【完整源码+数据集+部署教程】 路面落叶检测系统源码和数据集:改进yolo11-AggregatedAtt
背景意义
研究背景与意义
随着城市化进程的加快,城市道路的维护与管理面临着越来越多的挑战。尤其是在秋冬季节,落叶不仅影响道路的美观,还可能导致交通事故和行车安全隐患。因此,开发一种高效的路面落叶检测系统显得尤为重要。传统的人工检测方法不仅耗时耗力,而且容易受到天气、光照等因素的影响,准确性和效率难以保证。基于此,利用计算机视觉技术,尤其是深度学习算法,来实现自动化的落叶检测,成为了一个亟待解决的问题。
YOLO(You Only Look Once)系列算法因其高效的实时检测能力而受到广泛关注。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的推理速度,能够在复杂环境中实现高精度的目标检测。通过对YOLOv11的改进,可以更好地适应路面落叶的检测需求。我们的研究将专注于利用改进的YOLOv11模型,构建一个专门针对路面落叶的检测系统。
本研究所使用的数据集包含408张经过精心标注的落叶图像,且数据集的预处理和增强策略为模型的训练提供了良好的基础。通过对图像进行多种形式的增强,如随机旋转、亮度调整和噪声添加等,能够有效提高模型的鲁棒性和泛化能力。这一系统的成功实现,不仅可以提高路面落叶的检测效率,还能为城市管理者提供实时的数据支持,帮助其更好地进行道路维护和安全管理。
综上所述,基于改进YOLOv11的路面落叶检测系统的研究,不仅具有重要的理论意义,还有助于推动智能交通系统的发展,提升城市环境的管理水平。通过本项目的实施,期望能够为未来的智能城市建设提供有力的技术支持。
图片效果
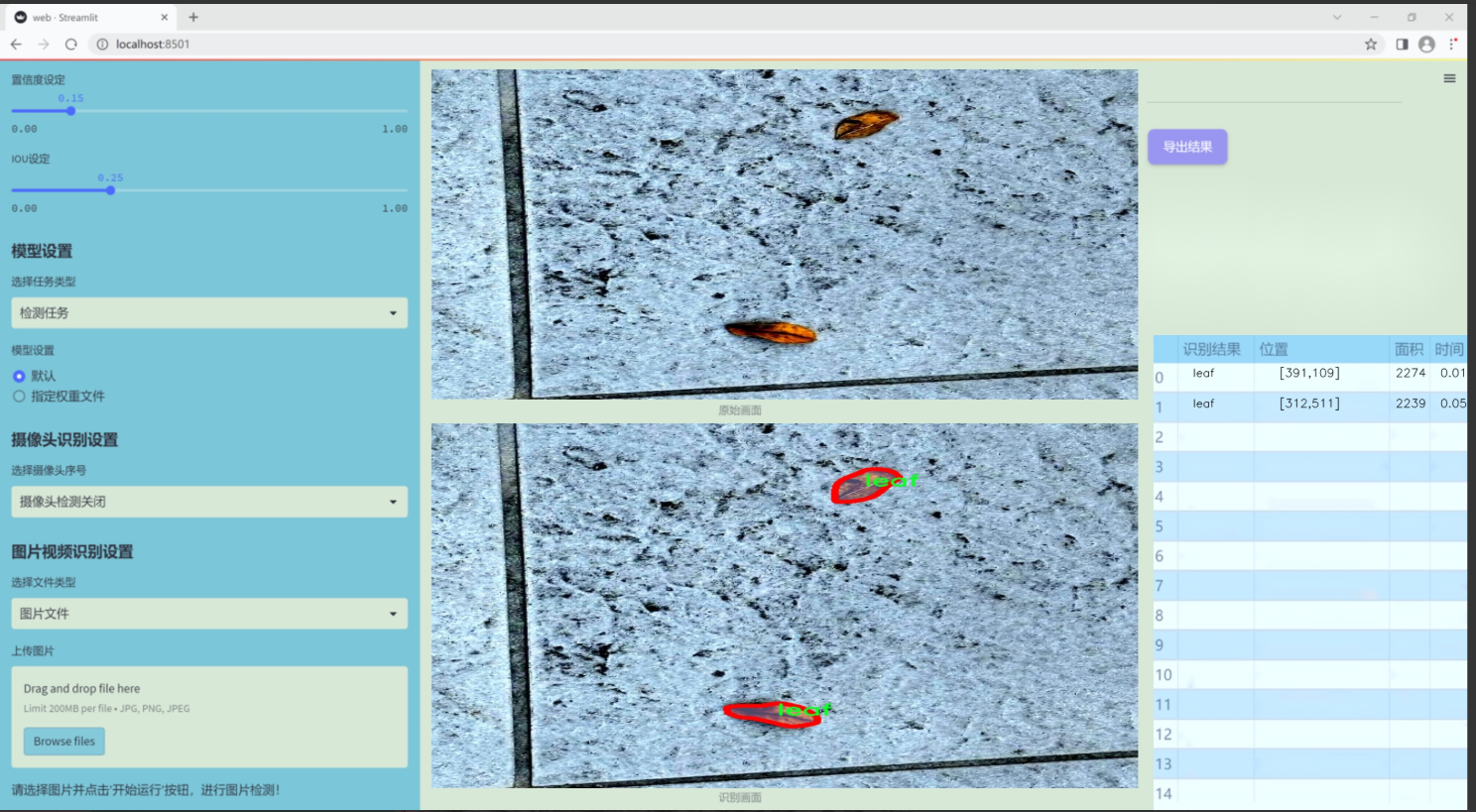
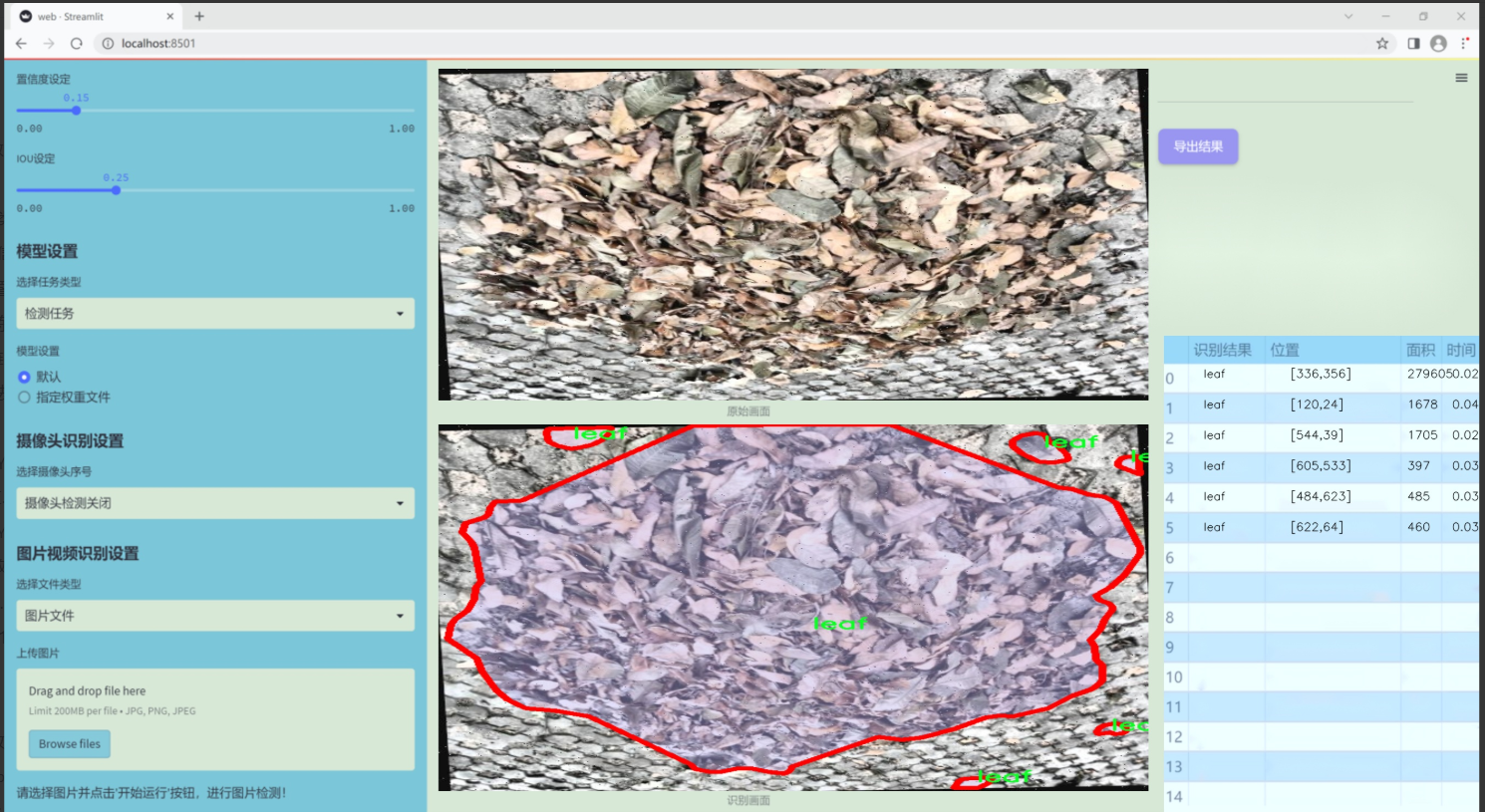
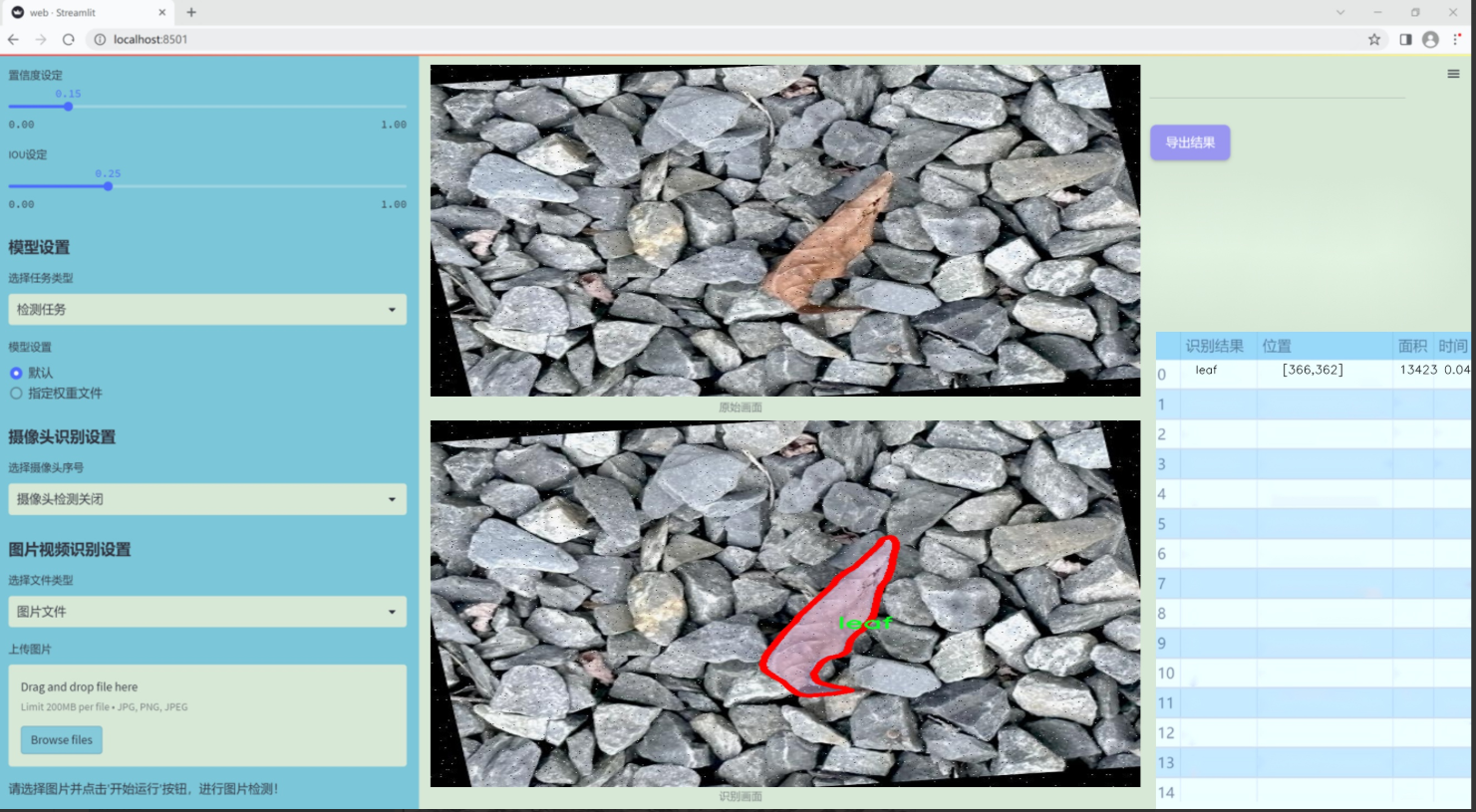
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的路面落叶检测系统,因此构建了一个专门针对“Fallen_leaf”主题的数据集。该数据集的设计考虑了落叶在不同环境和条件下的多样性,以确保模型能够在实际应用中具备良好的鲁棒性和准确性。数据集中包含了一个类别,即“leaf”,这意味着所有的标注和样本均围绕这一单一类别展开。尽管类别数量较少,但我们通过多样化的采集场景和拍摄条件,确保了数据集的丰富性和代表性。
在数据收集过程中,我们选择了多种不同的环境,包括城市公园、林间小道和校园等,力求涵盖不同种类的落叶和背景。这些场景的选择不仅考虑了视觉上的多样性,还注重了光照、天气变化及地面材质等因素对落叶检测的影响。数据集中包含的图像经过精心标注,确保每一片落叶都被准确地框定,以便于后续的模型训练和评估。
此外,为了增强模型的泛化能力,我们还对数据集进行了多种数据增强处理,包括旋转、缩放、翻转和颜色调整等。这些处理旨在模拟真实世界中可能遇到的各种情况,使得模型在面对不同的输入时能够保持高效的检测性能。通过这种方式,我们期望最终构建的路面落叶检测系统能够在多种环境下稳定运行,帮助实现更智能的城市管理和环境监测。





