李宏毅机器学习笔记22
目录
摘要
Abstract
1.Decoder-Autoregressive(AT)
如何开始
masked
如何停止
2.Decoder-Non-Autoregressive(NAT)
摘要
本篇文章继续学习李宏毅老师2025春季机器学习课程,学习内容是Transformer中decoder的基本架构,主要学习Decoder-Autoregressive(AT)的基本运作过程,以及Decoder-Non-Autoregressive(NAT)与Decoder-Autoregressive(AT)的差异。
1.Decoder-Autoregressive(AT)
如何开始
用语言辨识作为例子帮助理解decoder,首先是一段语音输入到encoder产生一排向量,产生的向量作为decoder的输入。在decoder产生文字之前,我们需要给他一个特殊的符号begin作为开始的信号,接下来decoder会输出一个向量,这个向量的长度非常长,它是vocabulary的size,在语音辨识中是可能的方块字(3000+常用汉字)。每一个中文字对应一个数值,数值最高的作为当前的输出。
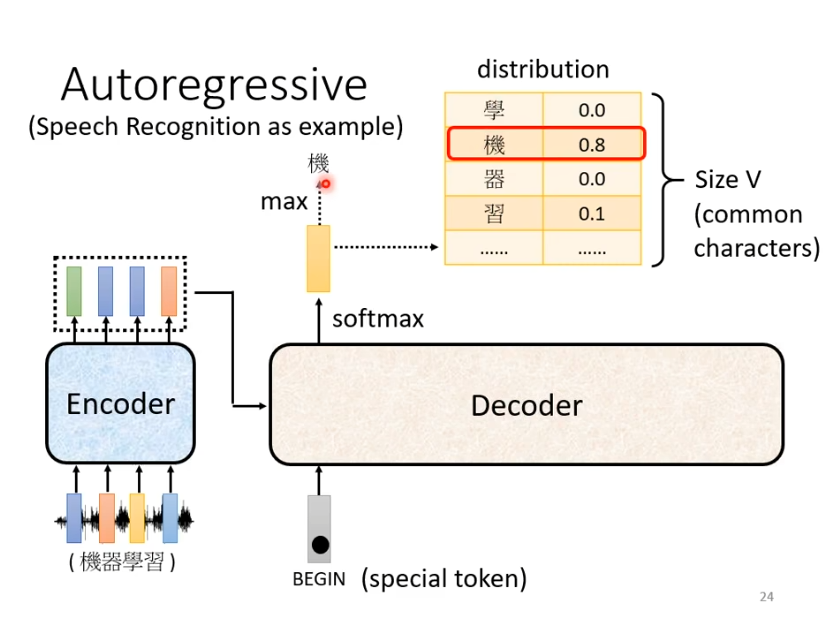
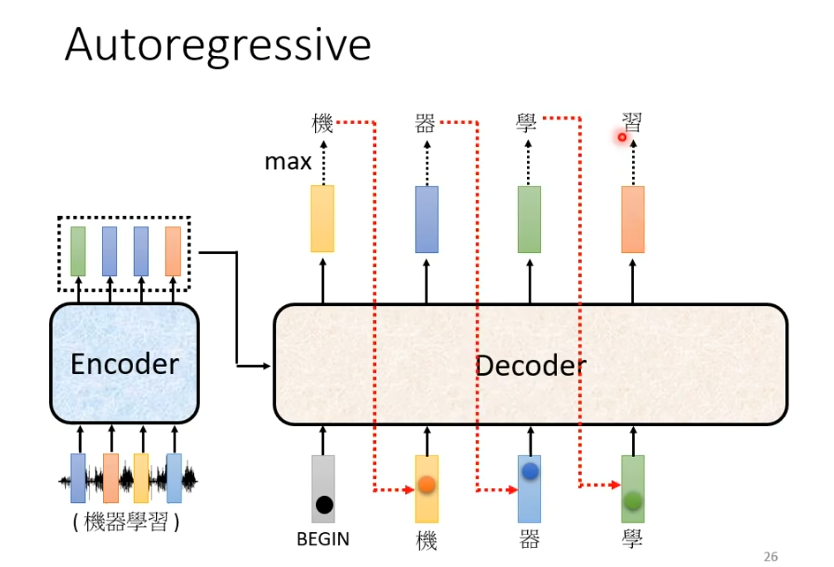
在得到第一个输出的字“机”后,“机”与begin作为decoder的输入,假设这次输出是“器”,下一次就会将begin和“机",“器”作为输入,以此类推。decoder会将自己的输出,当作自己的输入。
