Leetcode 26
1 题目
LCR 023. 相交链表
给定两个单链表的头节点 headA 和 headB ,请找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。
图示两个链表在节点 c1 开始相交:
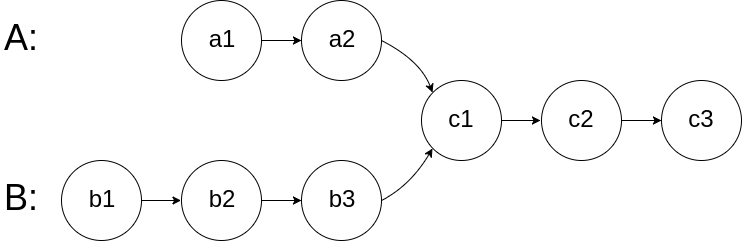
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
示例 1:
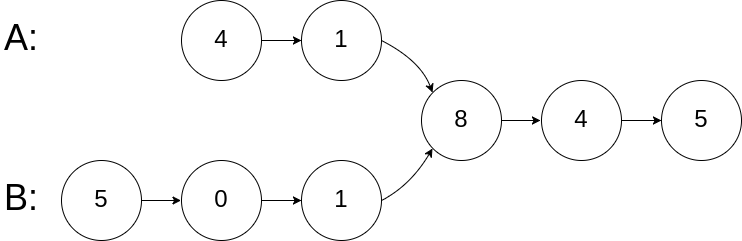
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 输出:Intersected at '8' 解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。 在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例 2:
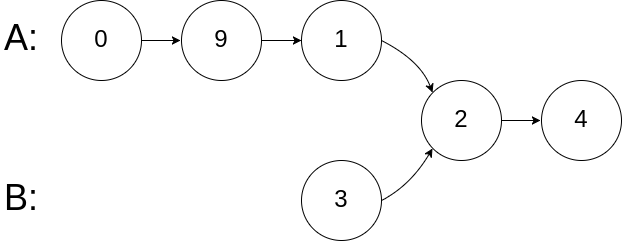
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 输出:Intersected at '2' 解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。 从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。 在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
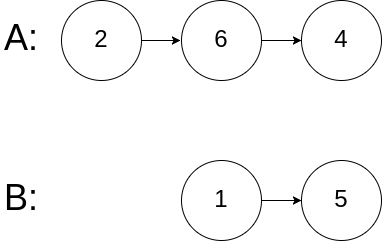
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 输出:null 解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。 由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n0 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA + 1] == listB[skipB + 1]
进阶:能否设计一个时间复杂度 O(n) 、仅用 O(1) 内存的解决方案
2 双指针解法
使用双指针的方法,可以将空间复杂度降至 O(1)。
只有当链表 headA 和 headB 都不为空时,两个链表才可能相交。【第一个循环条件】
因此首先判断链表 headA 和 headB 是否为空,如果其中至少有一个链表为空,则两个链表一定不相交,返回 null。
当链表 headA 和 headB 都不为空时,创建两个指针 pA 和 pB,初始时分别指向两个链表的头节点 headA 和 headB,然后将两个指针依次遍历两个链表的每个节点。具体做法如下:
每步操作需要同时更新指针 pA 和 pB。
如果指针 pA 不为空,则将指针 pA 移到下一个节点;如果指针 pB 不为空,则将指针 pB 移到下一个节点。
如果指针 pA 为空,则将指针 pA 移到链表 headB 的头节点;如果指针 pB 为空,则将指针 pB 移到链表 headA 的头节点。
当指针 pA 和 pB 指向同一个节点或者都为空时,返回它们指向的节点或者 null。
证明
下面提供双指针方法的正确性证明。考虑两种情况,第一种情况是两个链表相交,第二种情况是两个链表不相交。
情况一:两个链表相交
链表 headA 和 headB 的长度分别是 m 和 n。假设链表 headA 的不相交部分有 a 个节点,链表 headB 的不相交部分有 b 个节点,两个链表相交的部分有 c 个节点,则有 a+c=m,b+c=n。
如果 a=b,则两个指针会同时到达两个链表相交的节点,此时返回相交的节点;
如果 a,b不相等,则指针 pA 会遍历完链表 headA,指针 pB 会遍历完链表 headB,两个指针不会同时到达链表的尾节点,然后指针 pA 移到链表 headB 的头节点,指针 pB 移到链表 headA 的头节点,然后两个指针继续移动,在指针 pA 移动了 a+c+b 次、指针 pB 移动了 b+c+a 次之后,两个指针会同时到达两个链表相交的节点,该节点也是两个指针第一次同时指向的节点,此时返回相交的节点。
情况二:两个链表不相交
链表 headA 和 headB 的长度分别是 m 和 n。
如果 m=n,则两个指针会同时到达两个链表的尾节点,然后同时变成空值 null,此时返回 null;
如果 m,n不相等,则由于两个链表没有公共节点,两个指针也不会同时到达两个链表的尾节点,因此两个指针都会遍历完两个链表,在指针 pA 移动了 m+n 次、指针 pB 移动了 n+m 次之后,两个指针会同时变成空值 null,此时返回 null。
代码
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {if (headA == NULL || headB == NULL) {return NULL;}struct ListNode *pA = headA, *pB = headB;while (pA != pB) {pA = pA == NULL ? headB : pA->next;pB = pB == NULL ? headA : pB->next;}return pA;
}复杂度分析
时间复杂度:O(m+n),其中 m 和 n 是分别是链表 headA 和 headB 的长度。两个指针同时遍历两个链表,每个指针遍历两个链表各一次。
空间复杂度:O(1)。
3 寻找两个单链表的相交节点(核心代码)
这段代码是用于寻找两个单链表的相交节点,其中你提到的这两行代码是整个算法的核心,采用了一种非常巧妙的思路。
我们来详细解释这两行代码:
pA = pA == NULL ? headB : pA -> next ;
pB = pB == NULL ? headA : pB -> next ;
这两行代码的作用是让两个指针pA和pB分别遍历两个链表,当一个指针到达链表末尾(变为NULL)时,就将它重新指向另一个链表的头部,继续遍历。
具体逻辑:
- 对于
pA:如果pA当前是NULL(已经遍历完headA所在的链表),就把它指向headB(开始遍历另一个链表);否则,就让它移动到下一个节点pA->next - 对于
pB:如果pB当前是NULL(已经遍历完headB所在的链表),就把它指向headA;否则,就让它移动到下一个节点pB->next
这样做的巧妙之处在于:两个指针最终会同时到达相交节点(如果存在),或者同时到达NULL(如果不存在相交节点)。因为两个指针走过的总路程是相同的(都是两个链表的长度之和),所以它们一定会在某个时刻相遇。
举个例子:
- 假设链表 A 长度为 5,链表 B 长度为 3,且它们在第 3 个节点相交
pA会先走完 A 的 5 个节点,然后从 B 的头部开始走pB会先走完 B 的 3 个节点,然后从 A 的头部开始走- 最终它们会在第 3 个节点(相交点)相遇