K8s Pod详解与进阶实战
前言
一、Pod 的详解
1. Pod 基础概念
2. Pod 的两种使用方式
🧩 单容器 Pod
🔗 多容器 Pod
3. Pause 容器(基础容器)
4. Pod 的共享资源
🕸 网络共享
💾 存储共享
5. Pod 的存在意义(总结)
6. Pod 的典型使用场景
7. Pod 的类型
8. Pod 容器的分类
8.1 基础容器(Infrastructure Container)
8.2 初始化容器(Init Containers)
🌱 启动流程
📦 Init 容器的作用
二、Init 容器实战与 Pod 镜像策略
1. Init 容器实战案例
🧠 解析:
🔧 配合 Service 测试
2. Pod 的镜像拉取策略(imagePullPolicy)
🧭 策略类型:
🧪 实践案例:镜像拉取策略
3. Pod 的重启策略(restartPolicy)
🧩 案例演示
💡 小结
三、Pod 的进阶 —— 资源限制与调度机制
1. 为什么需要资源限制?
2. 资源配置字段
3. 资源单位说明
🧠 CPU 单位
💾 内存单位
4. Pod 资源配置示例
示例 1:指定资源请求与限制
✨ 分析:
示例 2:不同容器资源配比
💡 结果分析:
5. 调度与资源分配
🧩 实际案例输出:
6. Kubernetes 的资源分配逻辑总结
四、Pod 健康检查机制(Probe)详解与实战
1. 什么是探针(Probe)
2. 三种探针类型
3. 探针支持的三种检测方式
4. 探针的三种检测结果
5. exec 探针实战
示例:使用 exec 命令检测文件存在性
6. httpGet 探针实战
官方示例
案例:检测自定义 Web 服务
7. tcpSocket 探针实战
8. readinessProbe —— 就绪检测
案例:readiness + liveness 同时存在
9. readinessProbe 服务联动案例
10. startupProbe —— 启动检测
11. 探针常用参数详解
12. 小结
五、Pod 生命周期、状态详解与总结
1. Pod 生命周期(Lifecycle)
2. 容器生命周期钩子(Lifecycle Hooks)
📦 实例:postStart 与 preStop
🔧 测试命令
3. Pod 状态(Phase)
4. 容器状态(Container State)
📊 状态流转示意
5. Pod 状态诊断命令
查看 Pod 详细状态:
查看 Pod 所有容器的日志:
持续监控状态变化:
结合命名空间查看系统 Pod:
6. 实战案例总结
7. Kubernetes 调试 Pod 常用命令
总结
补充:httpGet 与 tcpSocket 的区别与使用总结
🧩httpGet 探针
✅ 定义
✅ 示例
✅ 工作原理
✅ 适用场景
🔌tcpSocket 探针
✅ 定义
✅ 示例
✅ 工作原理
✅ 适用场景
⚖️ 两者核心区别
⚠️常见误区:Nginx 用 tcpSocket 探针的陷阱
❌ 错误配置示例
问题说明
✅ 正确配置方式
🧪实际案例对比
🧠总结与建议
前言
在 Kubernetes 的世界中,Pod 是一切运行的起点。 无论是 Web 服务、数据库实例,还是后台任务,最终都以 Pod 的形式运行在集群之中。
但许多初学者只停留在“Pod 是容器集合”这一层理解,而忽视了它背后更深的设计哲学 —— Pause 容器的命名空间隔离、多容器的协作模式、Init 容器的初始化逻辑、探针与生命周期钩子的健康管理机制。
本文将带你从基础到进阶,全面拆解 Pod 的内部工作机制与配置逻辑,包括:
-
单容器与多容器 Pod 的结构区别
-
Init 容器与 Pause 容器的底层机制
-
镜像拉取与重启策略的实际应用
-
资源请求(Request)与限制(Limit)策略
-
探针(Probe)与生命周期(Lifecycle)的实战演示
阅读完本文后,你将不仅能部署 Pod,还将真正理解它如何启动、运行、退出与自我修复。 这是迈向 Kubernetes 高级实践(如 Deployment、StatefulSet、Operator)的关键一步。
一、Pod 的详解
1. Pod 基础概念
Pod 是 Kubernetes 中的最小部署单元,代表集群中运行的一个进程。 一个 Pod 可以包含一个或多个紧密耦合的容器,这些容器共享:
-
网络资源(同一个 IP 与端口空间)
-
存储资源(共享 Volume)
Kubernetes 中的更高层对象(如 Deployment、StatefulSet、DaemonSet)都是在 Pod 基础上扩展而来的。
2. Pod 的两种使用方式
🧩 单容器 Pod
最常见用法,一个 Pod 只包含一个容器。 Kubernetes 管理的是 Pod,而非单个容器。
apiVersion: v1 kind: Pod metadata:name: single-container-pod spec:containers:- name: nginximage: nginx:1.14
🔗 多容器 Pod
一个 Pod 可以包含多个容器,通常用于协作型任务,如日志收集、副本监控等。
apiVersion: v1 kind: Pod metadata:name: multi-container-pod spec:containers:- name: appimage: my-app:latest- name: sidecarimage: log-collector:latest
在同一个 Pod 内的容器之间:
-
可以通过
localhost通信(共享网络命名空间) -