decoder的结构如下图所示
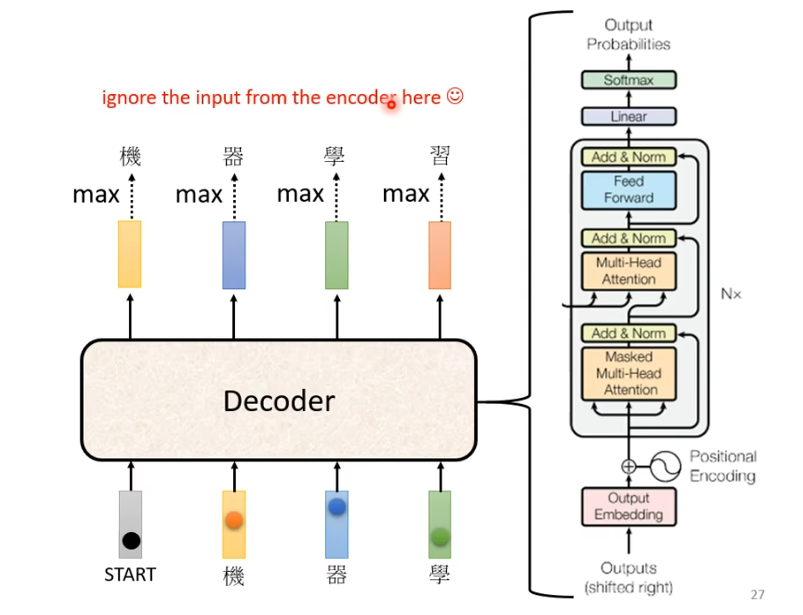
我们将encoder和decoder放在一起比较一下
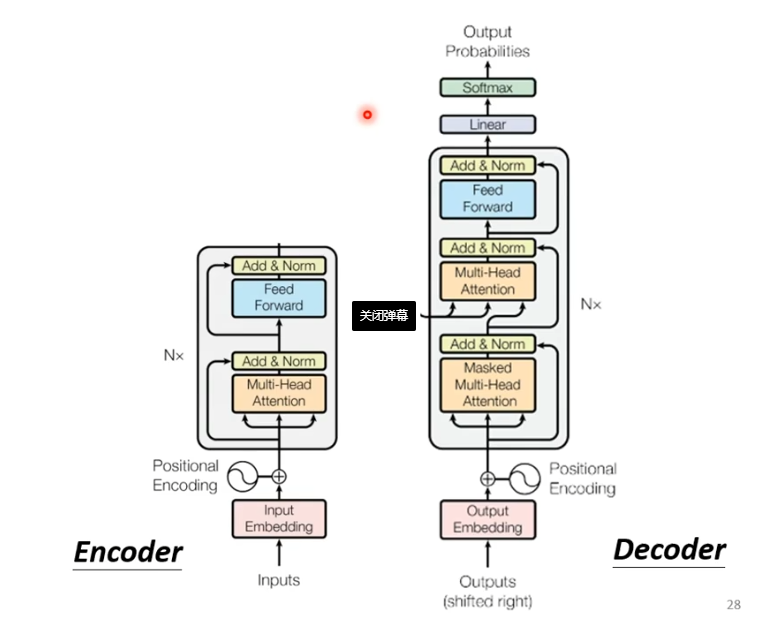
不难看出,如果我们把decoder中间部分去掉,encoder与decoder就非常相似。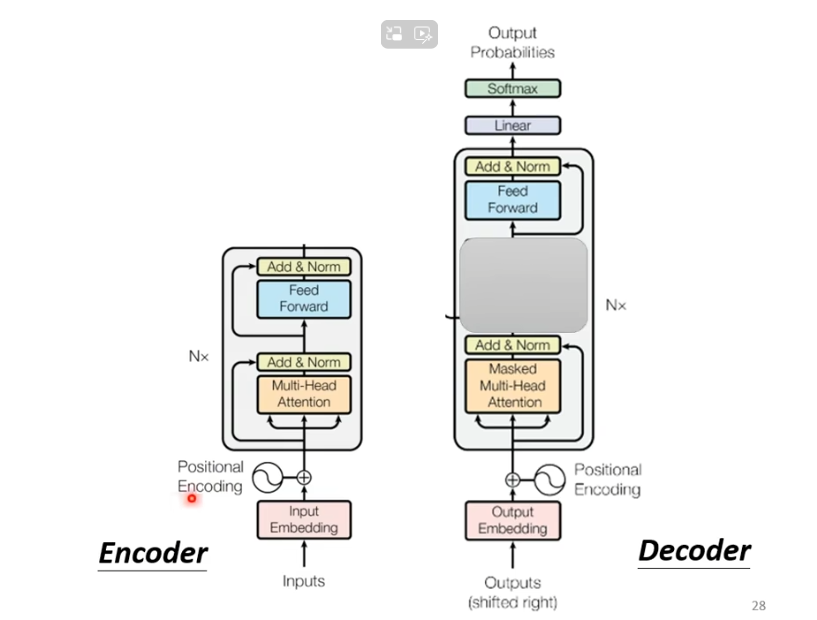
不同之处在于,decoder在multi-head这个block上面增加了一个masked。
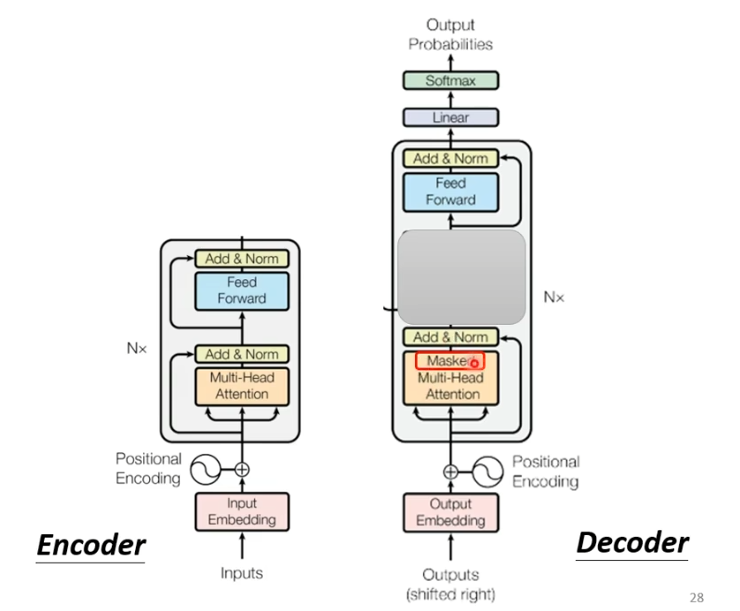
