Spark RDD 宽窄依赖:从 DAG 到 Shuffle 的性能之道

Spark RDD 宽窄依赖:从 DAG 到 Shuffle 的性能之道
🌟 你好,我是 励志成为糕手 !
🌌 在代码的宇宙中,我是那个追逐优雅与性能的星际旅人。
✨ 每一行代码都是我种下的星光,在逻辑的土壤里生长成璀璨的银河;
🛠️ 每一个算法都是我绘制的星图,指引着数据流动的最短路径;
🔍 每一次调试都是星际对话,用耐心和智慧解开宇宙的谜题。
🚀 准备好开始我们的星际编码之旅了吗?
目录
- Spark RDD 宽窄依赖:从 DAG 到 Shuffle 的性能之道
- 摘要
- 一、什么是 RDD 依赖:从逻辑血缘到执行边界
- 1.1 窄依赖(Narrow Dependency)
- 1.2 宽依赖(Wide Dependency)
- 1.3 DAG 与 Stage 的关系
- 二、可视化理解:从流程到架构的多维图示
- 三、执行细节:Shuffle 的写读、排序与聚合
- 3.1 Shuffle Write
- 3.2 Shuffle Read
- 3.3 排序与聚合:从无序全量到有序增量
- 3.4 External Shuffle Service 与 BlockManager
- 四、代码与实践:识别依赖与减少 Shuffle
- 4.1 Java RDD: reduceByKey vs groupByKey 的性能对比
- 4.2 Scala RDD:join 的宽依赖与 skew 缓解
- 4.3 Java RDD:自定义分区器与两段聚合
- 五、参数与方案对比表(扩展版)
- 六、性能优化清单:把“知道”变成“做到”
- 七、总结:依赖类型串起性能链路
- 参考文献
- 关键词标签
摘要
理解 Spark RDD 的宽窄依赖,是从“跑得动”到“跑得好”的关键分水岭。窄依赖类似短路径直连:父分区与子分区之间多为一对一或少量关系,不需要跨节点重分布,因此可以流水化执行、充分利用本地性、错误恢复成本低;宽依赖则像跨区域的骨干路由:数据需要按 key 或分区规则重划分,触发 Shuffle,涉及跨节点拉取与落盘排序,往往成为性能瓶颈。
本文以 DAG 视角拆解依赖类型如何决定 Stage 边界、任务并行度和容错策略,并通过代码示例、图示流程、参数对比与调优清单,帮助你在真实场景中判断“是否会 Shuffle、在哪里切 Stage、如何降低 IO 与网络成本”。我们将从概念出发,深入执行细节:Shuffle 写读、聚合与排序、External Shuffle Service 的作用、BlockManager 的职责;从工程实践回到设计抉择:为何 groupByKey 容易过载,reduceByKey 如何 map 端预聚合大幅降低倾倒量;coalesce 与 repartition 的适用场景与代价权衡;checkpoint/persist 如何影响 DAG 长度与容错边界。
随后给出一组可落地优化策略与参数指南,并以案例数据展示在不同分区数、序列化策略与倾斜缓解下的吞吐与耗时变化。最后,用一段总结将“依赖类型—DAG—Stage—Shuffle—IO—容错—成本”的链路贯穿,让你不仅能“知道”,更能“讲清”和“用好”,在复杂数据规模与集群条件下,做出稳健的性能决策。
一、什么是 RDD 依赖:从逻辑血缘到执行边界
1.1 窄依赖(Narrow Dependency)
- 子分区依赖于少量父分区(通常 1 个),数据无需全局重分布。
- 常见算子:map、filter、mapPartitions、flatMap、union(特殊场景)、coalesce(非 shuffle)。
- 特征:可流水化(pipeline),错误恢复只需重算相关父分区,Stage 内深度融合算子,充分利用数据本地性。
1.2 宽依赖(Wide Dependency)
- 子分区依赖多个父分区,需要按 key 或分区规则重新划分(Shuffle)。
- 常见算子:groupByKey、reduceByKey、distinct、sortBy、cogroup、repartition、coalesce(shuffle 模式)。
- 特征:触发 Shuffle,切割 Stage 边界,伴随磁盘 IO、网络传输、排序与聚合,增加调度与容错开销。
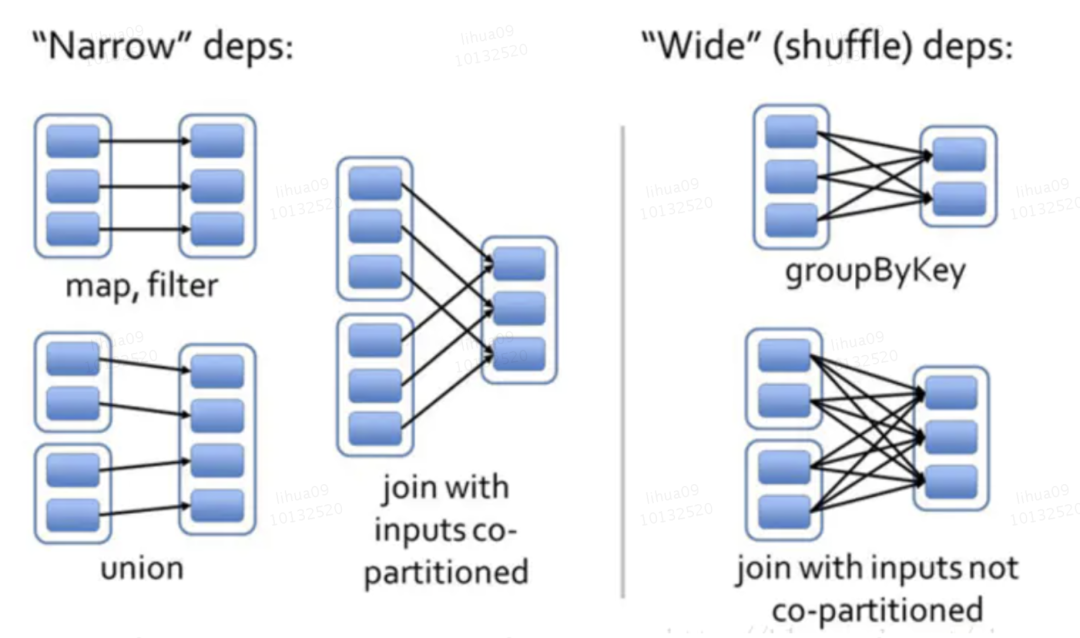
由上图就能很清晰的明白,宽依赖,窄依赖的区别就在于算子是否经过 shuffle 操作。那我们这里来讨论一个特殊的例子:join ——是宽依赖还是窄依赖?
