Redis -持久化

- 持久化
- Redis 的持久化是什么?
- Redis 的持久化什么时候需要用?
- Redis 的持久化有哪些方式?
- RDB 持久化是什么?
- RDB 的两种触发方式是什么?
- RDB 的 bgsave 的工作原理?
- RDB 文件坏了会怎样?
- AOF 持久化是什么?
- AOF 持久化如何保证效率的?
- AOF 重写是什么?
- AOF 重写的工作原理?
- RDB 和 AOF 的优缺点?
- Redis 混合持久化是什么?
持久化
Redis Persistence
Redis 的持久化是什么?
MySQL 的事务有四个核心的特性,原子性、一致性、持久性、隔离性。
这个持久性和持久化是一个意思,
本质就是将内存中的数据,存储到硬盘上面。
在重启进程或者重启主机后,
内存中的数据没了,这是不持久的,
硬盘中的数据还在,这就是持久的。
Redis 是个内存数据库,把数据存储在内存当中,
相比于 MySQL 这样的关系型数据库,Redis 最明显的优势就是快,
而这个快是有代价的,因为内存中的数据是不持久的,
而想要做到持久,就需要让 Redis 把数据存储到硬盘上。
于是 Redis 决定,内存中也存数据,磁盘上也存数据。
需要查询数据时,依然是从内存中直接读取,
硬盘上的数据,只在 Redis 重启时发挥作用,用于恢复内存中的数据。
Redis 的持久化什么时候需要用?
Redis 的持久化是个有代价的可选项,
开启后,会消耗更多的空间,因为同一份数据存了两遍,
并且比起没开持久化,效率还是会低一点点的。
必须开启持久化的场景:
如果数据丢失会造成严重的后果,
例如当 Redis 的数据是唯一数据源,
而不是做为缓存中间件(有MySQL兜底)时,
就必须开启持久化。
可以不用持久化的场景:
如果数据丢失后没什么影响,且数据可以快速重建,例如:
- Redis 用于缓存中间件,数据可以从 MySQL 重新加载
- 存储一些临时数据(如验证码)
- 恢复持久化数据后,那些数据已经过期失效
但是但是,还有例外,
即使 Redis 作为缓存使用,
如果存储的是难以重建的计算结果(如复杂的统计数据、耗时的聚合结果),
那持久化依然很有价值!
因为重新计算这些数据的成本可能很高。
所以总结起来就一句话:具体业务具体分析!
是否需要持久化关键看两点:
数据丢失的代价有多大?
数据重建的成本有多高?
如果代价大、重建难,就需要持久化。
如果代价小、重建快,可以不要。
Redis 的持久化有哪些方式?
把数据写入磁盘,一听就是个耗时间的事,
为了尽可能提高效率,Redis 用了两种持久化策略:
RDB,即 Redis DataBase,简单讲,这个是用来存 数据 的,一般是定期备份
AOF,即 Append Only File,简单讲,这个是用来存 用于恢复数据的操作 的,一般是实时备份
组合一下,Redis 就有了四个不同范围的持久化选项:
RDB 持久化、AOF 持久化、组合使用、禁用持久化
RDB 持久化是什么?
RDB 会定期的把 Redis 内存中的所有数据,全部写入硬盘中,生成一个"快照",
后续 Redis 一旦重启了,就可以根据刚刚的 “快照” 把内存中的数据恢复。
这里的 “快照”,
默认存于一个名为 dump.rdb 的二进制文件里,
默认所处的目录为 /var/lib/redis,
这个文件名和目录都可以在 /etc/redis/redis.conf 配置文件中修改。

