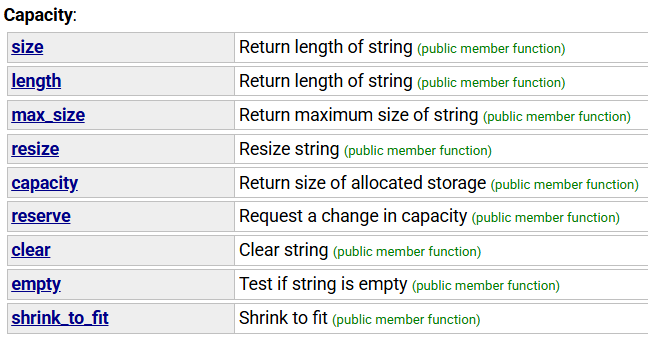
注意:
1. size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()
2. clear()只是将string中有效字符清空,不改变底层空间大小
3. resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不同的是当字符个数增多时:resize(n)用0来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
4. reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小
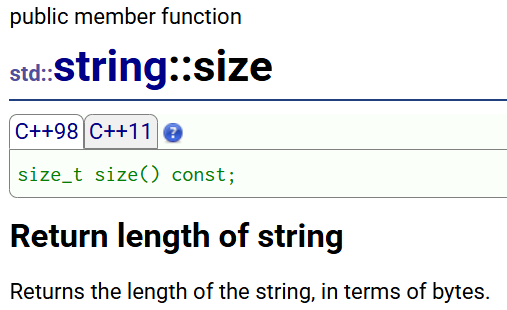
①size(重点)和length
知识点:
size和length是一样的(随便用,一般建议用size),没有区别,都是返回长度
注意:虽然它们后面是有\0的,但它俩都不包含\0
void test_string2()
{string s1("hello world");s1[0] = 'x'; //[]运算符返回的是这个字符的引用,所以能读能写cout << s1 << endl;cout << s1[0] << endl;// 越界有严格断言检查//s1[12]; //断言//s1.at(12); // 抛异常// 计算长度时不包含/0cout << s1.length() << endl; // 推荐用size,对于二叉树,用length不合理cout << s1.size() << endl;// 遍历 or 修改for (size_t i = 0; i < s1.size(); i++){s1[i]++;}cout << s1 << endl;
}int main()
{test_string2();return 0;
}②max_size、capacity、clear(重点)
知识点
1.
max_size 返回这个string到底最大能有多长这个接口是一个没有意义的接口
2. capacity:容量
size和capacity都不包含\0,但是它俩都有\0
3. clear就是把数据给清掉了(数据清到0,\0就挪到前面去了),但是不会清空间
也就是说size变成0,capacity不会变
代码演示:
void test_string3()
