达梦存储结构篇
参照之前学习的Oracle存储结构博客来对比学习一下达梦 段存储结构,文章错误地方还请指教!
达梦dba_objects中data_object_id字段为NULL,并没有记录段id,在Oracle中一般情况下表ID一旦创建就不会改变,而段ID是会变化的,当表被Tuncate时,原来的段会被删除,再为表新建一个段,将原来储存的空间释放,重新分配新的区,这样就会出现表ID没变,但段ID变了,多次执行truncate可以发现,每当truncate后OBJECT_ID不变,DARA_OBJECT_ID+1
在达梦数据库中段是如何创建的呢?我们一起来看下
段是如何创建的(一表对应多段)
创建测试环境
dmdba@DAMENG:5236 SQL> create user PANDA identified by "DB_top_123";-- (default tablespace xxx )
操作已执行
dmdba@DAMENG:5236 SQL> grant dba to panda;
操作已执行
dmdba@DAMENG:5236 SQL> @us pandaShow database usernames from dba_users matching %panda%USERNAME ACCOUNT_STATUS DEFAULT_TABLESPACE TEMPORARY_TABLESPACE USER_ID CREATED PROFILE
-------- -------------- ------------------ -------------------- ----------- -------------------------- -------
PANDA OPEN MAIN TEMP 50331751 2025-10-13 16:26:25.046785 NULLps:不能是SYSTEM表空间,用户不能在 SYSTEM 表空间创建表和索引。
16:26:36 dmdba@DAMENG:5236 SQL> create user PANDA01 identified by "DB_top_123" default tablespace SYSTEM ;
create user PANDA01 identified by "DB_top_123" default tablespace SYSTEM ;
第1 行附近出现错误[-3406]:表空间[SYSTEM]不能作为默认表空间.
已用时间: 1.973(毫秒). 执行号:0.
1)普通表
create table tab1(id number);select * from user_segments; 创建了一个表段

段延迟创建
达梦也支持段的延迟创建,可以通过设置 ini 参数 DEFERRED_SEGMENT_CREATION=1 开启延迟段分配功能,也可以在建表语句中进行指定,参数类型是SYS动态参数不需要重启。具体的段分配情况可以通过查看 V$SEGMENT_INFOS 获取。
dmdba@DAMENG:5236 SQL> @p segmentPARA_NAME PARA_VALUE DEFAULT_VALUE SESS_VALUE FILE_VALUE PARA_TYPE DESCRIPTION
------------------------- ---------- ------------- ---------- ---------- --------- -----------------------------------------------
DEFERRED_SEGMENT_CREATION 0 0 0 0 SYS Whether enable default defered segment creationused time: 8.775(ms). Execute id is 12467.
dmdba@DAMENG:5236 SQL>
dmdba@DAMENG:5236 SQL> alter system set 'DEFERRED_SEGMENT_CREATION'=1 both;
DMSQL executed successfully
used time: 19.719(ms). Execute id is 12468.
dmdba@DAMENG:5236 SQL> @p segmentPARA_NAME PARA_VALUE DEFAULT_VALUE SESS_VALUE FILE_VALUE PARA_TYPE DESCRIPTION
------------------------- ---------- ------------- ---------- ---------- --------- -----------------------------------------------
DEFERRED_SEGMENT_CREATION 1 0 1 1 SYS Whether enable default defered segment creationused time: 7.797(ms). Execute id is 12469.create table tab2(id number);select * from user_segments; 可以看见开启DEFERRED_SEGMENT_CREATION后,新建立的表并没有分配段,和Oracle不同的是仍可以在user_segments视图查看但是段大小为0。

像表里插入数据,向表中插入一条数据后,发现分配了一个表段,共1048576 bytes32个簇
insert into tab1(id) values(1); select * from user_segments; 
计算一下一个段大小: 1*32(簇数)*32(页大小KB)*1024=1048576 bytes
dmdba@DAMENG:5236 SQL> @fun get%sizeNAME CLASS$
---------------------- -------------------
SF_GET_ARCHIVE_SIZE data watch function
SF_GET_EXTENT_SIZE system function
SF_GET_FILE_BYTES_SIZE system function
GET_DISK_SIZE system function
SF_GET_PAGE_SIZE system functionused time: 1.425(ms). Execute id is 12484.
dmdba@DAMENG:5236 SQL>
dmdba@DAMENG:5236 SQL> SELECT SF_GET_PAGE_SIZE()/1024 KB; KB
--
32used time: 1.875(ms). Execute id is 12485.