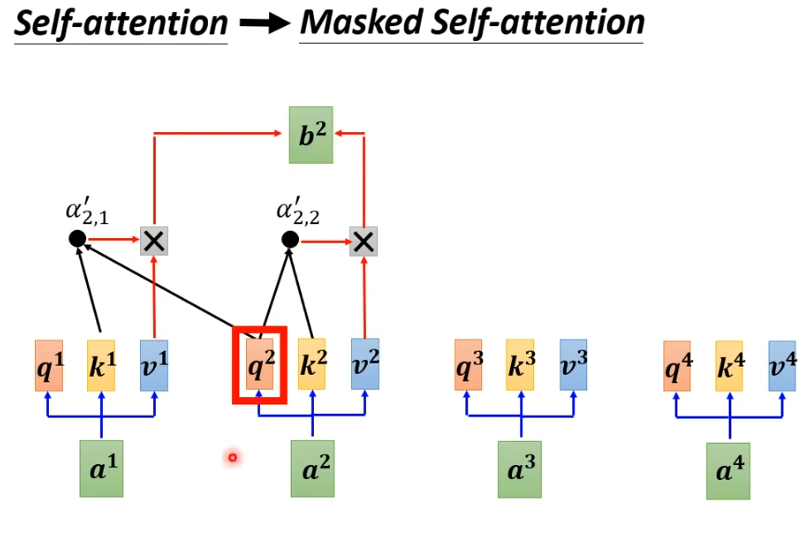
masked
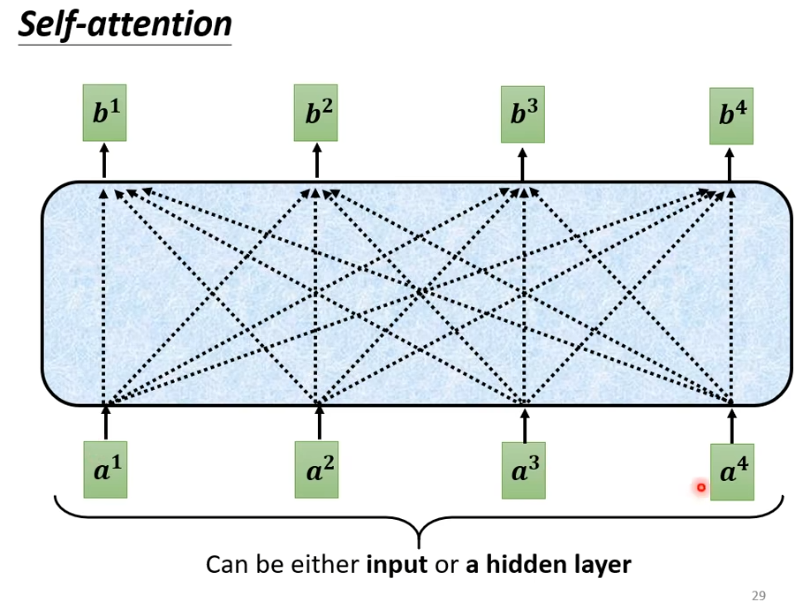
masked是什么呢?我们原本的self-attention是根据所有的信息产生输出。b1由a1-a4产生,b2 也由a1-a4产生,b3,b4同样由a1-a4产生。
增加masker之后,我们不能再看右边。即b1只由a1产生,b2由a1,a2产生,b3由a1,a2,a3产生,b4由a1-a4产生。
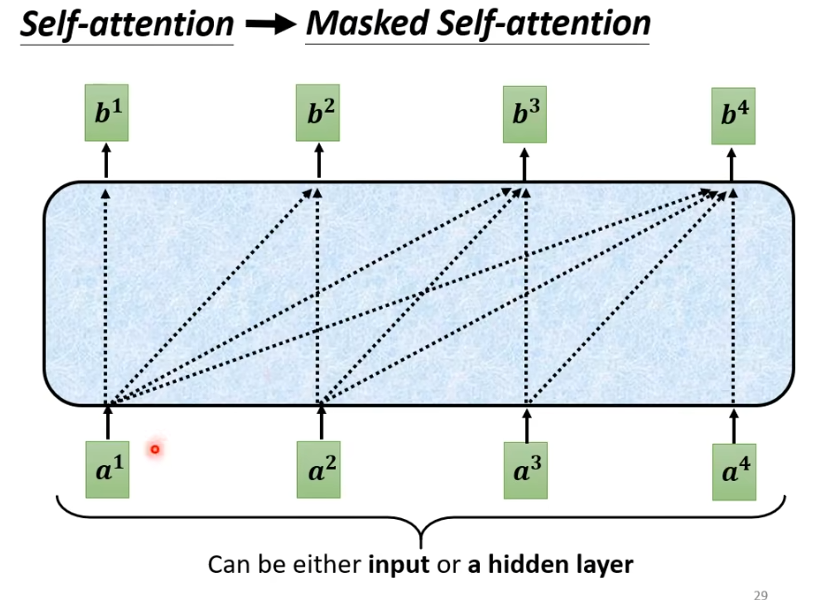
具体来说,就是计算时,只考虑前面,假设计算b2,我们只考虑q1,k1,q2,k2。
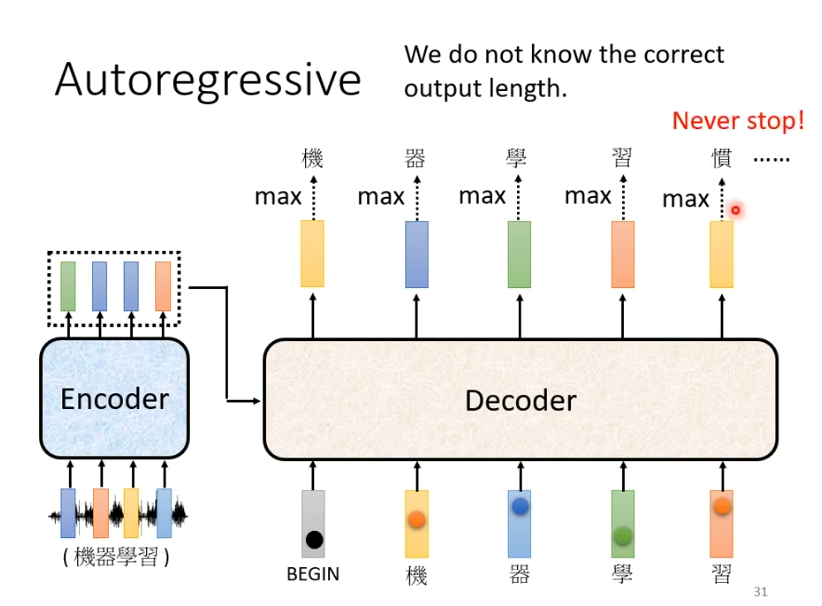