{string s1("hello world");cout << s1.max_size() << endl;cout << s1.size() << endl; // 不包含结尾的\0 11cout << s1.capacity() << endl; // 存储实际有效字符个数,不包含结尾的\0 15s1.clear();cout << s1.size() << endl; // 不包含结尾的\0 0 cout << s1.capacity() << endl; // 存储实际有效字符个数,不包含结尾的\0 15
}③empty(重点)
![]()
empty:判断是否为空
string扩容:
1. 插入
push_back -> 尾插
void TestCapacity()
{string s1;//s1.reserve(200); // 确定知道要插入多少字符,提前扩容size_t old = s1.capacity();cout << s1.capacity() << endl;for (size_t i = 0; i < 200; i++){s1.push_back('x');if (s1.capacity() != old){cout << s1.capacity() << endl;old = s1.capacity();}}
}string扩容的方式:

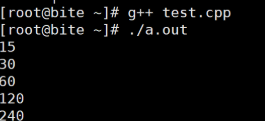
vs2022 1.5倍扩容(除了第一次) gcc(linux系统下):(2倍扩容)
STL设计是一种规范
规定哪些容器和算法,要实现哪些接口,不同的编译平台实现是不一样的
④reserve(重点)
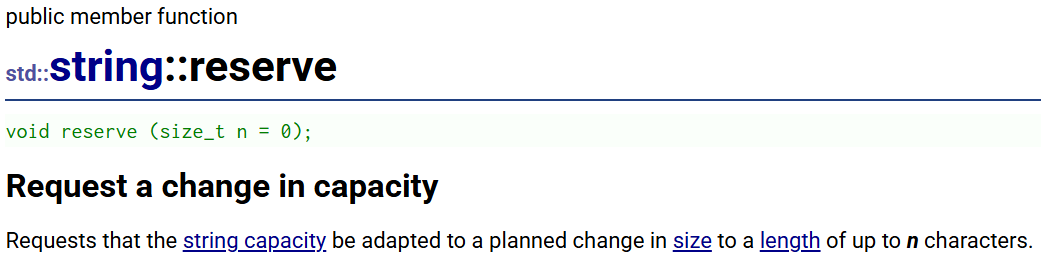
reserve:保留的意思
reverse:颠倒,反转的意思
不要把它俩弄混
reserve:请求capacity的变化,它就是一个手动扩容的接口
你给n,就会把容量扩到n那么大,甚至比n还大(至少得到n)
string s2("hello world");
cout << s2.size() << endl;
cout << s2.capacity() << endl;s2.reserve(20); //capacity增长至少到20或者比20大,都行
cout << s2.size() << endl;
cout << s2.capacity() << endl;s2.reserve(5);