可以挂载共享 Volume 实现数据交换
3. Pause 容器(基础容器)
在每个 Pod 中,都有一个特殊容器 —— Pause 容器。 它的职责是为 Pod 提供 Linux 命名空间(Namespace)基础。
-
负责建立网络、PID、IPC、UTS 等命名空间
-
Pod 内其他容器共享该命名空间
-
负责网络与存储的隔离与共享
👉 举例:
docker ps -a | grep pause registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0 "/pause"
该容器由 Kubelet 自动启动,对用户透明。
4. Pod 的共享资源
🕸 网络共享
-
每个 Pod 拥有一个独立的 IP 地址。
-
Pod 内所有容器共享 IP 与端口,可通过
localhost通信。 -
与外部通信时,通过宿主机端口映射暴露服务。
💾 存储共享
Pod 可以定义共享存储卷(Volume):
-
所有容器可挂载同一 Volume
-
可用于数据持久化,容器重启数据不丢失
5. Pod 的存在意义(总结)
-
每个 Pod 都有一个“基础容器”(Pause)负责网络与存储环境
-
应用容器运行在同一命名空间,共享资源
-
Pod 是 Kubernetes 抽象与调度的最小单位
6. Pod 的典型使用场景
-
单一进程应用:运行一个独立的容器(如 Nginx、Redis)
-
多进程协作应用:Sidecar 模式(如主应用 + 日志采集器)
7. Pod 的类型
| 类型 | 描述 |
|---|---|
| 自主式 Pod | 由用户直接创建,不具备自愈能力。节点宕机后不会自动恢复。 |
| 控制器管理的 Pod | 由 Deployment、StatefulSet 等控制器管理,具备副本与重建机制。 |
8. Pod 容器的分类
8.1 基础容器(Infrastructure Container)
负责整个 Pod 的网络与存储空间。 启动 Pod 时,Kubernetes 自动拉起该容器。
cat /opt/kubernetes/cfg/kubelet | grep pod-infra --pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0
8.2 初始化容器(Init Containers)
Init 容器在应用容器启动之前执行。 每个 Init 容器必须 成功退出 后,才能启动下一个。
🌱 启动流程
-
顺序执行多个 Init 容器
-
若任一 Init 容器失败,Pod 会根据
restartPolicy重试 -
所有 Init 容器完成后,主容器(MainContainer)才会启动
📦 Init 容器的作用
-
执行初始化任务,如环境检测、配置拉取
-
可以使用主容器中不存在的工具(如
sed,awk,dig) -
提高安全性:敏感操作放在 Init 容器完成
-
可以访问不同文件系统视图(如 Secrets)
-
能阻塞主容器启动直到前置条件满足
二、Init 容器实战与 Pod 镜像策略
1. Init 容器实战案例
下面通过一个示例演示 Init 容器的工作机制。
apiVersion: v1 kind: Pod metadata:name: myapp-podlabels:app: myapp spec:containers:- name: myapp-containerimage: busybox:1.28command: ['sh', '-c', 'echo The app is running! && sleep 3600']initContainers:- name: init-myserviceimage: busybox:1.28command: ['sh', '-c', 'until nslookup myservice; do echo waiting for myservice; sleep 2; done;']- name: init-mydbimage: busybox:1.28command: ['sh', '-c', 'until nslookup mydb; do echo waiting for mydb; sleep 2; done;']
🧠 解析:
-
Pod 中定义了 两个 Init 容器:
init-myservice和init-mydb -
只有当这两个容器都成功执行完毕后,主容器
myapp-container才会启动
🔧 配合 Service 测试
# myservice.yaml apiVersion: v1 kind: Service metadata:name: myservice spec:ports:- protocol: TCPport: 80targetPort: 9376 # mydb.yaml apiVersion: v1 kind: Service metadata:name: mydb spec:ports:- protocol: TCPport: 80targetPort: 9377
部署命令:
kubectl create -f myservice.yaml kubectl create -f mydb.yaml kubectl apply -f myapp-pod.yaml kubectl describe pod myapp-pod
查看 Init 容器日志:
kubectl logs myapp-pod -c init-myservice
🧩 结论:
-
Init 容器确保主容器只在依赖资源可用后启动
-
若任何 Init 容器失败,Pod 会反复重试直到成功