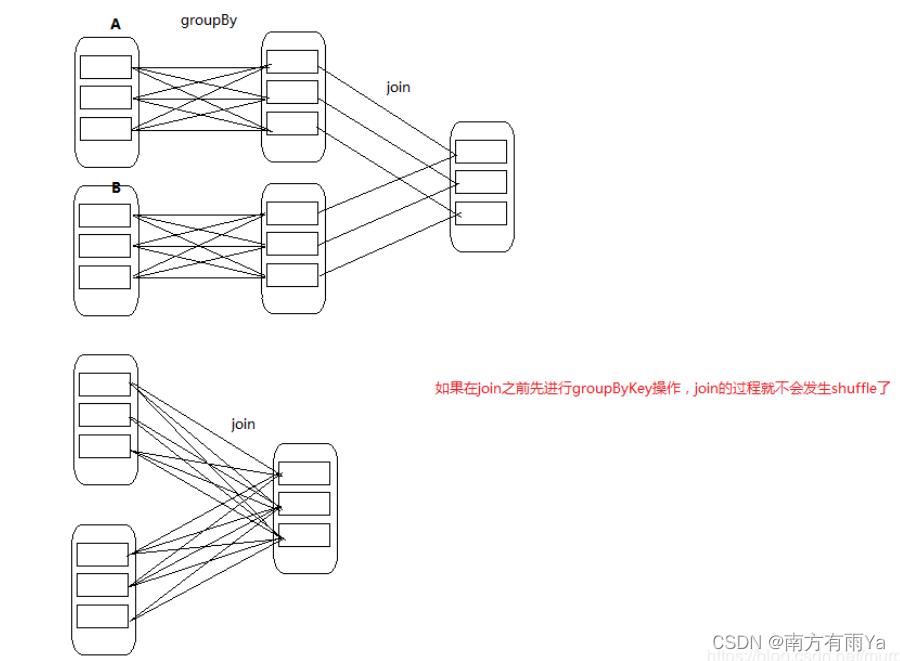
特殊地来说,join既可以是宽依赖,也可以是窄依赖,取决于join操作之前是否经过shuffle操作。(放两张其他大佬地图)
1.3 DAG 与 Stage 的关系
DAG——有向无环图,指的是数据转换执行的过程,有方向,无闭环(其实就是RDD执行的流程)原始的RDD通过一系列的转换操作就形成了DAG有向无环图,任务执行时,可以按照DAG的描述,执行真正的计算(数据被操作的一个过程)。一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action。
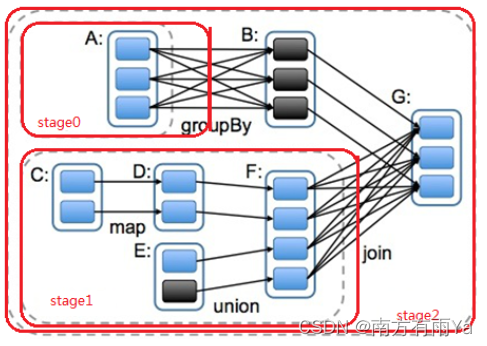
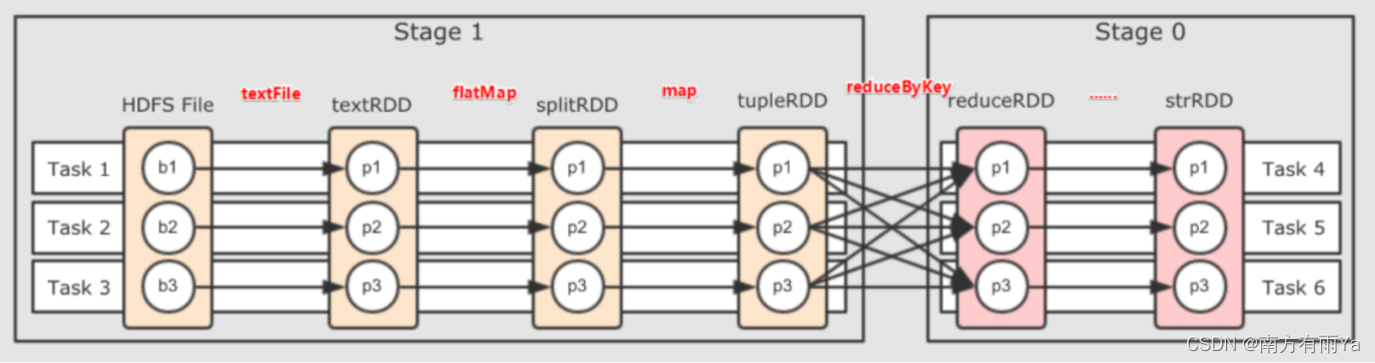
那么我们基于不同的依赖关系和和DAG的呈现,引入stage的概念。stage用于并行计算。一个复杂的业务逻辑经过shuffle计算,也就意味着要前端数据产生结果后才能继续运算,那么我们可以把一个DAG划分成多个stage,每当遇到一个shuffle就划分一个stage,当然,同一个stage间也可以有多个算子操作,形成一个pipeline流水线,就像下面这张图展示的一样
二、可视化理解:从流程到架构的多维图示
依赖链路与 Stage 切分;类型:flowchart;说明:展示窄/宽依赖如何影响 DAG 分段
Shuffle 时序交互;类型:sequenceDiagram;说明:Map 任务写本地,Reduce 任务拉取合并
集群架构视图;类型:architecture-beta;说明:Driver、Executors、Shuffle 服务与存储路径
执行时间占比;类型:pie;说明:示例作业中各阶段耗时分布
三、执行细节:Shuffle 的写读、排序与聚合
当我们谈论“宽依赖一定引发 Shuffle”时,往往只是笼统地把一整段复杂的系统行为归为一个黑箱。要把性能优化落到实处,就必须把这个黑箱拆开,沿着数据在集群中的旅程逐点审视:写(map 端生产中间结果)、读(reduce 端拉取并重建分区)、排(排序与合并)、合(聚合与去重),以及承载这些步骤的存储与网络组件的细节与参数。
3.1 Shuffle Write
分区决策与溢写:Map 任务在处理父 RDD 分区时,依据 Partitioner(默认 HashPartitioner,特定场景可能使用 RangePartitioner)为每条记录计算目标分区。记录经过序列化、可选压缩后写入内存缓冲。当缓冲或排序内存不足时触发 spill,溢写成多个临时文件。
// 示例:自定义分区器控制数据分布
class CustomPartitioner(numParts: Int) extends Partitioner {override def numPartitions: Int = numPartsoverride def getPartition(key: Any): Int = {// 根据业务逻辑自定义分区策略val hashCode = key.hashCode()Math.abs(hashCode % numPartitions)}
}// 使用自定义分区器
val rdd = sc.parallelize(Seq(("A", 1), ("B", 2), ("C", 3), ("A", 4)))
val partitionedRDD = rdd.partitionBy(new CustomPartitioner(2))// 查看分区效果
partitionedRDD.glom().collect()
// 结果:Array(Array((A,1), (A,4)), Array((B,2), (C,3)))
Sort-based Shuffle 与归并:现代 Spark 默认使用 Sort-based Shuffle。每次 spill 会生成一个有序段(按照分区、再按 key 排序)。任务结束前将多个段归并为最终的 map 输出文件,并写出索引(index)以标记每个目标分区的数据偏移与长度。这个归并过程受 spark.shuffle.sort.bypassMergeThreshold 等参数影响,小分区数场景可绕过归并走“直写”路径以减少开销。
// 关键参数配置示例
