yolov8 检测

YOLOv8 是 ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本。YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。
YOLOv8原生支持多种任务类型,包括检测、分类、分割、姿态、定向边界框等
YOLOV8引入的新特性包括:
一、网络结构
- C2f模块,更强的特征融合
- 检测头分离,检测和分类信息由之前的一个检测头输出变成独立输出
- 检测结果输出,从输出一个具体结果变成输出分布概率
二、anchor free
- 不再需要anchor辅助
三、损失计算
- 正负样本匹配更简单高效,根据预测动态筛选正负样本
- DFL 分布焦点损失,将输出一个独立值变成输出分布概率
网络结构
以yolov8l.yaml网络为例,如下图所示:
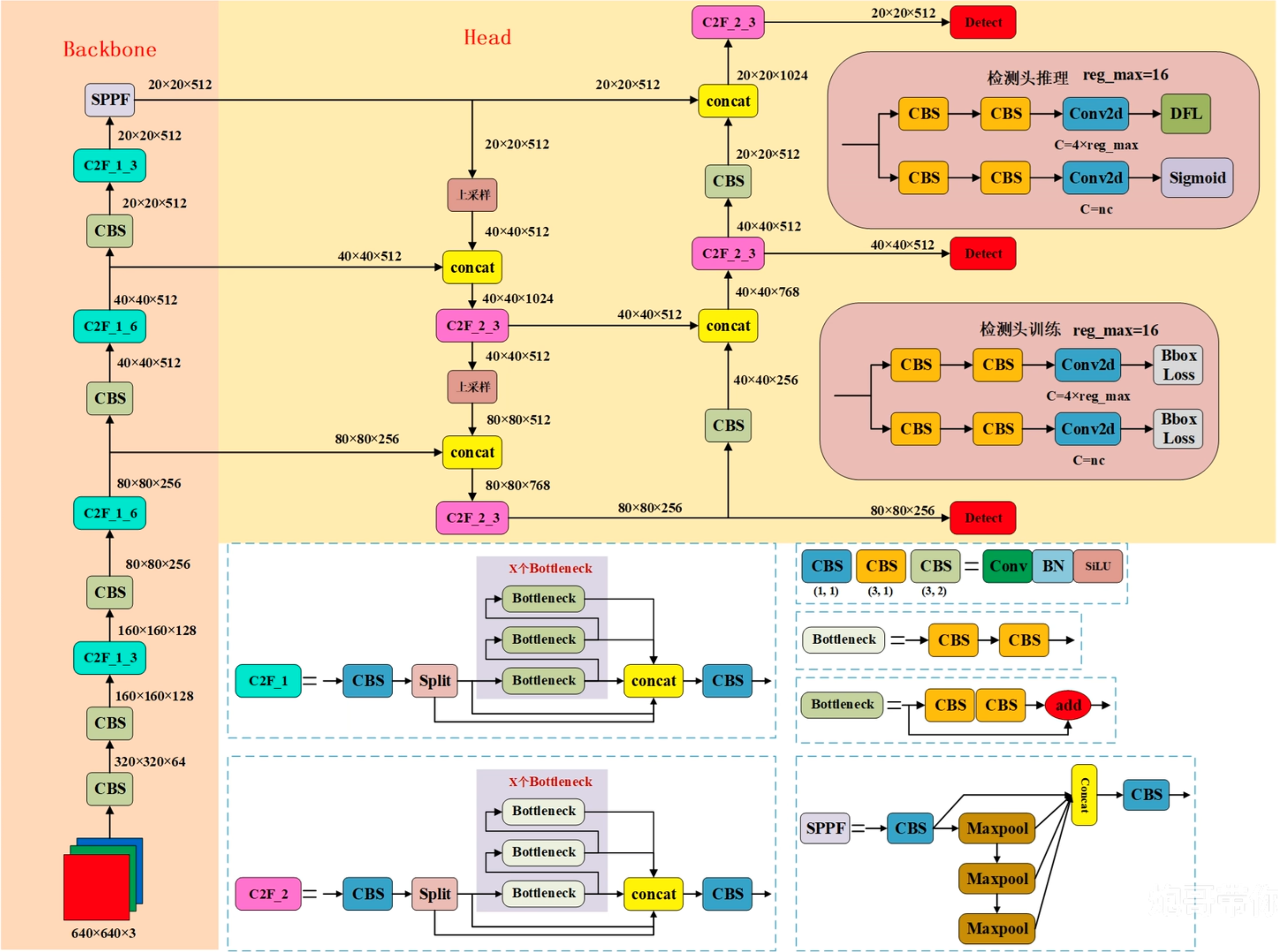
和yolov5的网络结构整体上比较类似,包括骨干、颈部、头部,FPN特征金字塔,PAN链路聚合网络等经典网络结构的设计都能看到。此外yolov8网络上的创新点也很多,包括更强的特征融合模块C2f,多检测头共用一套网络等。
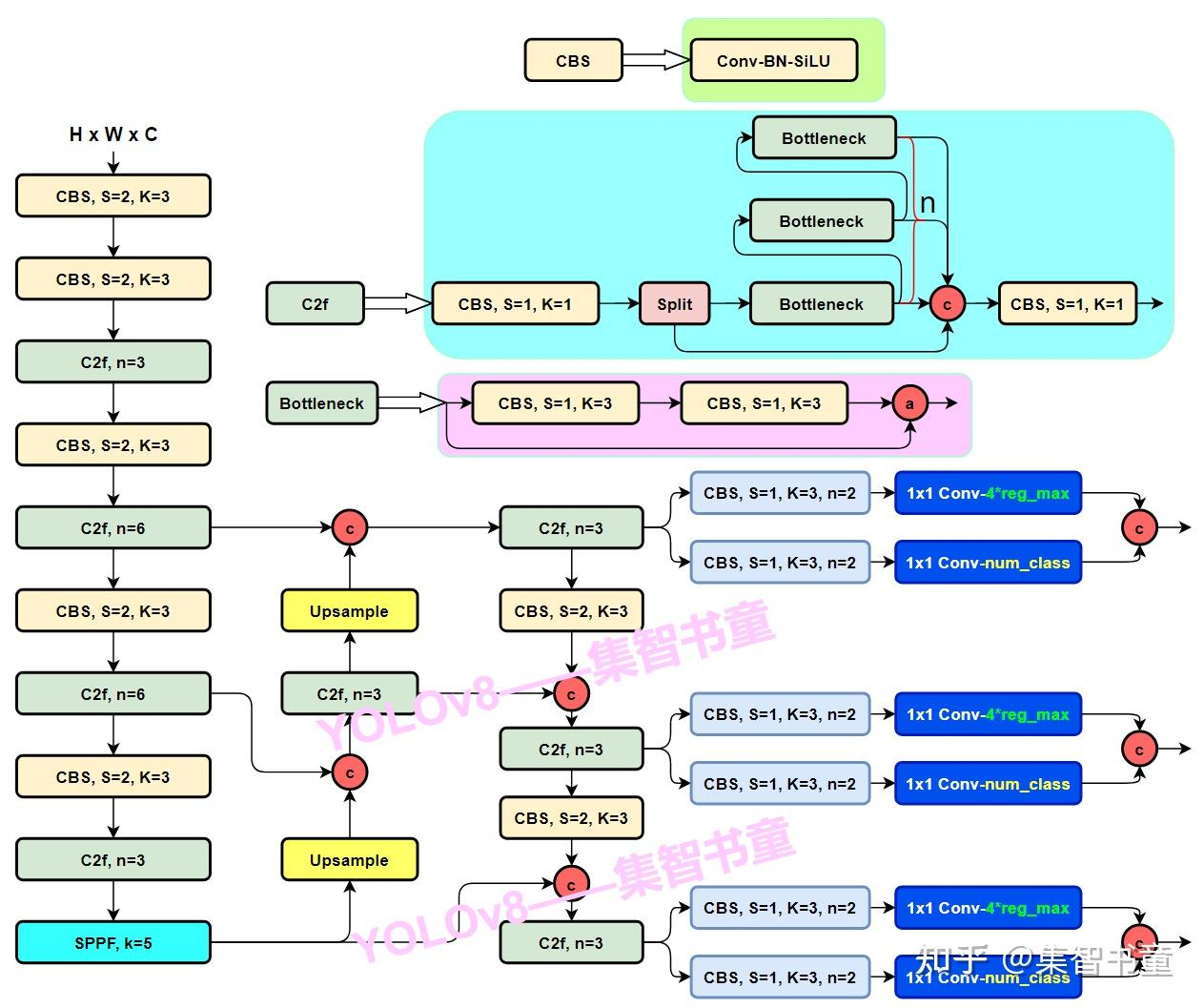
yolov8 的基础结构:
- CBS
- Bottleneck
- C2F_1
- C2F_2
- SPPF
- Detect
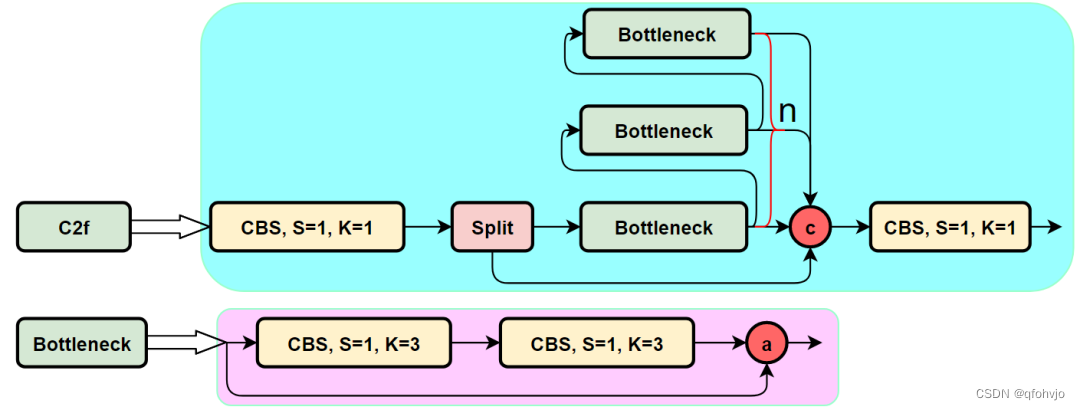
C2f
C2F模块(Cross-stage Feature Fusion)是一种用于特征融合的设计,主要用于增强不同阶段间特征的交互,提升模型对多尺度目标的检测能力。
网络结构
C2f的网络结构如下:
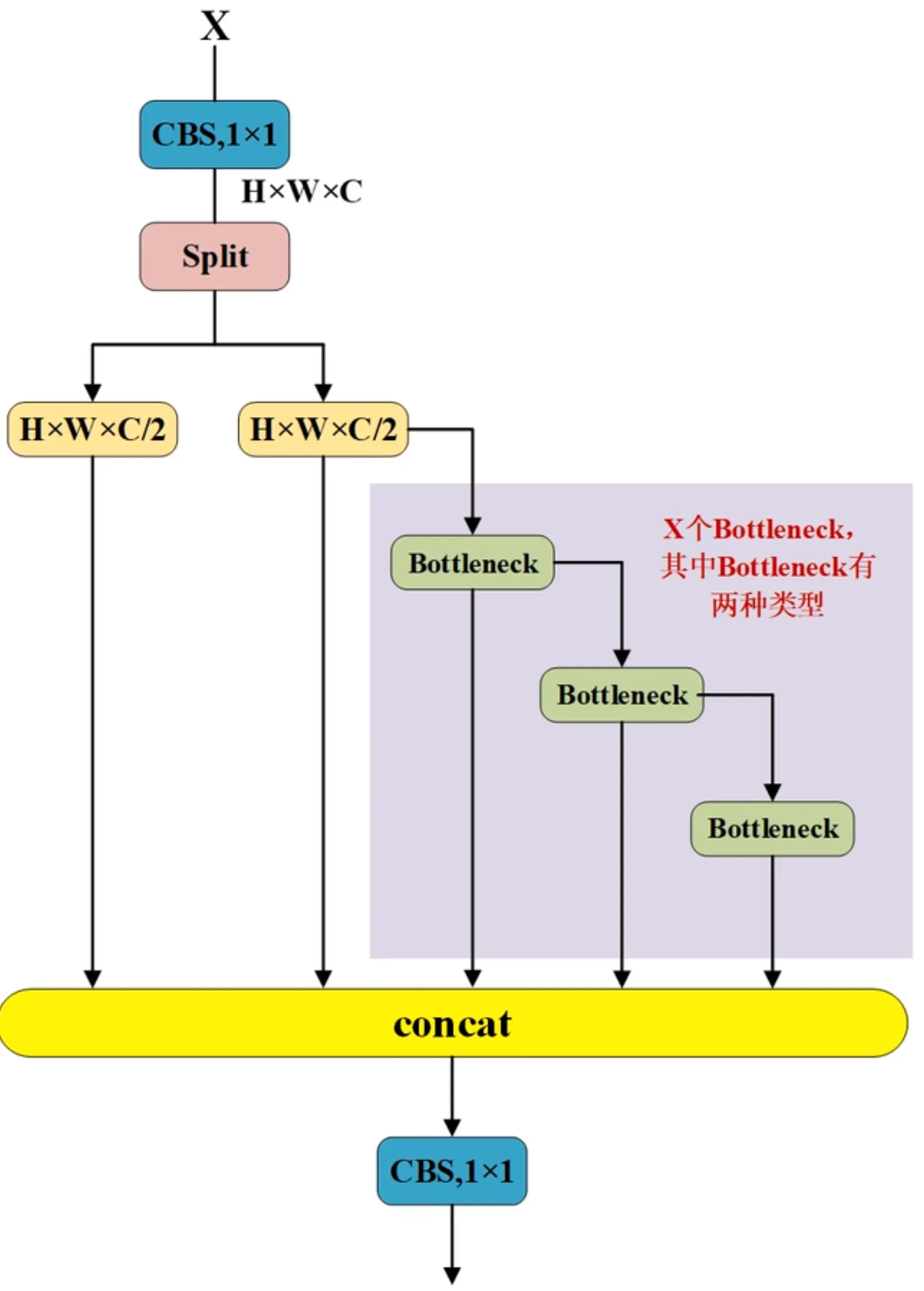
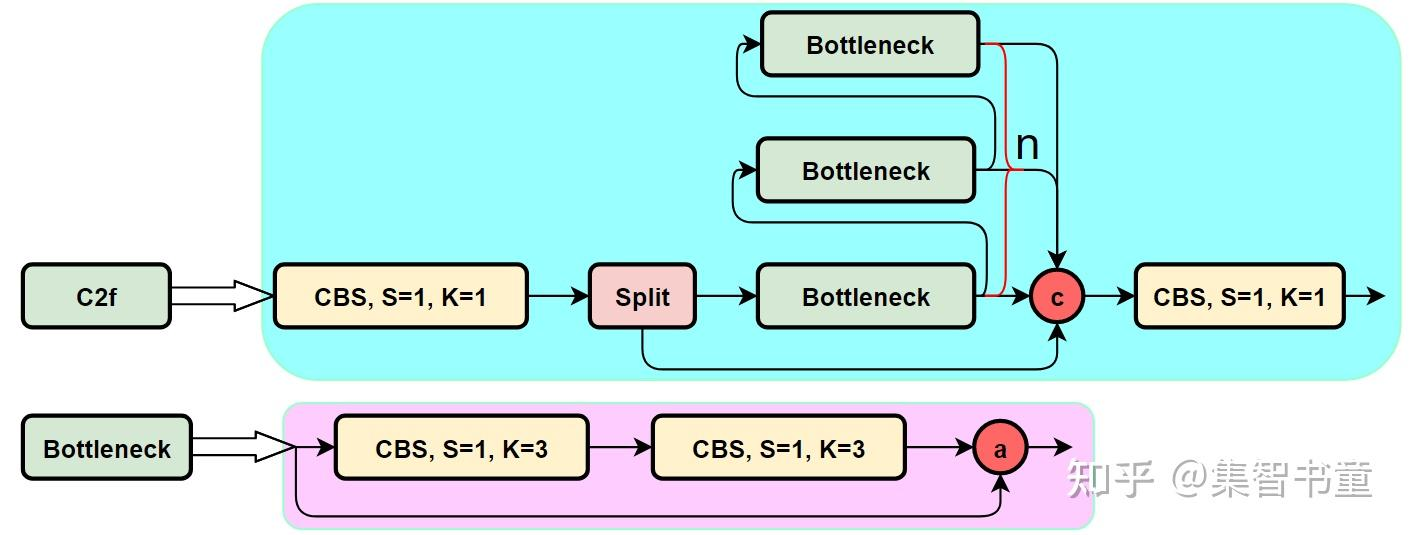
C2f中基础网络块包括:
- CBS
- Bottleneck
根据Bottleneck的不同,一共有两种C2f模块,分别是 C2F_1 和 C2F_2。
- C2F_1: Bottleneck 包含 便捷连接
- C2F_2: Bottleneck 不包含 便捷连接
计算过程:
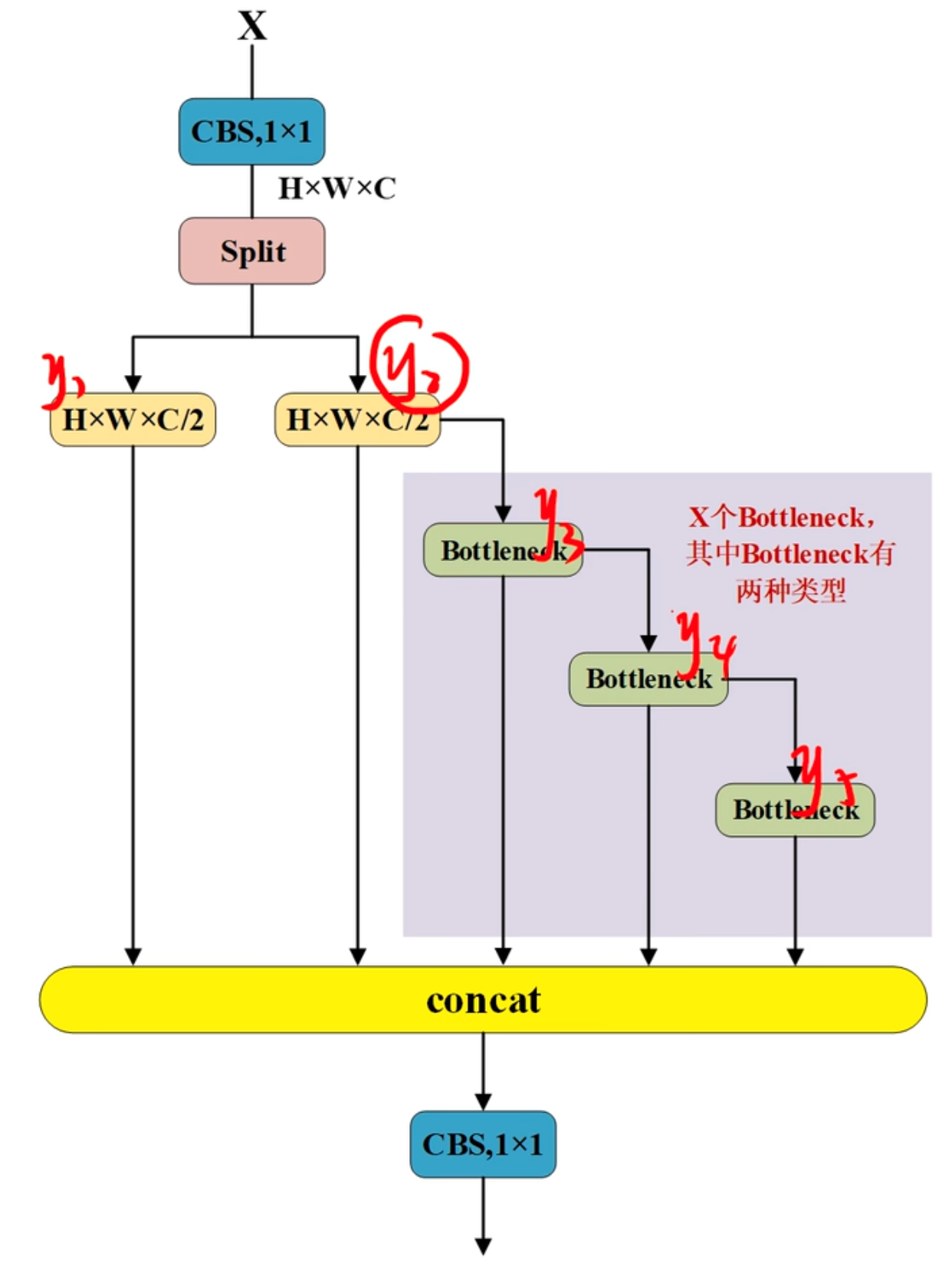
C2f 处理流程:
- Conv1:输入特征图首先经过一个卷积层(通常为1x1卷积)处理,输出的特征图通道数增加一倍。这一步的目的是增加模型的特征表达能力。
- Split:输入特征图使用torch.split将特征图一分为二,如b * c * h * w切分成 b * c * h/2 * w/2,一部分进入Bottleneck模块,另一部分直接参与后续的拼接。
- Bottleneck:经过分割后的特征图在多个Bottleneck模块中逐层处理,提取更深层次的特征。bottleneck模块可以配置是否使用shortcut连接,用于增强梯度传播和信息流动。
- Concat:将所有Bottleneck模块的输出以及之前分割的特征图进行拼接,增加特征的多样性。
- Conv2:最终通过一个卷积层将拼接后的特征图通道数压缩到所需的输出通道数,以适应下一步的处理需求。
网络结构定义:
class C2f(nn.Module):"""Faster Implementation of CSP Bottleneck with 2 convolutions."""def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,expansion."""super().__init__()self.c = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, 2 * self.c, 1, 1)self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))def forward(self, x):"""Forward pass through C2f layer."""y = list(self.cv1(x).chunk(2, 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))def forward_split(self, x):"""Forward pass using split() instead of chunk()."""y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in self.m)return self.cv2(torch.cat(y, 1))
class Bottleneck(nn.Module):"""Standard bottleneck."""def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, andexpansion."""super().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, k[0], 1)self.cv2 = Conv(c_, c2, k[1], 1, g=g)self.add = shortcut and c1 == c2def forward(self, x):"""'forward()' applies the YOLO FPN to input data."""return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
YOLOv8中的C2f模块是一种改进的特征提取模块,其设计旨在解决一些传统目标检测模型中存在的问题,并提升模型的整体性能。以下是C2f模块解决的问题、优点和缺点的总结:
解决的问题
- 多尺度特征提取能力不足:传统的目标检测模型在处理不同尺寸目标时,尤其是小目标检测时,容易出现漏检或误检的情况。C2f模块通过改进特征融合方式,增强了对多尺度目标的检测能力。
- 信息丢失与梯度消失问题:在深层网络中,特征提取过程中容易丢失低层的细节信息,导致梯度消失,影响模型的训练效果。C2f模块通过保留更多的低层特征信息,改善了这一问题。
- 复杂场景下的检测精度问题:在目标密集、遮挡或重叠的复杂场景中,传统模型的检测精度会下降。C2f模块通过优化特征融合和梯度传播,提高了在这些复杂场景下的检测精度。
优点
- 提升多尺度特征提取能力:C2f模块通过双阶段特征融合(Cross-Stage Feature Fusion),能够更好地处理不同尺度的目标,尤其在小目标检测方面表现突出。
- 改善梯度流:C2f模块增强了网络的梯度传播能力,减少了梯度消失的问题,从而提高了模型的训练效率和稳定性。
- 提高检测精度:在复杂场景下,如目标密集、遮挡或重叠的场景中,C2f模块能够更准确地检测目标,提升了模型的整体精度。
- 轻量化设计:相比一些复杂的模块,C2f模块在保持高性能的同时,减少了参数量和计算复杂度,适合在资源受限的设备上部署。
缺点
- 模型设计复杂:虽然C2f模块在功能上有所提升,但其结构相对复杂,增加了模型设计和实现的难度。
- 对硬件要求较高:尽管进行了轻量化设计,但由于其复杂的结构和优化的特征提取能力,C2f模块仍然需要较高的计算资源和内存支持。
- 训练难度增加:由于模块的复杂性,C2f模块的训练过程可能需要更多的数据和更长的训练时间,以达到最佳性能。
