【AI论文】通过渐进式一致性蒸馏实现高效的多模态大语言模型
摘要:在多模态大语言模型(Multi-modal Large Language Models, MLLMs)中,视觉令牌(Visual tokens)会消耗大量计算资源,这极大地降低了模型的效率。近期的一些研究尝试通过在训练过程中压缩视觉令牌来提升效率,方法包括修改模型组件或引入额外的参数。然而,这些研究往往忽视了此类压缩操作所带来的学习难度增加问题,因为模型的参数空间难以快速适应由令牌压缩引起的特征空间中的大幅扰动。在本研究中,我们提出了一种渐进式学习框架——通过渐进式一致性蒸馏(Progressive Consistency Distillation, EPIC)开发高效的多模态大语言模型(Efficient MLLMs)。具体而言,我们沿着令牌维度和层维度对令牌压缩所引入的特征空间扰动进行分解,分别引入了令牌一致性蒸馏和层一致性蒸馏,旨在通过利用教师模型的指导并遵循渐进式学习轨迹来降低训练难度。大量实验表明,我们提出的框架具有卓越的有效性、鲁棒性和泛化能力。Huggingface链接:Paper page,论文链接:2510.00515
研究背景和目的
研究背景:
随着多模态大语言模型(MLLMs)的发展,这些模型在处理和理解多模态信息(如图像、视频和文本)方面展现出了卓越的能力。
然而,与仅需处理少量密集文本令牌的大语言模型(LLMs)不同,MLLMs需要处理大量的视觉令牌,这导致了显著的计算挑战,尤其是在处理高分辨率图像或多帧视频时。视觉令牌的数量通常比文本令牌多出几个数量级,同时包含更大的空间冗余性,这使得MLLMs的计算效率成为亟待解决的问题。
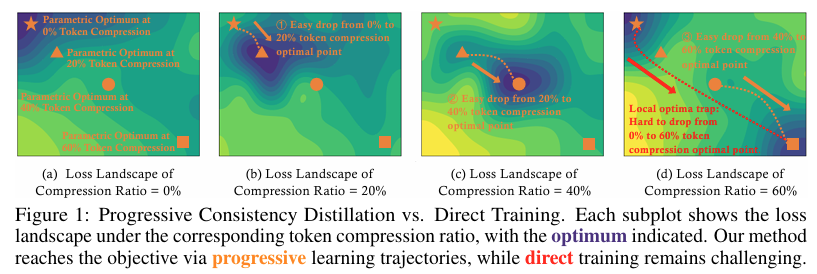
为了提高MLLMs的效率,近期的研究尝试通过压缩视觉令牌来减少计算资源消耗。这些方法包括基于模型组件修改的参数化方法和无需额外训练的非参数化方法。然而,这些方法往往忽略了令牌压缩在训练过程中增加的学习难度,因为模型参数空间需要快速适应由令牌压缩引起的特征空间中的大幅扰动。
研究目的:
本研究旨在提出一种新的学习框架——通过渐进一致性蒸馏(EPIC)来提高多模态大语言模型的效率。具体目标包括:
- 减少计算资源消耗:通过压缩视觉令牌来降低MLLMs在处理高分辨率图像和视频时的计算资源需求。
- 保持模型性能:在压缩视觉令牌的同时,确保模型的性能不会显著下降,甚至在某些情况下能够提升模型性能。
- 提高训练稳定性:通过引入教师模型的指导,减少由于令牌压缩引起的特征空间扰动对模型训练的影响,提高训练的稳定性和收敛性。
研究方法
为了实现上述研究目标,本研究提出了EPIC框架,该框架主要包括两个关键组件:令牌一致性蒸馏(TCD)和层一致性蒸馏(LCD)。
令牌一致性蒸馏(TCD):
- 渐进式学习:在训练初期,教师模型和学生模型都采用较低的令牌压缩比,形成相对容易的学习任务。随着训练的进行,逐步增加压缩比,形成渐进式学习轨迹。
- 教师模型与学生模型共享参数:教师模型使用略低于学生模型的压缩比,通过KL散度损失函数指导学生模型的学习,提供平滑的目标分布。
- 压缩比差距控制:教师模型和学生模型之间的压缩比差距也设计为遵循渐进式学习策略,逐步增加差距,以减轻学习难度。
层一致性蒸馏:
- 从深到浅层层推进:在训练初期,视觉令牌压缩主要在深层进行,随着训练的深入,逐步将压缩令牌引入较浅层,遵循由易到难的学习路径。
- 教师模型与学生模型的压缩比差距:教师模型使用略低于学生模型的压缩比,鼓励学生从教师模型中受益,逐步引导学生模型适应更强的压缩。