val conf = new SparkConf().set("spark.shuffle.file.buffer", "64k") // 写缓冲区大小.set("spark.shuffle.compress", "true") // 启用压缩.set("spark.shuffle.spill.compress", "true") // 溢写文件压缩.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // Kryo序列化.set("spark.shuffle.sort.bypassMergeThreshold", "200") // 小分区直写阈值val spark = SparkSession.builder().config(conf).getOrCreate()写路径关键参数:
spark.shuffle.file.buffer:map 端写文件的缓冲大小,过小导致频繁系统调用与碎片文件,过大则挤占内存。
spark.shuffle.compress 与 spark.shuffle.spill.compress:是否压缩中间数据与溢写文件;数据压缩可降网络和磁盘成本,但增加 CPU。
spark.serializer:序列化实现,Kryo 常优于 Java 序列化,尤其是对象结构复杂或数量庞大时。
度量指标与常见问题:在 Spark UI 中观察 Shuffle Write Size、Spill 数量、写耗时、每个 Map 任务输出文件大小分布。常见问题包括小文件过多(后续读放大)、溢写频繁(内存配置不当)、序列化慢(对象膨胀或实现低效)。
3.2 Shuffle Read
Map Output Tracker 与拉取并发:Driver 汇聚 Map 端的输出位置信息(mapStatus),Reduce 端任务据此并行从多个 Executor 或 External Shuffle Service 拉取数据块。拉取遵循“边拉边合并”的思路,避免一次性把所有块加载到内存。
拉取与缓冲:spark.reducer.maxSizeInFlight 控制拉取过程中的并发总量;spark.reducer.maxReqsInFlight 控制并发请求数;过小会降低带宽利用,过大可能挤压内存与触发频繁 GC。网络底层由 Netty 实现,相关参数决定连接与传输开销的平衡。
反序列化与排序合并:拉取到的数据块会被解压、反序列化,并根据是否需要排序(如需要按 key 排序或下游为 sortBy/reduce 语义)进入外排或内排流程。最终构建成目标分区的迭代器,为下游聚合或算子消费。
(1)拉取并发控制与参数优化:
// Shuffle Read关键参数配置
val conf = new SparkConf().set("spark.reducer.maxSizeInFlight", "48m") // 单次拉取数据量上限.set("spark.reducer.maxReqsInFlight", "10") // 并发拉取请求数.set("spark.shuffle.io.maxRetries", "3") // 网络重试次数.set("spark.shuffle.io.retryWait", "5s") // 重试等待时间.set("spark.shuffle.detectCorrupt", "true") // 数据损坏检测// 内存管理配置(统一内存管理).set("spark.memory.fraction", "0.6") // 执行和存储内存比例.set("spark.memory.storageFraction", "0.5") // 存储内存占比
(1)spark.shuffle.io.maxRetries 与 spark.shuffle.io.retryWait:网络波动或节点临时不可用时的重试容忍度。
(2)spark.storage.memoryFraction(旧参数)与统一内存管理:影响执行时可用于聚合/排序/缓存的内存比例。
(2)spark.shuffle.detectCorrupt:是否检测中间块损坏并触发重拉。
-度量与症状:Shuffle Read Size、Fetch Wait Time、Remote Reads 比例、反序列化时间。若 Fetch 等待长、失败重试多,常见原因是热点 Reduce 拉取集中、网络不均或个别 Map 输出异常。
(2)反序列化与数据重建示例:
// 自定义序列化器示例(扩展KryoSerializer)
class CustomKryoSerializer extends KryoSerializer {override def newKryo(): Kryo = {val kryo = super.newKryo()// 注册自定义类以提高序列化效率kryo.register(classOf[MyBusinessObject])kryo}