//s2.shrink_to_fit(); // 缩容,一般不要用,代价不小
cout << s2.size() << endl; //capacity有可能会变,有可能不会变,但是它肯定不会到5(因为不能改变内容)
cout << s2.capacity() << endl; 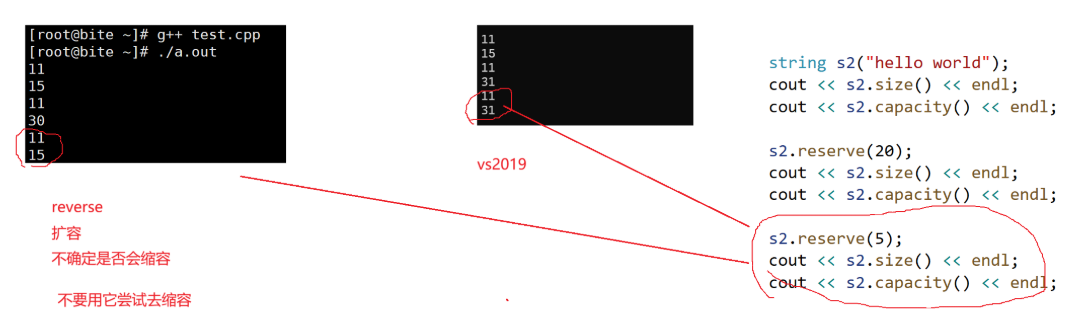
void TestCapacity() //reserve的核心作用就是解决这里的问题
{string s1;//s1.reserve(200); // 确定知道要插入多少字符,提前扩容size_t old = s1.capacity();cout << s1.capacity() << endl;for (size_t i = 0; i < 200; i++){s1.push_back('x'); //提前扩容的话,这儿就不会扩容了,就提高了效率if (s1.capacity() != old){cout << s1.capacity() << endl;old = s1.capacity();}}
}不知道要插入多少数据,就不要用reserve
![]()
真要缩容,这个shrink_to_fit 接口就是缩容的一个接口(也不会改变内容),不确定缩到跟size一样大
s2.shrink_to_fit(); // 缩容,一般不要用,代价不小
cout << s2.size() << endl;
cout << s2.capacity() << endl; 但是一般情况下,不建议缩容
本质上,缩容是一种经典的以时间换空间的逻辑
扩容、缩容是不影响它里面的数据的
⑤resize(重点)
resize是对size进行一个改变,这个就不涉及容量的问题,主要是要改变它里面的数据
resize既可以插入也可以删除,甚至还会扩容
string s3("hello world");
cout << s3 << endl;// <当前对象的size,相当于保留前n个,删除后面的数据
s3.resize(5);
cout << s3 << endl;// >当前对象的size,插入数据
s3.resize(10, 'x');
cout << s3 << endl;s3.resize(30, 'y');// 扩容了
cout << s3 << endl;resize在string部分用的不是很多,但是在vector(顺序表)用的就很多
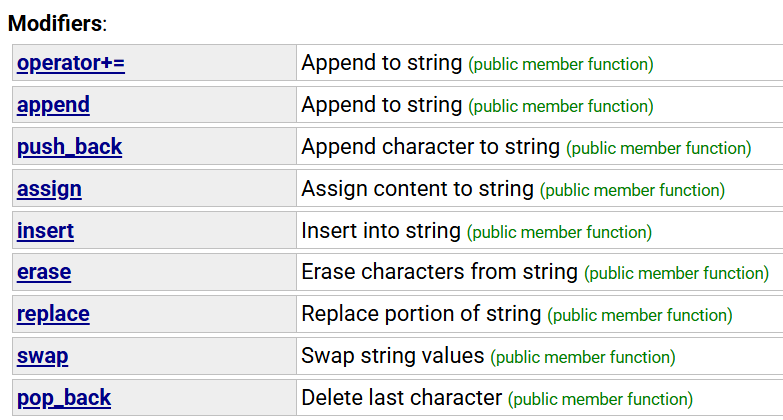