总体而言,C2f模块在YOLOv8中起到了重要的作用,通过优化特征提取和梯度传播,显著提升了模型在多尺度目标检测和复杂场景下的性能。然而,其复杂的设计和对硬件资源的需求也带来了一定的挑战。
C3和C2f对比
YOLO V5 中的C3模块和YOLOV8中的C2F模块对比:
C3 和 C2F区别:C3串联Bottleneck, C2F并联Bottleneck

对比C3模块和C2f模块,可以看到C2f获得了更多的梯度流信息
anchor_free
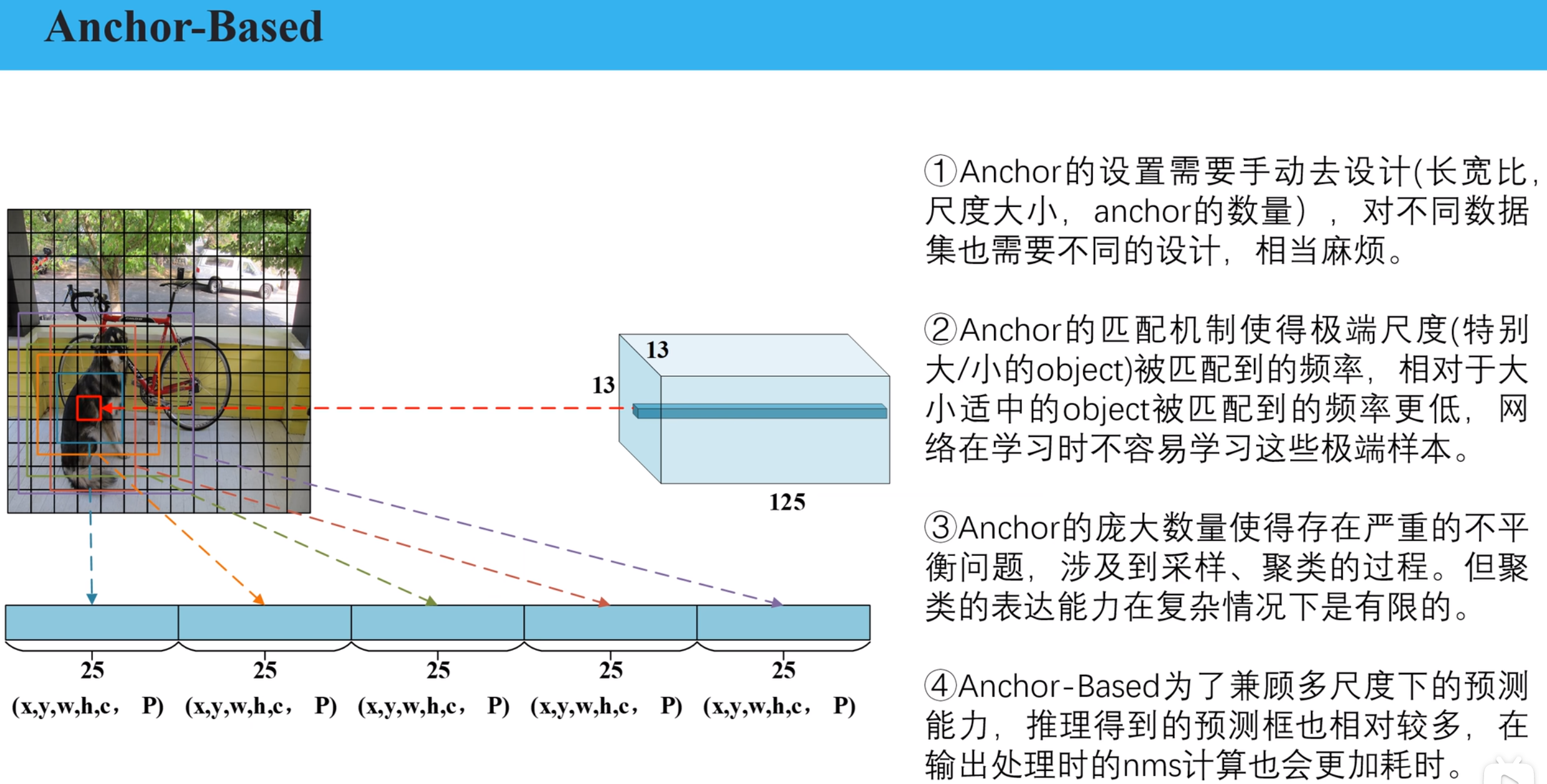
yolov8中采用anchor_free的方式,抛弃了yolov5中基于anchor的回归方式。通过对比anchor_base和anchor_free来说明这种技术的实现。
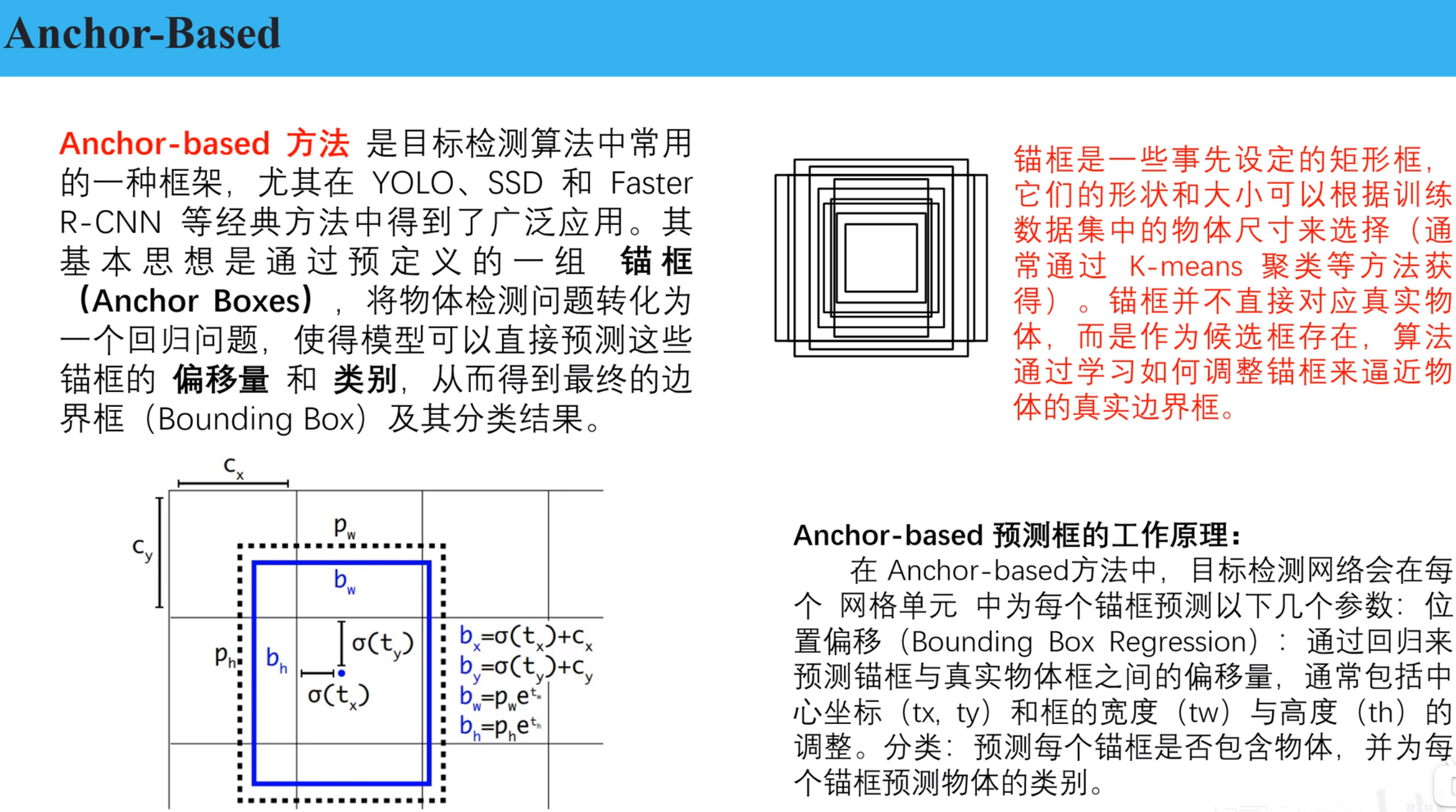
anchor_base
核心思想:预先定义一组不同尺度、长宽比的锚框(Anchor Boxes),作为候选检测框,然后通过回归调整和分类筛选最终检测结果。
特点:网络模型输出的预测框宽高值是基于anchor的宽高的值,使得模型收敛更快

优点
- 高召回率:密集的 Anchor Boxes 能覆盖更多潜在目标,尤其对小目标检测效果较好。
- 训练稳定:回归任务基于固定 Anchor,预测偏移量范围较小,容易收敛。
- 适应多尺度:通过不同尺度的 Anchor 匹配不同大小的目标。
缺点
- 超参数敏感:Anchor 的尺度(scale)、长宽比(aspect ratio)需要人工设计,影响检测性能。
- 计算冗余:大量 Anchor 导致正负样本不平衡(背景框远多于目标框),需额外策略(如 Focal Loss)优化。
- 灵活性低:不同任务(如人脸检测 vs. 通用检测)需重新调整 Anchor 参数,迁移性较差。
Anchor-base存在的问题
anchor_free
核心思想:不依赖预定义的 Anchor,直接预测目标中心点或关键点(如角点、极值点),再回归边界框。
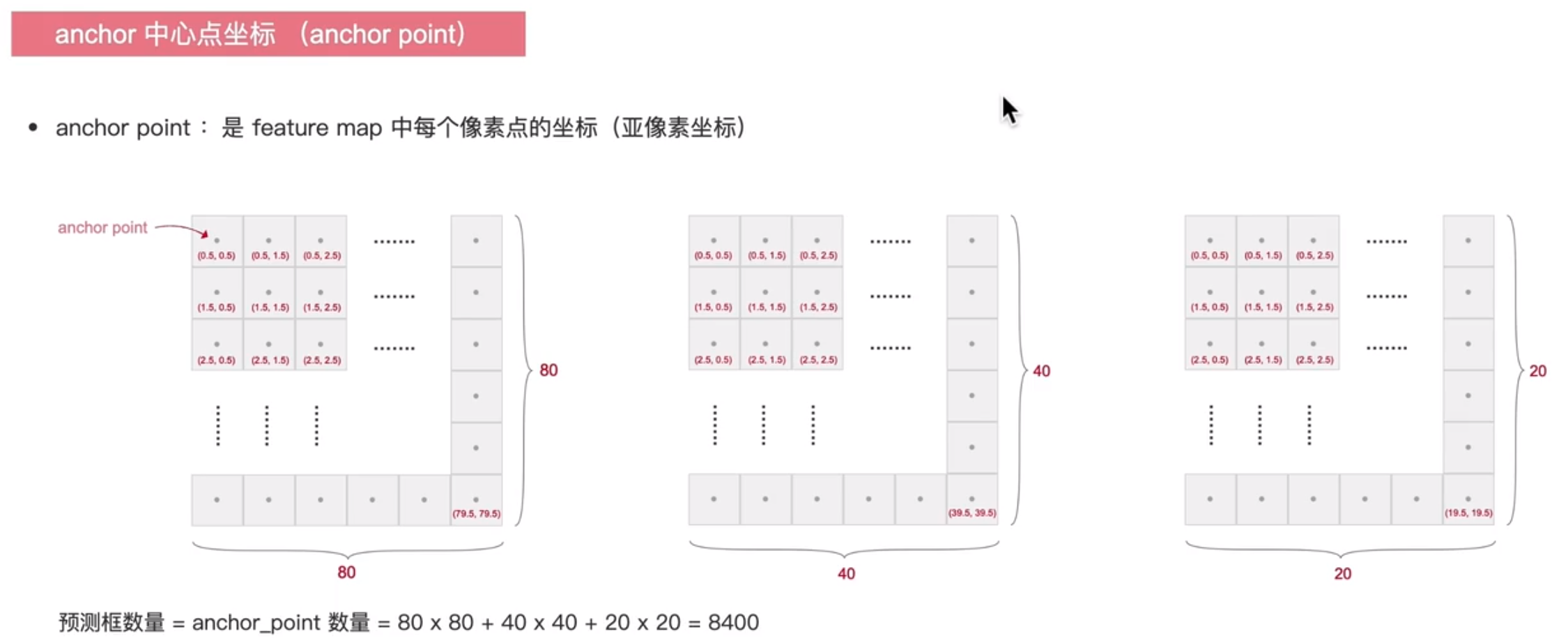
anchor point: 是grid cell 中每个网格中心点的坐标,也可以说是feature map中每个像素点的中心坐标
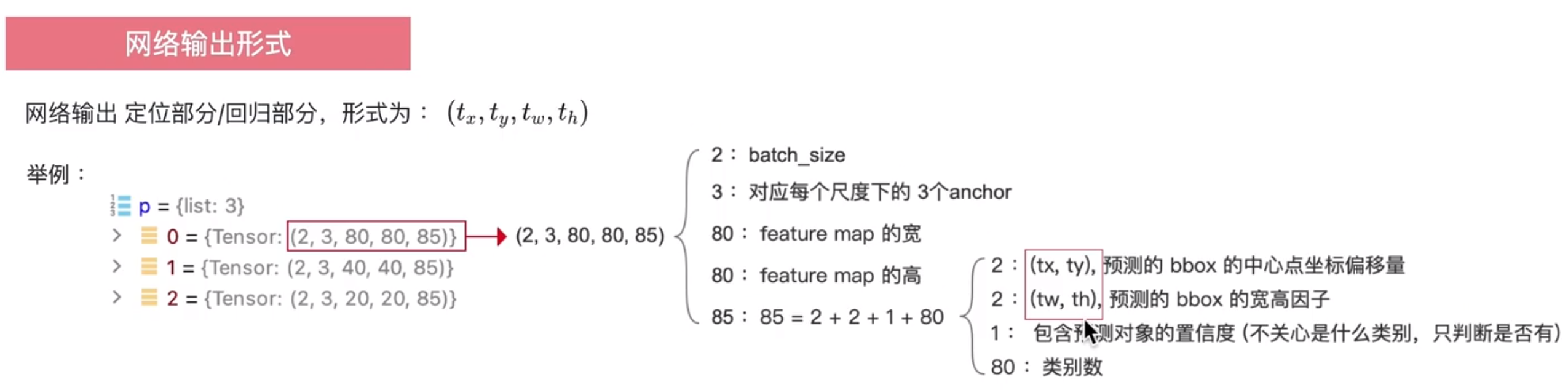
yolov8中预测框的输出是以anchor_point为基准的的,每一个anchor_point 都会输出一个预测框,一共是8080+4040+20*20个
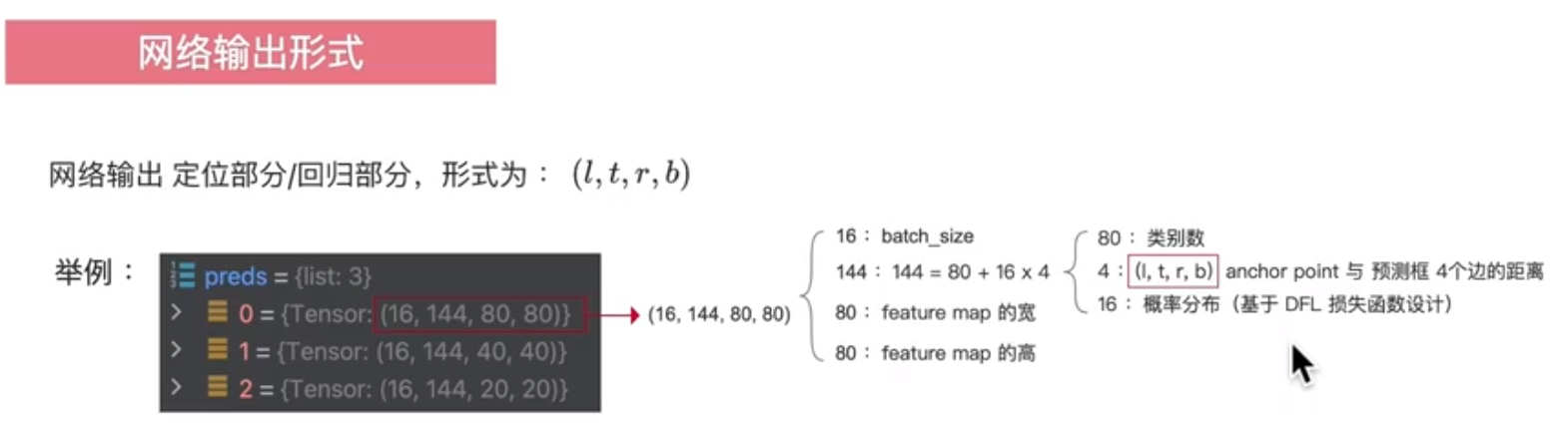
网络部分的输出是ltrb,即预测框相对于anchor point 的上下左右范围,会进一步处理成一个x1,y1,x2,y2的形式。

优点:
- 无需设计锚框参数:直接预测目标的中心点、边界或关键点,避免了锚框设计和调整的复杂性。
- 计算效率高:减少了锚框相关的计算量,推理速度更快,适合实时应用。
- 对不规则物体检测友好:更适合检测形状不规则的目标,如人体姿态、文字等。
- 减少冗余预测:部分Anchor-Free方法(如CenterNet)无需非极大值抑制(NMS)后处理,进一步提高了效率。
缺点:
- 对小目标检测敏感:由于每个位置只预测一个框,可能会漏检小目标。
- 密集物体检测问题:在目标密集或重叠的场景中,容易出现重叠预测或漏检。
- 训练数据要求高:需要高质量的标注数据来训练模型,否则会影响检测精度。
- 精度有限:在某些情况下,Anchor-Free 方法的检测精度可能不如Anchor-Based 方法。
检测头
参考:
https://zhuanlan.zhihu.com/p/722076107