}// 在配置中使用自定义序列化器
val conf = new SparkConf().set("spark.serializer", "com.example.CustomKryoSerializer")3.3 排序与聚合:从无序全量到有序增量
(1)排序模型:对于需要顺序的操作(如 sortByKey),会进行全局 key 的排序重建,这往往是 CPU 与内存双高的环节。对于 reduceByKey 等聚合语义,核心不是排序本身,而是把相同 key 的值合并,排序只是帮助邻接相同 key 以便线性聚合(或者通过哈希聚合绕开严格排序)。
(2)Map-side Combine:reduceByKey 之所以优于 groupByKey,关键在于它隐式启用 map 端的预聚合,将相同 key 的多条记录先在本地合并,大幅降低跨节点数据量。这一行为由 Aggregator 驱动,combiner 的质量(如是否为结合律、是否易膨胀)直接影响效果。
(4)外排与内排:当内存不足以容纳全部中间状态时,会采用外部排序(External Sort),把中间段写盘再多路归并。参数如 spark.shuffle.file.buffer、序列化格式、压缩算法都会影响归并效率。
3.4 External Shuffle Service 与 BlockManager
BlockManager:是 Executor 本地数据块的管理者,负责 RDD 缓存、广播变量、Shuffle 块的读写与索引维护。其与内存管理器协作,决定了在执行时内存如何在“执行(Execution)与存储(Storage)”之间动态腾挪。
External Shuffle Service(ESS):当 Executor 因为资源弹性或失败而提前退出时,ESS 能持续对外提供 map 输出文件的服务,避免 Reduce 端找不到文件。ESS 也能减轻 Executor 进程本身的文件服务压力,提高作业稳定性。在部署上需要与集群管理器(如 YARN、K8s)协同配置端口、权限与磁盘路径。
推送式 Shuffle(Spark 3.2+):在 map 端将已完成的分区块主动推送到 reducer 侧的 merge 服务器,提前完成合并,减少长尾。虽然主要在 Spark SQL/Shuffle Manager 层体现,但其思想同样有助于理解“让数据靠近消费端”的价值。
四、代码与实践:识别依赖与减少 Shuffle
4.1 Java RDD: reduceByKey vs groupByKey 的性能对比
我们可以把这两种操作想象成两种不同的“统计选票”的方式。
reduceByKey:聪明的“各投票站先唱票”
工作方式:reduceByKey 就像每个投票站(计算节点/Executor)在把结果上报给总部之前,会先把自己站点的所有选票清点一遍。比如,A投票站收到了100张投给“候选人X”的票,它不会把这100张票都送走,而是直接上报一个数字:“候选人X,100票”。
为什么高效:这种“本地预聚合”(Map-side Combine)的方式,极大地减少了需要汇总到总部(Shuffle过程)的数据量。网络中传输的不再是海量的原始数据,而是每个节点预先计算好的中间结果。
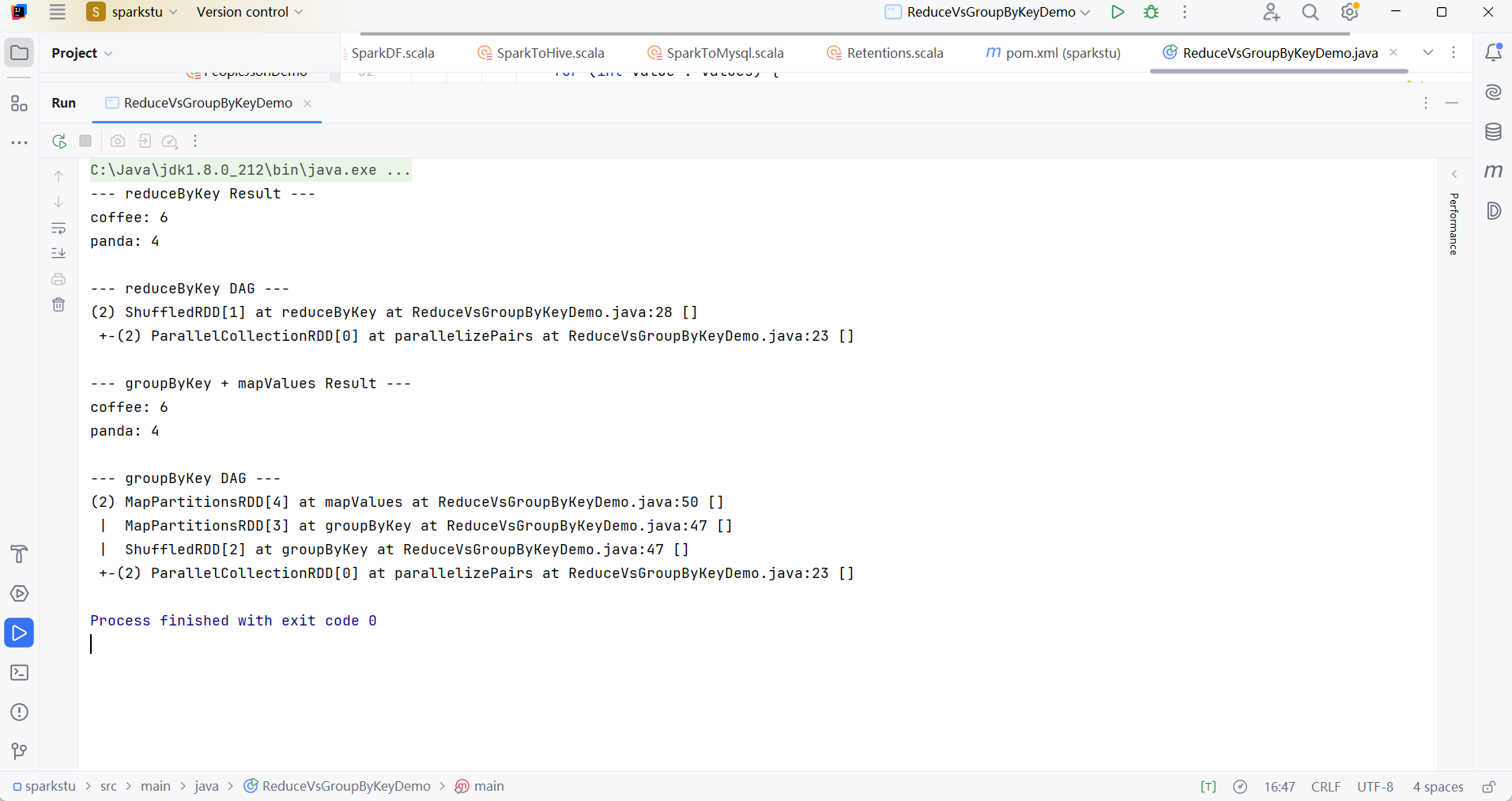
在代码中:reducedRDD.toDebugString() 的输出结果比较简短,你可以看到 ShuffledRDD 的上一步是一个 MapPartitionsRDD,这正是在 Shuffle 发生之前执行本地聚合的体现。
groupByKey:粗暴的“所有选票送总部”
工作方式:groupByKey 则像所有投票站把收到的每一张原始选票,都不加处理地直接用卡车运到总部。总部必须腾出巨大的仓库来接收来自全国各地的所有选票,然后再由一个工作人员来一张张地清点。
为什么低效:如果某个候选人是大热门,那么运送他选票的卡车会造成交通堵塞(网络拥堵),总部的仓库也可能被撑爆(Reducer内存溢出)。这个过程不仅传输了大量冗余数据,还给最终的计票工作带来了巨大的压力。
在代码中:summedRDD.toDebugString() 的执行计划(DAG)就更长一些。它清晰地显示,数据先通过 ShuffledRDD 进行了全量的数据移动,之后才通过 mapValues(另一个 MapPartitionsRDD)来进行聚合计算。这完美诠释了“先shuffle,后计算”的低效路径。