2. Pod 的镜像拉取策略(imagePullPolicy)
在 Pod 中,每个容器都需要镜像启动。 镜像拉取策略决定 Kubernetes 何时拉取镜像。
🧭 策略类型:
| 策略 | 说明 |
|---|---|
| IfNotPresent | 默认值。若本地已存在镜像,则不会重新拉取。 |
| Always | 每次启动 Pod 时都重新拉取最新镜像。 |
| Never | 永不拉取镜像,只使用本地镜像。 |
示例:
imagePullPolicy: Always
🧪 实践案例:镜像拉取策略
# pod1.yaml apiVersion: v1 kind: Pod metadata:name: pod-test1 spec:containers:- name: nginximage: nginximagePullPolicy: Alwayscommand: [ "echo", "SUCCESS" ]
部署后查看状态:
kubectl create -f pod1.yaml kubectl get pods -o wide
结果:
pod-test1 0/1 CrashLoopBackOff 4 3m33s
💡 原因:echo 执行后容器立即退出,Pod 会根据 restartPolicy 重启。
修改 Pod:
apiVersion: v1 kind: Pod metadata:name: pod-test1 spec:containers:- name: nginximage: nginx:1.14 # 修改版本imagePullPolicy: Always
重新部署:
kubectl delete -f pod1.yaml kubectl apply -f pod1.yaml kubectl get pods -o wide
验证版本:
curl -I http://10.244.2.24 # HTTP/1.1 200 OK # Server: nginx/1.14.2
3. Pod 的重启策略(restartPolicy)
Pod 的重启策略定义容器退出后的行为。 有三种取值:
| 策略 | 行为说明 |
|---|---|
| Always | 无论退出状态如何都重启(默认)。 |
| OnFailure | 仅当退出码非 0 时重启。 |
| Never | 容器退出后不重启。 |
示例:
restartPolicy: Always
🧩 案例演示
# pod3.yaml apiVersion: v1 kind: Pod metadata:name: foo spec:containers:- name: busyboximage: busyboxargs:- /bin/sh- -c- sleep 30; exit 3
执行:
kubectl apply -f pod3.yaml kubectl get pods
容器每 30 秒退出一次,状态显示 RESTARTS +1。
修改重启策略为 Never:
apiVersion: v1 kind: Pod metadata:name: foo spec:containers:- name: busyboximage: busyboxargs:- /bin/sh- -c- sleep 30; exit 3restartPolicy: Never
重新部署:
kubectl apply -f pod3.yaml kubectl get pods -w
📘 观察:
-
当策略为
Never时,容器退出后不会重启 -
当策略为
Always时,容器会循环重启
⚠️ 注意:Kubernetes 不支持直接重启 Pod,只能删除后重建。
💡 小结
-
Always用于长期运行服务(如 Nginx、Tomcat) -
OnFailure适合批处理任务(如 CronJob) -
Never适合一次性任务或调试场景
三、Pod 的进阶 —— 资源限制与调度机制
1. 为什么需要资源限制?
在 Kubernetes 中,节点资源是有限的(CPU、内存等)。 为了防止某些容器无限占用资源,Pod 的每个容器都可以设置资源请求(requests)与限制(limits):
-
Requests(请求值):容器启动时,调度器用于选择合适节点的依据。 👉 表示容器运行所需的最少资源。
-
Limits(限制值):容器运行时可使用的最大资源量。 👉 超过限制时,Kubernetes 会进行限制或强制终止。
2. 资源配置字段
Kubernetes 在 Pod YAML 中通过以下字段定义资源请求与限制:
spec.containers[].resources.requests.cpu # CPU 请求值 spec.containers[].resources.requests.memory # 内存请求值 spec.containers[].resources.limits.cpu # CPU 限制值 spec.containers[].resources.limits.memory # 内存限制值
3. 资源单位说明
🧠 CPU 单位
-
1CPU = 1 核(vCPU 或超线程) -
使用
m表示“毫核”:-
500m= 0.5 核心 -
100m= 0.1 核心 -
1= 1 个完整核心
-
支持小数形式,例如
0.25表示四分之一核心。
💾 内存单位
-
二进制单位(推荐):
-
1Ki = 1024 bytes -
1Mi = 1024 Ki -
1Gi = 1024 Mi
-
-
十进制单位(也可用):
-
1KB = 1000 bytes -
1MB = 1000 KB -
