【完整源码+数据集+部署教程】 淡水鱼种类识别图像分割系统源码和数据集:改进yolo11-SDI
背景意义
研究背景与意义
随着全球淡水资源的日益紧张,淡水鱼类的保护与管理变得愈发重要。淡水鱼类不仅是生态系统的重要组成部分,也是人类食品链中不可或缺的资源。对淡水鱼种类的准确识别和分类,能够为生态保护、渔业管理以及水域生物多样性研究提供重要的科学依据。然而,传统的鱼类识别方法往往依赖于人工观察和专家知识,效率低下且容易受到主观因素的影响。因此,基于计算机视觉技术的自动化鱼类识别系统应运而生。
近年来,深度学习技术的迅猛发展为图像识别领域带来了革命性的变化,尤其是YOLO(You Only Look Once)系列算法在目标检测和图像分割任务中表现出色。YOLOv11作为该系列的最新版本,具备更高的准确性和实时性,适合于处理复杂的图像数据。在此背景下,基于改进YOLOv11的淡水鱼种类识别图像分割系统的研究显得尤为重要。
本项目所使用的数据集包含七种不同的淡水鱼类,包括Anabas、Clarias、Common Silver Carp、Nile Tilapia、Red Tilapia Fish、Siriped Catfish和Spotted Featherback,共计291张经过精确标注的图像。这些图像经过多种预处理和增强技术的处理,能够有效提高模型的鲁棒性和泛化能力。通过对这些鱼类进行高效的图像分割与识别,不仅可以提高淡水鱼类的监测效率,还能为渔业资源的可持续利用提供科学依据。
综上所述,基于改进YOLOv11的淡水鱼种类识别图像分割系统的研究,不仅具有重要的学术价值,也为实际应用提供了可行的解决方案。通过这一系统的开发与应用,能够推动淡水鱼类保护和管理的智能化进程,为生态环境的可持续发展贡献力量。
图片效果
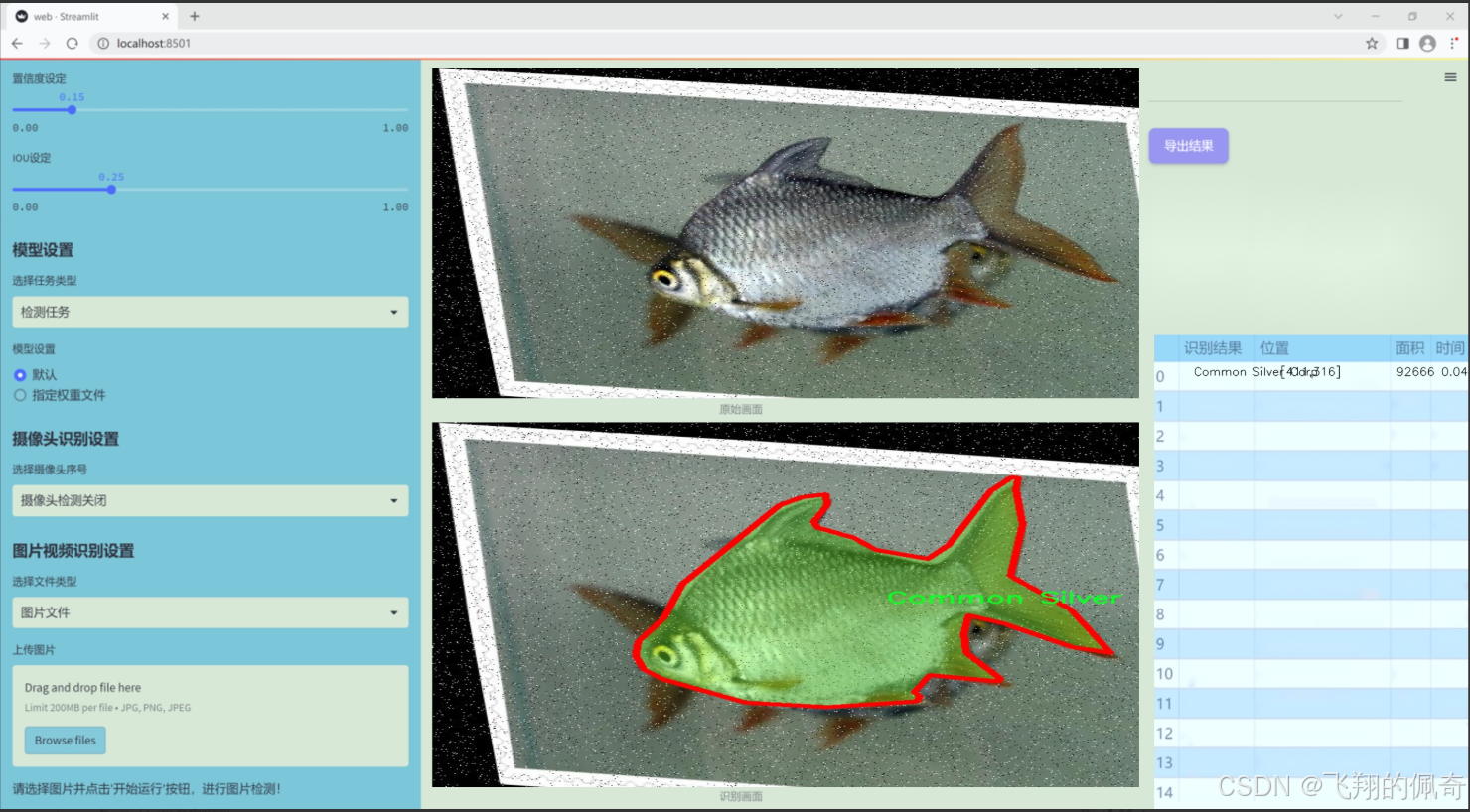
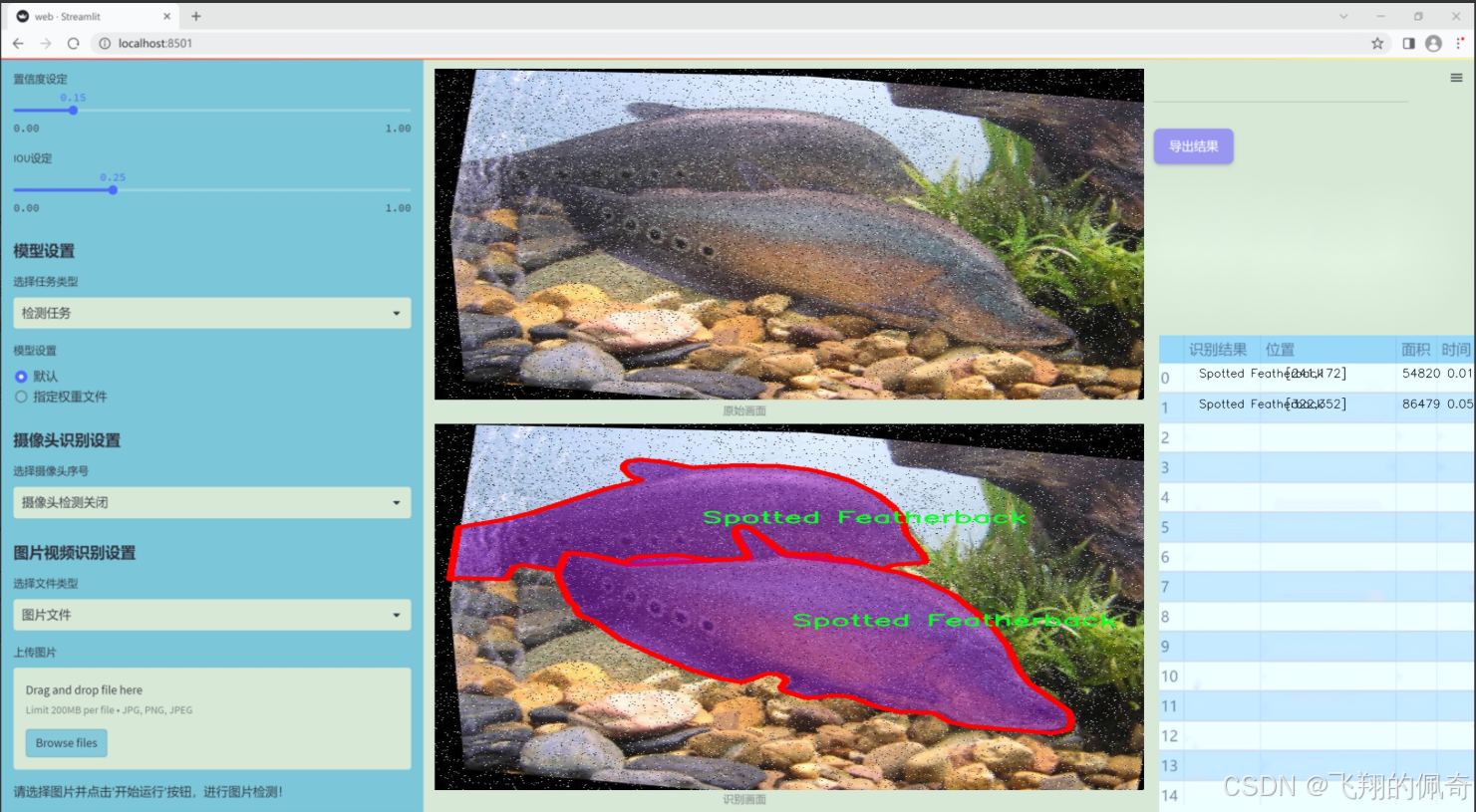
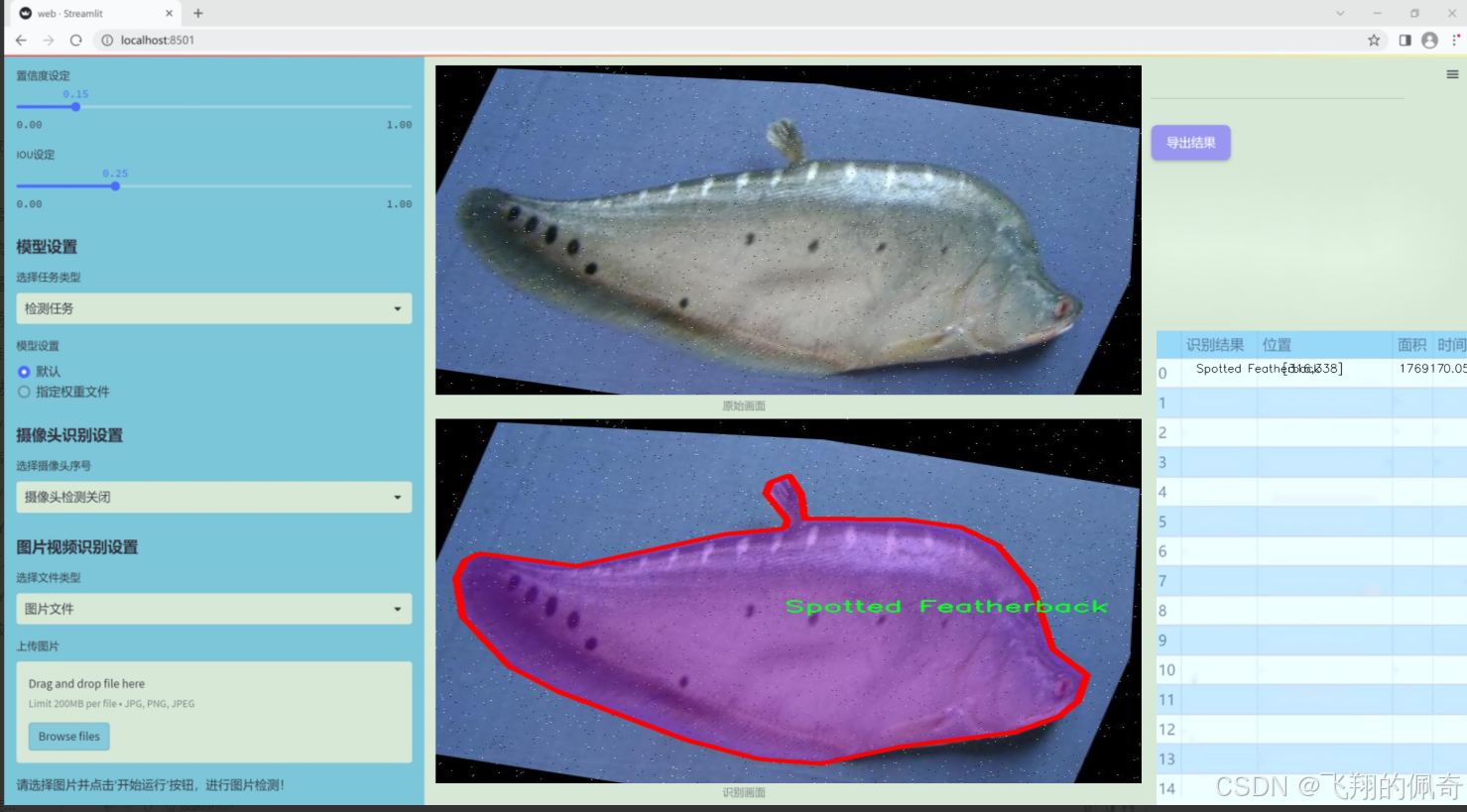
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11模型,构建一个高效的淡水鱼种类识别图像分割系统,以支持水产养殖、生态研究及生物多样性保护等领域的应用。为实现这一目标,我们构建了一个专门针对淡水鱼种类的图像数据集,涵盖了七个主要类别的鱼类。这些类别包括:Anabas、Clarias、Common Silver Carp、Nile Tilapia、Red Tilapia Fish、Siriped Catfish和Spotted Featherback。每个类别的选择都基于其在淡水生态系统中的重要性以及在水产养殖业中的经济价值,确保数据集的代表性和实用性。
数据集的构建过程经过精心设计,包含了多样化的图像样本,涵盖不同的拍摄角度、光照条件和背景环境,以提高模型的泛化能力。每个类别的图像均经过标注,确保在训练过程中能够准确识别和分割不同种类的淡水鱼。这种精细化的标注不仅有助于提高模型的识别精度,还为后续的研究提供了丰富的数据基础。
此外,为了提升模型的鲁棒性,数据集中还包括了部分鱼类在自然栖息环境中的图像,旨在模拟真实世界中的应用场景。这种多样化的训练数据将使得改进后的YOLOv11模型在实际应用中表现出更强的适应性和准确性,能够有效应对不同环境下的淡水鱼种类识别任务。
通过这一数据集的应用,我们期望能够推动淡水鱼种类识别技术的发展,为相关领域的研究和实践提供有力支持。