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;
import java.util.List;public class ReduceVsGroupByKeyDemo {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("ReduceVsGroupByKey").setMaster("local[*]");try (JavaSparkContext sc = new JavaSparkContext(conf)) {List<Tuple2<String, Integer>> data = Arrays.asList(new Tuple2<>("coffee", 1),new Tuple2<>("coffee", 2),new Tuple2<>("panda", 3),new Tuple2<>("coffee", 3),new Tuple2<>("panda", 1));JavaPairRDD<String, Integer> rdd = sc.parallelizePairs(data, 2); // 创建2个分区// --- 方案一:使用 reduceByKey (高效) ---// reduceByKey 会在 map 端(Shuffle write 之前)先进行一次本地的 reduce 操作。// 这样可以极大地减少需要通过网络传输到 reduce 端的数据量。JavaPairRDD<String, Integer> reducedRDD = rdd.reduceByKey((a, b) -> a + b);System.out.println("--- reduceByKey Result ---");reducedRDD.foreach(record -> System.out.println(record._1() + ": " + record._2()));System.out.println("\n--- reduceByKey DAG ---");// toDebugString() 会显示 RDD 的血缘关系。// 注意看输出中的 ShuffledRDD,它的依赖是 MapPartitionsRDD,这表明它在 Shuffle 前做了 map 端的处理。System.out.println(reducedRDD.toDebugString());/* 预期的 toDebugString() 输出类似:* (2) ShuffledRDD[2] at reduceByKey at ReduceVsGroupByKeyDemo.java:31 []* +-(2) MapPartitionsRDD[1] at parallelizePairs at ReduceVsGroupByKeyDemo.java:25 []* | ParallelCollectionRDD[0] at parallelizePairs at ReduceVsGroupByKeyDemo.java:25 []*/// --- 方案二:使用 groupByKey (低效) ---// groupByKey 会将所有分区中相同 key 的数据全部拉取到同一个 reduce task 中,// 形成 (key, Iterable<value>) 的结构。这个过程没有预聚合,网络开销和内存压力都很大。JavaPairRDD<String, Iterable<Integer>> groupedRDD = rdd.groupByKey();// 为了得到和 reduceByKey 一样的结果,还需要在 groupByKey 之后再做一次 map 操作。JavaPairRDD<String, Integer> summedRDD = groupedRDD.mapValues(values -> {int sum = 0;for (int value : values) {sum += value;}return sum;});System.out.println("\n--- groupByKey + mapValues Result ---");summedRDD.foreach(record -> System.out.println(record._1() + ": " + record._2()));System.out.println("\n--- groupByKey DAG ---");// 注意看这里的 DAG,MapPartitionsRDD 直接依赖于 ShuffledRDD,// ShuffledRDD 又依赖于 MapPartitionsRDD。