【完整源码+数据集+部署教程】 手部清洗步骤识别系统源码和数据集:改进yolo11-DRBNCSPELAN
背景意义
研究背景与意义
随着公共卫生意识的提高,手部清洗作为预防疾病传播的重要措施,越来越受到重视。尤其是在新冠疫情后,正确的手部清洗步骤被广泛推广,成为个人卫生的重要组成部分。然而,尽管手部清洗的重要性不言而喻,许多人在实际操作中仍存在误区,导致清洗效果不佳。因此,开发一个能够准确识别手部清洗步骤的系统,不仅能够帮助用户掌握正确的清洗方法,还能在公共卫生教育中发挥重要作用。
本研究旨在基于改进的YOLOv11模型,构建一个手部清洗步骤识别系统。该系统将利用一个包含7057张图像的数据集,数据集中涵盖了12个不同的手部清洗步骤,具体包括多个步骤的左右手操作。这种细致的分类将使得系统能够更准确地识别和指导用户完成每一个步骤,从而提升手部清洗的规范性和有效性。
在计算机视觉领域,YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而备受关注。通过对YOLOv11的改进,我们期望能够进一步提升模型在手部清洗步骤识别中的准确性和鲁棒性。数据集的构建和预处理环节也将为模型的训练提供坚实的基础。具体而言,数据集经过了多种增强处理,包括随机翻转、裁剪和旋转等,这将有助于提高模型的泛化能力,适应不同环境和用户的手部清洗习惯。
综上所述,本研究不仅具有重要的理论意义,还具备广泛的应用前景。通过构建一个智能化的手部清洗步骤识别系统,我们希望能够在提升公众卫生意识的同时,推动计算机视觉技术在健康领域的应用,为未来的公共卫生管理提供新的解决方案。
图片效果
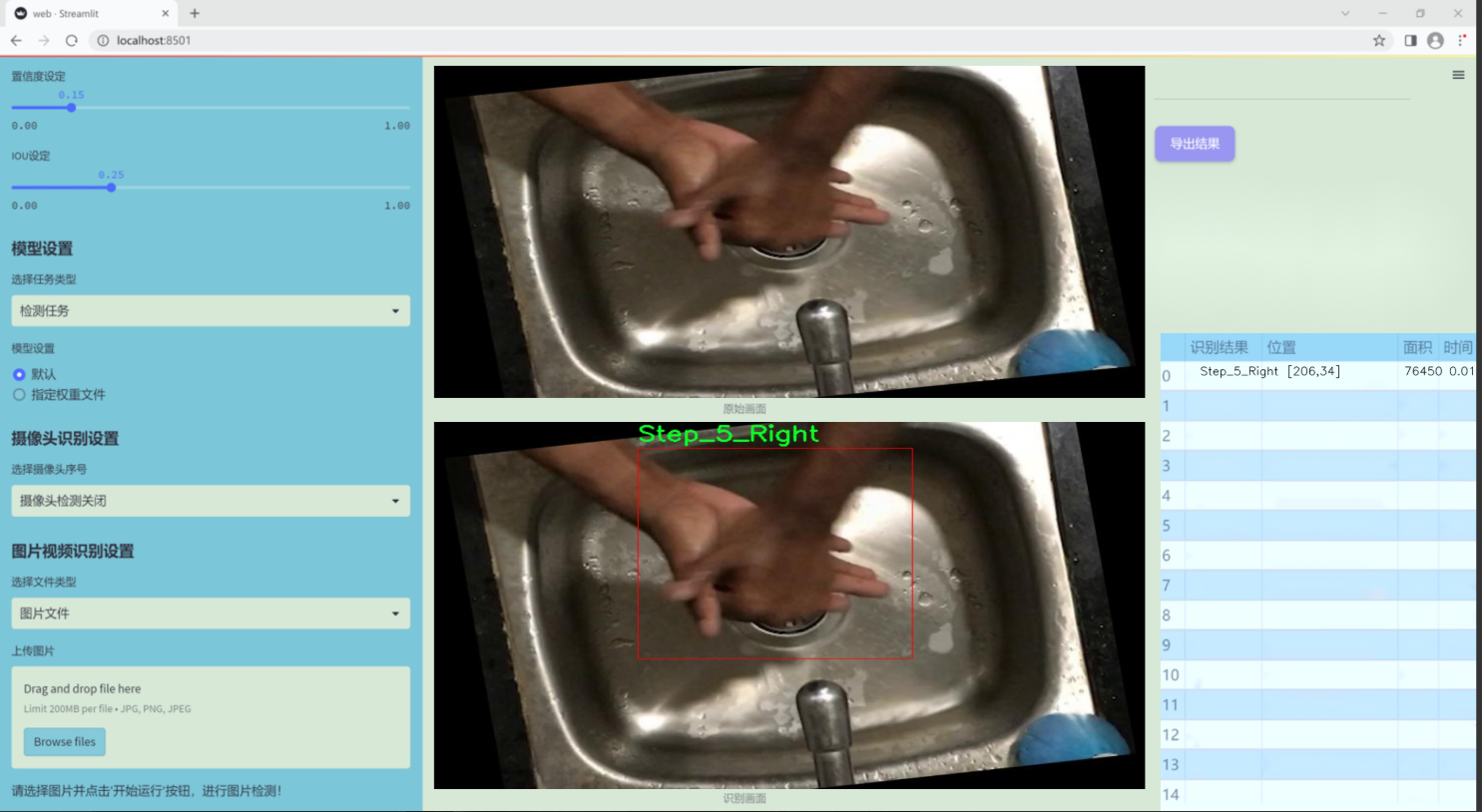


数据集信息
本项目数据集信息介绍
本项目所使用的数据集旨在为改进YOLOv11的手部清洗步骤识别系统提供强有力的支持。该数据集以“Steps auto data”为主题,专注于手部清洗过程中的各个步骤,通过精确的标注和丰富的样本,为模型的训练和评估奠定了坚实的基础。数据集中共包含12个类别,分别为‘Step_1’,‘Step_2_Left’,‘Step_2_Right’,‘Step_3’,‘Step_4_Left’,‘Step_4_Right’,‘Step_5_Left’,‘Step_5_Right’,‘Step_6_Left’,‘Step_6_Right’,‘Step_7_Left’和‘Step_7_Right’。这些类别细致地划分了手部清洗的不同步骤,确保模型能够在多样化的场景中准确识别和分类。
数据集的构建过程中,采用了多种数据采集手段,包括视频录制和图像捕捉,确保了数据的多样性和真实性。每个步骤的图像和视频样本均经过精确标注,以便于模型在训练时能够学习到每个步骤的独特特征。此外,数据集中还考虑了不同光照条件、背景环境和手部动作的变化,使得模型在实际应用中具备更强的鲁棒性和适应性。
通过对该数据集的深入分析与利用,研究团队期望能够显著提升YOLOv11在手部清洗步骤识别中的性能,进而推动相关领域的研究和应用。数据集的丰富性和系统性将为后续的模型优化和算法改进提供重要的数据支持,助力实现更高效的手部清洗过程监测与指导。





核心代码
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
from functools import partial
定义一个二维层归一化类
class LayerNorm2d(nn.Module):
def init(self, normalized_shape, eps=1e-6, elementwise_affine=True):
super().init()
# 使用 nn.LayerNorm 进行归一化
self.norm = nn.LayerNorm(normalized_shape, eps, elementwise_affine)
def forward(self, x):# 将输入的形状从 (B, C, H, W) 转换为 (B, H, W, C)x = x.permute(0, 2, 3, 1).contiguous()# 进行归一化x = self.norm(x)# 再将形状转换回 (B, C, H, W)x = x.permute(0, 3, 1, 2).contiguous()return x
自适应填充函数
def autopad(k, p=None, d=1):
“”“根据卷积核大小和填充要求自动计算填充大小”“”
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # 实际卷积核大小
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # 自动填充
return p
定义交叉扫描的自定义函数
class CrossScan(torch.autograd.Function):
@staticmethod
def forward(ctx, x: torch.Tensor):
B, C, H, W = x.shape
ctx.shape = (B, C, H, W)
xs = x.new_empty((B, 4, C, H * W)) # 创建一个新的张量
xs[:, 0] = x.flatten(2, 3) # 将输入展平