核心代码
以下是经过简化和注释的核心代码部分,主要包括Swin Transformer的基本结构和功能实现。
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Mlp(nn.Module):
“”" 多层感知机(MLP)模块 “”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_features # 输出特征数hidden_features = hidden_features or in_features # 隐藏层特征数self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换self.act = act_layer() # 激活函数self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换self.drop = nn.Dropout(drop) # Dropout层def forward(self, x):""" 前向传播 """x = self.fc1(x) # 线性变换x = self.act(x) # 激活x = self.drop(x) # Dropoutx = self.fc2(x) # 线性变换x = self.drop(x) # Dropoutreturn x
class WindowAttention(nn.Module):
“”" 窗口注意力机制模块 “”"
def __init__(self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.):super().__init__()self.dim = dim # 输入通道数self.window_size = window_size # 窗口大小self.num_heads = num_heads # 注意力头数head_dim = dim // num_heads # 每个头的维度self.scale = head_dim ** -0.5 # 缩放因子# 定义相对位置偏置参数self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads))# 计算相对位置索引coords_h = torch.arange(self.window_size[0])coords_w = torch.arange(self.window_size[1])coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成坐标网格coords_flatten = torch.flatten(coords, 1) # 展平坐标relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 调整维度relative_coords[:, :, 0] += self.window_size[0] - 1 # 偏移relative_coords[:, :, 1] += self.window_size[1] - 1relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1self.relative_position_index = relative_coords.sum(-1) # 