K8S(七)—— Kubernetes Pod 进阶配置与生命周期管理全解析
文章目录
- 前言
- 一、Pod 进阶配置
- 1.1 Pod 资源限制
- 1.1.1 核心概念
- 1.1.2 资源单位
- 1.2 Pod 资源限制案例
- 示例 1:资源请求和限制配置
- 案列1:不同容器资源配置
- 调度与资源分配
- 1、Pod 调度实例:
- 2、CPU 与内存资源分配的实际情况
- 3、总结
- 1.3 健康检查(探针 Probe)
- 1.3.1 探针类型(重点)
- 1.3.2 检查方法
- 二、Kubernetes 探针(Probe)实践
- 2.1 存活探针(Liveness Probe)实践
- 2.1.1 Exec 方式:通过执行命令检测存活状态
- 示例1:Exec 方式核心配置
- 案例1:Exec 方式实操配置与结果
- 执行命令与结果查看
- 2.1.2 HTTP Get 方式:通过HTTP请求检测存活状态
- 示例2:HTTP Get 方式核心配置
- 案例2:HTTP Get 方式实操配置与结果
- 执行命令与结果查看
- 2.1.3 TCP Socket 方式:通过TCP连接检测存活状态
- 示例3:TCP Socket 方式核心配置(含就绪探针)
- 案例3:TCP Socket 方式实操配置与结果
- 执行命令与结果查看
- 2.2 就绪探针(Readiness Probe)实践
- 案例4:就绪探针与存活探针协同配置
- 执行命令与结果查看
- 案例5:就绪探针与Service Endpoint联动
- 执行命令与结果查看
- 三、容器生命周期钩子管理实践
- 3.1 案例6:初始化容器与生命周期钩子
- 执行命令与结果查看
- 核心逻辑总结
- 四、 Pod 与容器的状态说明
- 4.1 Pod 状态
- 4.2 容器状态
- 总结
- 一、资源限制:保障集群资源可控
- 二、探针实践:实现应用健康自愈
- 三、生命周期与状态:掌控 Pod 全生命周期
前言
当掌握 Pod 基础概念后,进阶配置(资源限制、健康检查)与生命周期管理(钩子、状态监控)成为保障 K8s 应用稳定运行的核心。资源限制可避免容器过度占用集群资源,健康探针能实时诊断应用状态、自动恢复异常,而生命周期钩子则支持容器启停阶段的自定义操作。
本文围绕 Pod 资源限制、探针实践、生命周期管理及状态解读展开,通过“理论+实操案例”,帮助读者掌握 Pod 进阶运维能力,解决生产环境中资源争用、服务异常、优雅启停等关键问题。
一、Pod 进阶配置
1.1 Pod 资源限制
为避免容器过度占用集群资源,K8s 支持为容器的 CPU 和内存资源设置资源请求(requests)和限制(limits)。这些设置确保了容器的资源分配和限制,避免资源争用和过度使用。
1.1.1 核心概念
- 请求(requests):容器启动时所需的最小资源,K8s 调度器根据此值选择有足够资源的节点;
- 限制(limits):容器运行时允许使用的最大资源,超出则会被限制(CPU 节流、内存 OOM 杀死)。
官网示例:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container///Pod 和 容器 的资源请求和限制:
spec.containers[].resources.requests.cpu //定义创建容器时预分配的CPU资源
spec.containers[].resources.requests.memory //定义创建容器时预分配的内存资源
spec.containers[].resources.limits.cpu //定义 cpu 的资源上限
spec.containers[].resources.limits.memory //定义内存的资源上限
1.1.2 资源单位
- CPU:以"毫核(m)"为单位,1 CPU = 1000m(如 500m 表示 0.5 核);
- 内存:支持二进制单位(Gi、Mi、Ki,1Gi=1024Mi)和十进制单位(GB、MB,1GB=1000MB),推荐使用二进制单位(如 64Mi、1Gi)。
需要注意的是,在存储设备中,标示的单位(如GB)是基于十进制,而操作系统通常使用二进制单位(如GiB)。因此,1 GiB 的内存比 1 GB 多出大约 73MB。
1.2 Pod 资源限制案例
以下是两个常见的 Kubernetes Pod 配置示例,展示了如何为容器指定资源请求和限制:
示例 1:资源请求和限制配置
apiVersion: v1
kind: Pod
metadata:name: frontend