这表明数据是先完整地 Shuffle,// 然后才在 reduce 端进行 mapValues 操作,中间没有预聚合。System.out.println(summedRDD.toDebugString());/* 预期的 toDebugString() 输出类似:* (2) MapPartitionsRDD[5] at mapValues at ReduceVsGroupByKeyDemo.java:50 []* | ShuffledRDD[4] at groupByKey at ReduceVsGroupByKeyDemo.java:47 []* +-(2) MapPartitionsRDD[1] at parallelizePairs at ReduceVsGroupByKeyDemo.java:25 []* | ParallelCollectionRDD[0] at parallelizePairs at ReduceVsGroupByKeyDemo.java:25 []*/}}
}
这里放一个运行结果:
4.2 Scala RDD:join 的宽依赖与 skew 缓解
意图与要点:
- join 按 key 重分布,是宽依赖典型代表。
- 用 salting 分流热点 key,减少倾斜。
- 按规模选择 repartition 或非 shuffle 的 coalesce。
// Scala 示例:宽依赖 join 与倾斜缓解
import org.apache.spark.{SparkConf, SparkContext}
val conf = new SparkConf().setAppName("JoinSkew").setMaster("local[*]")
val sc = new SparkContext(conf)val a = sc.parallelize(Seq(("k1", 1), ("hot", 2), ("k2", 3)), 3)
val b = sc.parallelize(Seq(("k1", "A"), ("hot", "B"), ("hot", "C")), 3)// 宽依赖:join 触发 Shuffle
val joined = a.join(b) // (key, (valA, valB))// 倾斜缓解:对热点 key 加盐分散
def salt(k: String): String = if (k == "hot") k + "_" + scala.util.Random.nextInt(10) else k
val aSalted = a.map{ case (k, v) => (salt(k), v) }
val bSalted = b.map{ case (k, v) => (salt(k), v) }val joinedSalted = aSalted.join(bSalted)// 去盐:示例简化
val normalized = joinedSalted.map{ case (sk, (x, y)) => (sk.split("_")(0), (x, y)) }// 分区:必要时进行 repartition(会 Shuffle)
val finalRdd = normalized.repartition(4)finalRdd.take(10).foreach(println)
sc.stop()
关键行点评:
- join 必然宽依赖,按 key 重分布引发 Shuffle。
- salting 分流热点,减轻 Reduce 端倾斜,代价是额外处理复杂度与数据还原。
- repartition 会 Shuffle;coalesce(不带 shuffle)适合减少分区用于下游窄依赖。
4.3 Java RDD:自定义分区器与两段聚合
意图与要点:
- 使用自定义分区器控制 key 到分区的映射。
- 两段聚合:map 端 combine + reduce 端汇总,降低跨节点数据量。
// Java 示例:自定义分区器与两段聚合(简化)
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.*;
import org.apache.spark.api.java.function.*;
import scala.Tuple2;
