【AI论文】CoDA:面向协作数据可视化的智能体系统
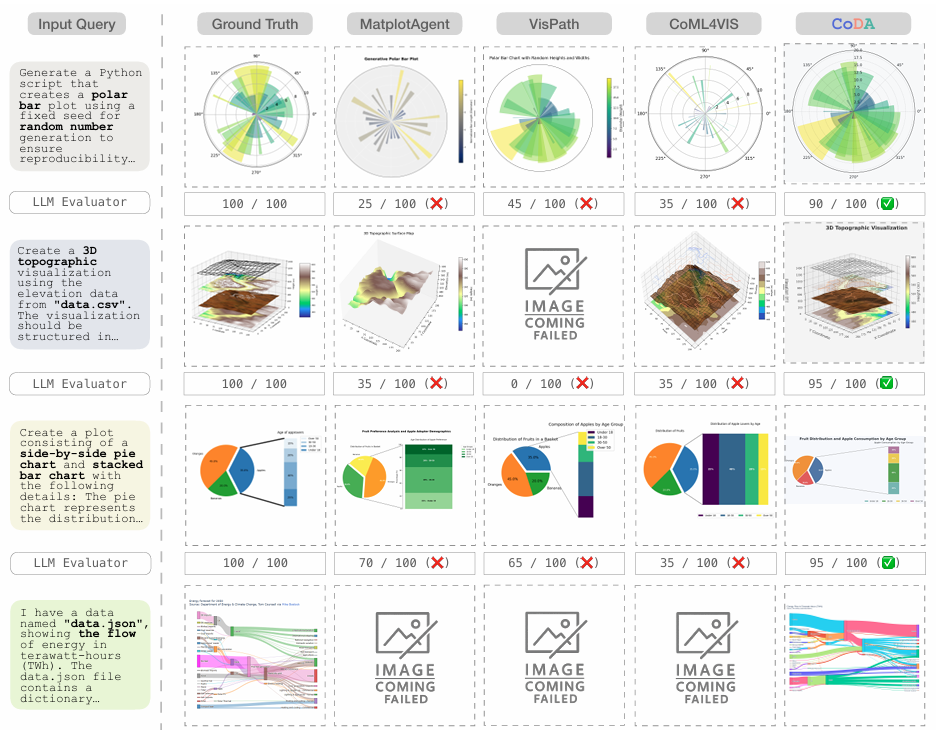
摘要:深度研究已彻底变革了数据分析领域,然而数据科学家仍需投入大量时间手动制作可视化图表,这凸显了通过自然语言查询实现强大自动化功能的迫切需求。然而,现有系统在处理包含多个文件的复杂数据集以及进行迭代优化时仍面临困难。现有的方法,包括简单的单智能体或多智能体系统,往往过度简化了任务,它们侧重于初始查询解析,却无法有效应对数据复杂性、代码错误或最终可视化质量等问题。在本文中,我们将这一挑战重新定义为协作式多智能体问题。我们推出了CoDA这一多智能体系统,该系统采用专门的大语言模型(LLM)智能体进行元数据分析、任务规划、代码生成和自我反思。我们对这一流程进行了规范化,展示了以元数据为中心的分析如何绕过令牌限制,以及以质量为导向的优化如何确保系统的鲁棒性。大量评估表明,CoDA在总体得分上取得了显著提升,性能优于竞争基准方法,最高提升幅度达41.5%。本研究表明,可视化自动化的未来不在于孤立的代码生成,而在于集成化、协作式的智能体工作流程。Huggingface链接:Paper page,论文链接:2510.03194
研究背景和目的
研究背景:
随着大数据时代的到来,数据可视化在商业智能、数据科学和决策制定中扮演着至关重要的角色。
然而,传统的手动创建可视化图表的过程耗时且繁琐,数据科学家和分析师往往需要将大量时间花费在数据准备和可视化任务上,而非专注于洞察生成。尽管近年来大型语言模型(LLMs)的发展为自动化这一流程提供了可能性,但现有的基于LLMs的可视化系统仍存在诸多局限性。例如,传统基于规则的系统难以处理自然语言查询和多样化的数据模式;而基于LLMs的方法虽然能够利用链式思考提示生成可视化,但常面临数据限制、幻觉和多源数据融合等问题。此外,多智能体框架虽然引入了协作系统来生成绘图代码,但缺乏对元数据的聚焦分析,导致在迭代编辑中表现不佳。
研究目的:
本研究旨在解决现有数据可视化自动化系统中的关键问题,提出一种名为CoDA(Collaborative Data-visualization Agents)的多智能体系统。
CoDA通过专门化的LLM智能体执行元数据分析、任务规划、代码生成和自我反思等任务,以实现复杂数据集和查询的高效、准确和美观的可视化。具体目标包括:
- 提高自动化水平:减少数据科学家在手动创建可视化图表上的时间投入,提高自动化程度。
- 增强系统鲁棒性:通过元数据聚焦分析和质量驱动的细化,提高系统处理复杂数据和查询的能力。
- 提升可视化质量:确保生成的可视化图表在准确性、清晰度和美观性方面达到高标准。
- 支持迭代优化:通过多智能体协作和自我反思机制,支持对可视化结果的迭代优化。
研究方法
为了实现上述研究目标,本研究采用了多智能体系统的设计方法,具体包括以下几个关键组件:
1. 智能体架构设计:
CoDA系统由多个专门化的LLM智能体组成,包括查询分析器(Query Analyzer)、数据处理器(Data Processor)、可视化映射器(VizMapping Agent)、搜索代理(Search Agent)、设计探索器(Design Explorer)、代码生成器(Code Generator)、调试代理(Debug Agent)和可视化评估器(Visual Evaluator)。
每个智能体负责特定的任务,并通过共享内存缓冲区进行通信和协作。
2. 查询分析与任务规划:
查询分析器负责解析自然语言查询,提取用户意图,并生成全局待办事项列表(global TODO list)。
数据处理器则提取数据文件的元数据摘要,识别数据特征和潜在的数据转换需求。可视化映射器将查询语义映射到具体的可视化类型和数据绑定上,确保可视化结果符合用户需求。
3. 代码生成与调试:
设计探索器生成内容与美学概念,优化颜色、布局等元素,并评估设计是否满足用户体验需求。