spec:containers:- name: appimage: images.my-company.example/app:v4env:- name: MYSQL_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi" # 最少 64Mi 内存cpu: "250m" # 最少 0.25 CPUlimits:memory: "128Mi" # 最大 128Mi 内存cpu: "500m" # 最大 0.5 CPU- name: log-aggregatorimage: images.my-company.example/log-aggregator:v6resources:requests:memory: "64Mi" # 最少 64Mi 内存cpu: "250m" # 最少 0.25 CPUlimits:memory: "128Mi" # 最大 128Mi 内存cpu: "500m" # 最大 0.5 CPU
分析:
- 每个容器的 请求资源 是:
0.25 CPU和64Mi内存。 - 每个容器的 限制资源 是:
0.5 CPU和128Mi内存。 - 该 Pod 的 总请求资源 为
0.5 CPU和128Mi内存。 - 该 Pod 的 总限制资源 为
1 CPU和256Mi内存。
案列1:不同容器资源配置
vim pod2.yaml
apiVersion: v1
kind: Pod
metadata:name: frontend
spec:containers:- name: webimage: nginxenv:- name: WEB_ROOT_PASSWORDvalue: "password"resources:requests:memory: "64Mi" # 最少 64Mi 内存cpu: "250m" # 最少 0.25 CPUlimits:memory: "128Mi" # 最大 128Mi 内存cpu: "500m" # 最大 0.5 CPU- name: dbimage: mysqlenv:- name: MYSQL_ROOT_PASSWORDvalue: "abc123"resources:requests:memory: "512Mi" # 最少 512Mi 内存cpu: "0.5" # 最少 0.5 CPUlimits:memory: "1Gi" # 最大 1Gi 内存cpu: "1" # 最大 1 CPU
分析:
- Web 容器:
- 请求:
0.25 CPU和64Mi内存 - 限制:
0.5 CPU和128Mi内存
- 请求:
- DB 容器:
- 请求:
0.5 CPU和512Mi内存 - 限制:
1 CPU和1Gi内存
- 请求:
该 Pod 的总请求资源为:
0.75 CPU和576Mi内存
该 Pod 的总限制资源为:
1.5 CPU和1.128Gi内存
调度与资源分配
Kubernetes 调度 Pod 时,会根据容器的资源请求(requests)来筛选合适的节点。调度器会优先选择资源充足的节点进行分配;若当前节点资源不足,则会自动将 Pod 调度到其他可用节点。
1、Pod 调度实例:
kubectl apply -f pod2.yaml
kubectl describe pod frontend
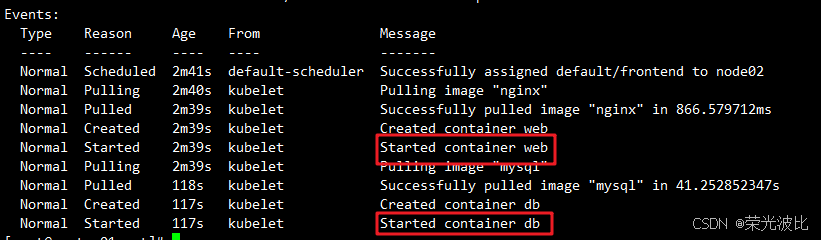
查看 Pod 分配资源情况:
kubectl get pods -o wide
输出结果将显示 Pod 是否成功启动,以及它的运行状态。
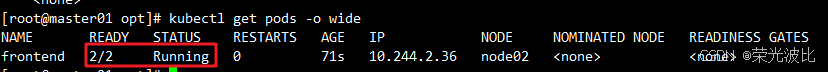
查看节点资源:
kubectl describe nodes node02
该命令可查看节点资源使用详情,包括各Pod的资源请求与限制占用情况,以及节点剩余可用资源。
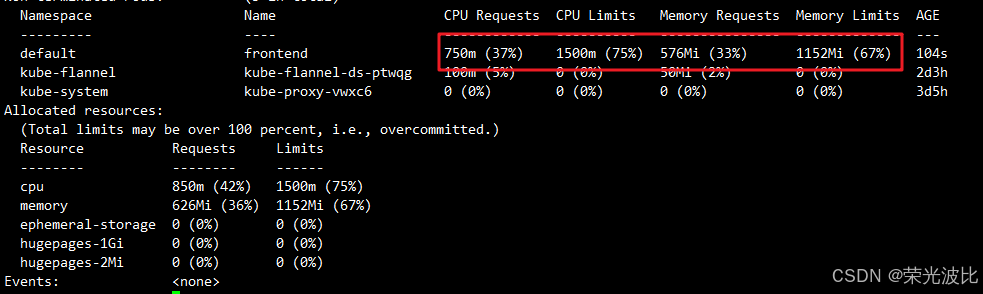
2、CPU 与内存资源分配的实际情况
假设你的虚拟机配备 2 个 CPU 核心,当为 Pod 配置了 1 个 CPU 的请求量和 2 个 CPU 的限制时,该 Pod 将占用节点 50% 的 CPU 资源。
节点资源的分配情况可以通过以下命令进行查看:
kubectl describe nodes node02
输出的资源分配详细信息示例:
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits--------- ---- ------------ ---------- --------------- -------------default frontend 500m (25%) 1 (50%) 128Mi (3%) 256Mi (6%)kube-system kube-flannel-ds-amd64-f4pbp 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%)
3、总结
-
资源请求与限制:
requests表示容器运行所需的最小资源量,调度器根据该值选择合适节点。limits定义容器可使用的资源上限,超出部分将被系统限制。