dmdba@DAMENG:5236 SQL>
dmdba@DAMENG:5236 SQL> select SF_GET_EXTENT_SIZE();SF_GET_EXTENT_SIZE()
--------------------
32used time: 2.448(ms). Execute id is 12486.由此可见,DM8中只有插入数据后才会分配段空间。可以通过参数控制全局指定是否立即创建段。
-- 立即创建
ALTER SYSTEM SET 'DEFERRED_SEGMENT_CREATION'=1; create table tab3(id number) segment creation immediate; -- 延迟创建
ALTER SYSTEM SET 'DEFERRED_SEGMENT_CREATION'=0; create table tab3(id number) segment creation deferred; 2)创建一个带主键的表
create table tab3(id number) segment creation deferred; -- 本实验是在堆表下测试的
dmdba@DAMENG:5236 SQL> @p list_tablePARA_NAME PARA_VALUE DEFAULT_VALUE SESS_VALUE FILE_VALUE PARA_TYPE DESCRIPTION
--------------------- ---------- ------------- ---------- ---------- --------- -----------------------------------------------------
LIST_TABLE 1 0 1 1 SESSION Whether to convert tables to LIST tables when created
LIST_TABLE_BRANCH 0 0 0 0 SYS concurrent branch number when list_table open
LIST_TABLE_NON_BRANCH 0 0 0 0 SYS non-concurrent branch number when list_table openused time: 6.311(ms). Execute id is 12490.分配了一个表段和索引段

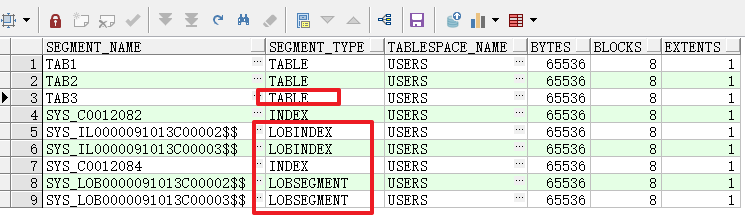
3)创建一个有 lob 字段的表
create table tab5(x int primary key, y clob, z blob) segment creation immediate; 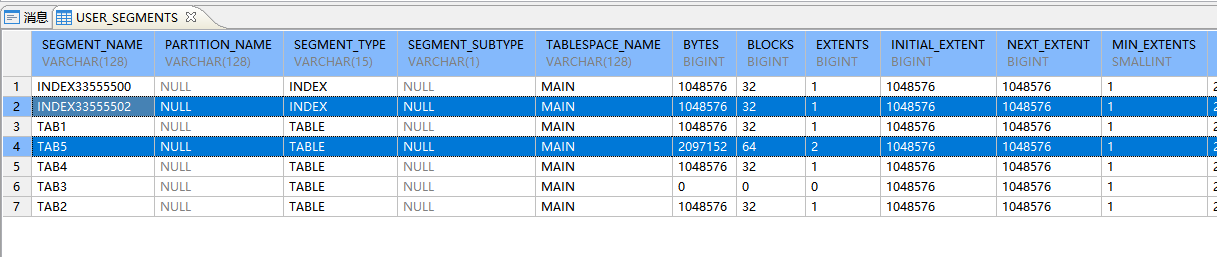
会有一个表段和一个索引段,并且表段初始分配了两个簇(2个extens)这个和Oracle是不一样的,相同ddl语句Oracle创建了一个表段、一 个索引段、2 个 lobindex,2 个 lobsegment,也就是Oracle会为每个大字段创建一个lob段和lob索引段。
结论:创建一个表时,表的信息及数据可能会分散到多个段之中,每个段保存着一部分信息, 而段由簇组成,簇由页组成,页由操作系统组成。
页中空间的使用
DM8中页的分配并没有把一个簇全部用完,而是分配了部分页,6*32*1024=196608bytes,后续后根据插入数据的的多少现分配。
select * from DBA_EXTENTS where owner='PANDA' ;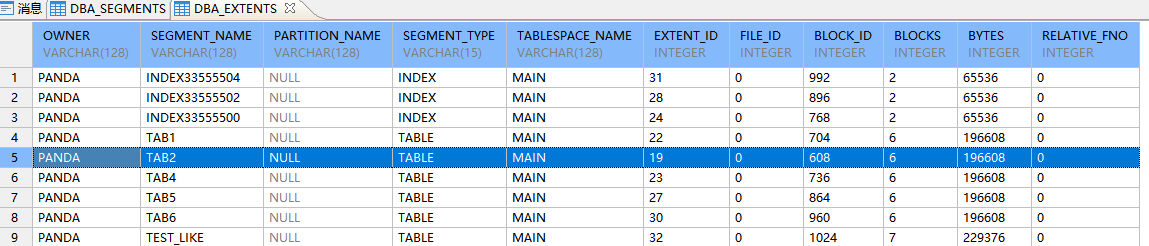
Oracle中关于区的管理方式有系统管理和统一区大小两种方式,在系统区管理的表空间中区大小随表的增大而增大,而在DM中簇大小和页大小在初始化实例之后不可更改,这里有哪些影响吗?