2.6 string类对象的修改操作
注意:
1. 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
2. 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
①append
append:追加
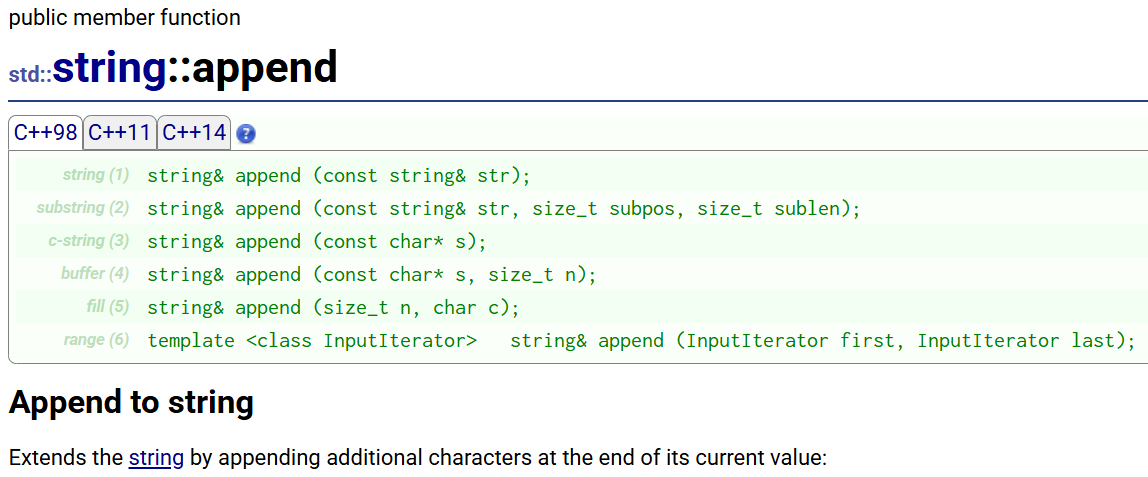
最常用的是第3个版本:
string s1("hello world");
s1.push_back('%');
s1.append("hello bit");
cout << s1 << endl;s1.append(10, '#');
cout << s1 << endl;string s2(" apple hello!");
//s1.append(s2);
s1.append(++s2.begin(), --s2.end());
cout << s1 << endl;②operator+=(重点)

因为+=返回的是自己,所以可以用&(引用)返回
string s3("hello world");
s3 += ' ';
s3 += "hello bit";
cout << s3 << endl;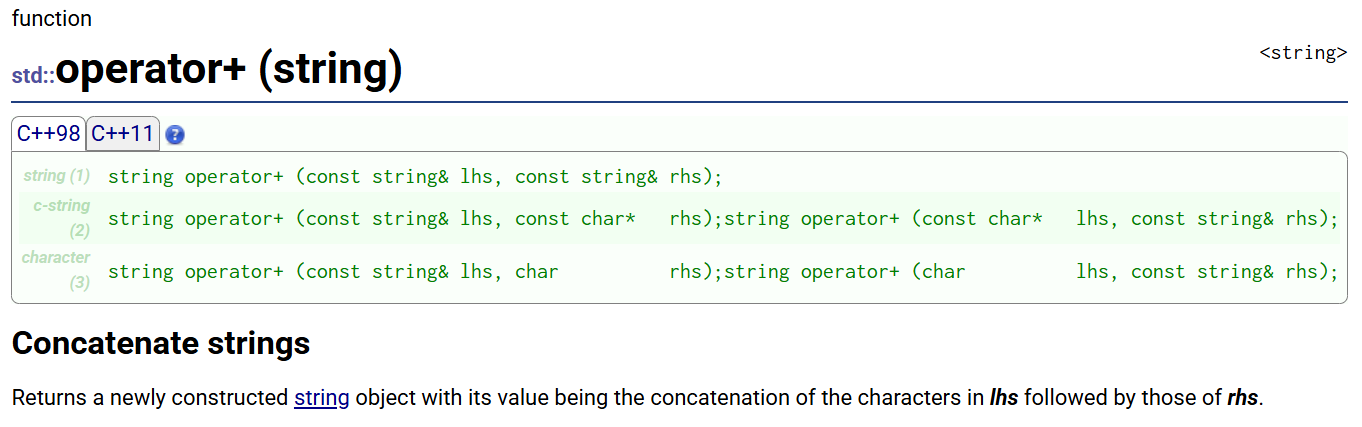
+ 没有重载为成员函数,重载成了非成员函数(重载成了全局的),+是以传值的方式返回(+是不改变自己的)
成员函数string一定在第一个位置,要是+重载为成员函数,它就做不了以下的事情:
cout << s3 + "xxxx" << endl;
cout << "xxxx" + s3 << endl;顺便说一下:
比较大小也是一样的,是按ASCII来比较的,没有重载为成员函数,重载成了非成员函数(重载成了全局的)
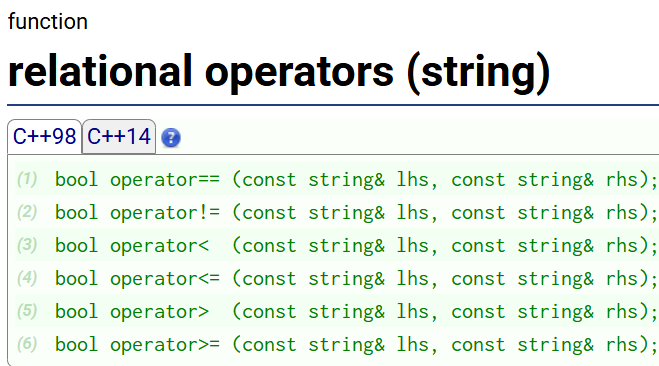
非成员函数:

assign也是一种赋值
s3.assign("yyy");
cout << s3 << endl;pop_back:尾删
③ insert
insert:头插
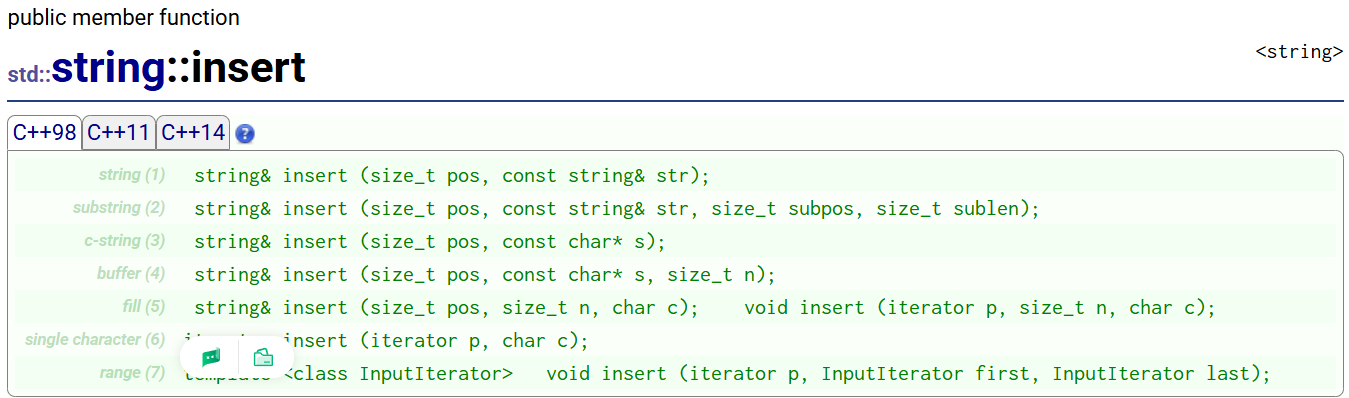
insert要谨慎使用,效率不太高(因为要挪动数据)
string s1("hello world");
cout << s1 << endl;s1.insert(0, "xxx"); // 头插