-
默认设置:
- 当未明确配置
requests时,系统会默认采用与limits相同的值。
- 当未明确配置
-
资源聚合计算:
- Pod 内所有容器的资源请求和限制会被自动汇总,用于节点资源监控和调度决策。
-
资源计量单位:
- CPU:以毫核(
m)为单位,例如500m代表 0.5 核 CPU。 - 内存:采用标准字节单位,建议使用二进制倍数单位如
GiB、MiB等。
- CPU:以毫核(
1.3 健康检查(探针 Probe)
K8s 通过 探针 定期诊断容器状态,确保应用健康运行。探针由 kubelet 执行,分为三类:
1.3.1 探针类型(重点)
- livenessProbe(存活探针):用于检测容器是否正常运行,若探测失败则根据重启策略重启容器。若容器未配置存活探针,默认状态为
Success; - readinessProbe(就绪探针):用于检测容器是否准备好接收请求,若探测失败则将该Pod的IP从匹配Service的endpoints中移除。在初始延迟期前,默认就绪状态为Failure。若容器未配置就绪探针,默认状态为Success;
- startupProbe(启动探针,1.17+):用于检测应用是否完成启动。若配置了启动探针,在该探针成功前其他探针均不生效(适用于启动较慢的应用)。若启动探针失败,kubelet将终止容器并根据restartPolicy进行重启。若容器未配置启动探针,默认状态为Success。
以上规则可以同时定义。在readinessProbe检测成功之前,Pod的running状态是不会变成ready状态的。
1.3.2 检查方法
- exec:在容器内执行指定命令,返回状态码 0 表示成功;
- tcpSocket:对容器 IP 地址的指定端口执行 TCP 握手检查,端口连通即判定为成功;
- httpGet:向容器 IP 地址的指定端口和路径发送 HTTP GET 请求,响应状态码在 200 至 399 范围内即视为成功。
每次探测都将获得以下三种结果之一:
- 成功:容器通过了诊断。
- 失败:容器未通过诊断。
- 未知:诊断失败,因此不会采取任何行动
二、Kubernetes 探针(Probe)实践
2.1 存活探针(Liveness Probe)实践
存活探针用于检测容器是否运行正常,若探测失败,kubelet会杀死容器并根据重启策略重启容器。以下是三种常见的存活探针实现方式。
2.1.1 Exec 方式:通过执行命令检测存活状态
示例1:Exec 方式核心配置
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-exec
spec:containers:- name: livenessimage: k8s.gcr.io/busyboxargs: - /bin/sh- -c- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 60livenessProbe:exec:command:- cat- /tmp/healthyfailureThreshold: 1 initialDelaySeconds: 5periodSeconds: 5
- 核心逻辑:容器启动后先创建
/tmp/healthy文件,30秒后删除该文件;探针每5秒执行cat /tmp/healthy命令,文件存在则探测成功,文件删除后探测失败,触发容器重启。 - 关键参数说明:
initialDelaySeconds:容器启动后等待5秒再执行第一次探测(默认0秒,最小值0)。periodSeconds:每5秒执行一次探测(默认10秒,最小值1)。failureThreshold:探测失败1次后即触发容器重启(默认3次,最小值1)。timeoutSeconds:探测超时时间(默认1秒,最小值1;1.20版本前exec探针忽略此参数)。
案例1:Exec 方式实操配置与结果
vim exec.yaml
apiVersion: v1
kind: Pod
metadata:name: liveness-execnamespace: default
spec:containers:- name: liveness-exec-containerimage: busyboximagePullPolicy: IfNotPresentcommand: ["/bin/sh","-c","touch /tmp/live ; sleep 10; rm -rf /tmp/live; sleep 3600"]livenessProbe:exec:command: ["test","-e","/tmp/live"]initialDelaySeconds: 1periodSeconds: 3
执行命令与结果查看
1.、创建Pod:
kubectl create -f exec.yaml
