hive join优化和数据倾斜处理
1. Hive join优化
使用Hive Join语句时,如果数据量大,可能造成SQL执行速度和查询速度慢,可以进行join优化,Join优化可分为Map Join、Bucket Map Join、Sort Merge Bucket MapJoin、Join 顺序优化。
1.1 map join
Hive Map Join适合大表 Join 小表场景,可以将小表数据加载到内存中与大表进行关联,SQL转换的MR任务只有Map阶段没有Reduce阶段,Map Join原理是在Map任务前起了一个MapReduce Local Task,这个Task通过TableScan读取小表内容到本机,在本机以HashTable的形式保存并写入硬盘上传到HDFS,并在distributed cache中保存,在Map Task中从本地磁盘或者distributed cache中读取小表内容直接与大表join得到结果并输出。
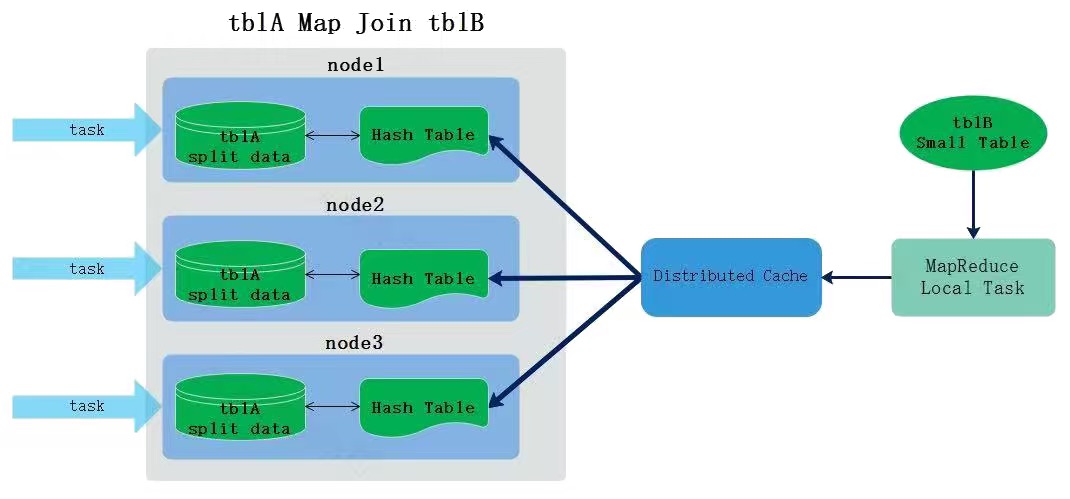
关于Map Join的相关参数如下:
- hive.auto.convert.join:该参数决定是否自动优化普通join为map join,默认为true,建议设置为true。如果不能转换成map join,自动执行common join,即转换成MR任务执行。
- hive.mapjoin.smalltable.filesize:该参数 设定小表文件大小阈值,默认25000000byte,约25M,即所有文件输入总大小小于该值的表都会看做小表加载到内存,根据实际情况设置该值,该值描述的是表文件大小,加载到内存中占用内存空间更大。
注意:使用Map Join时需要注意小表不能过大,如果小表将内存基本用尽,会使整个系统性能下降甚至出现内存溢出的异常。
1.2 Bucket Map Join
Bucket Map Join可以看成是对Map Join的改进,Map Join适合大表Join小表场景,如果两张表都比较大,就无法将一张表数据缓存到内存中进行Join,这时可以使用Bucket Map Join。
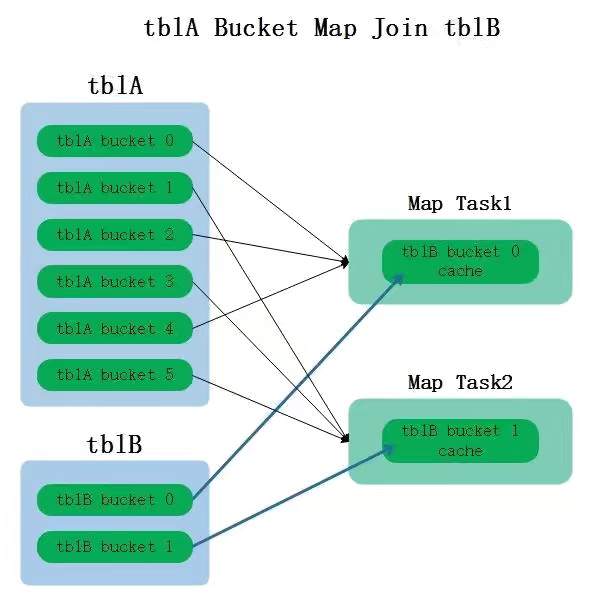
Bucket Map Join适合大表Join大表场景,使用Bucket Map Join时要求两张Join表都是分桶表,并且按照分桶字段进行关联,此外还要求一张表分桶数是另外一张表的整数倍。其原理是在对应的节点上只需要将另外一张表对应的bucket桶数据进行缓存即可,不需要缓存表所有数据,这样就可以实现高效率的Join操作,要求一张表分桶数是另外一张表的整数倍的原因是保证两张表分桶之间有确定的对应关系。
下图是Bucket Map Join示意图,有tblA 和 tblB两个分桶表,两表都是按照关联字段id进行分桶,tblA 分了6个桶(假设每个桶中id分别为0,1,2,3,4,5),tblB分了2个桶(假设桶0中id为0,2,4;桶1中id为1,3,5),那么每个task进行Join关联时就可以缓存部分tblB中的数据,而不需要将tblB整个表都进行缓存处理。
#该参数表示是否忽略SQL中的hint语法,默认为true,使用hint需要设置为false
set hive.ignore.mapjoin.hint=false
#该参数表示关闭cbo优化,默认为true。开启cbo优化也会忽略sql中的hint语法,所以需要关闭。
set hive.cbo.enable=false
1.3 Sort Merge Bucket MapJoin