https://blog.csdn.net/weixin_44115575/article/details/147668575
解耦头
在传统的耦合头(如 YOLOv5)中,分类和边界框回归任务共享同一套特征,使用一个共同的输出分支来同时进行这两项任务的预测。如yolov5的结果输出:[x1, y1, x2, y2, conf, cls],
- xywh 预测框的信息
- conf 置信度
- cls 概率类别(多个)
但是分类任务和边界框回归任务具有不同的目标和特征需求。
分类任务更注重图像中的语义信息,而回归任务则更多依赖几何和位置信息。因此,使用相同的特征来执行这两项任务可能导致模型无法充分学习到每项任务所需的最佳特征,从而影响检测性能。
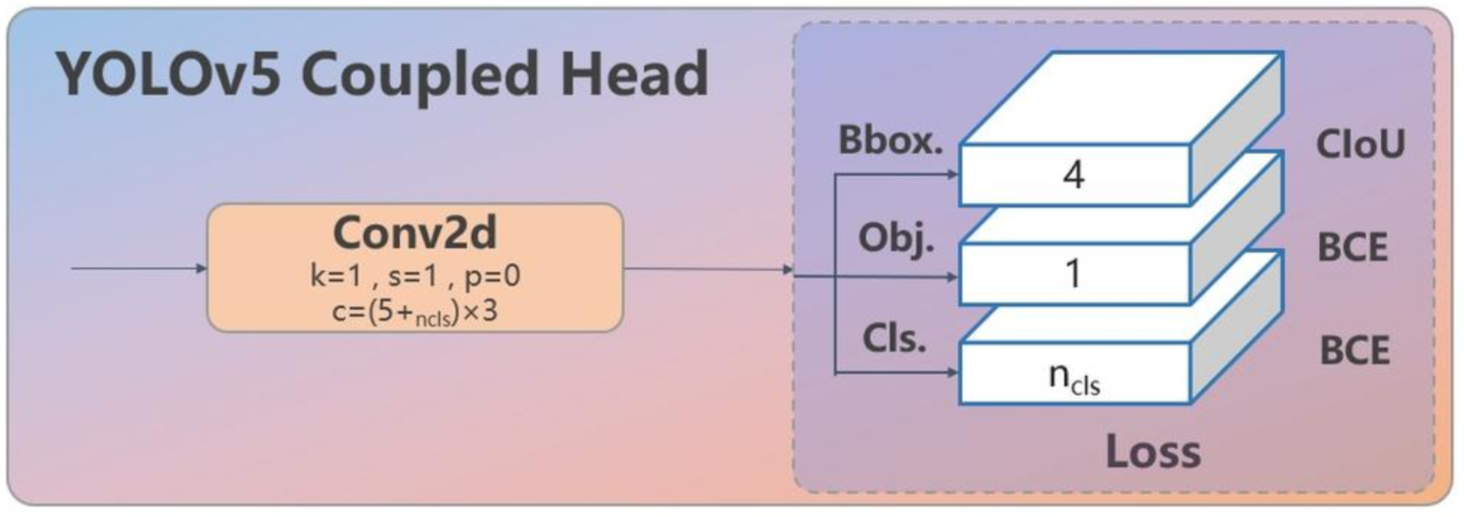
而yolov8采用的是解耦头,类别概率和预测框结果分为两个检测头输出,实现如下:
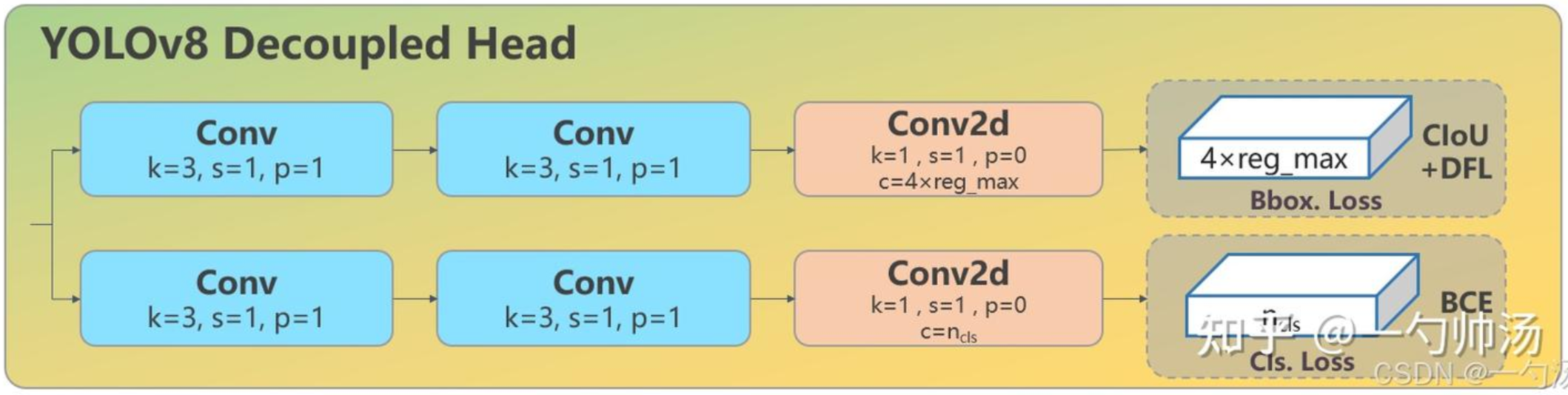
分布焦点损失
在学习检测头的原理之前,首先需要理解分布焦点损失(Distribution Focal Loss)的思想。检测头是基于这种思想来完成的。
直接回归坐标存在的问题:
在目标检测中,边界框回归通常直接预测坐标值(如中心点偏移、宽高)。这种方法存在两大瓶颈:
- 对标注噪声敏感:标注误差或边界模糊时,模型被迫拟合不准确的标签,导致回归不稳定。
- 缺乏不确定性建模:无法区分“确定性高”和“不确定性高”的预测(如遮挡目标),泛化能力受限。
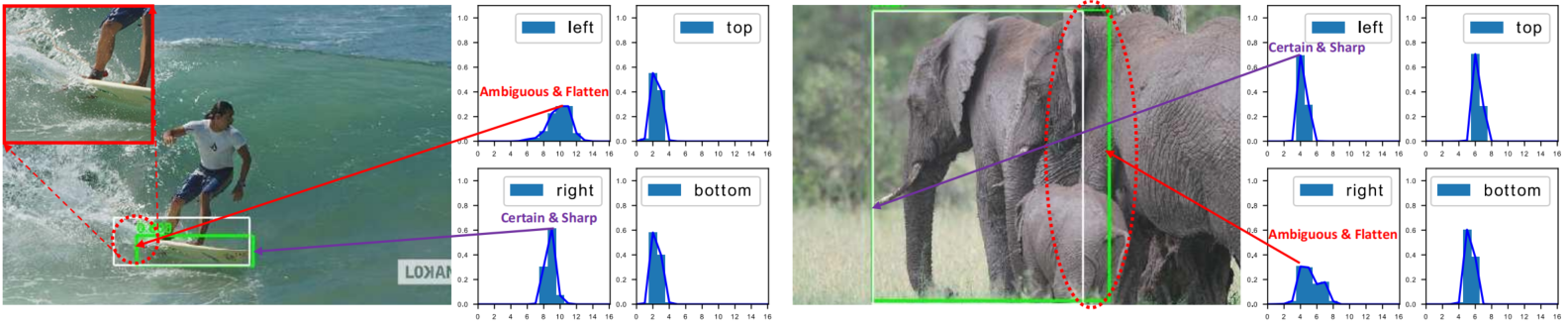
如图所示:由于遮挡、阴影、模糊等原因,许多目标的边界并不清晰,因此真实标签(白色框)有时并不可靠,仅用狄拉克δ分布难以表示这些情况(狄拉克δ分布是一种理想的、只在单一点概率为1,其他地方概率为0的数学分布,表示完全确定的情况)。
相反,提出的边界框泛化分布学习方法能够通过分布形状体现边界信息。将一个预测值建模为一段区间上的分布概率之和。使用一段区间的概率来表示一个预测值,优点是:其中较为平坦的分布表示边界不清晰或模糊的情况(见红色圆圈标记),而尖锐的分布表示边界明确的情况。
DFL介绍
DFL 的全称是 Distribution Focal Loss,即 分布焦点损失。它是由旷视科技在 2020 年的论文《Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection》中提出的。
DFL 将目标值(如边界框的 x 坐标)建模为一个在某个数值范围内的离散分布。
步骤分解:
- 定义范围:假设我们要预测的目标值
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y</font>(例如某个框的左侧<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">x</font>坐标)的真实值在 0 到 15 像素之间。我们将其离散化,用 16 个整数来表示这个范围,即<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">[0, 1, 2, ..., 15]</font>。这 16 个点我们称之为“锚点”。 - 模型输出:模型不再只输出 1 个标量值,而是输出 16 个值(每个锚点一个),这 16 个值经过 Softmax 后形成一个概率分布
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">P = [P0, P1, ..., P15]</font>,表示<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y</font>等于每个锚点值的概率。 - 从分布到预测值:最终的预测值