从空间利用率来讲,更小的存储分配方式会节省更多的空间,大簇可能会浪费空间,为一个表分配8MB的簇大小,他只用了1bytes,这个8MB空间也是属于这个表的,其他表无法在使用这部分空间,从这个角度讲小簇的空间利用率无疑是高的。
但从性能角度上讲,对于随机访问,大簇、小簇没有影响。但对于全表扫描这样的操作,大簇又是更合适的。因为连续空间更多,可以减少磁头在区间的定位。
在Oracle拥有系统管理区大小的方式下,当表比较小时,区也比较小,当表大时,区也随之变大这种方式无疑可以在空间的利用率、全扫描的性能之间找到一种平衡。因此建议大多数情况下,都可以采用系统管理区大小的方式。除非有某个表,已明确地知道它会很大,为了保证全扫描的性能,直接建一个统一区大小,并且区比较大的表空间,以便将表存放其中。如果使用统一区大小,几百KB甚至1MB的区,都有点小。其实可以参考系统管理型的表空间,当段的大小超过64MB时,区大小为8MB。在使用统一区大小时,也可以将所有区都固定为8MB。
而DM并没有提供簇分配方式的管理,一个簇用完在分配下一个,在插入数据时可能会影响插入效率,而且大小不能改所以建议在初始的时候就将簇大小和页大小设置的大一些,存储的数据越连续,IO次数才能更低。
create table demo01(id number,name varchar2(100));
-- 插入1百万条数据
INSERT INTO demo01
SELECT ROWNUM ,'test'||ROWNUM AS name
FROM dual
CONNECT BY ROWNUM <= 1000000;commit;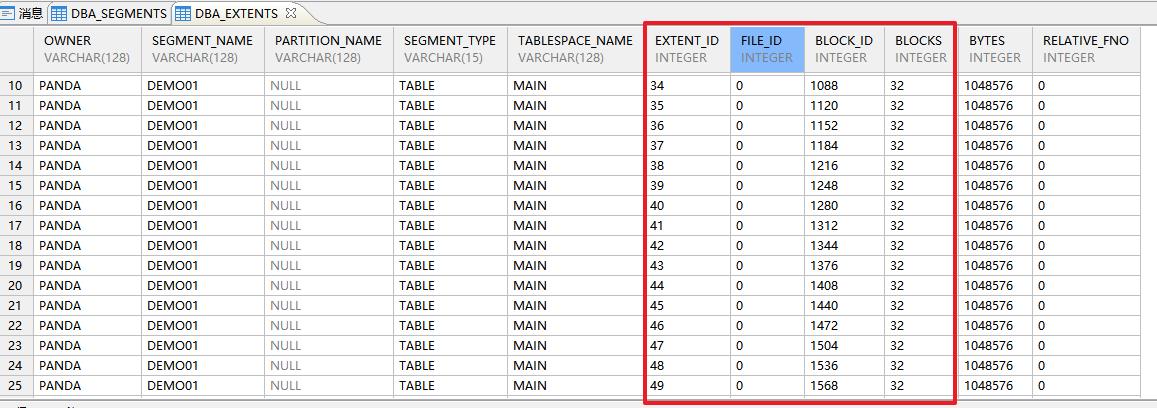
典型问题:堆表是有序的吗?