核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MF_Attention(nn.Module):
“”"
自注意力机制的实现,来源于Transformer。
“”"
def init(self, dim, head_dim=32, num_heads=None, qkv_bias=False,
attn_drop=0., proj_drop=0., proj_bias=False):
super().init()
# 设置每个头的维度和缩放因子self.head_dim = head_dimself.scale = head_dim ** -0.5# 计算头的数量self.num_heads = num_heads if num_heads else dim // head_dimif self.num_heads == 0:self.num_heads = 1# 计算注意力的总维度self.attention_dim = self.num_heads * self.head_dim# 定义Q、K、V的线性变换self.qkv = nn.Linear(dim, self.attention_dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop) # 注意力的dropoutself.proj = nn.Linear(self.attention_dim, dim, bias=proj_bias) # 输出的线性变换self.proj_drop = nn.Dropout(proj_drop) # 输出的dropoutdef forward(self, x):B, H, W, C = x.shape # 获取输入的批次大小、高度、宽度和通道数N = H * W # 计算总的像素数# 计算Q、K、Vqkv = self.qkv(x).reshape(B, N, 3, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)q, k, v = qkv.unbind(0) # 分离Q、K、V# 计算注意力权重attn = (q @ k.transpose(-2, -1)) * self.scale # 计算点积注意力attn = attn.softmax(dim=-1) # 归一化attn = self.attn_drop(attn) # 应用dropout# 计算输出x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.attention_dim) # 应用注意力权重x = self.proj(x) # 线性变换x = self.proj_drop(x) # 应用dropoutreturn x # 返回输出
class MetaFormerBlock(nn.Module):
“”"
MetaFormer块的实现,包含自注意力和MLP。
“”"
def init(self, dim,
token_mixer=nn.Identity, mlp=Mlp,
norm_layer=partial(LayerNormWithoutBias, eps=1e-6),
drop=0., drop_path=0.,