import org.apache.spark.HashPartitioner;public class CustomPartitionDemo {public static void main(String[] args) {SparkConf conf = new SparkConf().setAppName("CustomPartitionDemo").setMaster("local[*]");JavaSparkContext sc = new JavaSparkContext(conf);JavaPairRDD<String, Integer> rdd = sc.parallelizePairs(java.util.Arrays.asList(new Tuple2<>("k1", 1), new Tuple2<>("k2", 2), new Tuple2<>("hot", 5), new Tuple2<>("k1", 3)), 4);// 自定义分区器(示例用 HashPartitioner 代替)JavaPairRDD<String, Integer> partitioned = rdd.partitionBy(new HashPartitioner(4));// 两段聚合:combineByKey 等价 reduceByKey 的 map-side combine 特性JavaPairRDD<String, Integer> agg = partitioned.reduceByKey((a, b) -> a + b, 4);System.out.println(agg.collect());sc.close();}
}
关键行点评:
- partitionBy 显式控制分区布局,有助于本地性与均衡。
- reduceByKey 天生支持 map 端预聚合,组合自定义分区器提升效果。
- 代码侧简单,但需结合数据分布与倾斜情况评估分区数与策略。
五、参数与方案对比表(扩展版)
| 项目 | 窄依赖(map/filter 等) | 宽依赖(reduceByKey/join 等) | 关键参数 | 优化建议 |
|---|---|---|---|---|
| 是否 Shuffle | 否 | 是 | spark.shuffle.compress | 延后/减少 Shuffle 次数 |
| Stage 合并 | 可同一 Stage | 切分新 Stage | spark.shuffle.sort.bypassMergeThreshold | 调整算子顺序最大化流水化 |
| 容错成本 | 低,局部重算 | 高,需重做 Shuffle | spark.shuffle.file.buffer | persist/checkpoint 关键节点 |
| 数据倾斜 | 较小 | 显著 | spark.reducer.maxSizeInFlight | salting/自定义分区器/两段聚合 |
| IO 压力 | 低 | 高(磁盘+网络) | spark.io.compression.codec | 压缩、序列化优化、map-side combine |
| 分区策略 | coalesce(非 Shuffle) | repartition(Shuffle) | spark.default.parallelism | 按数据规模与核心数动态调整 |
| 序列化 | 开销小 | 影响明显 | spark.serializer=Kryo | 对象复杂时切换 Kryo 提升吞吐 |
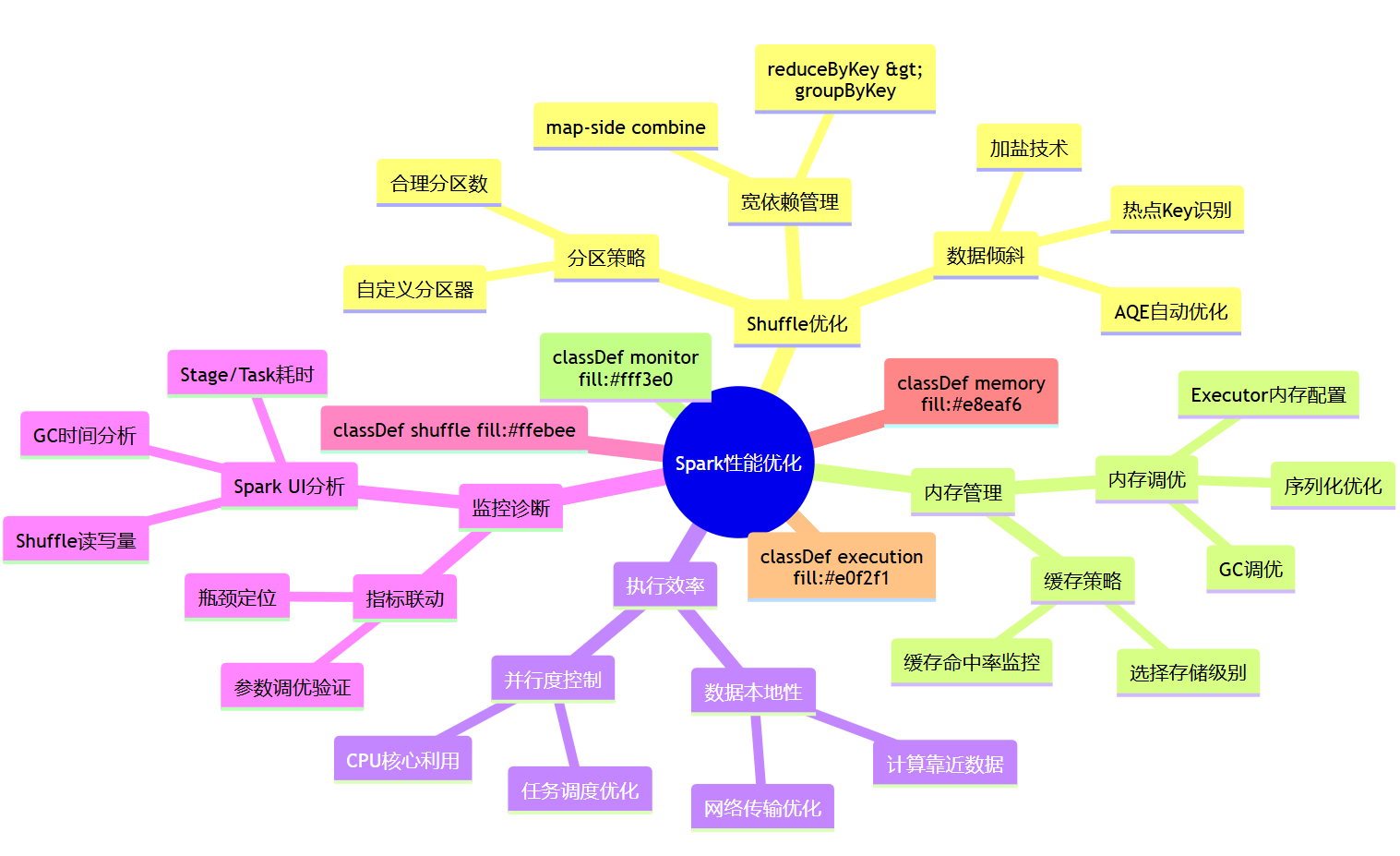
六、性能优化清单:把“知道”变成“做到”
在Spark性能调优的实践中,规避常见陷阱往往比掌握高深技巧更为关键。以下是对几个典型“坑”的解析与规避策略,旨在帮助您将“知道”转化为“做到”。
- 过早cache:无效的“保险”与内存的“刺客”
许多开发者习惯在数据加载后立即cache,但这常是陷阱。若上游数据或处理逻辑尚不稳定,cache一个“脏”数据,会在后续失败时导致缓存作废和完全重算。更危险的是,缓存一个庞大且仅使用一次的中间结果,会持续占用宝贵的Executor内存,可能挤出更重要的数据,并引发频繁的Full GC,最终拖慢整个应用。
规避策略: cache应用在“刀刃”上——那些计算昂贵、结果稳定且会被多次复用的关键节点。例如,在即将进行多次join或groupBy操作前,或在机器学习的迭代计算中。请务必在Spark UI的"Storage"页监控缓存命中率,果断移除低效、零命中的缓存点。
- groupByKey滥用:网络与内存的双重灾难
