RNN代码实战专项
前言
本文重点在,如何跑通一个简单的RNN模型,精度不在考虑范围内
总体思路
- 数据预处理
- 词嵌入
- 构建Dataset,DataLoader
- 构建RNN模型
- 训练
由于看了李沐的动手学深度学习,但发现里面的都都d2l数据集貌似以及被删除了,因此决定设置一个更简单的数据集进行调整,部分参考的知乎教程:(30 封私信 / 83 条消息) 动手学深度学习8.6. 循环神经网络的简洁实现-笔记&练习(PyTorch) - 知乎
同时,在这过程中涉及到一些名词的概念,我都会在遇到时加以解释
数据预处理
首先导入需要的包
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
import time
import math我本次用三个句子,如下
# ---------------- 1. 原始句子 -----------------
sents = ['I love AI', 'Deep learning is fun', 'Hello world']# ---------------- 2. 快速分词 + 建词表 ----------
word_set = set()
for sent in sents:word_set.update(sent.lower().split())
vocab = ['<pad>'] + sorted(word_set) # 把 pad 放 0 索引
#stoi:string_to_token
string_to_index = {w: i for i, w in enumerate(vocab)}
print('词表:', vocab)
print('stoi:', string_to_index)
我们可以看到输出
词表: ['<pad>', 'ai', 'deep', 'fun', 'hello', 'i', 'is', 'learning', 'love', 'world']
stoi: {'<pad>': 0, 'ai': 1, 'deep': 2, 'fun': 3, 'hello': 4, 'i': 5, 'is': 6, 'learning': 7, 'love': 8, 'world': 9}
也就是我们对每一个词都进行了索引编码,然后运行下列代码
from torch.nn.utils.rnn import pad_sequence
# ---------------- 3. 转索引序列 ---------------
indexed = [torch.tensor([string_to_index[w] for w in sent.lower().split()]) for sent in sents]
print('原始索引序列:', indexed) 我们会得到
原始索引序列: [tensor([5, 8, 1]), tensor([2, 7, 6, 3]), tensor([4, 9])]
发现,I的索引是5,love的索引是8,ai的索引是1,所以,I love AI,变成了,5 8 1
接下来是需要理解的地方,pad_sequence
如下面这一张表格,我们发现三个句子是不定长的,括号里面的是词对应的索引,pad_sequence的作用就是,将所有句子补充到同样长度,例如我们将不足的部分添空,多出的部分补0
本例中,我要将所有句子补充到五个单词的长度,不足的部分添pad
| I(5) | love(8) | AI(1) | pad(0) | pad(0) |
| Deep(2) | Learning(7) | is(6) | fun(3) | pad(0) |
| Hello(4) | World(9) | pad(0) | pad(0) | pad(0) |
代码如下
# 手动 pad 到相同长度 5(batch_first=True 要求)
padded = pad_sequence(indexed, batch_first=True, padding_value=0)
if padded.size(1) < 5:pad_cols = 5 - padded.size(1)padded = torch.cat([padded, torch.zeros(padded.size(0), pad_cols, dtype=torch.long)], dim=1)