Sort Merge Bucket Map Join 简称 SMB Map Join,其与Bucket Map Join非常类似(也可以看成Bucket Map Join一种情况),也是适合两张大表进行Join关联场景,也要求两张Join表都是分桶表、一张表分桶数是另外一张表的整数倍、并且Join按照分桶字段进行关联,与Bucket Map Join不同的是 SMB Map Join还要求桶内的表数据按照分桶字段有序。
除了桶内的表数据按照分桶字段有序这点区别之外, SMB Map Join与Bucket Map Join两者在Join方式上也有区别:Bucket Map Join是将一张分桶表的桶数据进行缓存与另外一张表进行Join关联来避免shuffle操作,而SMB Map Join由于两表中关联字段就是分桶列,且分桶类内的数据有序,那么Mapper就可以依次获取两张表中相同桶内的相同数据进行Join关联,而不进行当前桶数据缓存,同样达到避免shuffle过程。
SMB Map Join相关参数如下:
- hive.auto.convert.sortmerge.join
该参数表示是否启动自动转换SMB Join,默认为true,建议设置为true。
- hive.optimize.bucketmapjoin.sortedmerge
该参数表示是否启用SMB Map Join,默认值为false,使用SMB Map Join 建议设置为true开启。
1.4 Join 顺序优化
当有3张及以上大表进行Join时,选择不同的Join顺序,执行时间可能存在较大差异,使用恰当的Join顺序可以有效缩短任务执行时间。虽然有CBO优化默认会进行join顺序调整,但是如果表存在数据倾斜或者查询条件值在表中不存在的情况,可能调整出非最优的join顺序,可以根据表中数据量大小和业务关联关系,人为调整表关联顺序,多表Join 顺序原则:优先关联Join出来结果较小的表,将这些表前置,可以加快数据处理结果。
2. 数据倾斜处理
在Hive中,数据倾斜(Data Skew)是指在执行SQL查询时,某些任务(task)处理的数据量显著多于其他任务,导致负载不均衡,从而影响查询的整体性能。这种现象通常发生在数据分布不均的表分组聚合或者表Join连接操作时。
2.1 开启Map-Side预聚合
在Hive中Map-Side预聚合是一种优化技术,可以减少Shuffle阶段的数据量和网络传输成本。HQL转换成MapReduce任务执行,Map阶段的输出会被shuffle并根据key进行排序,然后发送给Reduce阶段进行进一步处理,对于聚合操作场景,Map-side预聚合允许在Map任务结束之前对数据进行局部聚合,可以显著减少Reduce阶段需要处理的数据量,Map-Side预聚合可以解决数据倾斜的原因也在于此。
Map-Side预聚合相关参数如下:
- hive.map.aggr
该参数表示在group by语句中是否开启map端预聚合,默认为true,建议设为true。
- hive.map.aggr.hash.min.reduction
该参数控制聚合查询时表是否适合执行Map-side预聚合,默认值为0.99。判断方式:首先对若干条数据(hive.groupby.mapaggr.checkinterval设置)进行map-side聚合,聚合后的结果条数与聚合前的条数比例如果小于该值,则认为表聚合查询适合进行map-side聚合,否则不适合。建议设置为默认值。
- hive.groupby.mapaggr.checkinterval
该参数是用于判断源表是否适合map端预聚合的条数,默认值100000。建议设置为默认值。
- hive.map.aggr.hash.force.flush.memory.threshold
该参数表示Map-Side聚合使用到的hash表占用map task 堆内存最大比例,默认值0.9,超过该值,则会将hash 表强制刷写磁盘。