如何停止
在实际上,输入与输出长度的关系是非常复杂的,在我们的例子中可能在输出“习”之后还会继续输出“惯”等等,因为它并不知道什么时候应该停止。
那么我们想要让他停下来,就需要我们准备一个特别的符号“断”,假设用END表示。
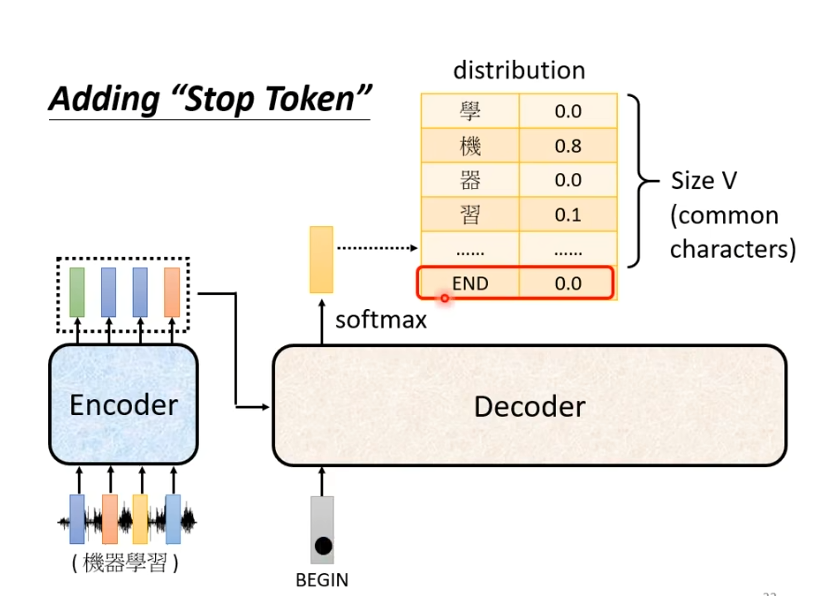
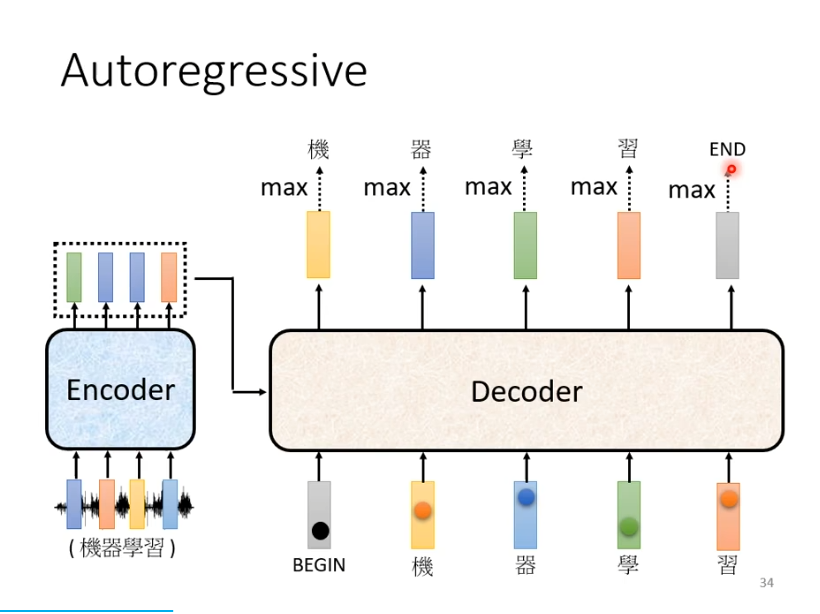
此时,我们就期望当输出“习”时,它知道语音辨识的结果已经结束了,不需要产生更多的词汇,产生的向量中END的几率必须是最大的。产生END后,decoder产生sequence的过程就结束了。
2.Decoder-Non-Autoregressive(NAT)