代码生成器根据设计规范和元数据信息合成可执行的Python代码。调试代理负责执行代码,诊断错误,并提供修复方案。
4. 自我反思与迭代优化:
可视化评估器从多个维度(清晰度、准确性、美观性、布局等)评估生成的可视化结果,并提供详细的反馈报告。
根据评估结果,系统通过迭代优化机制不断调整和改进可视化结果,直至达到满意的标准。
5. 实验设计与评估:
为了验证CoDA系统的有效性和优越性,本研究在多个基准测试集上进行了广泛的实验。
实验使用了MatplotBench和Qwen Code Interpreter等基准测试集,比较了CoDA与多个基线系统的性能。评估指标包括执行成功率(EPR)、可视化成功率(VSR)和总体得分(OS)。
研究结果
性能提升:
实验结果表明,CoDA系统在多个基准测试集上显著优于基线系统。
在MatplotBench和Qwen Code Interpreter基准测试集上,CoDA的总体得分(OS)分别提高了24.5%和41.5%。特别是在处理复杂查询和多样化数据模式时,CoDA展现出了更强的鲁棒性和适应性。
可视化质量:
CoDA生成的可视化图表在准确性、清晰度和美观性方面均达到了高标准。
通过元数据聚焦分析和质量驱动的细化机制,系统能够确保可视化结果紧密贴合用户需求和数据特征。此外,迭代优化机制进一步提升了可视化质量,使其更加符合专业标准和用户体验要求。
效率与可扩展性:
尽管CoDA系统引入了多个智能体和复杂的协作机制,但其计算效率并未显著降低。
实验结果显示,CoDA在保持高性能的同时,仍能在合理的时间内完成可视化任务。此外,CoDA的模块化设计使其易于扩展和定制,以适应不同领域和场景的需求。
用户反馈:
用户反馈表明,CoDA系统显著减轻了数据科学家在手动创建可视化图表上的负担,提高了工作效率和满意度。
用户特别赞赏系统的自动化程度和可视化质量,认为CoDA是数据可视化领域的一个重要突破。
研究局限
尽管CoDA系统在数据可视化自动化方面取得了显著进展,但仍存在一些局限性:
1. 计算资源需求:
尽管CoDA在保持高性能的同时实现了较高的计算效率,但在处理极大规模数据集时,仍需要较高的计算资源支持。
未来研究可探索更高效的算法和优化策略,以进一步降低计算资源需求。
2. 特定领域适应性:
当前CoDA系统主要针对通用数据可视化任务进行设计,对于特定领域(如医学、金融等)的可视化需求可能不够灵活。
未来研究可结合领域知识,开发更具针对性的可视化解决方案。
3. 用户交互与反馈机制:
虽然CoDA系统通过自我反思机制实现了可视化结果的迭代优化,但用户交互和反馈机制仍相对简单。
未来研究可引入更丰富的用户交互方式(如语音交互、手势识别等),以进一步提升用户体验和满意度。
未来研究方向
针对CoDA系统的局限性和数据可视化领域的发展趋势,未来研究可从以下几个方面展开:
1. 高效算法与优化策略:
探索更高效的算法和优化策略,以降低CoDA系统在处理大规模数据集时的计算资源需求。
例如,可研究基于分布式计算的并行化策略,或引入更高效的特征提取和降维算法。
2. 特定领域可视化解决方案:
结合领域知识,开发针对特定领域(如医学、金融等)的可视化解决方案。
通过引入领域特定的可视化模式和交互方式,提高CoDA系统在特定领域的应用效果和用户体验。
3. 增强用户交互与反馈机制:
引入更丰富的用户交互方式(如语音交互、手势识别等),以进一步提升用户体验和满意度。
同时,研究如何更有效地收集和利用用户反馈,以指导CoDA系统的持续优化和改进。
4. 跨模态数据可视化:
随着多模态数据的普及,跨模态数据可视化成为未来研究的重要方向。
可探索如何将CoDA系统扩展到多模态数据可视化领域,实现文本、图像、视频等多种模态数据的联合分析和可视化展示。
5. 开源与社区协作:
推动CoDA系统的开源实现,促进社区协作与持续改进。
通过开源社区的力量,不断完善和优化CoDA系统,形成开放、共享的研究生态。同时,可探索与其他开源项目的集成和协作,共同推动数据可视化领域的发展。