一致性蒸馏损失函数:使用KL散度作为一致性蒸馏的损失函数,衡量教师模型和学生模型输出分布之间的差异,指导学生模型向教师模型靠近。
研究结果
模型性能:
- 在多个视觉理解基准测试中,使用EPIC框架训练的MLLMs在保持高效能的同时,实现了与基线模型相当甚至更好的性能。具体来说,在MMBench等基准测试中,使用64个视觉令牌的模型在FLOPs和KV缓存使用上显著优于使用576个视觉令牌的LLaVA-v1.5模型。
效率提升:
- 计算资源减少:与基线模型相比,使用EPIC框架的模型在视觉令牌数量减少80%以上的情况下,仍能保持相当的性能水平,显著降低了计算资源消耗。具体表现为KV缓存、CUDA时间和FLOPs的大幅减少。
- 训练时间缩短:EPIC框架仅需在8个A100 GPU上训练约12小时,显著少于大多数需要两到三个训练阶段的方法。
鲁棒性和泛化能力:
- 不同压缩策略下的鲁棒性:通过交叉策略验证,发现无论使用何种令牌压缩策略训练,EPIC框架训练出的模型均展现出较强的鲁棒性,在不同压缩比下性能波动较小。
- 跨任务泛化:在包含不同类型和数量视觉令牌的复杂场景中,EPIC框架训练的模型仍能保持稳定的性能输出,显示出良好的泛化能力。
实际应用效果:
- 视觉理解任务:在图像描述、视觉问答等任务上,EPIC框架训练的模型展现出与未压缩模型相当甚至更好的性能,表明该框架能有效提升模型在实际应用中的表现。
- 多模态推理:在涉及复杂视觉信息整合的推理任务中,使用EPIC框架的模型同样表现出色,证明了该方法在高级认知功能上的有效性。
研究局限
尽管EPIC框架在提升MLLMs效率方面展现出显著优势,但仍存在一些潜在局限,具体包括:
模型架构依赖:
- 当前EPIC框架主要基于特定模型架构进行验证,未来需探索在不同架构上的普适性。虽未明确指出,但可推测模型依赖性可能限制更广泛场景的应用。
压缩比选择的主观性:
- 压缩比的选择在一定程度上依赖实验设计,可能影响结果的一般性。未来需探索更客观的压缩比选择标准。
长尾效应关注不足:
- 当前研究更多关注平均性能,对长尾分布(如少数类别的性能)关注不足,可能掩盖部分模型在特定场景下的不足。
极端压缩情景下的性能:
- 虽展示出良好平均性能,但在极端压缩情景(如1-2个令牌)下,模型性能可能出现显著下降,需进一步探索平衡效率与性能的最优策略。
未来研究方向
模型架构普适性研究:
- 探索EPIC框架在不同MLLMs架构上的普适性,验证其能否广泛应用于各类多模态模型。
动态压缩策略优化:
- 研究动态调整压缩比策略,根据模型实时性能反馈自动优化压缩比,实现效率与性能的更优平衡。
长尾效应与少数类别性能提升:
- 关注长尾分布和少数类别性能,通过迁移学习或元学习策略提升模型在少数类别上的表现。
极端压缩情景探索:
- 研究在极端压缩情景下如何保持模型性能的策略,如引入更复杂的蒸馏技术或混合精度训练方法。
跨模态应用拓展:
- 将EPIC框架应用于其他模态领域(如音频、视频等),探索跨模态压缩与一致性的保持策略。
可解释性与安全性增强:
- 研究如何提升模型在压缩情景下的可解释性,同时增强对抗性训练以提高模型鲁棒性。
真实场景与用户反馈整合:
- 结合用户反馈动态调整压缩策略,实现个性化压缩与一致性保持的平衡。
多阶段与终身学习:
- 探索多阶段训练策略,结合终身学习理念,使模型在不同训练阶段保持一致性,适应不断变化的数据分布和任务需求。。
社会影响与伦理考量:
- 评估模型在不同文化和伦理背景下的表现,开发符合伦理规范和社会责任的压缩与一致性保持策略。
开源与社区协作:
- 推动EPIC框架的开源实现,促进社区协作与持续改进,形成开放、共享的研究生态。