1GB = 1000 MB
-
⚠️ 注意:1GiB ≈ 1.07GB,操作系统通常使用二进制单位。
4. Pod 资源配置示例
示例 1:指定资源请求与限制
apiVersion: v1 kind: Pod metadata:name: frontend spec:containers:- name: appimage: images.my-company.example/app:v4env:- name: MYSQL_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi" # 请求最少 64Mi 内存cpu: "250m" # 请求 0.25 CPUlimits:memory: "128Mi" # 限制最大 128Mi 内存cpu: "500m" # 限制最大 0.5 CPU- name: log-aggregatorimage: images.my-company.example/log-aggregator:v6resources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"
✨ 分析:
-
每个容器请求资源:
0.25 CPU+64Mi -
每个容器限制资源:
0.5 CPU+128Mi -
整个 Pod 的总请求 =
0.5 CPU+128Mi -
总限制 =
1 CPU+256Mi
示例 2:不同容器资源配比
apiVersion: v1 kind: Pod metadata:name: frontend spec:containers:- name: webimage: nginxresources:requests:memory: "64Mi"cpu: "250m"limits:memory: "128Mi"cpu: "500m"- name: dbimage: mysqlenv:- name: MYSQL_ROOT_PASSWORDvalue: "abc123"resources:requests:memory: "512Mi"cpu: "0.5"limits:memory: "1Gi"cpu: "1"
💡 结果分析:
| 容器 | 请求 CPU | 限制 CPU | 请求内存 | 限制内存 |
|---|---|---|---|---|
| web | 0.25 | 0.5 | 64Mi | 128Mi |
| db | 0.5 | 1 | 512Mi | 1Gi |
-
总请求:
0.75 CPU / 576Mi -
总限制:
1.5 CPU / 1.128Gi
5. 调度与资源分配
当调度器选择节点时,它会根据 requests 判断节点是否有足够的可用资源。
示例命令:
kubectl apply -f pod2.yaml kubectl describe pod frontend kubectl describe nodes node02
输出结果可查看:
-
当前节点的 CPU/内存总量
-
已分配给 Pod 的请求值与限制值
🧩 实际案例输出:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits default frontend 500m (25%) 1 (50%) 128Mi (3%) 256Mi (6%) kube-system flannel 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%)
6. Kubernetes 的资源分配逻辑总结
-
Requests 用于调度决策(影响放在哪个节点)。
-
Limits 用于运行时约束(防止过度占用资源)。
-
若未指定
requests,则自动与limits相同。 -
Pod 中多个容器的资源值会累加计算节点总资源占用。
四、Pod 健康检查机制(Probe)详解与实战
1. 什么是探针(Probe)
探针(Probe) 是由 kubelet 周期性地对容器执行的诊断操作, 用于检测容器的运行健康状态与服务可用性。
📘 探针能帮助 Kubernetes 判断容器是否应被重启、移除或是否可对外提供服务。
2. 三种探针类型
| 探针类型 | 作用 | 失败后行为 |
|---|---|---|
| livenessProbe | 检查容器是否处于运行状态。 | 失败 → kubelet 杀死容器并按重启策略处理。 |
| readinessProbe | 检查容器是否准备好接受请求。 | 失败 → Pod IP 从对应的 Service Endpoint 移除。 |
| startupProbe | 检查容器内应用是否启动完成。 | 失败 → kubelet 杀死容器并重启。 |
💡 若未配置探针,Kubernetes 默认认为容器始终存活(Success 状态)。
3. 探针支持的三种检测方式
| 检测方式 | 说明 |
|---|---|
| exec | 在容器内执行命令,返回码为 0 表示成功。 |
| tcpSocket | 连接容器指定端口,成功建立 TCP 连接即为健康。 |
| httpGet | 对容器执行 HTTP 请求,返回 2xx~3xx 状态码表示健康。 |
4. 探针的三种检测结果
| 状态 | 说明 |
|---|---|
| Success | 检测通过。 |
| Failure | 检测失败。 |
| Unknown | 检测异常,不做处理。 |
5. exec 探针实战
示例:使用 exec 命令检测文件存在性