print('padded 输入 (batch, seq):', padded.shape) # -> (3, 5)输出
padded 输入 (batch, seq): torch.Size([3, 5])
3是什么意思呢?相当于我们上面的将一维向量(一共句子),转成了二维张量(就是上面的词表,3行5列,每一行都是一共句子),这一个词表作为我们后续处理的基础数据
词嵌入
我们将上面一个表格变为索引(其实这才是padd的值)
| 5 | 8 | 1 | 0 | 0 |
| 2 | 7 | 6 | 3 | 0 |
| 4 | 9 | 0 | 0 | 0 |
然后我们需要用上一个类,nn.Embedding,下面是它初始化需要的参数
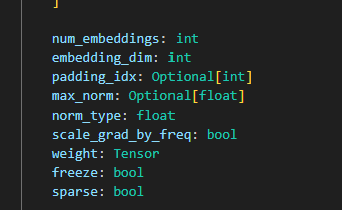
这里面有两个参数特别要注意,这两个参数也是必要的
num_embedding:表示一共有多少种不同的编号,例如上一个padd表格,我们一共有15个值,但是一共只要10种不同的编号,6个0都是同一个编号,我的理解是:编号的个数反映了有多少个不同的词
embedding_dim:对于这一个概念,我感觉举一个例子比较容易理解
我们拿上面的 "I love AI",来说,它的编码是
| 5 | 8 | 1 | 0 | 0 |
如果embedding_dim=2,那么每一个词都会被嵌入到一个向量中,这一个向量有两个维度,如下图所示,所以pad的整体维度就会变成 [3,5,2],2表示每一个词都是有一个二维向量,同理
[3,5,10],10表示每一个词都是一个10维向量
| [0.115,0.222] | [0.256,0.444] | [0.775,0.145] | [0.111,0.333] | [0.111,0.121] |
构建Dataset,Dataloader
这里就没什么要点,按部就班
# 5. 构造 Dataset / DataLoader
class TextDataset(torch.utils.data.Dataset):def __init__(self, padded):self.data = padded # (B, T)def __len__(self):return self.data.size(0)def __getitem__(self, idx):# 语言模型任务:用当前 token 预测下一个sent = self.data[idx] # (T,)return sent[:-1], sent[1:] # X, yloader = torch.utils.data.DataLoader(TextDataset(padded),batch_size=3,shuffle=True)构建RNN模型
这里有一个要点,就是我们需要使用到
nn.RNN这一个类,下面是它初始化需要的参数
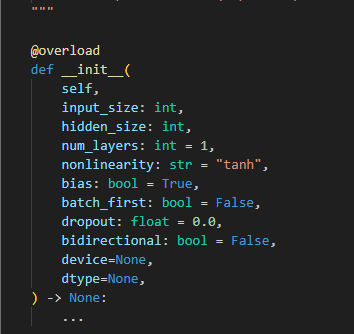
有几个参数是必要的,大家可以首先参考这一个教程
(30 封私信 / 83 条消息) PyTorch RNN&LSTM入门 - 知乎
我的理解
input_size:将的是我们RNN图(上一个教程所讲的)下方的Xi的输入维度
hidden_size:是我们输出的维度(RNN图垂直方向的输出)
num_layers:是我们从Xi到垂直方向的输出上,一共经过多少个Cell,也就是RNN图中的圆形或者小正方形部分
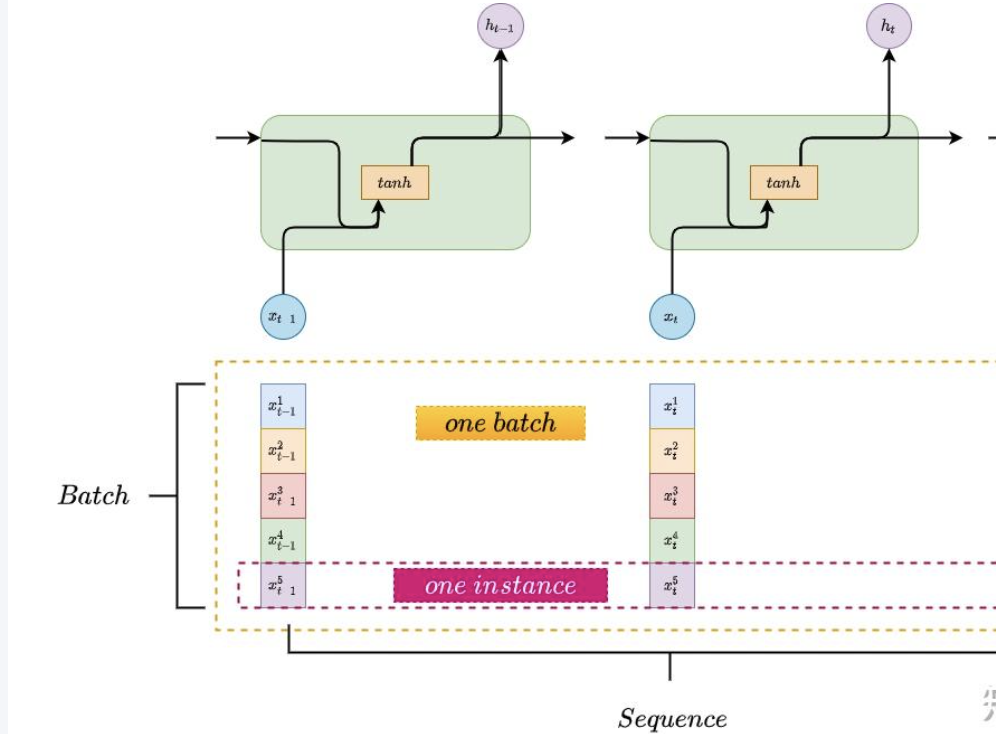
然后我们最开始还需要输入一共张量,作为水平方向起始输入,维度是(batch_size,sequence_len,input_size),然后我们要设定,batch_first=True
这里面有个batch_size,sequence_len可以参考上一个知乎教程中这一张图,我的理解是,batch_size:是输入张量的个数,类似我们输入的句子列表
squence_len:是每个张量的分量,类似我们输入的列表中,总共有多少个句子
Input_size:和上面含义一样,就是每一句话的维度
最后在输出上,加上Linear层,最终代码如下