layer_scale_init_value=None, res_scale_init_value=None):
super().init()
# 归一化层self.norm1 = norm_layer(dim)# 令牌混合器self.token_mixer = token_mixer(dim=dim, drop=drop)# 路径丢弃self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()# 层缩放self.layer_scale1 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale1 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()# 第二个归一化层和MLPself.norm2 = norm_layer(dim)self.mlp = mlp(dim=dim, drop=drop)self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()self.layer_scale2 = Scale(dim=dim, init_value=layer_scale_init_value) if layer_scale_init_value else nn.Identity()self.res_scale2 = Scale(dim=dim, init_value=res_scale_init_value) if res_scale_init_value else nn.Identity()def forward(self, x):# 输入数据的维度转换x = x.permute(0, 2, 3, 1)# 第一部分:归一化 -> 混合 -> 路径丢弃 -> 层缩放x = self.res_scale1(x) + \self.layer_scale1(self.drop_path1(self.token_mixer(self.norm1(x))))# 第二部分:归一化 -> MLP -> 路径丢弃 -> 层缩放x = self.res_scale2(x) + \self.layer_scale2(self.drop_path2(self.mlp(self.norm2(x))))return x.permute(0, 3, 1, 2) # 返回输出并转换维度
代码核心部分解释:
MF_Attention 类实现了自注意力机制,主要通过计算输入的Q、K、V来获得注意力权重,并将其应用于值(V)上,最终输出经过线性变换和dropout的结果。
MetaFormerBlock 类实现了一个MetaFormer块,包含了自注意力和多层感知机(MLP)。它通过归一化、混合、路径丢弃和层缩放来处理输入数据,并在两个阶段中分别应用自注意力和MLP。
这个程序文件metaformer.py实现了一种名为MetaFormer的深度学习模型的多个组件,主要用于图像处理和计算机视觉任务。文件中使用了PyTorch库,定义了多个神经网络模块,以下是对这些模块的逐一说明。