2.2 开启GroupBy自动均衡
如果对一张存在数据倾斜的表进行Group By操作时,可以将“hive.groupby.skewindata”参数设置为true,默认为false,表示不开启group by 数据倾斜均衡,如果设置为true,Hive在执行 GROUP BY 操作时会通过两个MR任务对倾斜数据进行负载均衡处理。
- 第一个MR任务:将数据随机分散到各个Reduce Task处理,每个Reduce Task对数据进行group by key 初步聚合。
- 第二个MR任务:对第一个MR任务的结果继续按照group by key分组字段进行聚合,完成最终聚合操作。
“hive.groupby.skewindata”自动均衡原理可以看做将聚合操作分成两个步骤完成,先分散局部聚合,使每个任务处理数据量相对均衡,然后再对聚合结果再次聚合,从而减少一次聚合将大量相同倾斜key交由一个task处理出现的倾斜问题。
开启hive.groupby.skewindata参数需要注意如下问题:
- 开启该参数会执行两个MR Job,可能会增加额外的计算量和存储量,需要权衡利弊。
- 该参数仅针对group by的SQL操作有效。
2.3 双重聚合
在对倾斜的数据表进行group by处理时,也可以通过双重聚合来解决倾斜问题。所谓双重聚合是用户自己对group by的key随机加前缀,聚合一次,然后再去掉前缀,再次按照相同的key 分组聚合。随机加前缀后第一次聚合实际上已经将倾斜的key得到初步的聚合结果,再去掉前缀再次聚合能保证倾斜的key聚合结果的聚合。
这种方式类似开启GroupBy自动均衡参数,实际上就是用户将数据倾斜问题通过多个步骤打散解决。
2.4 开启 map join
在数据倾斜的表进行Join时,可以通过开启Map Join解决数据倾斜。Hive Map Join适合大表 Join 小表场景,可以将小表数据加载到内存中与大表进行关联,将小表加载到内存与倾斜的表进行join操作,自然也就不会存在shuffle,也没有reduce task处理倾斜问题。关于map join参数参考map join小节。
2.5 开启Skew Join
大表和大表进行Join时,并且其中一张表存在数据倾斜时,可以开启Skew Join来解决数据倾斜问题,Skew join解决数据倾斜原理如下:在执行SQL时会将倾斜的key存入到HDFS目录中,其余非倾斜的key正常join,对倾斜的key使用map join操作来避免shuffle倾斜,最后将两部分结果通过union进行合并得到最终结果。
Skew Join相关参数如下:
- hive.optimize.skewjoin
该参数表示是否开启skew join,默认为false,数据倾斜存在时,建议设置为true。
- hive.skewjoin.key
该参数表示触发执行skewjoin倾斜key的阈值,默认值为100000,如果某个键的行数超过10万行,则认为该键存在数据倾斜,会执行skewjoin。
2.6 随机加前缀并扩容数据Join
如果两张大表进行Join,其中一张大表有数据倾斜,可以使用这种方式,这种方式本质就是用户自己对倾斜的key加随机前缀进行打散,然后对另外一张表相同key的数据进行扩容,这样就能保证随机加前缀的所有key都能与另外一张表数据join对应上,然后将随机加前缀的数据进行join操作,这样就不存在数据倾斜,最后再去掉前缀得到结果。其原理如下图所示:
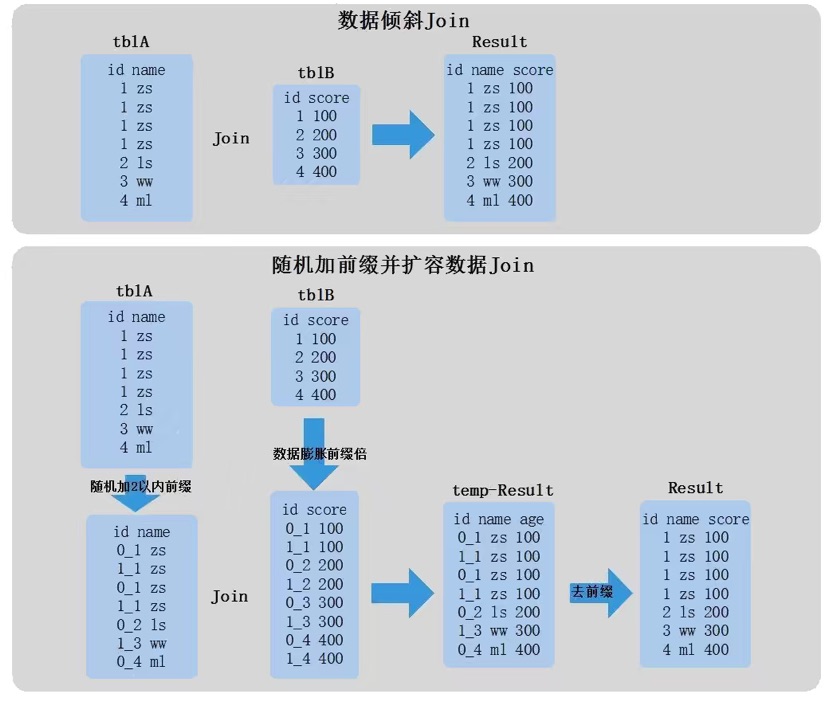
这种方式可以配合增加处理数据并行度来加快处理速度,但也存在弊端:如果对倾斜的key膨胀N倍,另外一张表数据每个key都要膨胀N倍,会导致计算过程占用大量磁盘空间。