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y_hat</font>不是简单地取概率最大的那个锚点,而是这个分布的期望值(加权平均):
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y_hat = Σ(i * Pi)</font>,其中<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">i</font>是锚点,<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">Pi</font>是其对应的概率。
例如,如果模型输出的概率集中在 5 和 6 周围(即 P5 和 P6 的值很高),那么最终的预测值 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y_hat</font> 就会是 5.x,实现了亚像素级别的精确回归。
总结:
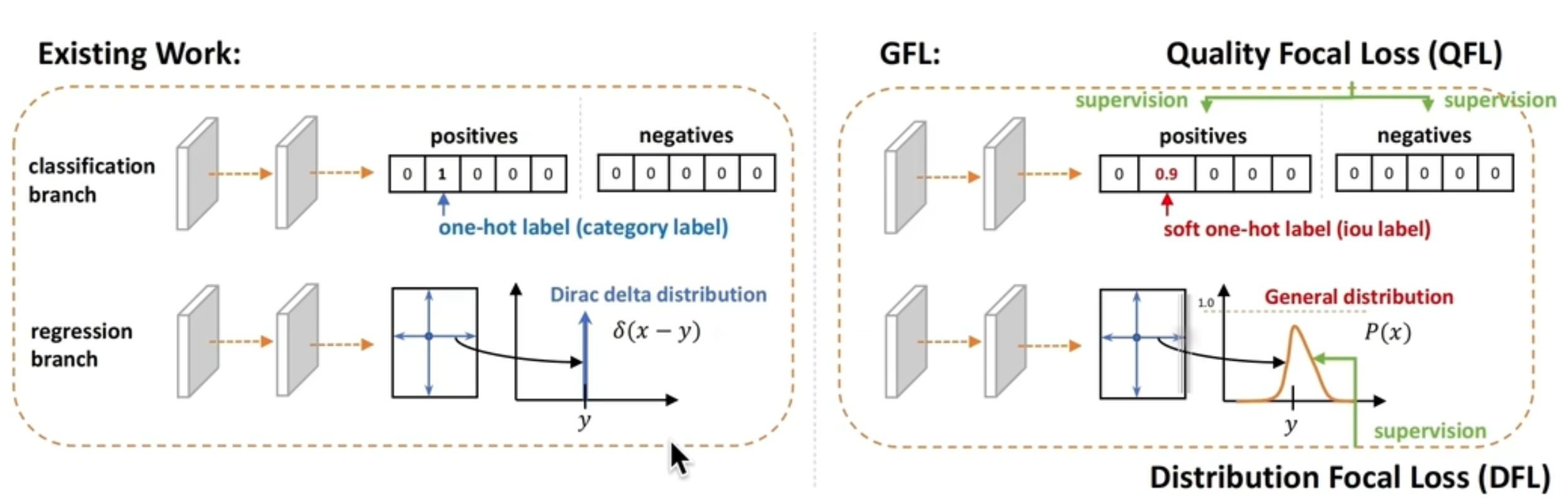
| 狄克拉分布 | DFL分布 | |
|---|---|---|
| 特点 | 单点概率为1,其他概率为0 | 从连续坐标到离散分布 |
| 输出过程 | 输出多个值,服从一般分布,任意分布 | 将连续坐标值建模为离散区间上的概率分布 加权求和(积分)得到最终预测坐标 |
预测结果输出
首先再明确一下模型的输出结果:
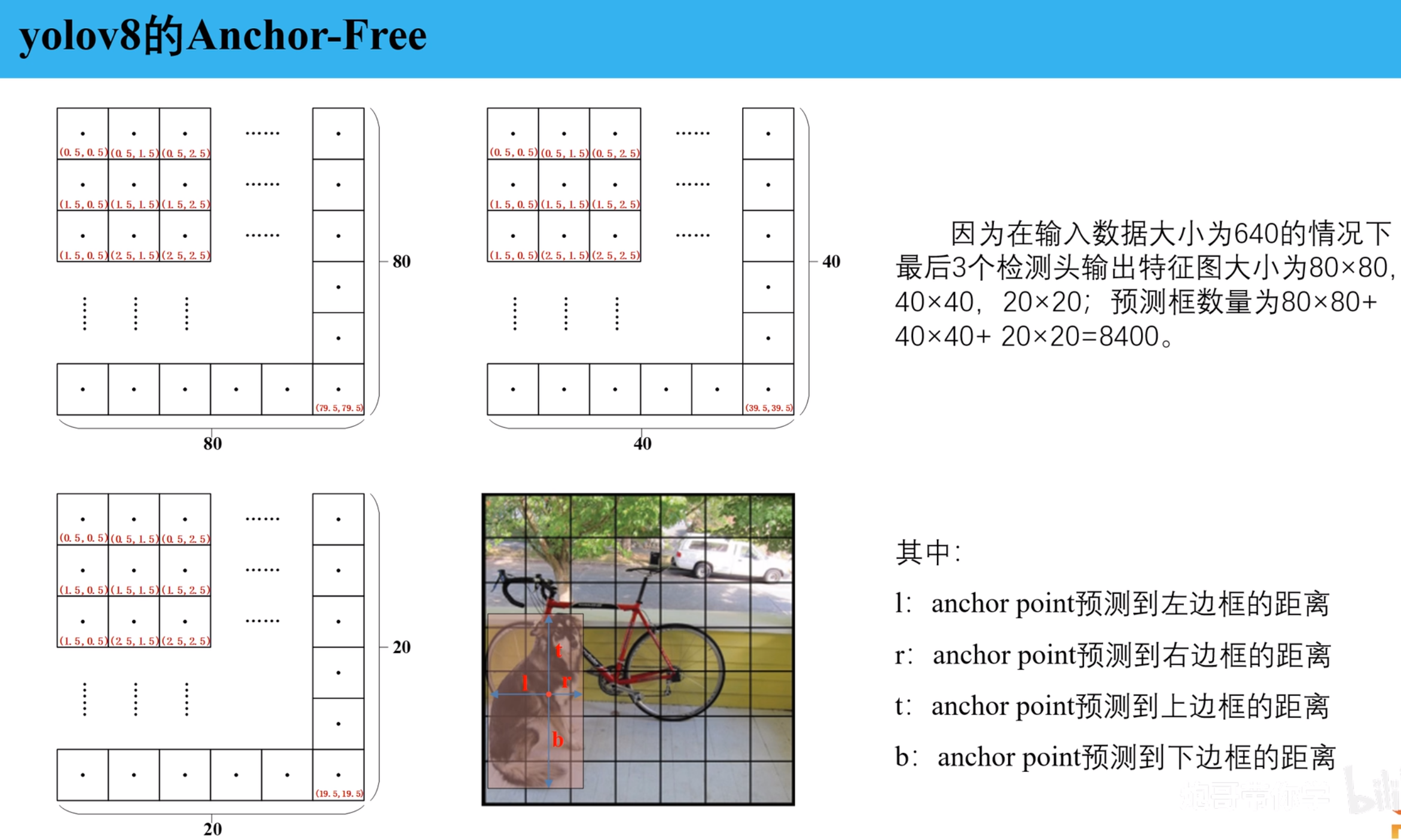
- 骨干网络输出按照3种尺度输出结果,如2020、4040、80*80
- 每一个网格输出4*16的数据,4是坐标框的输出是l、r、t、b、分别代表以网格中心点anchor point 为基准的预测物体的左右上下范围。16 是16组坐标框的结果,0-15个结果,数字的意义是该特征图下单位长度
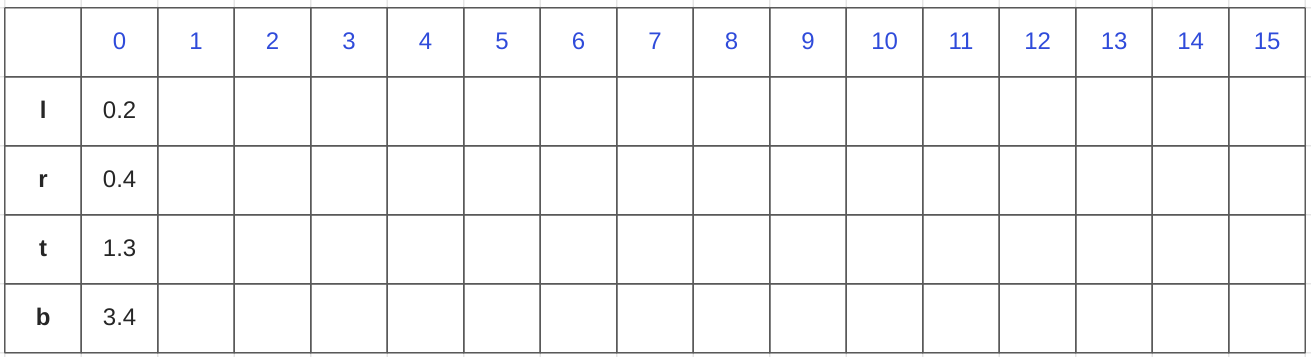
DFL:
DFL 模块实现分布焦点损失(Distribution Focal Loss)思想,将连续的回归问题转化为离散的概率分布预测,从而使网络学习更加鲁棒。
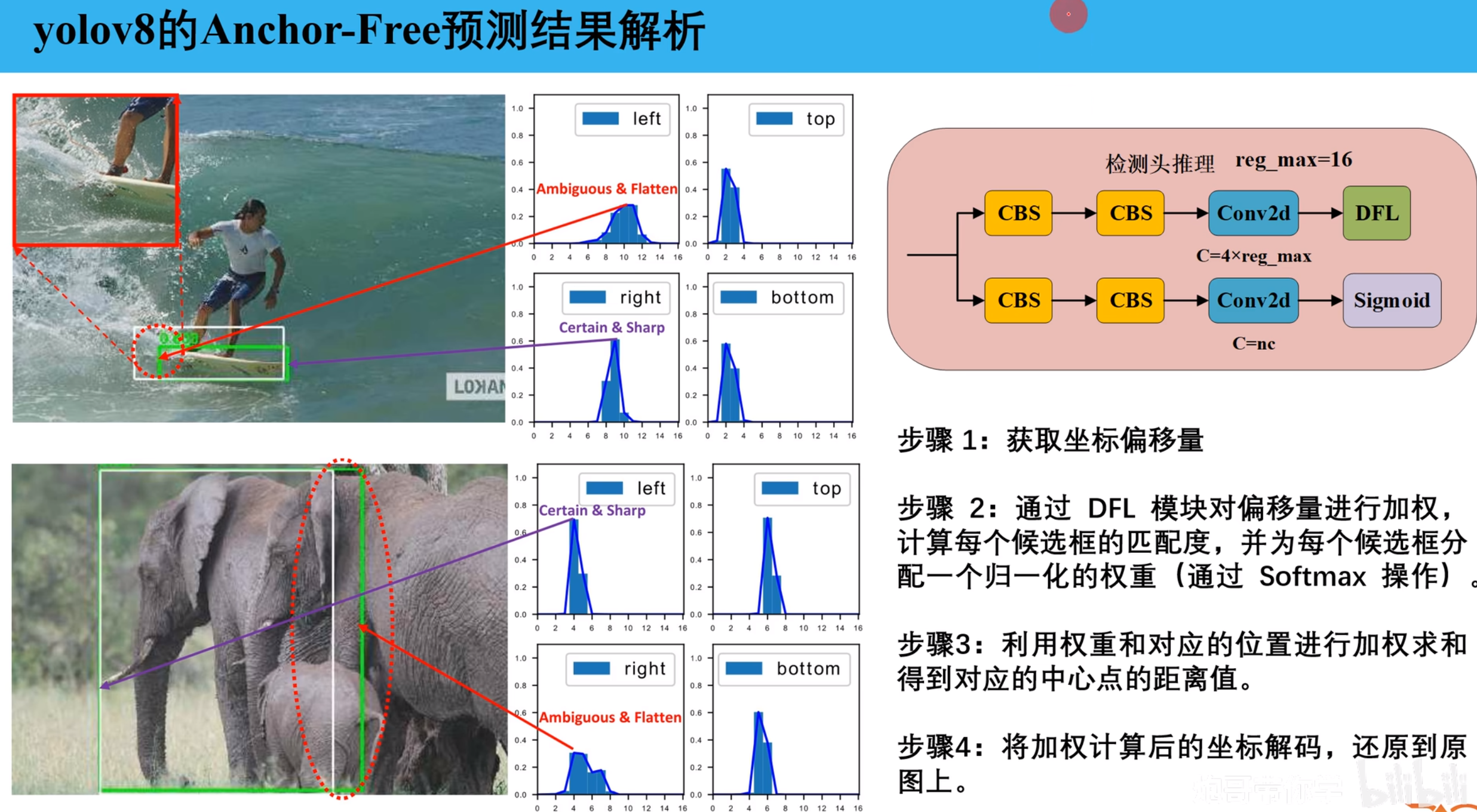
DFL之前的坐标是4 * 16 的形式,也就是输出了16组上下左右的坐标值,在DFL中会完成两个处理:
- 分别对上下左右的16个值使用softmax做归一化处理,将具体的数值转换成对应的权重。0-15对应的是距离anchor point的长度,该下标下权重越高说明预测为该长度的概率越大
- 将0-15 和 对应的权重求和,得到上下左右4个长度的具体值。
- 将计算的上下左右距离从特征图尺度还原到原图上,得到640*640输入图形下的输出的结果。输出结果的格式是l、t、b、r。总计输出8400个预测结果
优点:
yolov5的输出中每一个预测框直接输出一个坐标,DFL中输出16个坐标加权求和,DFL的处理方式让结果不那么激进,减少了波动较大的结果,提高了模型输出的稳定性和准确性。
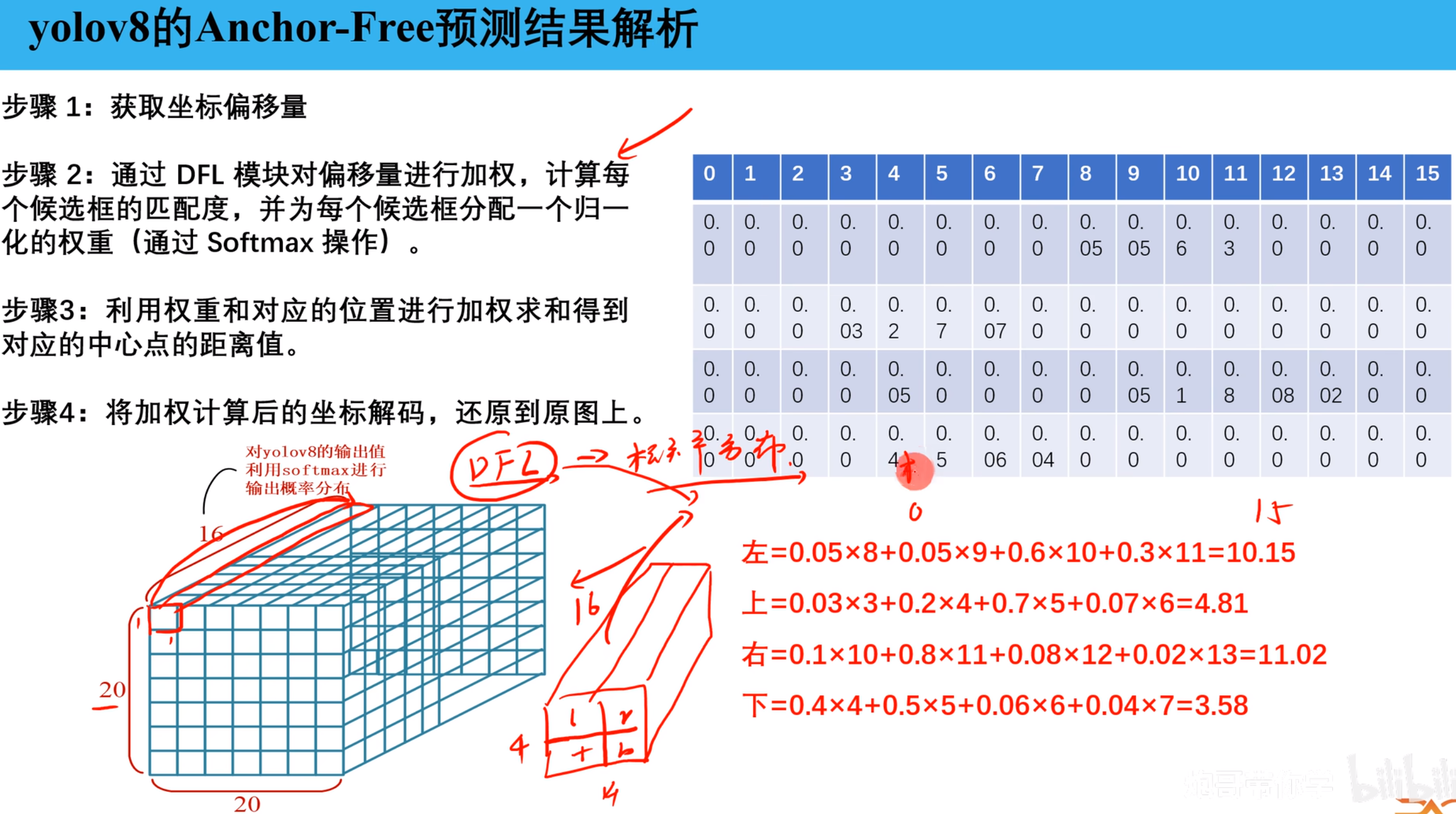
Detect逻辑处理流程:
- 获取坐标偏移量
- 通过DFL模块对16个结果进行加权计算,给每一个候选框增加一个权重,权重通过softmax处理
- 利用权重和对应位置进行加权求和得到距离中心点的值
- 将加权计算后的坐标解码,还原到原图上
正负样本匹配
正负样本匹配基础
为什么需要正负样本匹配?