首先,文件引入了一些必要的库,包括torch和torch.nn,以及一些函数和类,如partial、DropPath和to_2tuple。接着,定义了一些常用的模块,如Scale、SquaredReLU和StarReLU。Scale类用于对输入进行元素级别的缩放,SquaredReLU和StarReLU则是不同形式的激活函数,前者是对ReLU激活后的结果进行平方,后者则在ReLU的基础上加入了可学习的缩放和偏置。
接下来是MF_Attention类,它实现了标准的自注意力机制,通常用于Transformer模型中。该类通过线性变换生成查询、键和值,并计算注意力权重。注意力权重经过softmax处理后与值相乘,最终通过线性变换和dropout层输出结果。
RandomMixing类则实现了一种随机混合机制,通过一个随机矩阵对输入进行线性变换,增强模型的表达能力。
LayerNormGeneral类是一个通用的层归一化实现,支持不同的输入形状和归一化维度,允许用户选择是否使用缩放和偏置。LayerNormWithoutBias是一个优化版本,直接使用PyTorch的F.layer_norm函数,速度更快。
SepConv类实现了分离卷积,结合了逐点卷积和深度卷积的优点,通常用于减少参数量和计算量。Pooling类实现了一种特定的池化操作,返回输入与池化结果的差异。
Mlp类实现了多层感知机(MLP),包括两个线性层和激活函数,通常用于特征转换。ConvolutionalGLU类实现了一种卷积门控线性单元(GLU),结合了卷积和门控机制。
MetaFormerBlock和MetaFormerCGLUBlock类实现了MetaFormer的基本构建块。前者使用标准的MLP作为混合器,后者则使用卷积GLU。两个类都包含层归一化、残差连接和drop path机制,以增强模型的训练稳定性和性能。
总体来说,这个文件定义了一系列模块,旨在构建灵活且高效的MetaFormer模型,适用于各种计算机视觉任务。每个模块都经过精心设计,以便在不同的网络架构中进行组合和使用。
10.3 pkinet.py
以下是经过简化和注释的核心代码部分:
import math
import torch
import torch.nn as nn
定义DropPath类,用于随机丢弃路径(随机深度),通常用于残差块的主路径中
class DropPath(nn.Module):
“”“Drop paths (Stochastic Depth) per sample.”“”
def init(self, drop_prob: float = 0.1):
super().init()
self.drop_prob = drop_prob # 丢弃概率
def forward(self, x: torch.Tensor) -> torch.Tensor:# 如果丢弃概率为0或不在训练模式下,直接返回输入if self.drop_prob == 0. or not self.training:return xkeep_prob = 1 - self.drop_probshape = (x.shape[0], ) + (1, ) * (x.ndim - 1) # 处理不同维度的张量random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)output = x.div(keep_prob) * random_tensor.floor() # 应用丢弃return output