RDB 的两种触发方式是什么?
第一种是手动触发,程序员通过 Redis 客户端,执行 save/bgsave 命令,来触发快照生成。
其中 save 是同步的,不建议使用,因为生成快照需要保存当前的所有数据,其破坏力不亚于 keys *
而 bgsave 是异步的,一般都用这个,Redis 会 fork 一个子进程来异步的写入 RDB 文件。
第二种是自动触发,触发后的行为类似 bgsave,这个触发机制比手动触发更常用,
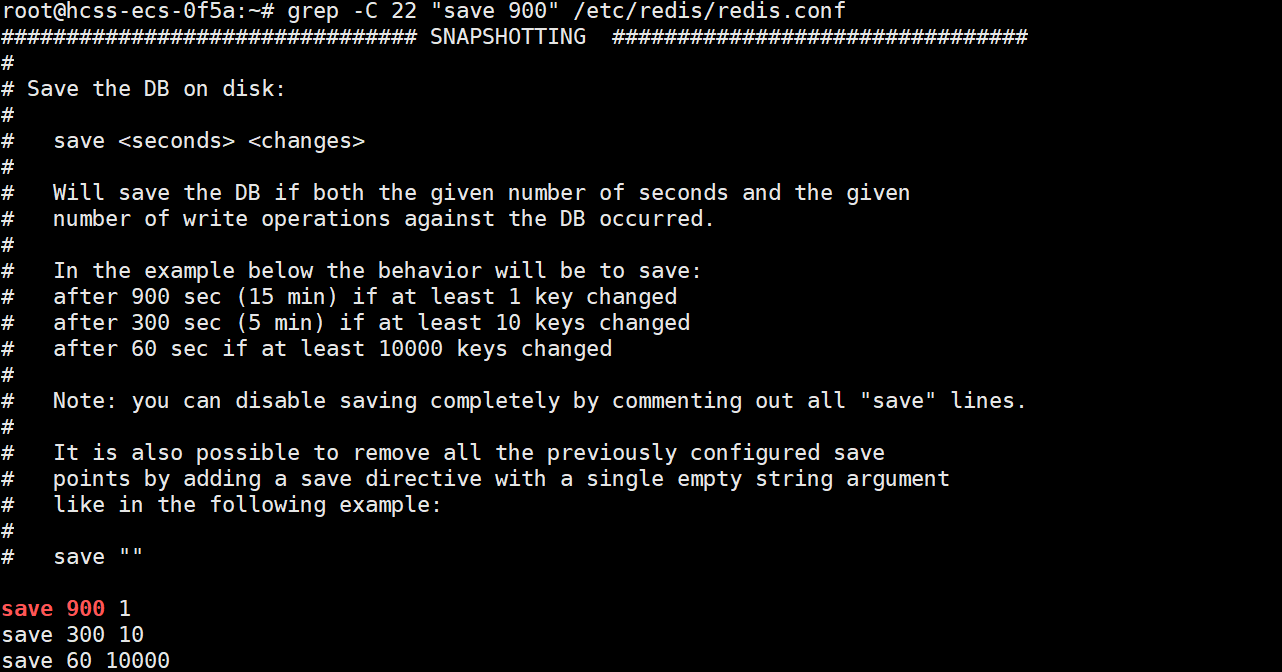
在 Redis 的配置文件中可以设置自动触发条件,默认的长这样:
save 900 1 # 900秒内至少1个键被修改时,触发 bgsave
save 300 10 # 300秒内至少10个键被修改时,触发 bgsave
save 60 10000 # 60秒内至少10000个键被修改时,触发 bgsave
如果要关闭自动触发,可以使用:
save ""
另外,值得注意的是,除了 bgsave 和 save 外,
shutdown 命令在关闭 Redis 服务时,如果配置了持久化选项,也会触发一次 save(注意这里不是 bgsave),
这是因为 shutdown 时需要确保数据完整保存后再退出,所以使用阻塞式的 save 而不是异步的 bgsave,
且此时如果有子进程正在执行 bgsave,会被直接 kill 掉(毕竟就算等它执行完,文件也会马上被覆盖掉)
而 Linux 上的命令 service redis-server restart 可以用于重启 Redis 服务,
此时会执行一个类似于 shutdown 的操作,确保在关闭时进行持久化(如果配置了)
再补充一点,flushall 也会触发 RDB 保存,生成一个空的 rdb 文件,
相当于清空了 rdb 文件,Redis 的删库跑路命令果然名不虚传
RDB 的 bgsave 的工作原理?