xs[:, 1] = x.transpose(dim0=2, dim1=3).flatten(2, 3) # 转置并展平
xs[:, 2:4] = torch.flip(xs[:, 0:2], dims=[-1]) # 翻转
return xs
@staticmethod
def backward(ctx, ys: torch.Tensor):B, C, H, W = ctx.shapeL = H * Wys = ys[:, 0:2] + ys[:, 2:4].flip(dims=[-1]).view(B, 2, -1, L)y = ys[:, 0] + ys[:, 1].view(B, -1, W, H).transpose(dim0=2, dim1=3).contiguous().view(B, -1, L)return y.view(B, -1, H, W)
定义选择性扫描的核心功能
class SelectiveScanCore(torch.autograd.Function):
@staticmethod
@torch.cuda.amp.custom_fwd
def forward(ctx, u, delta, A, B, C, D=None, delta_bias=None, delta_softplus=False, nrows=1, backnrows=1):
# 确保输入是连续的
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None and D.stride(-1) != 1:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if B.dim() == 3:
B = B.unsqueeze(dim=1)
ctx.squeeze_B = True
if C.dim() == 3:
C = C.unsqueeze(dim=1)
ctx.squeeze_C = True
ctx.delta_softplus = delta_softplus
ctx.backnrows = backnrows
# 调用 CUDA 核心进行前向计算
out, x, *rest = selective_scan_cuda_core.fwd(u, delta, A, B, C, D, delta_bias, delta_softplus, 1)
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out
@staticmethod
@torch.cuda.amp.custom_bwd
def backward(ctx, dout, *args):u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensorsif dout.stride(-1) != 1:dout = dout.contiguous()du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda_core.bwd(u, delta, A, B, C, D, delta_bias, dout, x, ctx.delta_softplus, 1)return (du, ddelta, dA, dB, dC, dD, ddelta_bias, None, None, None, None)
定义一个简单的卷积网络结构
class SimpleStem(nn.Module):
def init(self, inp, embed_dim, ks=3):
super().init()
self.hidden_dims = embed_dim // 2
self.conv = nn.Sequential(
nn.Conv2d(inp, self.hidden_dims, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(self.hidden_dims),
nn.GELU(),
nn.Conv2d(self.hidden_dims, embed_dim, kernel_size=ks, stride=2, padding=autopad(ks, d=1), bias=False),
nn.BatchNorm2d(embed_dim),
nn.SiLU(),
)
def forward(self, x):return self.conv(x)
定义一个用于特征融合的网络结构
class VisionClueMerge(nn.Module):
def init(self, dim, out_dim):
super().init()
self.hidden = int(dim * 4)
self.pw_linear = nn.Sequential(
nn.Conv2d(self.hidden, out_dim, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(out_dim),
nn.SiLU()
)
def forward(self, x):# 通过不同的下采样方式进行特征融合y = torch.cat([x[..., ::2, ::2],x[..., 1::2, ::2],x[..., ::2, 1::2],x[..., 1::2, 1::2]], dim=1)return self.pw_linear(y)