定义一个简单的卷积模块
class ConvModule(nn.Module):
def init(self, in_channels, out_channels, kernel_size, stride=1, padding=0, norm_cfg=None, act_cfg=None):
super().init()
layers = []
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding))
if norm_cfg:
layers.append(nn.BatchNorm2d(out_channels))
if act_cfg:
layers.append(getattr(nn, act_cfg[‘type’])())
self.conv = nn.Sequential(*layers)
def forward(self, x):return self.conv(x)
定义Poly Kernel Inception Block
class PKIBlock(nn.Module):
“”“Poly Kernel Inception Block”“”
def init(self, in_channels: int, out_channels: int):
super().init()
self.pre_conv = ConvModule(in_channels, out_channels, kernel_size=1) # 预卷积
self.dw_conv = ConvModule(out_channels, out_channels, kernel_size=3, stride=1, padding=1) # 深度卷积
self.pw_conv = ConvModule(out_channels, out_channels, kernel_size=1) # 点卷积
def forward(self, x):x = self.pre_conv(x) # 先进行预卷积x = self.dw_conv(x) # 深度卷积x = self.pw_conv(x) # 点卷积return x
定义Poly Kernel Inception Network
class PKINet(nn.Module):
“”“Poly Kernel Inception Network”“”
def init(self):
super().init()
self.stem = ConvModule(3, 32, kernel_size=3, stride=2, padding=1) # Stem层
self.block = PKIBlock(32, 64) # 添加一个PKIBlock
def forward(self, x):x = self.stem(x) # 通过Stem层x = self.block(x) # 通过PKIBlockreturn x
创建模型实例
def PKINET_T():
return PKINet()
主程序入口
if name == ‘main’:
model = PKINET_T() # 实例化模型