2.、查看Pod事件(探测失败后触发重启):
kubectl describe pods liveness-exec
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 68s default-scheduler Successfully assigned default/liveness-exec to node02
Normal Pulled 18s (x2 over 67s) kubelet Container image "busybox" already present on machine
Normal Created 18s (x2 over 66s) kubelet Created container liveness-exec-container
Normal Started 18s (x2 over 66s) kubelet Started container liveness-exec-container
Warning Unhealthy 1s (x6 over 55s) kubelet Liveness probe failed:
Normal Killing 1s (x2 over 49s) kubelet Container liveness-exec-container failed liveness probe, will be restarted
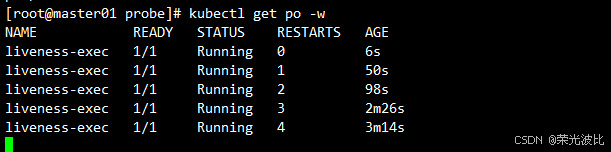
3、 实时查看Pod状态(重启次数增加):
kubectl get pods -w
2.1.2 HTTP Get 方式:通过HTTP请求检测存活状态
示例2:HTTP Get 方式核心配置
apiVersion: v1
kind: Pod
metadata:labels:test: livenessname: liveness-http
spec:containers:- name: livenessimage: k8s.gcr.io/livenessargs:- /serverlivenessProbe:httpGet:path: /healthzport: 8080httpHeaders:- name: Custom-Headervalue: AwesomeinitialDelaySeconds: 3periodSeconds: 3
- 核心逻辑:探针向容器的8080端口发送
GET /healthz请求(携带自定义Header),返回状态码200-399视为成功,其他状态码视为失败,触发容器重启。
案例2:HTTP Get 方式实操配置与结果
vim httpget.yaml
apiVersion: v1
kind: Pod
metadata:name: liveness-httpgetnamespace: default
spec:containers:- name: liveness-httpget-containerimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80livenessProbe:httpGet:port: httppath: /index.htmlinitialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
执行命令与结果查看
-
创建Pod:
kubectl create -f httpget.yaml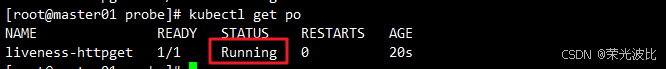
-
手动删除探测依赖文件(模拟服务异常):
kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html -
查看Pod状态(探测失败后重启):
kubectl get podsNAME READY STATUS RESTARTS AGE liveness-httpget 1/1 Running 1 91s
- 补充说明:探针参数逻辑为「延迟1秒启动探测,每3秒探测一次,超时时间10秒,失败3次后杀死容器」。

2.1.3 TCP Socket 方式:通过TCP连接检测存活状态
示例3:TCP Socket 方式核心配置(含就绪探针)
apiVersion: v1
kind: Pod
metadata:name: goproxylabels:app: goproxy
spec:containers:- name: goproxyimage: k8s.gcr.io/goproxy:0.1ports:- containerPort: 8080readinessProbe: # 就绪探针:检测容器是否可提供服务tcpSocket:port: 8080initialDelaySeconds: 5periodSeconds: 10livenessProbe: # 存活探针:检测容器是否运行tcpSocket:port: 8080initialDelaySeconds: 15periodSeconds: 20