相对位置索引self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # QKV线性变换self.attn_drop = nn.Dropout(attn_drop) # 注意力的Dropoutself.proj = nn.Linear(dim, dim) # 输出线性变换self.proj_drop = nn.Dropout(proj_drop) # 输出的Dropoutdef forward(self, x, mask=None):""" 前向传播 """B_, N, C = x.shape # B: 批量大小, N: 窗口内的token数, C: 特征维度qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)q, k, v = qkv[0], qkv[1], qkv[2] # 分离Q, K, Vq = q * self.scale # 缩放Qattn = (q @ k.transpose(-2, -1)) # 计算注意力权重# 添加相对位置偏置relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1)attn = attn + relative_position_bias.unsqueeze(0) # 添加偏置attn = F.softmax(attn, dim=-1) # softmax归一化attn = self.attn_drop(attn) # 注意力的Dropoutx = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出x = self.proj(x) # 线性变换x = self.proj_drop(x) # 输出的Dropoutreturn x
class SwinTransformer(nn.Module):
“”" Swin Transformer主干网络 “”"
def __init__(self, patch_size=4, in_chans=3, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):super().__init__()self.patch_embed = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim) # 图像到patch的嵌入self.layers = nn.ModuleList() # 存储每一层# 构建每一层for i_layer in range(len(depths)):layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),depth=depths[i_layer],num_heads=num_heads[i_layer],window_size=7) # 窗口大小固定为7self.layers.append(layer)def forward(self, x):""" 前向传播 """x = self.patch_embed(x) # 将输入图像转换为patchfor layer in self.layers:x = layer(x) # 逐层传递return x
其他辅助函数和类(如PatchEmbed, BasicLayer等)可以根据需要添加
代码说明
Mlp类:实现了一个简单的多层感知机,包含两个线性层和一个激活函数,支持Dropout。