apiVersion: v1 kind: Pod metadata:name: liveness-execnamespace: default spec:containers:- name: liveness-exec-containerimage: busyboximagePullPolicy: IfNotPresentcommand: ["/bin/sh", "-c", "touch /tmp/live ; sleep 30; rm -rf /tmp/live; sleep 3600"]livenessProbe:exec:command: ["test", "-e", "/tmp/live"]initialDelaySeconds: 1periodSeconds: 3
部署与测试:
kubectl create -f exec.yaml kubectl get pods -w kubectl describe pod liveness-exec
事件输出示例:
Warning Unhealthy Liveness probe failed: Normal Killing Container liveness-exec-container failed liveness probe, will be restarted

🧩 说明:
-
容器启动 1 秒后开始探测,每 3 秒检测一次
/tmp/live文件是否存在。 -
30 秒后文件被删除,探针失败 → kubelet 杀死容器 → 自动重启。
6. httpGet 探针实战
官方示例
apiVersion: v1 kind: Pod metadata:labels:test: livenessname: liveness-http spec:containers:- name: livenessimage: k8s.gcr.io/livenessargs:- /serverlivenessProbe:httpGet:path: /healthzport: 8080httpHeaders:- name: Custom-Headervalue: AwesomeinitialDelaySeconds: 3periodSeconds: 3
💡 逻辑说明:
-
启动后 3 秒执行首次探测
-
每 3 秒访问一次
http://<PodIP>:8080/healthz -
HTTP 状态码 200~399 视为健康,否则判为失败并重启容器
案例:检测自定义 Web 服务
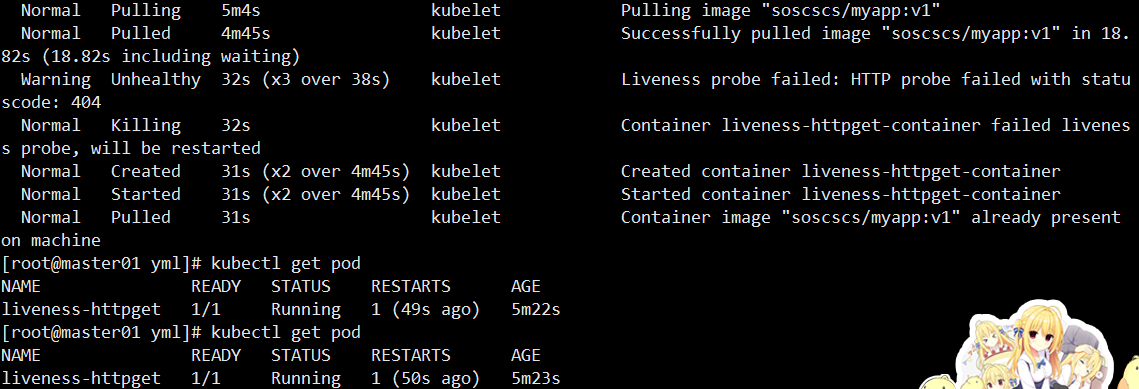
apiVersion: v1 kind: Pod metadata:name: liveness-httpgetnamespace: default spec:containers:- name: liveness-httpget-containerimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80livenessProbe:httpGet:port: httppath: /index.htmlinitialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
运行后执行:
kubectl create -f httpget.yaml kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html kubectl get pods -w
📘 结果:
liveness-httpget 1/1 Running 1 2m44s
因文件删除导致
/index.html访问失败,触发探针 → 重启容器。
7. tcpSocket 探针实战
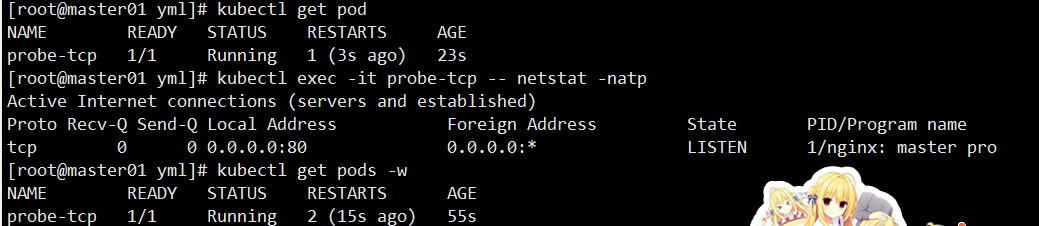
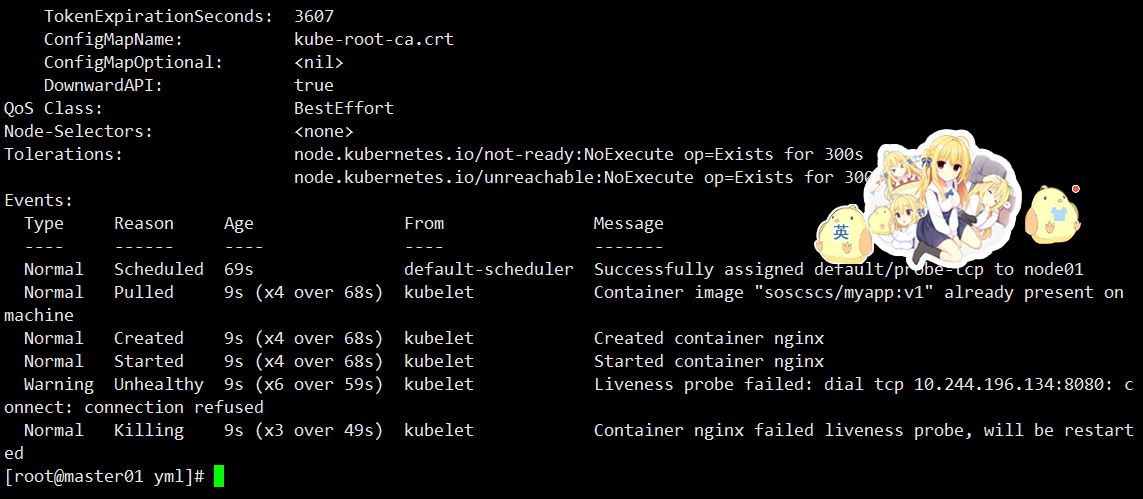
apiVersion: v1 kind: Pod metadata:name: probe-tcp spec:containers:- name: nginximage: soscscs/myapp:v1livenessProbe:initialDelaySeconds: 5timeoutSeconds: 1tcpSocket:port: 8080periodSeconds: 10failureThreshold: 2
验证:
kubectl create -f tcpsocket.yaml kubectl exec -it probe-tcp -- netstat -natp kubectl get pods -w
若容器端口无监听,则在连续 2 次探测失败后被重启。
8. readinessProbe —— 就绪检测
readinessProbe 用于检测 Pod 是否准备好对外提供服务。
当探针失败时,Kubernetes 会从 Service 的 endpoints 列表中移除该 Pod IP。
案例:readiness + liveness 同时存在
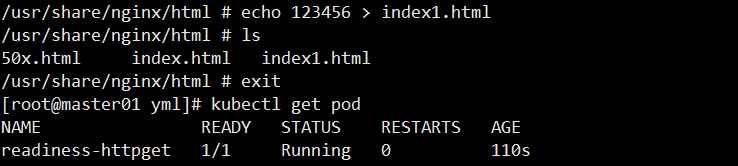
apiVersion: v1 kind: Pod metadata:name: readiness-httpgetnamespace: default spec:containers:- name: readiness-httpget-containerimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index1.htmlinitialDelaySeconds: 1periodSeconds: 3livenessProbe:httpGet:port: httppath: /index.htmlinitialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