NAT与AT的差别在于AT是一个一个产生,NAT是一次全部产生。NAT的输入全是begin信号,一个begin对应一个字。
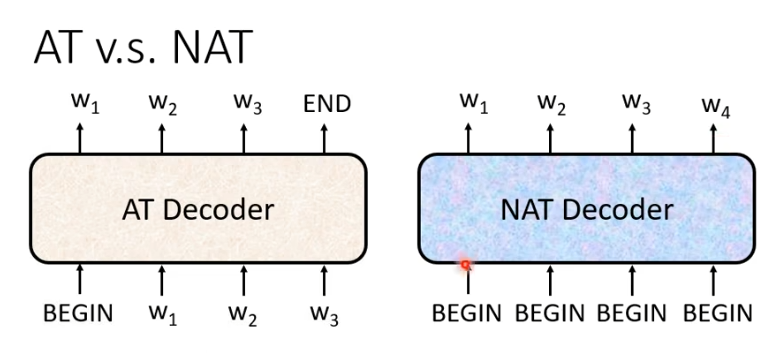
但是我们如何知道需要输出多少字?
一个做法是另外扔一个classifier,它吃encoder的输入输出是一个数字,代表输出的长度。
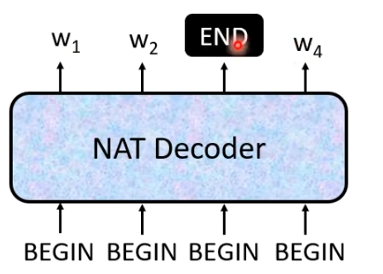
另一种做法是,假设句子的长度上限是300,我们就输入300个begin,观察什么时候输出END。
NAT的优势在效率比AT更高,AT是一个一个字产生,假设100个字就要decode100次,而NAT都是一次输出,所有NAT会比AT更快。