WindowAttention类:实现了窗口注意力机制,支持相对位置偏置,计算Q、K、V并进行注意力计算。
SwinTransformer类:构建了Swin Transformer的主干网络,包含图像到patch的嵌入和多个基本层(BasicLayer)。
这些类和方法构成了Swin Transformer的核心结构,能够处理图像数据并提取特征。
这个程序文件实现了Swin Transformer模型,主要用于计算机视觉任务。Swin Transformer是一种基于变换器(Transformer)的架构,采用了分层的方式和窗口注意力机制,能够有效处理高分辨率图像。
首先,程序导入了必要的库,包括PyTorch和一些辅助函数。接着定义了一个多层感知机(Mlp)类,该类包含两个线性层和一个激活函数(默认为GELU),用于特征的非线性变换。
接下来,定义了窗口划分(window_partition)和窗口逆变换(window_reverse)函数。这两个函数用于将输入特征图划分为多个窗口,并在计算注意力后将结果合并回原来的特征图。
然后,定义了窗口注意力(WindowAttention)类,它实现了基于窗口的多头自注意力机制。该类支持相对位置偏置,并能够处理平移窗口的情况。注意力计算中使用了相对位置索引,以增强模型对局部特征的捕捉能力。
Swin Transformer的核心是Swin Transformer Block类,它由窗口注意力和前馈网络(FFN)组成。每个块包含层归一化、窗口注意力、残差连接和多层感知机。该类还支持在窗口之间进行循环移位,以增强模型的上下文捕捉能力。
PatchMerging类用于将特征图的patch进行合并,减少特征图的空间维度,同时增加通道数。BasicLayer类则是一个基本的Swin Transformer层,包含多个Swin Transformer Block,并在必要时进行下采样。
PatchEmbed类负责将输入图像划分为patch并进行嵌入,输出的特征图会被送入后续的Swin Transformer层。
SwinTransformer类是整个模型的主类,负责构建整个Swin Transformer架构。它定义了各个层的参数,并实现了前向传播的逻辑。模型支持绝对位置嵌入、随机深度、归一化等功能。
最后,程序中还定义了一个更新权重的函数,用于加载预训练模型的权重,并提供了一个SwinTransformer_Tiny函数,用于创建一个小型的Swin Transformer模型实例,并可选择性地加载权重。
整体来看,这个程序文件实现了Swin Transformer的完整结构,适用于图像分类、目标检测等视觉任务。
10.4 dynamic_snake_conv.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
class DySnakeConv(nn.Module):
def init(self, inc, ouc, k=3) -> None:
super().init()
# 初始化三个卷积层
self.conv_0 = Conv(inc, ouc, k) # 标准卷积
self.conv_x = DSConv(inc, ouc, 0, k) # 沿x轴的动态蛇形卷积
self.conv_y = DSConv(inc, ouc, 1, k) # 沿y轴的动态蛇形卷积
def forward(self, x):# 将三个卷积的输出在通道维度上拼接return torch.cat([self.conv_0(x), self.conv_x(x), self.conv_y(x)], dim=1)