- 核心逻辑:
- 就绪探针:容器启动5秒后,每10秒尝试连接8080端口,连接成功则标记容器「就绪」。
- 存活探针:容器启动15秒后,每20秒尝试连接8080端口,连接失败则重启容器。
案例3:TCP Socket 方式实操配置与结果
vim tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:name: probe-tcp
spec:containers:- name: nginximage: soscscs/myapp:v1livenessProbe:initialDelaySeconds: 5timeoutSeconds: 1tcpSocket:port: 8080 # 注意:nginx默认监听80端口,此处故意配置错误以模拟探测失败periodSeconds: 10failureThreshold: 2
执行命令与结果查看
1、 创建Pod:
kubectl create -f tcpsocket.yaml
kubectl get po

2、查看容器实际监听端口(确认配置错误):
kubectl exec -it probe-tcp -- netstat -natp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1/nginx: master pro

3、 实时查看Pod状态(探测失败后循环重启):
kubectl get pods -w
NAME READY STATUS RESTARTS AGE
probe-tcp 1/1 Running 0 1s
probe-tcp 1/1 Running 1 25s # 首次重启:5秒延迟 + 10秒*2次失败
probe-tcp 1/1 Running 2 45s # 后续重启:每10秒*2次失败触发
probe-tcp 1/1 Running 3 65s
4、修改TcpSocket端口
apiVersion: v1
kind: Pod
metadata:name: probe-tcp
spec:containers:- name: nginximage: soscscs/myapp:v1livenessProbe:initialDelaySeconds: 5timeoutSeconds: 1tcpSocket:port: 80 # 将探针检测端口修改为80periodSeconds: 10failureThreshold: 2kubectl apply -f tcpsocket.yaml
kubectl get po # 探针检测正常,pod不再重启
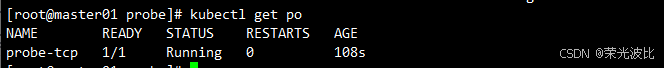
2.2 就绪探针(Readiness Probe)实践
就绪探针用于检测容器是否「可提供服务」,若探测失败,Pod会被标记为「未就绪」,从Service的Endpoint中移除,不再接收流量。
案例4:就绪探针与存活探针协同配置
vim readiness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:name: readiness-httpgetnamespace: default
spec:containers:- name: readiness-httpget-containerimage: soscscs/myapp:v1imagePullPolicy: IfNotPresentports:- name: httpcontainerPort: 80readinessProbe: # 就绪探针:检测/index1.html是否存在(决定是否接收流量)httpGet:port: 80path: /index1.htmlinitialDelaySeconds: 1periodSeconds: 3livenessProbe: # 存活探针:检测/index.html是否存在(决定是否重启容器)httpGet:port: httppath: /index.htmlinitialDelaySeconds: 1periodSeconds: 3timeoutSeconds: 10
执行命令与结果查看
1、创建Pod:
kubectl create -f readiness-httpget.yaml
2、初始状态:/index1.html不存在,Pod「未就绪」(READY 0/1)。
kubectl get po
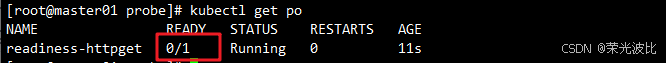
3、手动创建/index1.html(模拟服务就绪):
kubectl exec -it readiness-httpget sh