模型训练的核心思想是计算标准值和预测结果的差距,然后更新权重,减少这种差距。标准值就是数据集,数据集中有标注框和非标注框,称之为背景。标注框需要对应的预测结果计算差距,背景也需要对应的预测结果计算差距。那么说就需要选择出预测结果中一部分和标注框计算loss,分和背景计算loss。
因此:正样本就是预测结果中和标注框计算loss的部分,负样本是预测结果中和背景计算loss的部分。
正负样本通常指的是预测结果,或者说和预测结果相关的。正负样本都是用来更新模型的参数,正样本和标注框计算loss进行权重更新,负样本和背景计算loss进行权重的更新。
正负样本匹配规则
YOLOv8采用了一种名为 Task-Aligned Assigner 的动态匹配规则来选择正负样本。与YOLOv5等早期版本中较为静态的分配策略不同,这种方法能根据模型当前的学习状态,更智能地分配样本,通常能带来更好的性能
在模型输出结果之后进行正样本匹配,首先回顾一下模型的输出结果:
coco数据集(80个类别)下,模型的输出结果是 (8080 + 4040 + 2020) * (80 + 164)。
- 三种尺度:80 40 20
- 类别概率:80
- 预测框ltbr:16 * 4

正样本匹配规则:

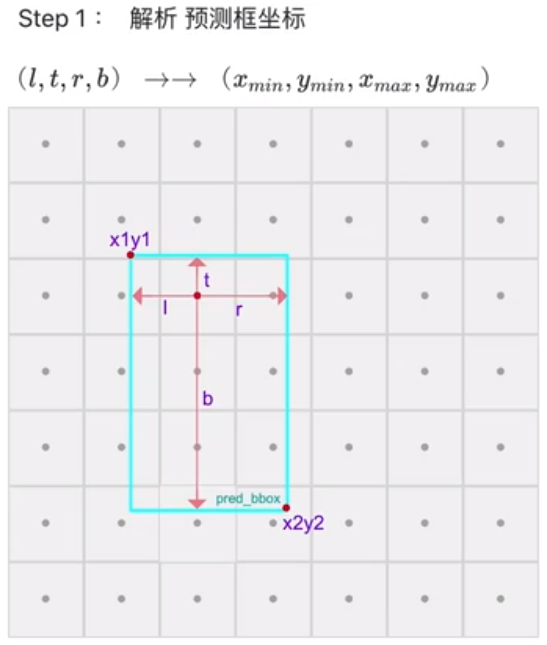
一、解析预测框
预测框输出是l、t、b、r,首先将其解析成x1, y1, x2, y2 的格式。
二、粗筛正样本
将模型三个尺寸的输出结果都还原到原图尺寸上,得到所有的预测结果
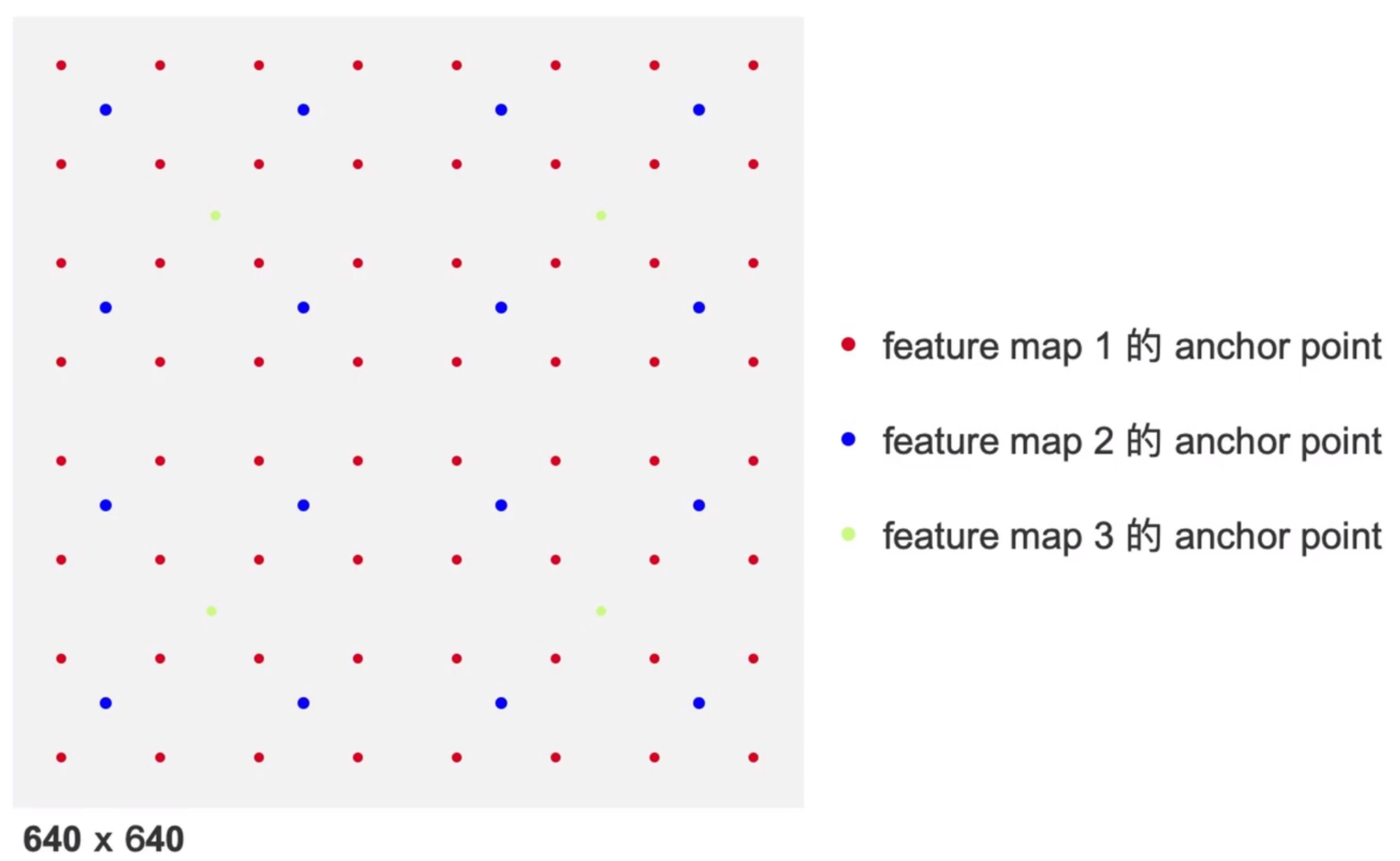
gt 框覆盖的anchor_point对应的预测结果都是正样本,下图中gt框以内的预测结果都是粗筛的正样本。

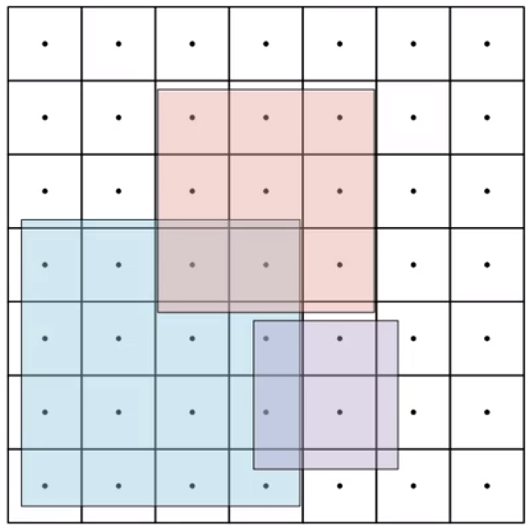
设计思路:理论上来说gt框覆盖的anchor_point 就可以预测出该gt框,因为上下左右都是正数数值。
三、精筛正样本
从是上一步粗筛的基础之后进一步处理正样本。首先计算质量计算公式,每一个粗筛得到的预测框都计算出一个质量公式,公式如下:

精筛正样本:
1、利用质量计算公式计算所有初筛正样本和真实框得分
2、选择得分最高的前k个作为候选框,默认选择前10个为正样本
3、去重(找出分配给多个真实框的预测框,只保留CIOU最大值的预测框为正样本)
计算示例如下:
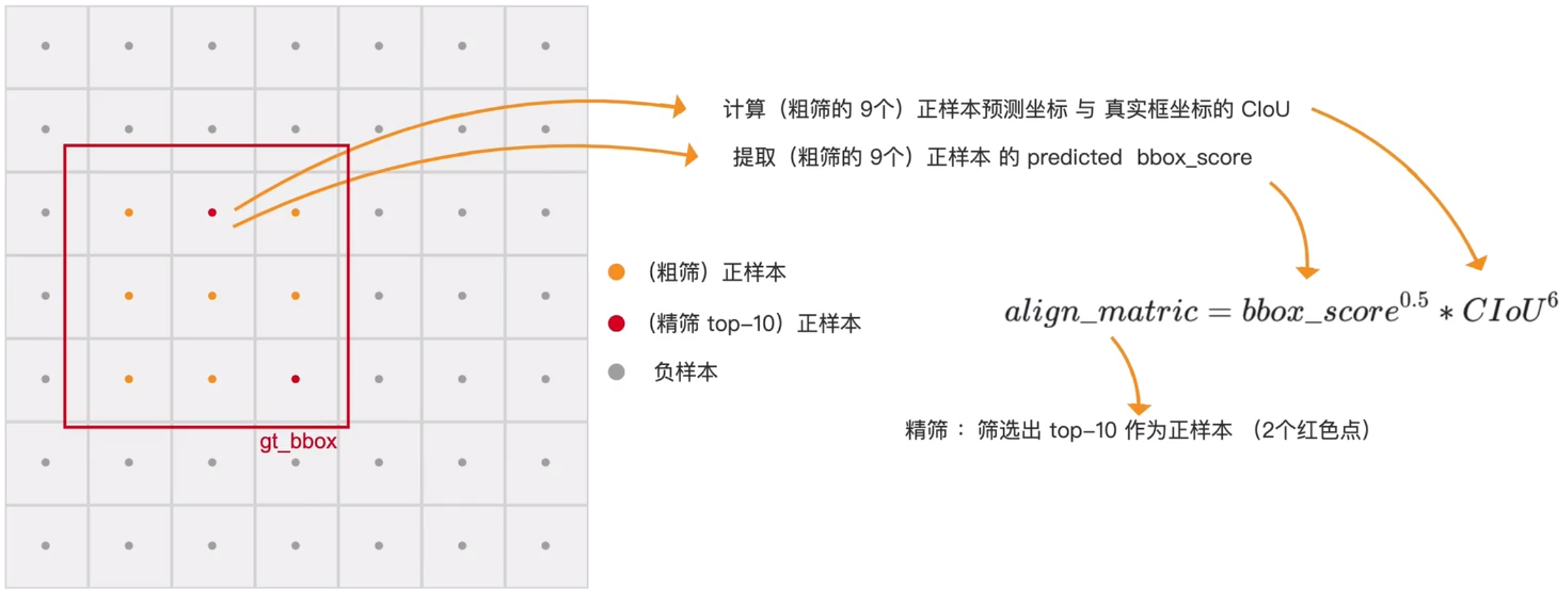
精筛之后得到的正样本数量:类别 * 10,假设有5个类别,那么就得到50个正样本,从8400个输出结果中获取50个正样本
四、处理预测一对多
会存在两个标注框重叠,从而导致一个anchor_point同时属于两个标注框的情况,这时肯定不能让一个预测框去拟合两个标注框,所以需要抉择该预测框属于哪一个标注框。
规则是:计算预测框和标注框的CIOU,选择CIOU大一对,该预测框就是该标注框的正样本,那么另一个标注框就获得一个负样本。

YOLOV5 和 YOLOV8 对比
通过对比yolov5 和 yolov8的正负样本筛选,来加深理解
YOLOv5 的正负样本筛选
YOLOv5 的正负样本筛选中正负样本指的是anchor。yolov5是经典基于anchor匹配的目标检测框架,正负样本筛选过程:
- 通过标注框匹配anchor,根据标注框和anchor的宽高比小于4的规则匹配得到anchor
- 每一个anchor对应一个预测结果,匹配上的anchor对应的预测结果就是正样本
- 正样本和标注框计算loss
YOLOv8 的正负样本筛选
yolov8 的正负样本筛选中正负样本指的是预测结果。yolov8是anchor free的目标检测框架,筛选过程:
- 将预测结果预测框还原到特征图上
- 预测框内的anchor point对应的预测结果都是正样本
- 正样本和标注框计算loss
区别与联系对比表
| 特性 | YOLOv5 | YOLOv8 |
|---|---|---|
| 核心策略 | 静态、基于规则的分配 | 动态、基于质量的分配(Task-Aligned) |
| 依赖锚框 | 是,严重依赖 | 否,无锚框(Anchor-Free) |
| 分配依据 | 真实框与锚框的宽高比、网格中心点位置 | 分类得分与预测框IoU的加权组合(对齐度量) |
| 分配时机 | 训练前基本确定,与模型性能无关 | 每个训练步骤动态变化,与模型当前性能强相关 |
| 正样本数量 | 每个真实框固定分配约3个正样本(1个主+2个邻近) | 每个真实框分配top k个正样本,数量更灵活 |
| 灵活性 | 较低,对新颖或极端尺度的目标适应性差 | 较高,能自适应地选择高质量正样本 |
| 联系 | 都是一对多分配,一个GT对应多个正样本 | 都旨在为每个GT选择多个合适的正样本进行学习 |
| 联系 | 都考虑了空间先验(YOLOv5是邻近网格,YOLOv8通过IoU隐含) | 都是模型训练中标签分配(Label Assignment) 的关键步骤 |
从YOLOv5到YOLOv8的正负样本筛选策略的演变,代表了目标检测领域标签分配技术的进步:
- YOLOv5 的策略简单有效,但相对“笨拙”,它假设好的正样本只与位置和形状有关。
- YOLOv8 的策略更加智能和自适应,它认为好的正样本应该是模型自己当前“认为”分类准且定位也准的样本。这种策略能更高效地利用监督信号,通常能带来更快的收敛速度和更高的最终精度。
因此,正负样本筛选策略的升级是YOLOv8性能优于YOLOv5的关键原因之一。
损失计算
损失主要包括类别损失和定位损失,损失函数公式如下:
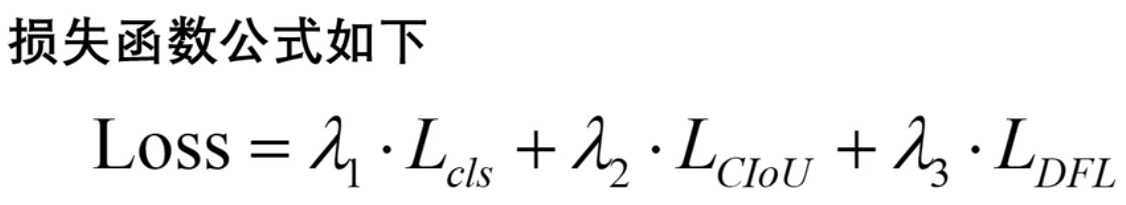
损失函数计算公式包括:
- 类别损失
- 定位 CIOU 损失
- 定位 DFL 损失
类别损失:BCE Loss
定位损失:CIoU Loss + DFL(Distribution Focal Loss)
然后每个损失还包括一个可配置的系数。
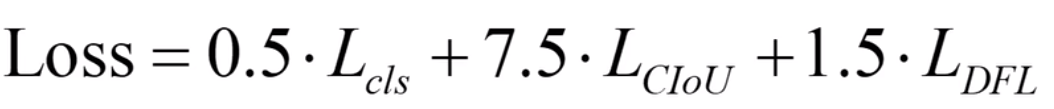
类别损失
注意点:
一、模型的输出是未经过后处理的结果
模型输出是原始数值,没有经过softmax 或 simod 处理,在后续计算中实用BCE loss,会在loss函数的处理过程中先sigmod处理,然后再计算二元交叉熵损失
二、每个类别单独计算
模型输出有多个类别但选择的仍然是二元交叉熵损失,主要是对每一个类别分别计算,这样的好处是更关注负样本。在使用交叉熵损失函数时多个类别只有一个是正类,那么剩下的负类关注点较少。使用二分类交叉熵来处理多分类问题。
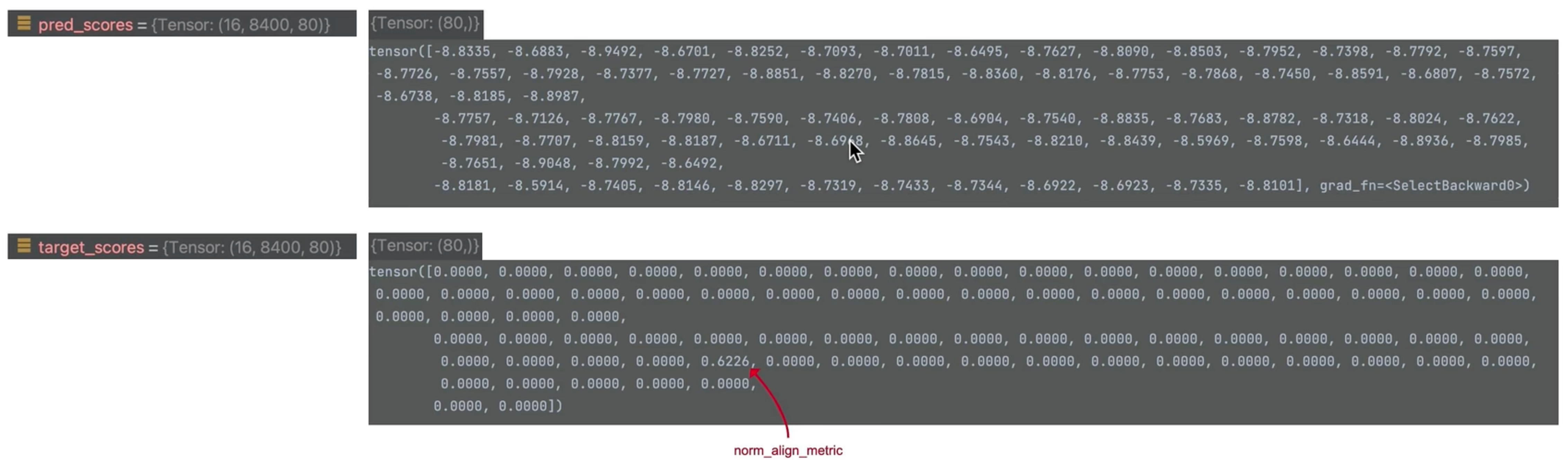
- 真实类别的类别值不是1而是norm_align_metric