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
print(res.size()) # 输出结果的尺寸
代码注释说明:
DropPath类:实现了随机丢弃路径的功能,通常用于深度学习模型中的残差块,以减少过拟合。
ConvModule类:封装了卷积层、批归一化和激活函数的组合,简化了卷积层的创建过程。
PKIBlock类:实现了一个多核的Inception模块,包含预卷积、深度卷积和点卷积。
PKINet类:构建了一个简单的多核Inception网络,包含Stem层和一个PKIBlock。
主程序入口:实例化模型并进行前向传播,输出结果的尺寸。
这个程序文件 pkinet.py 实现了一个名为 PKINet 的深度学习模型,主要用于计算机视觉任务。该模型的结构基于多种卷积模块和注意力机制,旨在提高图像处理的性能。以下是对代码的详细讲解。
首先,文件导入了一些必要的库,包括数学库、类型提示、PyTorch 及其神经网络模块。接着,它尝试导入一些来自 mmcv 和 mmengine 的模块,如果导入失败,则使用 PyTorch 的基础模块作为替代。
接下来,定义了一些辅助函数和类。drop_path 函数实现了随机深度(Stochastic Depth)技术,用于在训练期间随机丢弃某些路径,以提高模型的泛化能力。DropPath 类是对这个函数的封装,方便在模型中使用。
autopad 函数用于自动计算卷积的填充,以确保输出尺寸与输入尺寸一致。make_divisible 函数则用于确保通道数是某个值的倍数,以便于模型的兼容性和性能。
接下来定义了一些用于数据格式转换的类,如 BCHW2BHWC 和 BHWC2BCHW,它们用于在不同的张量维度之间进行转换。
GSiLU 类实现了一种激活函数,即全局 Sigmoid 门控线性单元,能够自适应地调整特征图的激活值。
CAA 类实现了上下文锚点注意力机制,旨在增强特征图的表达能力。ConvFFN 类则实现了一个多层感知机(MLP),使用卷积模块构建。
Stem 和 DownSamplingLayer 类分别实现了模型的初始层和下采样层,负责特征图的初步处理和尺寸缩小。
InceptionBottleneck 类实现了一个瓶颈结构,结合了多个卷积操作,以提取多尺度特征。PKIBlock 类则是一个多核的 Inception 模块,集成了上下文锚点注意力和前馈网络。
PKIStage 类将多个 PKIBlock 组合在一起,形成模型的一个阶段。最后,PKINet 类则是整个网络的主类,负责构建网络的不同阶段,并定义前向传播过程。
在 PKINet 的构造函数中,定义了不同的网络架构设置,并根据输入参数构建相应的网络层。模型的权重初始化也在此处进行。
最后,文件提供了三个函数 PKINET_T、PKINET_S 和 PKINET_B,分别用于创建不同规模的 PKINet 模型。在主程序中,创建了一个 PKINET_T 模型实例,并通过随机生成的输入张量进行前向传播,输出每个阶段的特征图尺寸。
总体而言,这个文件实现了一个复杂的深度学习模型,结合了多种先进的技术,旨在提升计算机视觉任务的性能。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式