测试:
kubectl create -f readiness-httpget.yaml kubectl exec -it readiness-httpget sh cd /usr/share/nginx/html/ echo 123 > index1.html kubectl get pods
删除探测文件:
kubectl exec -it readiness-httpget -- rm -rf /usr/share/nginx/html/index.html kubectl get pods -w
📘 输出变化:
readiness-httpget 1/1 Running 0 4m10s readiness-httpget 0/1 Running 1 4m15s
liveness 探针失败导致重启,而 readiness 探针控制 Pod 是否参与流量分发。

9. readinessProbe 服务联动案例
apiVersion: v1 kind: Pod metadata:name: myapp1labels:app: myapp spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10 --- apiVersion: v1 kind: Pod metadata:name: myapp2labels:app: myapp spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10 --- apiVersion: v1 kind: Pod metadata:name: myapp3labels:app: myapp spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10 --- apiVersion: v1 kind: Service metadata:name: myapp spec:selector:app: myapptype: ClusterIPports:- name: httpport: 80targetPort: 80
当 readiness 检测失败时:
kubectl get pods,svc,endpoints -o wide
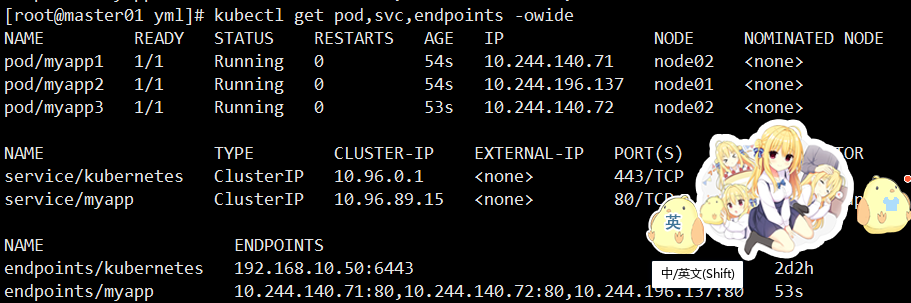
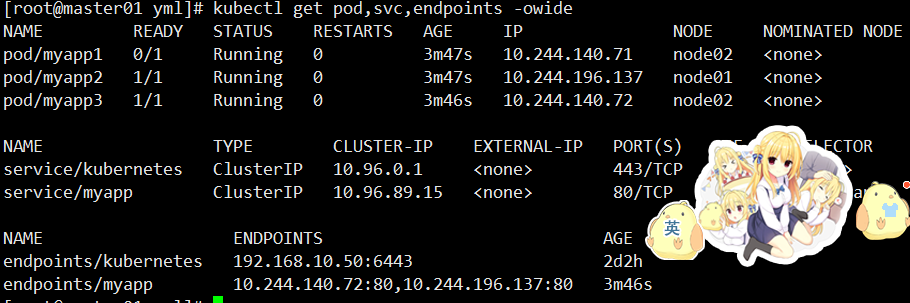
可观察到该 Pod 从 endpoints/myapp 中消失,表示不再接收流量。
10. startupProbe —— 启动检测
适用于 启动时间较长 的应用(如 Java 服务)。
配置示例:
startupProbe:httpGet:path: /healthzport: 8080failureThreshold: 30periodSeconds: 10
解释:
-
每 10 秒检测一次,失败 30 次才重启(最长容忍 300 秒)
-
startupProbe 成功后,其他探针才开始生效
11. 探针常用参数详解
| 参数 | 说明 | 默认值 |
|---|---|---|
initialDelaySeconds | 容器启动后首次探测前的等待时间 | 0 |
periodSeconds | 探测间隔时间 | 10 |
timeoutSeconds | 每次探测的超时时间 | 1 |
failureThreshold | 探测失败最大次数 | 3 |
successThreshold | 探测成功最少次数 | 1 |
12. 小结
-
livenessProbe → 控制容器重启
-
readinessProbe → 控制流量路由
-
startupProbe → 控制应用启动阶段健康检查
-
三者可同时存在,但执行顺序为:
startupProbe → livenessProbe / readinessProbe
五、Pod 生命周期、状态详解与总结
1. Pod 生命周期(Lifecycle)
Pod 生命周期描述了容器从启动到终止的完整过程。 Kubernetes 提供了多个机制来在容器生命周期的不同阶段执行操作。
主要包括:
-
Init 容器(InitContainer)
-
PostStart 与 PreStop 钩子(Lifecycle Hooks)
-
探针(Probe)检测机制
-
Pod 状态(Phase)管理
2. 容器生命周期钩子(Lifecycle Hooks)
容器生命周期钩子允许在容器启动和停止时执行自定义命令或脚本。 主要包含两个事件:
| 钩子事件 | 执行时机 | 说明 |
|---|---|---|
| postStart | 容器启动后立即执行 | 可用于初始化任务 |
| preStop | 容器终止前执行 | 可用于优雅关闭、清理资源 |
📦 实例:postStart 与 preStop