groupByKey是性能的头号杀手,其根源在于它从不进行任何本地预聚合。它会将一个Key对应的所有Value,不加处理地通过网络Shuffle到单一Reducer节点上,然后在内存中创建一个巨大的数据集合。这不仅会引起网络风暴,更会直接导致Reducer端内存溢出(OOM)。
规避策略: 只要你的业务逻辑包含对分组数据的聚合(如求和、计数等),就永远不要使用groupByKey。请使用自带Map端预聚合(Map-Side Combine)的高效算子:reduceByKey是首选,它能将Shuffle数据量降低几个数量级;功能更强大的aggregateByKey则提供了更高的灵活性。在DataFrame/SQL中,直接使用groupBy(…).agg(…),其底层的Catalyst优化器会自动生成最高效的预聚合执行计划。
- 分区数极端:从“并行不足”到“调度过载”
分区数是Spark并行度的“油门”,踩得太轻或太重都会出问题。分区过少,会导致大量CPU核心闲置,资源利用率低下,且单个任务处理的数据量过大,增加OOM风险。反之,分区过多,会给Driver带来巨大的调度压力,并且在数据写出时产生“小文件风暴”,为存储系统带来灾难。
规避策略: 一个合理的初始值是集群总CPU核心数的2-4倍。在运行时,可使用repartition来调整分区(会触发全量Shuffle),或用coalesce来高效地合并减少分区(避免全量Shuffle)。强烈建议开启Spark 3.x的AQE(自适应查询执行),它能在运行时动态合并或拆分分区,智能应对数据量变化。
- 忽视数据倾斜:被“长尾任务”拖垮的木桶
数据倾斜是指少数Key的数据量远超其他,导致处理这些Key的Task成为“长尾任务”,拖慢整个作业。
规避策略: 这是一个需要组合拳解决的复杂问题。首先,通过AQE的UI或代码定位倾斜的Key。核心解决思路是“分而治之”:通过加盐(Salting),给倾斜Key加上随机后缀,将其打散到多个Task中并行处理,最后再聚合去掉“盐”的结果。此外,Spark 3.x的AQE自带倾斜Join优化,应始终开启。对于大小表Join场景,优先考虑Broadcast Join,从根源上消除Shuffle。
- 参数只看单点:只见树木,不见森林
Spark性能是一个复杂的系统工程,参数间相互影响。孤立地调整单个参数,如只增加Executor内存,可能会忽略其对GC、并发度的连锁反应,导致“按下葫芦浮起瓢”。
规避策略: 采用科学的调优方法论:首先,用一套标准参数运行并建立性能基线。然后,通过Spark UI联动分析各项指标(如Task耗时、Shuffle量、GC时间),找到瓶颈并提出优化假设。最后,小步迭代,一次只改动一组相关参数,并与基线对比,验证调优效果。
七、总结:依赖类型串起性能链路
当我们把目光从算子微观实现抬升到“依赖类型—执行边界—资源开销”的宏观图谱,Spark 的性能逻辑会变得清楚而可操作。
窄依赖意味着局部性与流水化,能在同一 Stage 内顺畅推进,容错也更轻;宽依赖则带来数据重分布,一旦进入 Shuffle,网络、磁盘、排序与聚合的复杂成本叠加,调度与容错也随之变重。设计管线的首要策略,是尽量把代价留在本地:先过滤、先映射、先压缩,再将必须的聚合或连接放到后面,并采用 reduceByKey 等具备 map 端预聚合能力的算子降低跨节点传输。分区数决定并行度与倾斜程度,序列化与压缩决定传输与存储效率,cache/checkpoint 决定重复计算的边界与成本。
将这些因素联合评估与迭代,就能形成可复用的方法论:用 DAG 解读依赖结构,用 Stage 切分定位瓶颈,用 UI 指标与可视化做反馈调优,最终让每一次 Shuffle 都“有准备、有掌控”。需要强调的是,性能优化并非追求绝对数值,而是在数据特征、集群条件与业务目标下持续试验与权衡。坚持以依赖类型理解执行机理,以管线化策略减少远距离数据旅途,你的 Spark 作业才能在复杂环境中保持稳定、快速且可解释的表现,遇到瓶颈时也能有条不紊地定位、验证与修复。把握这条主线,性能将不再是偶然的好运,而是可预期的工程能力。
参考文献
Apache Spark 官方文档 - RDD Programming Guide
《Learning Spark, 2nd Edition》 - O’Reilly
Databricks Blog - Understanding Spark PartitioningDatabricks Blog - Understanding Spark Partitioning
关键词标签
#Spark #大数据优化 #分布式计算 #性能调优 #数据倾斜