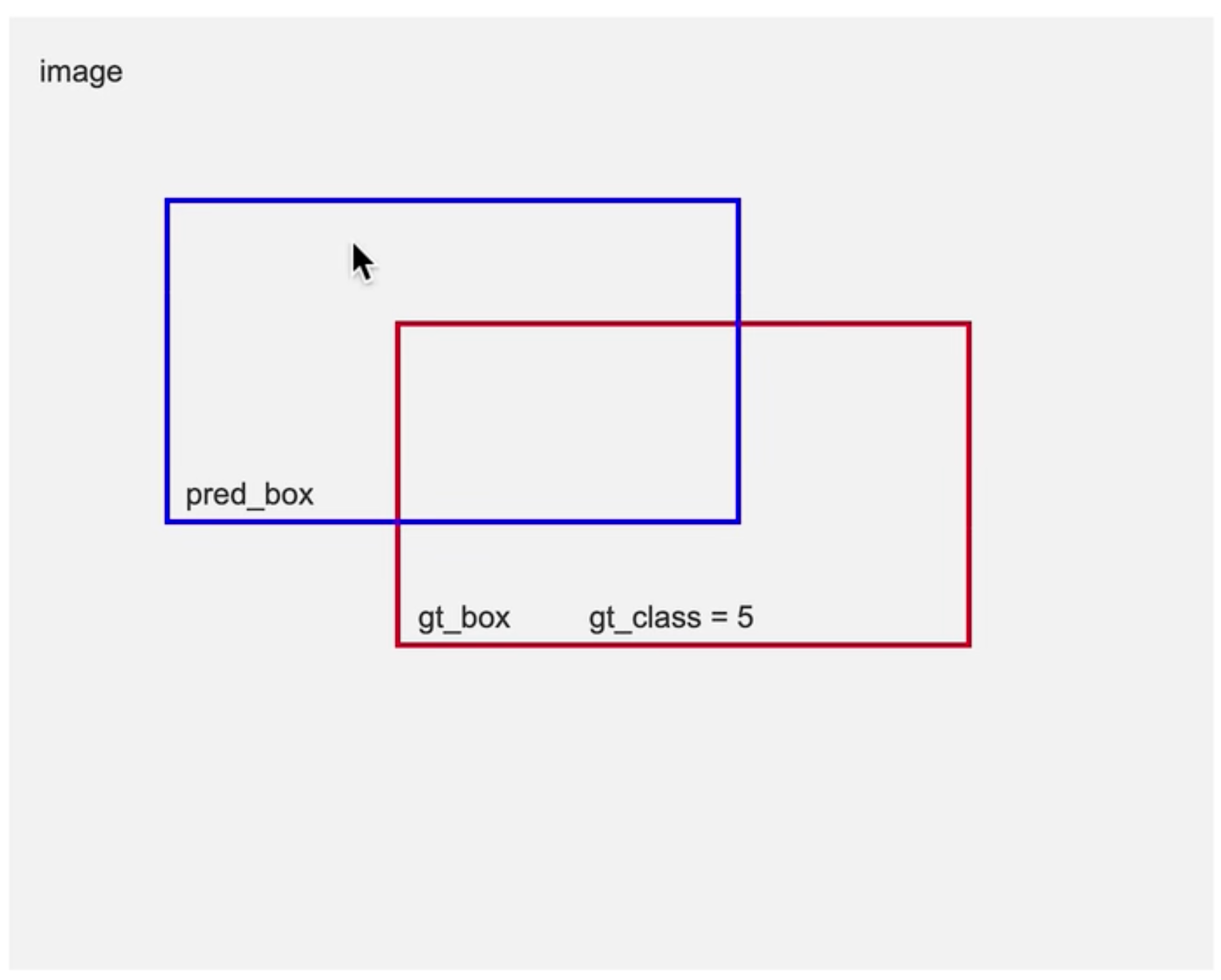
计算类别损失的时候是用蓝色框的预测类别和蓝色框的真实类别去做运算,蓝色框没有真实类别,所以就不能说蓝色框的真实类别概率为1,使用norm_align_metric作为它的真实类别概率。
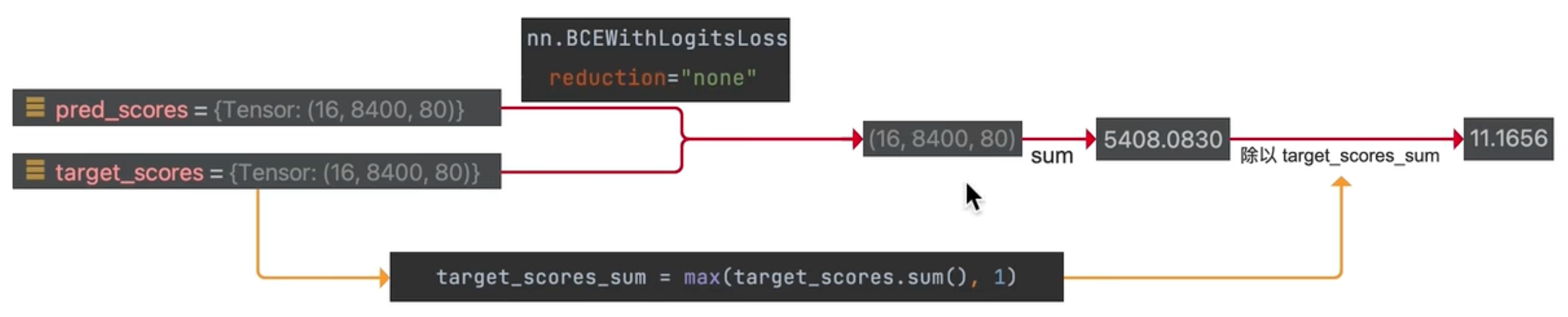
计算损失的过程:
- 获取预测类别的值
- 获取目标类别的值
- 使用二元交叉熵,先对预测值进行sigmod处理,然后计算交叉熵
- 将每个类别的loss相加,得到总loss
- 总loss除以所有真实目标值的总和
定位损失
CIOU
CIOU 损失,首先,我们回顾一下 IOU 的定义:
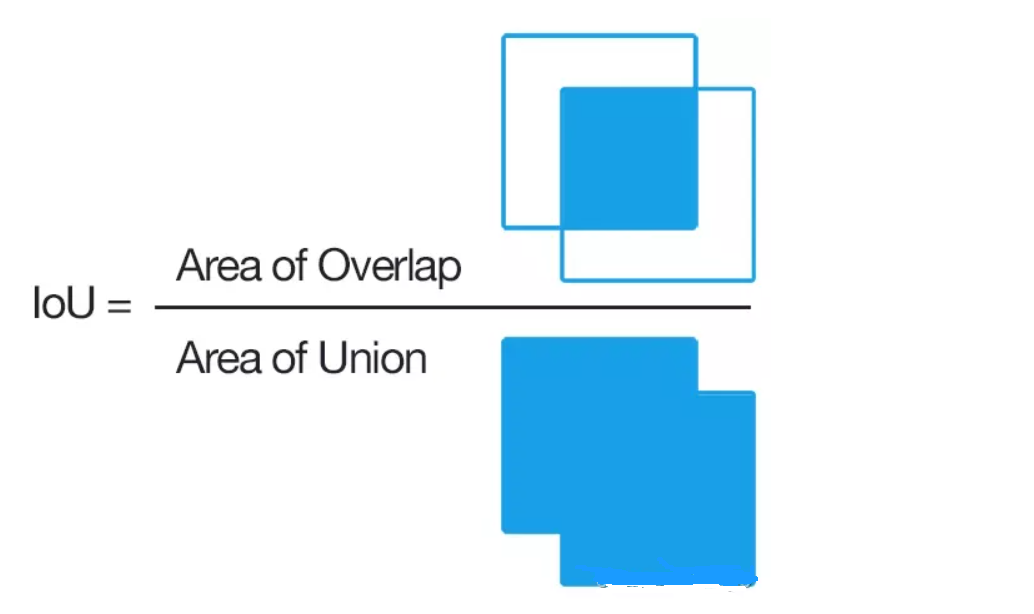
CIoU的计算公式
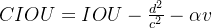
- d 为预测框和真实框中心点的距离,
- c 为最小外接矩形的对角线距离。
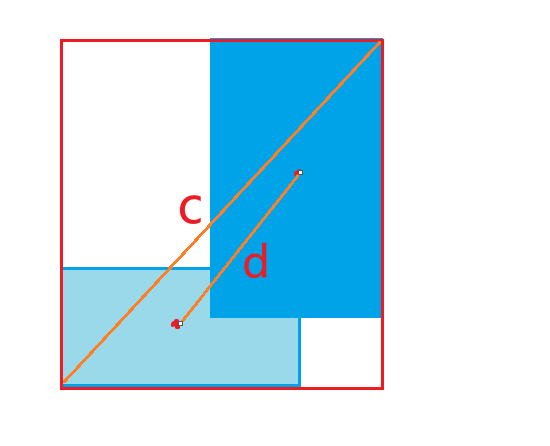
- α α 是权重函数
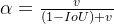
- v 而用来度量长宽比的相似性 v 是修正因子,用于进一步调整损失函数,考虑目标框的形状和方向。具体计算方式为:
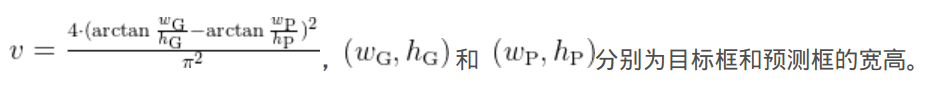
CIOU Loss 的设计中涵盖了:
- 面积
- 距离
- 宽高比
CIoU Loss最终定义为:
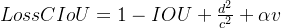
DFL 损失
首先再回顾一下YOLOV8模型的输出:
模型输出3个尺寸的预测,分别是 2020、4040、80*80。每个输出结果包括定位和类别。如coco数据集上是144:
- 16*4:其中定位的输出是4 * 16 的概率分布
- 80:80个类别的概率输出
输出示例:
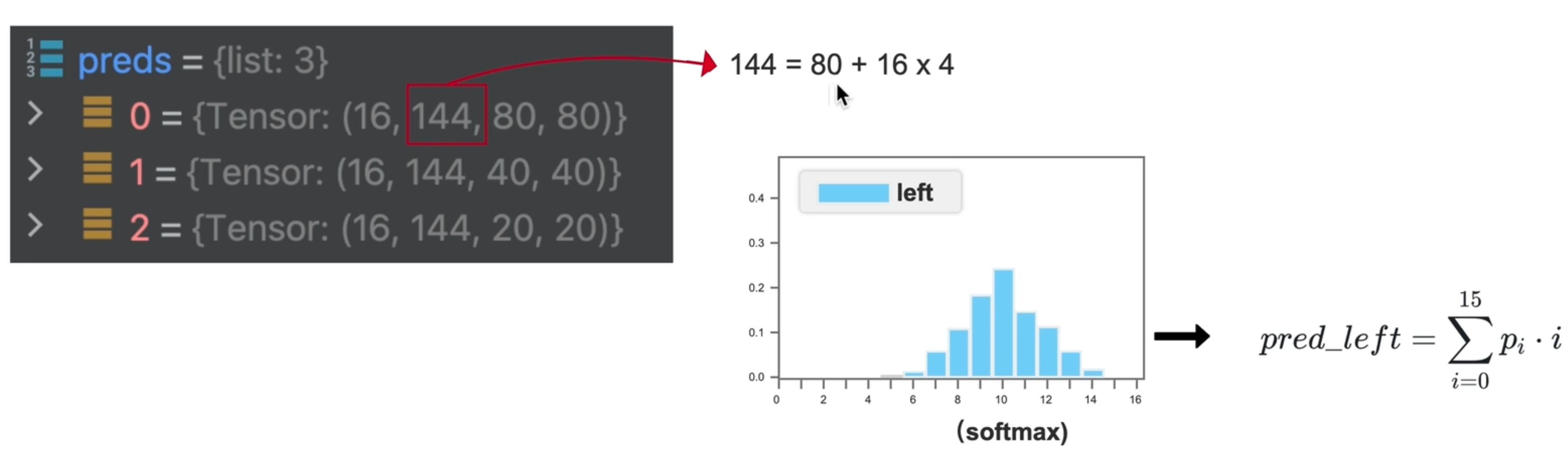
输出解释:
定位输出的16 * 4,代表16组上下左右的数值产生的一般分布。
输出概率的形状在目标清晰明确的时候会产生尖锐的山峰,目标模糊是会产生平缓的山峰。清晰的尖锐的山峰代表着模型拟合的更好。
在设计损失函数的时候就希望增加真实值左右两边概率,快速学习成尖锐的样子,让山峰更高。
DFL 损失计算过程:
目标:我们希望模型输出的分布能够快速、集中地收敛到真实值附近。
方法:DFL 损失鼓励真实值 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y</font> 两侧最近的两个锚点(比如 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">yi</font> 和 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">yi+1</font>)的概率尽可能大,而其他锚点的概率尽可能小。
假设真实值 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y = 9.3</font>,那么它位于锚点 8 和 9 之间。
- 我们期望的“理想”分布是:
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">P8</font>和<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">P9</font>的值非常高,其他位置的概率为 0。 - 损失函数会计算当前分布
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">P</font>与这个“理想”分布之间的交叉熵损失。 - “Focal” 体现在这里:它通过调节因子,让模型更加关注那些与真实标签相关的、但当前概率还不太高的样本(即难例),加速分布的集中过程。
数学上,DFL 损失的简化形式可以表示为:
<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">DFL(Si, Si+1) = -((yi+1 - y) * log(Si) + (y - yi) * log(Si+1))</font>
其中 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">Si</font> 和 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">Si+1</font> 是真实值 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">y</font> 左右两侧锚点预测的概率,<font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">yi</font> 和 <font style="color:rgb(15, 17, 21);background-color:rgb(235, 238, 242);">yi+1</font> 是这两个锚点的值。

DFL 损失的核心思想是:首先确定真实值,如9.3,然后找到预测值中真实值上下两个整数坐标,如9.3向下取整是9,向上取整是10,找到这两个坐标以及对应的预测值。最后通过以上公式去计算损失。
注意:
DFL 的损失不是将16个值和真实值计算坐标,而是只取两个预测值去计算
具体的计算过程:
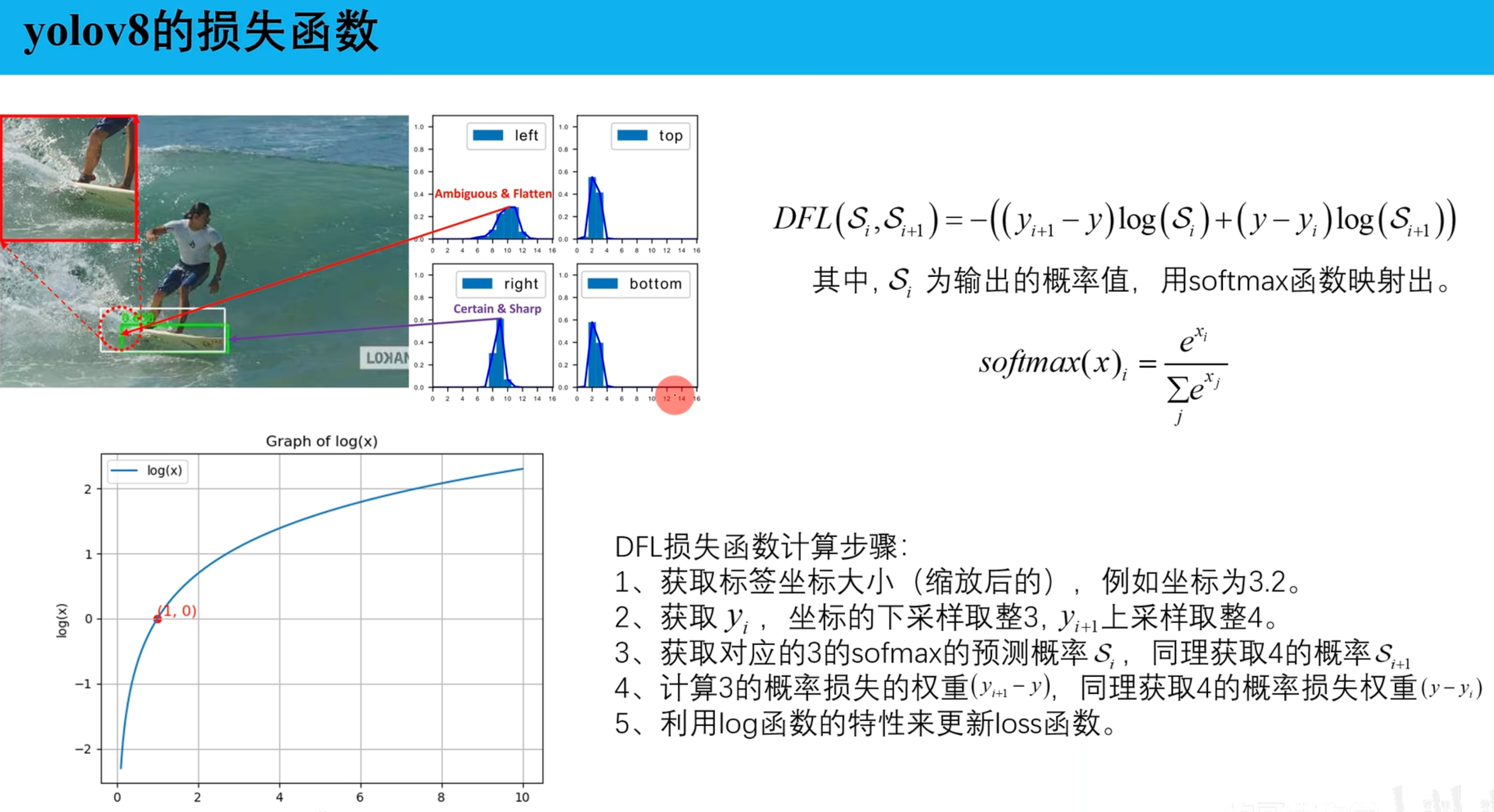
DFL损失函数计算步骤:
1、获取缩放后的标签坐标大小,例如坐标y为3.2
2、获取了yi坐标的下采样取整3,yi+1上采样取整4
3、获取对应的3的sofmax的预测概率Si,同理获取4的概率Si+1
4、 使用log函数计算 Si 和 Si+1 的输出
5、计算3的概率损失的权重(yi+1 - y),同理获取4的概率损失权重(y - yi)
6、两个概率分别乘以权重,然后相加再取反,得到最终的损失
损失权重计算
前面都没有提到损失的权重,这里再详细说明一下。在公式中,出了对预测Si结果做log运算,还需要给结果加一个权重。就是上面步骤5的内容:计算3的概率损失的权重(yi+1 - y),同理获取4的概率损失权重(y - yi)。
为什么有这种损失权重?
因为距离真实值越近希望获取的权重越大,这样能优化的更快,反之距离真实值越远就要设置越小的权重。
所以按照这种思路,示例计算如下:3离3.2更近,所以获得的权重较大,是(4.0-3.2) = 0.8,而4.0离3.2更远,所以获得权重较小,为(3.2-3.0) = 0.2。