- 首先 Redis 会执行 fork(),现在我们有了一个和父进程状态一致的子进程,
- 父进程给 bgsave 操作返回 OK 后,继续执行其他操作,
- 而子进程则开始将 内存 中的所有数据写入到一个临时的 RDB 文件中,
- 当子进程完成写入后,会用这个新的 RDB 文件替换掉旧文件。
使用多进程进行异步持久化的优势很多,
由于进程具有独立性,父进程后续对内存数据的改动并不会影响到子进程,
由于写时拷贝 copy-on-write 机制,操作系统只会对父进程后续执行了修改操作的数据进行实际的拷贝,
而大部分的数据都由父子进程共享,因此实际拷贝的开销也并不是很大。
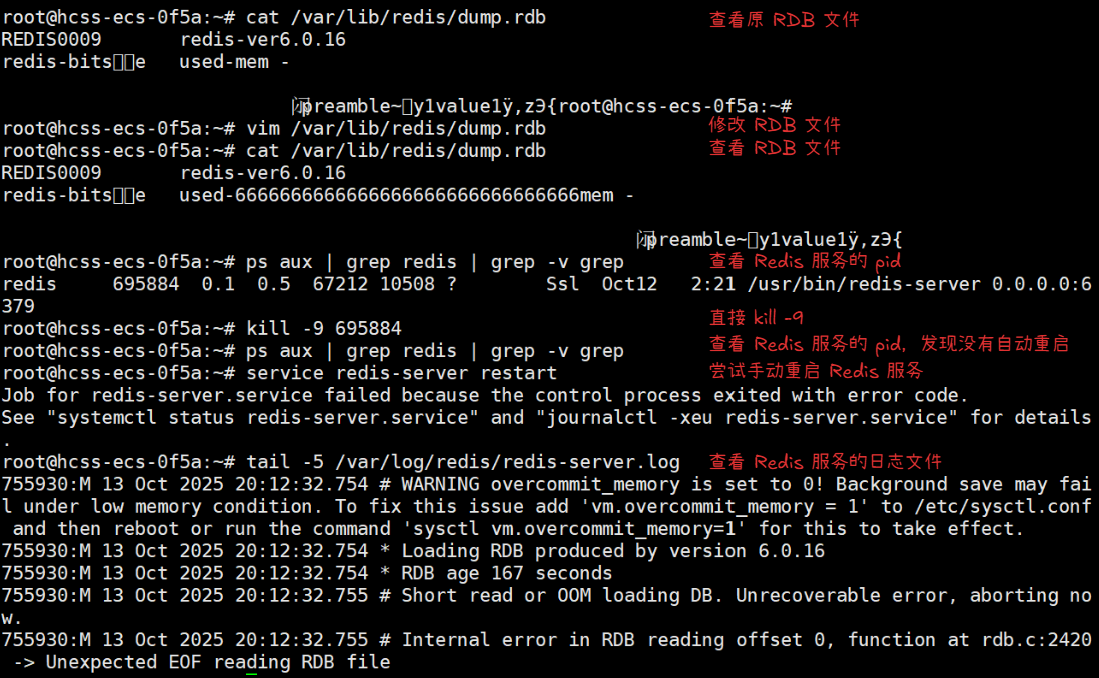
RDB 文件坏了会怎样?
如果是 RDB 文件末尾多了很多意义不明的数据,对 Redis 服务器没什么影响
如果是 RDB 文件中间坏掉了,Redis 服务器会无法启动,
此时我们可以查看 /var/log/redis/redis-server.log 日志文件,
里面记录了 Redis 服务启动错误的具体信息。
注,Redis 正常情况下,被 kill 掉后是会自动重启的,大致流程:
执行 service redis-server start
service 命令把请求转发给 systemd
systemd 启动 Redis 并开始监控
kill Redis 进程
systemd 检测到 Redis 进程退出
systemd 根据配置文件的 Restart=always
systemd 自动重启 Redis
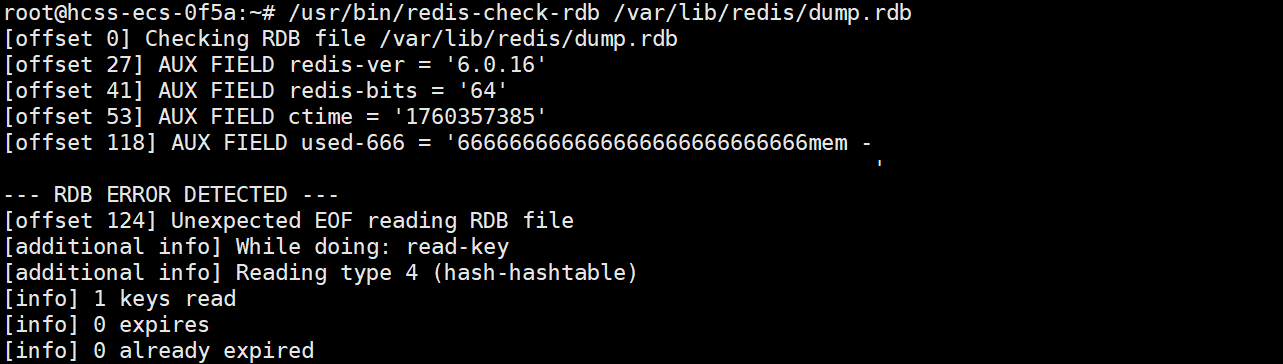
然后我们发现是 RDB 文件出了问题后,
还可以通过 Redis 提供的工具来查看 RDB 文件的具体问题,
一般是 /usr/bin/redis-check-rdb,
好像在 5.0 后,redis-server 和 redis-check-rdb 就是一个东西了:

运行时,加入 rdb 文件作为命令行参数,
此时就是以检查工具的方式来运行,
不会真的启动 Redis 服务器:
AOF 持久化是什么?
AOF 持久化的行为类似于 MySQL 的 binlog,会把用户的每个操作以文本形式追加到文件中。
Redis 默认没有开启 AOF 持久化:

可以修改为 appendonly yes 来打开 AOF
此后,每次 Redis 收到更改数据集的命令(例如 SET)时,它都会将其追加到 AOF。
当 Redis 重启时,会重放 AOF 文件中操作以重建状态。
AOF 持久化如何保证效率的?
如果每次收到一个更改数据集的命令,都调用一下 write,那么开销将会非常大。
就像很少有人会每嗑一个瓜子,都起身到很远的地方,把瓜子壳丢进垃圾桶。
因此 AOF 使用了一个缓冲区来存命令,然后定期 fsync 到文件中。
将数据 fsync 到磁盘的频率可以配置,有三个选项
always,每次追加新命令到 AOF 时 fsync,非常非常慢,非常安全
everysec,每秒 fsync,足够快,如果发生灾难,可能会丢失 1 秒的数据
no,从不 fsync,只是将数据交给操作系统,最快但最不安全的方法
建议(和默认)策略是每秒 fsync 一次,它既非常快又相当安全:

AOF 重写是什么?
由于每次都是在 AOF 末尾添加新的操作,AOF 将会变得越来越大。
并且很多操作都是不需要的,这些操作和重建当前状态无关,
比如我重复执行了100次相同数据的插入删除,等于什么都没做,
因此 Redis 支持一个有趣的功能,它能够在后台重建 AOF,而不中断对客户端的服务。
可以通过 bgrewriteaof 启动 AOF 重写,Redis 将编写重建内存中当前数据集所需的最短命令序列。
AOF 重写的工作原理?
这里和 RBD 的 bgsave 利用了相同的写时拷贝机制。
- 首先 Redis 会执行 fork(),现在我们有了一个和父进程状态一致的子进程
- 子进程开始在临时文件中写入新的 AOF
- 父进程此时会同时维护两个缓冲区,一个是旧 AOF 的,一个是 fork 之后的新命令,
如果重写失败,我们是安全的,
如果重写成功,我们也能快速获得重写期间的新命令 - 当子进程完成重写文件时,父进程会收到信号,并将内存缓冲区追加到子进程生成的文件末尾
- 成功!现在 Redis 原子地将旧文件重命名为新文件,并开始将新数据追加到新文件中
RDB 和 AOF 的优缺点?
RDB 的优势:
- 文件紧凑,二进制、单文件备份,便于恢复和传输
- 性能最优,通过 fork 子进程,父进程不需要执行磁盘 I/O
- 启动快速,大数据集重启速度快
RDB 的劣势:
- 数据丢失风险,定时保存,故障时可能丢失最近几分钟的数据
- fork 开销大,只用 RDB 时需要经常 fork(),大数据集时可能导致服务暂停,
AOF 也需要 fork(),但可以调整重写日志的频率,且不会影响持久性
AOF 的优势:
- 持久性强,可按秒级 fsync,最多丢失 1 秒数据
- 日志型安全,仅追加写入,即使断电也不会损坏,支持修复工具
- 可读可恢复,操作日志易解析,甚至能手动修改后恢复误删数据
AOF 的劣势:
- 文件较大,文本文件,体积通常是 RDB 的 2-3 倍
- 启动较慢,需根据命令重构数据,大数据集重启速度慢
Redis 混合持久化是什么?
传统的 AOF 重写,生成的新 AOF 文件依然是文本形式的命令,
Redis 重启恢复数据时,虽然避免了多余的操作,但加载速度依然较慢,
混合持久化的 AOF 重写,fork 后的子进程写的是 RDB 格式的文件,
此后的 AOF 文件,
前半部分是以 RDB 格式存储当前时间点的完整数据快照,
后半部分是以 AOF 格式追加增量的写命令。
这结合了 RDB 和 AOF 的优点,
相较于纯 AOF,
恢复速度更快,RDB 部分加载速度非常快,之后只需重放少量的 AOF 命令,
文件相对较小,大部分数据采用紧凑的 RDB 格式,比纯 AOF 小
相较于纯 RDB,
数据更加完整,持续追加写命令,减小了快照生成频率低导致的数据丢失问题
可以在配置文件中选择是否使用混合持久化:

注,Redis 4.0+ 才支持混合持久化

希望本篇文章对你有所帮助!并激发你进一步探索编程的兴趣!
本人仅是个C语言初学者,如果你有任何疑问或建议,欢迎随时留言讨论!让我们一起学习,共同进步!