apiVersion: v1 kind: Pod metadata:name: lifecycle-demo spec:containers:- name: lifecycle-demo-containerimage: soscscs/myapp:v1lifecycle:postStart:exec:command: ["/bin/sh", "-c", "echo Hello from postStart >> /var/log/nginx/message"]preStop:exec:command: ["/bin/sh", "-c", "echo Goodbye from preStop >> /var/log/nginx/message"]volumeMounts:- name: message-logmountPath: /var/log/nginx/initContainers:- name: init-myserviceimage: soscscs/myapp:v1command: ["/bin/sh", "-c", "echo 'Hello from InitContainer' >> /var/log/nginx/message"]volumeMounts:- name: message-logmountPath: /var/log/nginx/volumes:- name: message-loghostPath:path: /data/volumes/nginx/log/type: DirectoryOrCreate

![]()

🔧 测试命令
kubectl create -f post.yaml kubectl get pods -o wide kubectl exec -it lifecycle-demo -- cat /var/log/nginx/message
示例输出:
Hello from InitContainer Hello from postStart
删除 Pod:
kubectl delete pod lifecycle-demo cat /data/volumes/nginx/log/message
输出结果:
Hello from InitContainer Hello from postStart Goodbye from preStop
🧠 结论:
-
InitContainer→ 先执行初始化任务 -
postStart→ 容器启动后立即执行 -
preStop→ 容器终止前执行(可用于优雅关闭)
3. Pod 状态(Phase)
Pod 的整体状态由 .status.phase 字段标识。
| 状态 | 含义 |
|---|---|
| Pending | Pod 已创建但容器尚未启动(如镜像下载中)。 |
| Running | 至少有一个容器在运行或启动/重启中。 |
| Succeeded | 所有容器都已正常终止且不会重启。 |
| Failed | 所有容器终止,至少一个非正常退出。 |
| Unknown | 无法获取状态(多因节点通信异常)。 |
✅ 最常见状态为 Pending → Running,代表 Pod 正常启动。
4. 容器状态(Container State)
容器状态与 Pod 状态不同,是更细粒度的运行阶段。 主要分为三种:
| 状态 | 含义 |
|---|---|
| Waiting | 容器已创建但尚未运行(可能在下载镜像或等待依赖)。 |
| Running | 容器正在运行。 |
| Terminated | 容器已终止(成功或失败)。 |
📊 状态流转示意
[Waiting] → [Running] → [Terminated]↘︎ (错误) ↙︎[CrashLoopBackOff]
💡 CrashLoopBackOff 表示容器反复启动失败,Kubernetes 在逐渐延长重试间隔。
5. Pod 状态诊断命令
查看 Pod 详细状态:
kubectl describe pod <pod-name>
查看 Pod 所有容器的日志:
kubectl logs <pod-name> --all-containers=true
持续监控状态变化:
kubectl get pods -w
结合命名空间查看系统 Pod:
kubectl get pods -n kube-system
6. 实战案例总结
| 主题 | 功能 | 命令/配置 |
|---|---|---|
| Init 容器 | 初始化任务、依赖检测 | initContainers: |
| 镜像拉取策略 | 控制镜像更新方式 | imagePullPolicy: |
| 重启策略 | 控制容器退出行为 | restartPolicy: |
| 资源限制 | 管控 CPU/内存使用 | resources: |
| 探针 | 健康检查与服务可用性 | livenessProbe, readinessProbe |
| 生命周期钩子 | 容器启动与退出事件处理 | lifecycle: |
| Pod 状态 | 生命周期阶段监控 | kubectl describe/get pods |
7. Kubernetes 调试 Pod 常用命令
# 查看当前命名空间所有 Pod kubectl get pods # 查看 Pod 详细信息 kubectl describe pod mypod # 查看 Pod 内特定容器日志 kubectl logs mypod -c mycontainer # 实时查看日志 kubectl logs -f mypod # 进入容器交互终端 kubectl exec -it mypod -- /bin/sh # 删除并重建 Pod kubectl delete pod mypod && kubectl apply -f mypod.yaml
总结
通过本文,我们完整地从 Pod 的基础概念 到 高级应用场景,完成了一次系统的学习旅程。
🔹 你现在应该能够清晰回答以下问题:
-
为什么 Kubernetes 以 Pod 作为最小调度单元?