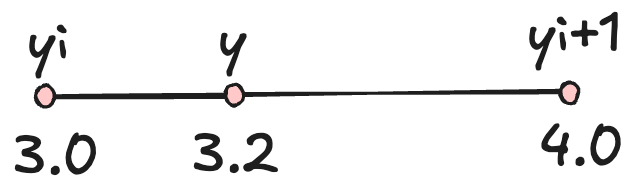
log 函数
x越接近1,y越接近0,x越接近0,y绝对值越大。
使用log函数处理Si和 Si+1的值,两个值越大则损失越小,也就是越概率越接近1,损失值就越小。然后将两个概率分别乘以对应的权重,最后相加取反得到一个正值的权重。
答疑
yolov8 获取的正样本远低于yolov5,为什么效果能好?
YOLOv8 虽然在正样本匹配数量上比 YOLOv5 更少,但效果却更好,这主要归功于其改进的正负样本分配策略、更高效的梯度流设计以及更先进的损失函数。以下是具体原因分析:
- 动态正负样本分配策略(Task-Aligned Assigner)
YOLOv8 采用了 Task-Aligned Assigner (TAL) 动态匹配策略,而 YOLOv5 使用的是静态的 IoU 匹配 或 边长比例分配 方式。TAL 综合考虑分类得分和回归 IoU,动态选择高质量的正样本,而不是像 YOLOv5 那样固定匹配规则。这使得 YOLOv8 能够:
- 更精准地选择关键样本:仅保留分类得分高且定位准确的样本,减少低质量匹配带来的噪声。
- 避免冗余匹配:YOLOv5 的 Anchor-Based 方式可能匹配多个低质量样本,而 YOLOv8 的 Anchor-Free 策略直接预测目标中心,减少无效匹配。
- 更丰富的梯度信息(C2f 模块)
YOLOv8 使用 C2f 模块替代 YOLOv5 的 C3 模块,其特点包括:
- 更多的跳层连接:增强梯度流动,提升模型收敛速度。
- 更高效的特征融合:通过 Split 和 Concat 操作,提高特征表达能力。
- 计算量优化:每个 BottleNeck 的输入通道数减少一半,降低计算成本。
- 改进的损失函数
YOLOv8 采用 DFL(Distribution Focal Loss)+ CIoU Loss 作为回归损失,而分类损失则使用 VFL(Varifocal Loss)(尽管部分版本仍沿用 BCE Loss)。这些改进:
- DFL:让模型更聚焦于目标位置附近的分布,提高定位精度。
- VFL:对高质量正样本赋予更高权重,提升分类性能。
相比之下,YOLOv5 仅使用 BCE Loss + CIoU Loss,优化目标较为单一。
- Anchor-Free 设计
YOLOv8 采用 Anchor-Free 策略,直接预测目标中心点,而 YOLOv5 依赖 Anchor-Based 机制。这一变化:
- 减少计算开销:避免大量 Anchor 匹配带来的计算负担。
- 提高泛化性:不再依赖人工设定的 Anchor 尺寸,适应不同目标形状。
- 更高效的训练策略
YOLOv8 在训练后期(最后 10 epoch)关闭 Mosaic 数据增强,避免过度干扰模型收敛。相比之下,YOLOv5 的静态增强策略可能引入噪声,影响最终精度。
结论
尽管 YOLOv8 的正样本数量比 YOLOv5 更少,但由于其 动态样本选择、更优的梯度流设计、改进的损失函数和 Anchor-Free 机制,使得每个正样本的质量更高,模型训练更高效,最终在精度上超越 YOLOv5。
为什么yolov8的anchor free 比 yolov5 的anchor base 更好?
YOLOv8 采用 Anchor-Free 设计相比 YOLOv5 的 Anchor-Based 方法表现更好,主要源于以下原因,同时也解释了为何 Anchor-Based 理论上收敛更快但最终性能可能不如 Anchor-Free:
1. 结构简化与泛化能力提升
- Anchor-Free 的优势:
YOLOv8 直接预测目标中心点和宽高(如基于中心点或关键点),避免了预设 Anchor 的局限性。这种设计:- 减少超参数依赖:无需针对数据集调整 Anchor 尺寸(YOLOv5 需聚类生成 Anchors),降低过拟合风险。
- 适应多尺度目标:通过特征金字塔(FPN/PAN)和动态标签分配(如 Task-Aligned Assigner),直接学习目标的绝对尺寸,对小目标和密集场景更鲁棒。
- Anchor-Based 的局限:
YOLOv5 的 Anchors 是固定的先验,若数据集目标尺寸分布与 Anchors 不匹配(如极端长宽比),模型需额外学习偏移量,增加复杂度。
2. 动态标签分配的优化
- YOLOv8 的 Task-Aligned Assigner:
动态根据分类置信度与预测框质量的联合指标(如 IoU)分配正样本,使训练更聚焦于高质量预测。这种机制比 YOLOv5 的静态分配(基于 Anchor 与 GT 的 IoU)更灵活,尤其适合复杂场景。 - Anchor-Based 的收敛快但上限低:
YOLOv5 的静态 Anchor 匹配在早期能快速收敛(因初始猜测更明确),但可能陷入局部最优,难以适应非常规目标分布。
3. 损失函数的设计改进
- YOLOv8 的分布焦点损失(DFL):
将边界框回归建模为分类任务(离散化宽高分布),提升定位精度,尤其对模糊边缘有效。而 YOLOv5 使用 CIoU 损失,依赖 Anchors 的初始位置,可能受限于 Anchors 的质量。 - 分类与定位的解耦:
YOLOv8 解耦分类和回归头,避免任务冲突,而 YOLOv5 的耦合设计可能因 Anchors 的偏差影响分类性能。
4. 模型容量与训练策略
- 更强的 Backbone 和 Neck:
YOLOv8 的 CSPDarkNet 和 PAN-FPN 结构优化了特征提取与融合效率,即使没有 Anchors 也能学习更丰富的特征。 - 更长的训练周期:
Anchor-Free 方法通常需要更长时间收敛(因需从零学习位置分布),但 YOLOv8 通过数据增强和优化策略(如 EMA、LR调度)弥补了这一点,最终达到更高精度。
为何 Anchor-Based 通常比Anchor-free 收敛更快?
- 先验知识加速初期训练:
Anchors 提供初始位置假设,模型只需学习微调偏移量,早期梯度更稳定。而 Anchor-Free 需从零学习位置,初期损失下降较慢。 - 样本分配更明确:
静态 Anchor 匹配规则(如 IoU>0.3)在早期能快速确定正负样本,而动态分配需要更多迭代优化。
总结:性能与收敛的权衡
- Anchor-Based(YOLOv5):
收敛快,适合小数据集或实时性要求高的场景,但性能受限于 Anchors 的设计。 - Anchor-Free(YOLOv8):
收敛慢但上限高,通过简化结构、动态优化和损失函数改进,最终在精度和泛化性上超越 Anchor-Based,尤其适合复杂任务。
实际选择需权衡速度与精度需求,但 YOLOv8 的改进证明了 Anchor-Free 在现代检测任务中的潜力。