cd /usr/share/nginx/html/
echo 123 > index1.html
exit
4、. 查看Pod状态(变为「就绪」):
kubectl get pods
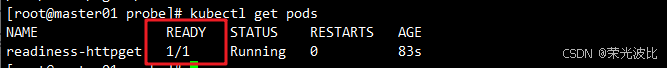
5、. 手动删除/index.html(模拟服务崩溃):
kubectl exec -it readiness-httpget -- rm -rf /usr/share/nginx/html/index.html
6、. 查看Pod状态(存活探针失败,触发重启,READY变为0/1):
kubectl get pods -w

案例5:就绪探针与Service Endpoint联动
vim readiness-myapp.yaml
apiVersion: v1
kind: Pod
metadata:name: myapp1labels:app: myapp
spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10
---
apiVersion: v1
kind: Pod
metadata:name: myapp2labels:app: myapp
spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10
---
apiVersion: v1
kind: Pod
metadata:name: myapp3labels:app: myapp
spec:containers:- name: myappimage: soscscs/myapp:v1ports:- name: httpcontainerPort: 80readinessProbe:httpGet:port: 80path: /index.htmlinitialDelaySeconds: 5periodSeconds: 5timeoutSeconds: 10
---
apiVersion: v1
kind: Service
metadata:name: myapp
spec:selector:app: myapptype: ClusterIPports:- name: httpport: 80targetPort: 80
执行命令与结果查看
1、. 创建Pod与Service:
kubectl create -f readiness-myapp.yaml
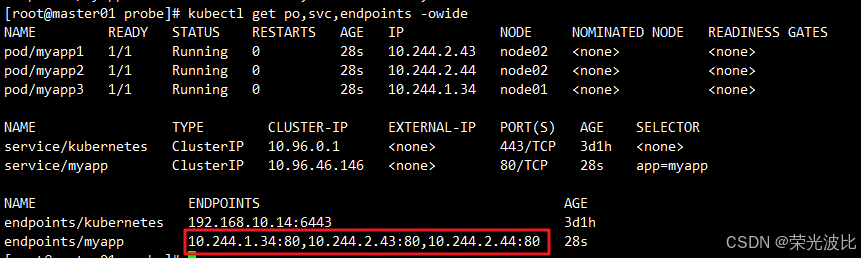
2、. 初始状态(所有Pod就绪,Endpoint包含3个Pod IP):
kubectl get pods,svc,endpoints -o wide
3、. 模拟myapp1故障(删除/index.html):
kubectl exec -it pod/myapp1 -- rm -rf /usr/share/nginx/html/index.html
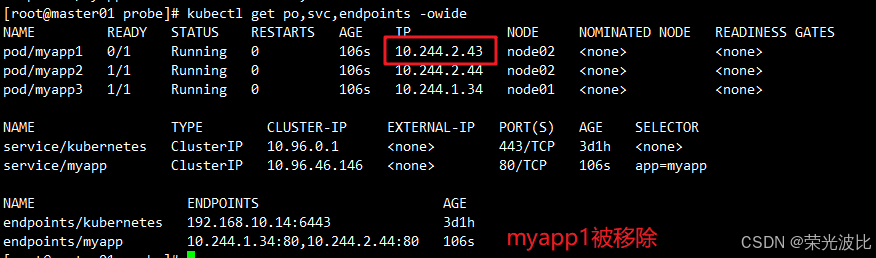
4、. 查看状态(myapp1未就绪,Endpoint移除其IP):
kubectl get pods,svc,endpoints -o wide
三、容器生命周期钩子管理实践
容器生命周期管理包括初始化容器(initContainers)、启动后动作(postStart)和停止前动作(preStop),用于在容器生命周期的特定阶段执行自定义操作。
3.1 案例6:初始化容器与生命周期钩子
vim post.yaml
apiVersion: v1
kind: Pod
metadata:name: lifecycle-demo
spec:containers:- name: lifecycle-demo-containerimage: soscscs/myapp:v1lifecycle: #此为关键字段postStart:exec:command: ["/bin/sh", "-c", "echo Hello from the postStart handler >> /var/log/nginx/message"] preStop:exec:command: ["/bin/sh", "-c", "echo Hello from the poststop handler >> /var/log/nginx/message"]volumeMounts:- name: message-logmountPath: /var/log/nginx/readOnly: falseinitContainers:- name: init-myserviceimage: soscscs/myapp:v1command: ["/bin/sh", "-c", "echo 'Hello initContainers' >> /var/log/nginx/message"]volumeMounts:- name: message-logmountPath: /var/log/nginx/readOnly: falsevolumes:- name: message-loghostPath:path: /data/volumes/nginx/log/type: DirectoryOrCreate