堆表是无序的,堆表的特点就是无序、插入快速。怎么证明呢?
dmdba@DAMENG:5236 SQL> @p list_table
dmdba@DAMENG:5236 SQL> select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%&1%');
old value 1:select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%&1%');
new value 1:select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%list_table%');PARA_NAME PARA_VALUE DEFAULT_VALUE SESS_VALUE FILE_VALUE PARA_TYPE DESCRIPTION
--------------------- ---------- ------------- ---------- ---------- --------- -----------------------------------------------------
LIST_TABLE 1 0 1 1 SESSION Whether to convert tables to LIST tables when created
LIST_TABLE_BRANCH 0 0 0 0 SYS concurrent branch number when list_table open
LIST_TABLE_NON_BRANCH 0 0 0 0 SYS non-concurrent branch number when list_table openused time: 13.029(ms). Execute id is 14410.CREATE TABLE panda.test_like (id number(10),name VARCHAR2(100), -- 姓名sfz VARCHAR2(20) -- 身份证号
);-- 查看表定义
dmdba@DAMENG:5236 SQL> @ddl panda.test_likeDBMS_METADATA.GET_DDL(OBJECT_TYPE,OBJECT_NAME,OWNER)
----------------------------------------------------------------------------------------------------------------------------------
CREATE TABLE "PANDA"."TEST_LIKE"
(
"ID" NUMBER(10,0),
"NAME" VARCHAR2(100),
"SFZ" VARCHAR2(20)) STORAGE(ON "MAIN", NOBRANCH) ;
used time: 9.703(ms). Execute id is 14810.-- 插入 100 万行模拟数据
INSERT INTO panda.test_like (id,name, sfz)
SELECT rownum,-- 随机生成中文姓名SUBSTR(base.surnames, FLOOR(DBMS_RANDOM.VALUE(1, 61)), 1)|| SUBSTR(base.first_names, FLOOR(DBMS_RANDOM.VALUE(1, 81)), 1)|| CASEWHEN DBMS_RANDOM.VALUE(0, 1) > 0.5THEN SUBSTR(base.second_names, FLOOR(DBMS_RANDOM.VALUE(1, 41)), 1)ELSE ''END AS name,-- 生成身份证号(前6位固定为421125)'421125'|| TO_CHAR(base.start_date + FLOOR(DBMS_RANDOM.VALUE(0, (base.end_date - base.start_date) + 1)),'YYYYMMDD')|| LPAD(FLOOR(DBMS_RANDOM.VALUE(0, 10000)), 4, '0') AS sfz
FROM (SELECT LEVEL AS n FROM dual CONNECT BY LEVEL <= 1000) num_seq, -- 1000000 1百万(SELECT '赵钱孙李周吴郑王冯陈褚卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜戚谢邹喻柏水窦章云苏潘葛奚范彭郎鲁韦昌马苗凤花方俞任袁柳' AS surnames,'伟芳娜秀英敏静丽娟英华慧巧美静文萍玲芳燕敏玲晓锋刚勇毅俊峰强军平保东文辉力明永健世广志义兴良海山仁波宁贵福生龙元' AS first_names,'伟芳娜秀英敏静丽娟英华慧巧美静文萍玲芳燕敏玲晓锋刚勇毅俊峰强军平保东文辉力明' AS second_names,TO_DATE('1900-01-01', 'YYYY-MM-DD') AS start_date,TO_DATE('2005-12-31', 'YYYY-MM-DD') AS end_dateFROM dual) base;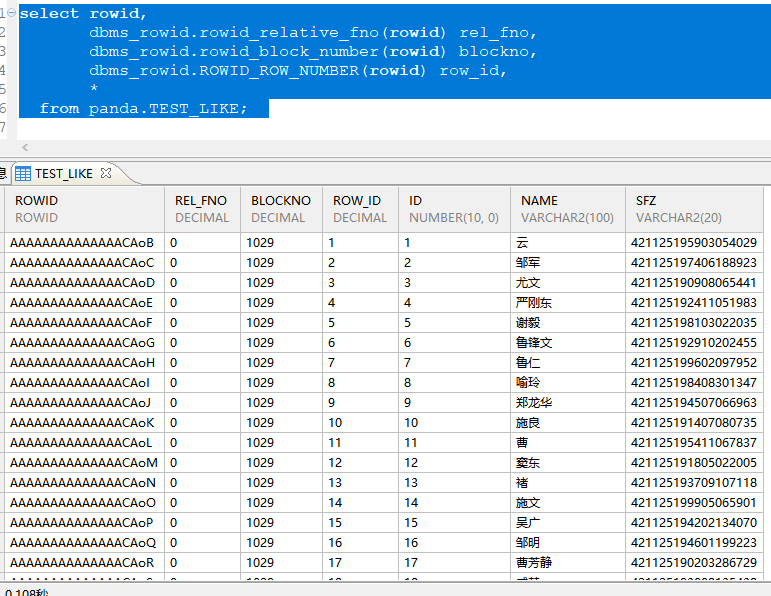
修改并发分支,再试试也是单调递增?哪里出问题了?dbms_rowid.ROWID_ROW_NUMBER(rowid)获取的物理位置不对?