cout << s1 << endl;s1.insert(0, 1, '#');
cout << s1 << endl;s1.insert(5, 1, '#');
cout << s1 << endl;s1.insert(s1.begin(), '$');
cout << s1 << endl;④erase
erase:头删
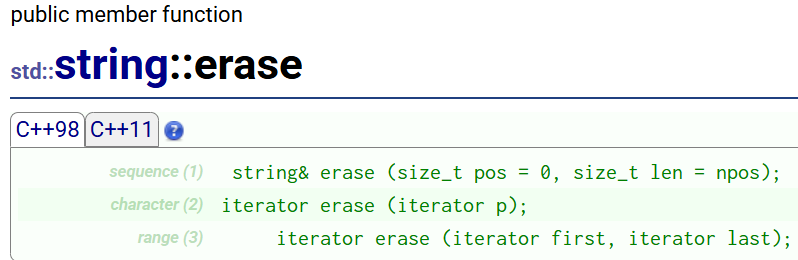
string s2("hello world");
cout << s2 << endl;s2.erase(s2.begin()); // 头删
cout << s2 << endl;s2.erase(0, 1);
cout << s2 << endl;s2.erase(5, 2);
cout << s2 << endl;s2.erase(5);
cout << s2 << endl;⑤replace
replace:替换
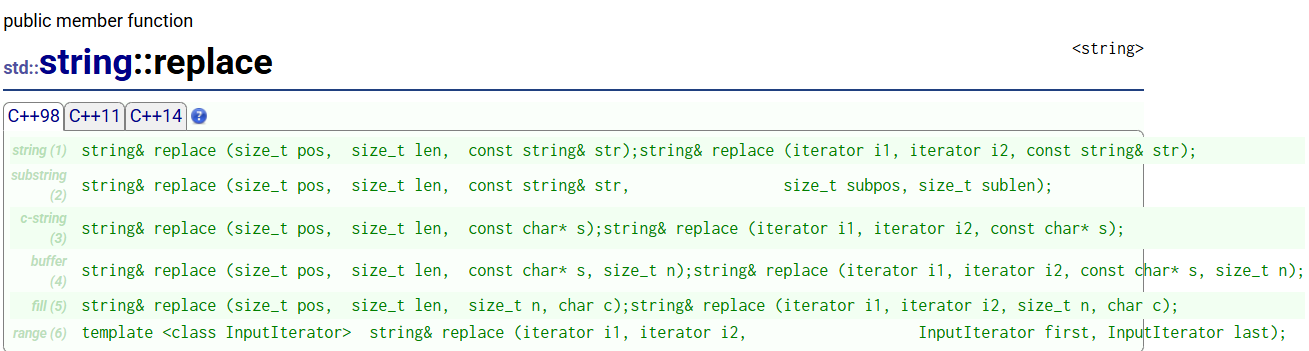
少量用是没问题的,但是要谨慎使用,replace效率不高(因为它也要挪动数据)
string s3("hello world");
cout << s3 << endl;s3.replace(5, 1, "%%%");
cout << s3 << endl;s3.replace(5, 3, "*");
cout << s3 << endl;⑥find + npos(重点)
find -> 找
如果没有匹配,它就会返回npos
// 所有空格替换为%%
string s4("hello world hello bit");
cout << s4 << endl;// 方法一,这个方法效率很低
size_t pos = s4.find(' ');
while (pos != string::npos)
{s4.replace(pos, 1, "%%");// 找下一个空格pos = s4.find(' ', pos + 2);
}cout << s4 << endl;// 方法二,这个方法效率很高
string s5("hello world hello bit");
cout << s5 << endl;string s6;
s6.reserve(s5.size());
for (auto ch : s5)
{if (ch != ' '){s6 += ch;}else {s6 += "%%";}
}
cout << s6 << endl;