执行命令与结果查看
1、. 创建Pod:
kubectl create -f post.yaml
2、 查看Pod状态:
kubectl get pods -o wide

3、查看容器内日志文件(验证执行顺序):
kubectl exec -it lifecycle-demo -- cat /var/log/nginx/message
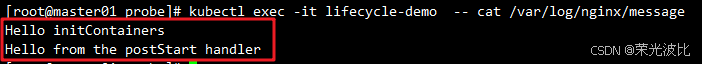
- 执行顺序说明:初始化容器(initContainers)先执行,主容器启动后立即触发
postStart动作。
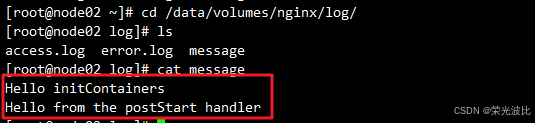
4.、在节点上查看宿主机挂载的日志文件:
# 在 node02 节点上操作
[root@node02 ~]# cd /data/volumes/nginx/log/
[root@node02 log]# ls
access.log error.log message
[root@node02 log]# cat message
Hello initContainers
Hello from the postStart handler
5.、删除Pod,验证preStop动作:
kubectl delete pod lifecycle-demo
6、 再次查看节点上的日志文件:
[root@node02 log]# cat message
Hello initContainers
Hello from the postStart handler
Hello from the poststop handler
- 说明:容器被删除前,Kubernetes会触发
preStop动作,执行预设命令。

核心逻辑总结
- 初始化容器(initContainers):在主容器启动前执行,用于完成主容器依赖的前置操作(如配置初始化、依赖检查等)。
- postStart:主容器启动后立即执行(无严格时间保证,可能与容器内进程并行),用于容器启动后的初始化操作。
- preStop:容器终止前执行(同步操作,会阻塞容器删除流程直至完成),用于优雅关闭(如保存状态、断开连接等)。
四、 Pod 与容器的状态说明
4.1 Pod 状态
- Pending:Pod 已创建,但容器未启动(可能在调度或拉取镜像);
- Running:pod已经与node绑定了(调度成功),至少一个容器运行中(或启动中);
- Succeeded:所有容器正常终止,且不会重启;
- Failed:Pod 中所有容器均已终止,且至少有一个容器异常终止(返回非零退出码或被系统强制终止);
- Unknown:无法获取状态(通常是通信问题)。
4.2 容器状态
- Waiting:启动中(如拉取镜像、初始化);
- Running:正常运行;
- Terminated:已终止(正常或异常)。
总结
本文聚焦 Pod 进阶配置与生命周期管理,核心要点可归纳为三部分:
一、资源限制:保障集群资源可控
通过 requests(最小资源请求,用于调度)和 limits(最大资源限制,避免过载)为容器配置 CPU/内存资源,需注意单位规范(CPU 用毫核 m,内存推荐二进制单位 Gi/Mi),同时根据容器角色(如数据库需更多内存)差异化配置,防止资源浪费或争用。
二、探针实践:实现应用健康自愈
三类探针各有核心作用:存活探针(livenessProbe)通过 Exec、HTTP、TCP 方式检测容器运行状态,失败则重启;就绪探针(readinessProbe)判断容器是否可接收流量,失败则移出 Service 端点;启动探针(startupProbe)适配慢启动应用,成功前屏蔽其他探针。实操中需合理设置 initialDelaySeconds(延迟探测)、periodSeconds(探测间隔)等参数,避免误判。
三、生命周期与状态:掌控 Pod 全生命周期
- 钩子管理:初始化容器(
initContainers)完成主容器前置依赖;postStart执行容器启动后操作,preStop实现优雅关闭(如保存状态); - 状态解读:Pod 状态(Pending/Running/Failed 等)反映整体部署进度,容器状态(Waiting/Running/Terminated)定位具体启动或终止问题,是排查故障的核心依据。
掌握这些进阶能力,可大幅提升 K8s 应用的稳定性与可运维性,为复杂业务场景(如微服务、高可用部署)打下坚实基础。