class DSConv(nn.Module):
def init(self, in_ch, out_ch, morph, kernel_size=3, if_offset=True, extend_scope=1):
super(DSConv, self).init()
# 用于学习可变形偏移的卷积层
self.offset_conv = nn.Conv2d(in_ch, 2 * kernel_size, 3, padding=1)
self.bn = nn.BatchNorm2d(2 * kernel_size) # 批归一化
self.kernel_size = kernel_size
# 定义沿x轴和y轴的动态蛇形卷积self.dsc_conv_x = nn.Conv2d(in_ch, out_ch, kernel_size=(kernel_size, 1), stride=(kernel_size, 1), padding=0)self.dsc_conv_y = nn.Conv2d(in_ch, out_ch, kernel_size=(1, kernel_size), stride=(1, kernel_size), padding=0)self.gn = nn.GroupNorm(out_ch // 4, out_ch) # 组归一化self.act = Conv.default_act # 默认激活函数self.extend_scope = extend_scope # 扩展范围self.morph = morph # 卷积核的形态self.if_offset = if_offset # 是否需要偏移def forward(self, f):# 计算偏移量offset = self.offset_conv(f)offset = self.bn(offset)offset = torch.tanh(offset) # 将偏移量限制在[-1, 1]之间# 使用 DSC 类进行变形卷积dsc = DSC(f.shape, self.kernel_size, self.extend_scope, self.morph)deformed_feature = dsc.deform_conv(f, offset, self.if_offset)# 根据形态选择相应的卷积操作if self.morph == 0:x = self.dsc_conv_x(deformed_feature.type(f.dtype))else:x = self.dsc_conv_y(deformed_feature.type(f.dtype))x = self.gn(x) # 归一化x = self.act(x) # 激活return x
class DSC(object):
def init(self, input_shape, kernel_size, extend_scope, morph):
self.num_points = kernel_size # 卷积核的大小
self.width = input_shape[2] # 输入特征图的宽度
self.height = input_shape[3] # 输入特征图的高度
self.morph = morph # 卷积核的形态
self.extend_scope = extend_scope # 偏移范围