-
Pause 容器、Init 容器和主容器(MainContainer)各自的作用是什么?
-
镜像拉取策略与重启策略对 Pod 稳定性有何影响?
-
如何通过探针与生命周期钩子保障 Pod 的高可用性?
-
Requests 与 Limits 如何影响调度器与节点资源分配?
🔹 你还掌握了实战操作:
-
使用 YAML 创建多容器 Pod
-
编写 Init 容器完成依赖检测
-
定义探针与钩子监控容器健康
-
管控 CPU / 内存资源分配
一句话总结:
Pod 是容器编排的“最小生命体”,理解 Pod 的生命周期、资源管理与健康检测机制,就相当于掌握了 Kubernetes 的核心运行逻辑。
补充:httpGet 与 tcpSocket 的区别与使用总结
在 Kubernetes 中,探针(Probe)用于检测容器是否健康(livenessProbe)、是否可对外提供服务(readinessProbe)、以及是否完成启动(startupProbe)。 常见的探针方式有两种:
-
httpGet -
tcpSocket
虽然两者都能检测容器端口的可用性,但工作层次和适用场景完全不同。
🧩httpGet 探针
✅ 定义
通过 HTTP 协议 访问容器端口上的某个路径,检查返回的 HTTP 状态码是否健康(2xx 或 3xx)。
✅ 示例
livenessProbe:httpGet:path: /healthzport: 8080initialDelaySeconds: 5periodSeconds: 10
✅ 工作原理
Kubelet 发起一个 HTTP 请求:
GET http://<PodIP>:8080/healthz
-
返回
2xx或3xx→ 探针成功 ✅ -
返回
4xx/5xx或连接超时 → 探针失败 ❌
✅ 适用场景
-
Web 应用或 HTTP API 服务(如 Nginx、Spring Boot、Tomcat、Flask)
-
能检测服务在应用层是否真正工作正常
-
可以通过
path精确检测具体接口逻辑
🔌tcpSocket 探针
✅ 定义
通过 TCP 协议 尝试连接指定端口,只判断能否建立连接。
✅ 示例
livenessProbe:tcpSocket:port: 3306initialDelaySeconds: 5periodSeconds: 10
✅ 工作原理
Kubelet 尝试建立 TCP 连接:
<PodIP>:3306
-
连接成功 → 探针成功 ✅
-
连接超时 / 拒绝 → 探针失败 ❌
✅ 适用场景
-
非 HTTP 协议的服务,如:
-
MySQL(3306)
-
Redis(6379)
-
RabbitMQ(5672)
-
-
仅需检测端口是否在监听,不关注应用层逻辑
⚖️ 两者核心区别
| 对比项 | httpGet | tcpSocket |
|---|---|---|
| 协议层 | HTTP (第7层) | TCP (第4层) |
| 检查内容 | HTTP 响应状态 | TCP 端口连通性 |
| 检测粒度 | 应用层(可检测业务逻辑) | 网络层(只检测端口) |
| 优点 | 能判断服务是否真正可用 | 简单高效、适合非HTTP服务 |
| 缺点 | 需HTTP接口支持 | 容易误判“端口通但服务挂” |
| 典型场景 | Web服务 | 数据库、缓存等非HTTP服务 |
⚠️常见误区:Nginx 用 tcpSocket 探针的陷阱
❌ 错误配置示例
livenessProbe:tcpSocket:port: 80
问题说明
-
Nginx 主进程还在监听 80 端口;
-
但配置错误、upstream 不可达或 worker 死掉;
-
端口仍能建立 TCP 连接;
-
tcpSocket探针判定“健康”,但 HTTP 实际不可访问; -
Kubernetes 不会重启容器,造成误判。
✅ 正确配置方式
livenessProbe:httpGet:path: /port: 80initialDelaySeconds: 5periodSeconds: 10
👉 这样 kubelet 会真正发起 HTTP 请求, 若 Nginx 无响应或返回非 2xx/3xx 状态码,就会自动判定异常并重启容器。
🧪实际案例对比
| 场景 | tcpSocket 探针结果 | httpGet 探针结果 |
|---|---|---|
| Nginx 正常运行 | ✅ 正常 | ✅ 正常 |
| Nginx 配置错误、HTTP 返回 500 | ✅ 正常(误判) | ❌ 异常 |
| Nginx 进程挂掉,端口关闭 | ❌ 异常 | ❌ 异常 |
🧠总结与建议
| 服务类型 | 推荐探针方式 | 理由 |
|---|---|---|
| Web 服务 (Nginx、Spring Boot、Tomcat) | httpGet | 能检查应用层健康状态 |
| 非 Web 服务 (MySQL、Redis、MQ) | tcpSocket | 无 HTTP 接口,仅检测端口 |
| 临时测试服务 | tcpSocket | 简单快速 |
| 严格健康检测需求 | httpGet | 能避免误判 |
✅ 一句话总结:
tcpSocket只能告诉你“端口开着”,httpGet才能告诉你“服务真的能用”