dmdba@DAMENG:5236 SQL> alter system set 'LIST_TABLE_BRANCH'=2;
DMSQL executed successfully
used time: 13.594(ms). Execute id is 14411.
dmdba@DAMENG:5236 SQL>
dmdba@DAMENG:5236 SQL> alter system set 'LIST_TABLE_NON_BRANCH'=2;
DMSQL executed successfully
used time: 13.001(ms). Execute id is 14412.
dmdba@DAMENG:5236 SQL>
dmdba@DAMENG:5236 SQL> @p list_table
dmdba@DAMENG:5236 SQL> select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%&1%');
old value 1:select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%&1%');
new value 1:select para_name,para_value,DEFAULT_VALUE,SESS_VALUE,FILE_VALUE,para_type,DESCRIPTION from v$dm_ini where para_name like upper('%list_table%');PARA_NAME PARA_VALUE DEFAULT_VALUE SESS_VALUE FILE_VALUE PARA_TYPE DESCRIPTION
--------------------- ---------- ------------- ---------- ---------- --------- -----------------------------------------------------
LIST_TABLE 1 0 1 1 SESSION Whether to convert tables to LIST tables when created
LIST_TABLE_BRANCH 2 0 2 0 SYS concurrent branch number when list_table open
LIST_TABLE_NON_BRANCH 2 0 2 0 SYS non-concurrent branch number when list_table openused time: 14.507(ms). Execute id is 14413.查了一下文档DM堆表确实是无序的但是没有证明出来,在问答社区看到了另一种通过伪劣PHYROWID 获取文件号行号的方法和DBMS_ROWID一样而且不限制表类型。
select rowid,PHYROWID,((PHYROWID >> 48) & 0xFF) AS FILE_NO,((PHYROWID >> 16) & 0xFFFFFFFF) AS PAGE_NO,* from panda.TEST_LIKE;有序的索引组织表
DM默认创建的是普通表也就是索引组织表,
dmdba@DAMENG:5236 SQL> @ddl dbmt.test_likeDBMS_METADATA.GET_DDL(OBJECT_TYPE,OBJECT_NAME,OWNER)
-----------------------------------------------------------------------------------------------------------------------------------
CREATE TABLE "DBMT"."TEST_LIKE"
(
"ID" NUMBER(10,0),
"NAME" VARCHAR2(100),
"SFZ" VARCHAR2(20)) STORAGE(ON "MAIN", CLUSTERBTR) ;
used time: 6.947(ms). Execute id is 14811.IOT表是有序存储的,DM提供了一个SF_GET_REAL_ROWID 根据 ROWID 数据类型获取本条数据的物理行号。本函数不适用于堆表的 ROWID。
SELECT t.*,t.rowid,SF_GET_REAL_ROWID(t.rowid) AS real_rowid
FROM dbmt.test_like t order by id;
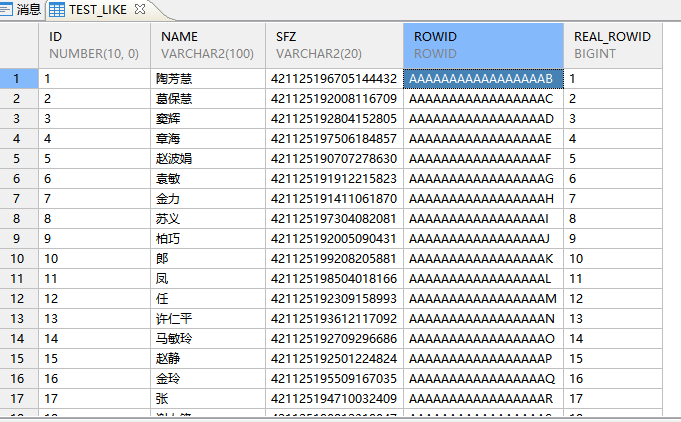
可以看到通过SF_GET_REAL_ROWID获取的物理行号和插入顺序id号是一一对应关系。