class RNNModel(nn.Module):def __init__(self, input_size, embed_size, hidden_size, num_layers=1,bidirectional=False):super().__init__()self.embedding = nn.Embedding(input_size, embed_size) # <-- 加一行self.rnn = nn.RNN(embed_size, hidden_size,num_layers, batch_first=False)self.linear = nn.Linear(hidden_size, input_size)self.num_directions = 2 if bidirectional else 1 # <-- 补上self.num_hiddens=hidden_sizeself.num_layers=num_layersself.embed_size=embed_sizedef forward(self, inputs, state):# inputs: (B, T) 但在训练循环里已经 .T 过了,所以这里是 (T, B)X = self.embedding(inputs.long()) # (T, B, embed_size)Y, state = self.rnn(X, state) # (T, B, hidden_size)output = self.linear(Y.reshape(-1, Y.size(-1))) # (T*B, vocab_size)return output, state训练
这里直接参考Kimi的代码,经过调试可以运行的
def train_rnn_lm(net, train_loader, vocab, lr, num_epochs, device):net.to(device)loss = nn.CrossEntropyLoss()optimizer = torch.optim.SGD(net.parameters(), lr=lr)for epoch in range(num_epochs):l_sum, n = 0., 0start = time.time()net.train()for X, y in train_loader: # X:(B,T) y:(B*T,)X, y = X.to(device), y.to(device)optimizer.zero_grad()# ---- 前向 ----logits, state = net(X, None) # logits:(B*T, V)# ---- 标签拉平 ----y_flat = y.T.reshape(-1) # 先转置再拉平,与 logits 对齐l = loss(logits, y_flat)l.backward()torch.nn.utils.clip_grad_norm_(net.parameters(), max_norm=1.0)#控制梯度爆炸optimizer.step()l_sum += l.item() * y_flat.numel()n += y_flat.numel()ppl = math.exp(l_sum / n)print(f'epoch {epoch+1:3d} | perplexity {ppl:8.3f} | 'f'time {time.time()-start:.1f}s')print(f'最终困惑度 {ppl:.1f}')#调用过程
device = d2l.torch.try_gpu()
import time,math
num_epochs, lr = 100, 1e-3
train_rnn_lm(net_rnn, loader, vocab, lr, num_epochs, device)
这里面有一个困惑度的含义,通俗易懂的讲,就是
困惑度,值越小 ⇒ 模型越“不困惑”,预测越准;
值越大 ⇒ 模型越“迷茫”,预测越差**
“平均有多少个等可能选项”供模型选择。
总结
你可以如何使用
你可以就只查看这代码和博文,来理解RNN的训练过程,也可以把这些代码复制到你自己的电脑上,并经过一定的调试,成功跑通后再来理解一下RNN模型的内容,
这里面所有代码都是经过我自己调试成功的,可能会有部分细节忘记复制过来了,但大部分的内容都在,本次是我第一次比较系统的理解RNN,如有遗漏,或者错误,欢迎大家指出!