# 定义特征图的形状self.num_batch = input_shape[0] # 批次大小self.num_channels = input_shape[1] # 通道数def deform_conv(self, input, offset, if_offset):# 计算坐标图y, x = self._coordinate_map_3D(offset, if_offset)# 进行双线性插值,得到变形后的特征图deformed_feature = self._bilinear_interpolate_3D(input, y, x)return deformed_feature# 计算坐标图的函数
def _coordinate_map_3D(self, offset, if_offset):# 省略具体实现,主要是计算变形卷积所需的坐标pass# 进行双线性插值的函数
def _bilinear_interpolate_3D(self, input_feature, y, x):# 省略具体实现,主要是根据坐标进行插值pass
代码注释说明:
DySnakeConv 类:实现了一个动态蛇形卷积模块,包含三个卷积层,分别是标准卷积和两个动态蛇形卷积。
DSConv 类:实现了动态蛇形卷积的具体操作,包括偏移量的计算和特征图的变形。
DSC 类:负责计算变形卷积所需的坐标图和进行双线性插值。
forward 方法:定义了前向传播的逻辑,包含了卷积操作和激活函数的应用。
以上代码保留了核心逻辑,并添加了详细的中文注释以便理解。
这个程序文件 dynamic_snake_conv.py 实现了一个动态蛇形卷积(Dynamic Snake Convolution)模块,主要用于深度学习中的卷积操作。文件中定义了两个主要的类:DySnakeConv 和 DSConv,以及一个辅助类 DSC。
首先,DySnakeConv 类是一个卷积神经网络模块,继承自 nn.Module。在其构造函数中,初始化了三个卷积层:conv_0、conv_x 和 conv_y。其中,conv_0 是标准卷积,conv_x 和 conv_y 是动态蛇形卷积,分别沿着 x 轴和 y 轴进行操作。forward 方法接受输入张量 x,并将三个卷积的输出在通道维度上进行拼接,形成最终的输出。
接下来,DSConv 类实现了动态蛇形卷积的具体操作。它的构造函数接受输入通道数、输出通道数、卷积核大小、形态参数等。该类使用了一个偏移卷积层 offset_conv 来学习可变形的偏移量,并定义了两个卷积层 dsc_conv_x 和 dsc_conv_y,分别用于处理沿 x 轴和 y 轴的卷积。forward 方法首先计算偏移量,然后根据偏移量进行变形卷积,最后通过相应的卷积层和归一化层得到输出。
DSC 类是一个辅助类,负责处理卷积操作中的坐标映射和双线性插值。它的构造函数接受输入形状、卷积核大小、扩展范围和形态参数。该类的 _coordinate_map_3D 方法根据偏移量生成新的坐标映射,_bilinear_interpolate_3D 方法则根据生成的坐标对输入特征图进行双线性插值,得到变形后的特征图。最后,deform_conv 方法将这两个步骤结合起来,完成变形卷积的操作。
总体来说,这个文件实现了一个灵活的卷积模块,能够根据输入特征的变化动态调整卷积核的位置,从而增强模型对形状和结构变化的适应能力。该方法在计算机视觉任务中可能具有较好的性能,尤其是在处理具有复杂形状的图像时。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式