代码核心部分解释:
LayerNorm2d: 实现了对输入的二维数据进行层归一化,适用于图像数据。
autopad: 根据卷积核大小自动计算填充,以确保输出尺寸与输入相同。
CrossScan: 实现了交叉扫描操作,用于对输入特征进行变换和组合。
SelectiveScanCore: 实现了选择性扫描的前向和反向传播,主要用于优化模型的计算效率。
SimpleStem: 定义了一个简单的卷积网络,用于特征提取。
VisionClueMerge: 实现了特征融合的功能,通过不同的下采样方式合并特征图。
这些核心部分构成了模型的基础结构,适用于处理图像数据并进行特征提取和融合。
这个程序文件 mamba_yolo.py 实现了一个基于深度学习的模型,主要用于计算机视觉任务,尤其是目标检测。文件中定义了多个类和函数,构成了模型的各个组件。
首先,文件引入了必要的库,包括 torch、math、functools 和 typing 等。接着,定义了一个 LayerNorm2d 类,它是对二维数据进行层归一化的实现。这个类的 forward 方法通过调整输入张量的维度来应用层归一化。
接下来,定义了一个 autopad 函数,用于自动计算卷积操作所需的填充,以确保输出的形状与输入相同。然后,定义了 CrossScan 和 CrossMerge 类,这两个类分别实现了交叉扫描和交叉合并的功能,主要用于处理张量的不同维度。
在 SelectiveScanCore 类中,定义了一个选择性扫描的前向和反向传播方法,这一部分的实现涉及到 CUDA 的加速操作,适合处理大规模数据。cross_selective_scan 函数则是对选择性扫描的封装,提供了更高层次的接口。
接下来,定义了 SS2D 类,这是一个主要的模块,包含了多个子模块和参数初始化的逻辑。它使用了选择性扫描的机制来处理输入数据,并通过卷积层和线性层进行特征提取。
文件中还定义了 RGBlock 和 LSBlock 类,这些类实现了不同的块结构,分别用于特征变换和特征融合。XSSBlock 和 VSSBlock_YOLO 类则是更复杂的模块,结合了前面定义的组件,构成了更高层次的网络结构。
此外,SimpleStem 和 VisionClueMerge 类用于网络的输入处理和特征合并,分别实现了初始卷积和特征拼接的功能。
整体来看,这个文件构建了一个复杂的神经网络架构,利用了多种深度学习技术,如卷积、归一化、选择性扫描等,旨在提高计算机视觉任务的性能。
10.4 kacn_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
class KACNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, dropout=0.0):
super(KACNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的度数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # dropout层初始化为None# 如果dropout大于0,则根据维度选择相应的dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查groups的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 为每个组创建归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 创建多项式卷积层self.poly_conv = nn.ModuleList([conv_class((degree + 1) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 注册一个缓冲区,用于存储多项式的系数arange_buffer_size = (1, 1, -1,) + tuple(1 for _ in range(ndim))self.register_buffer("arange", torch.arange(0, degree + 1, 1).view(*arange_buffer_size))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.poly_conv:nn.init.normal_(conv_layer.weight, mean=0.0, std=1 / (input_dim * (degree + 1) * kernel_size ** ndim))def forward_kacn(self, x, group_index):# 对输入进行激活和线性变换x = torch.tanh(x) # 使用tanh激活函数x = x.acos().unsqueeze(2) # 计算反余弦并增加一个维度x = (x * self.arange).flatten(1, 2) # 乘以多项式系数并展平x = x.cos() # 计算余弦x = self.poly_conv[group_index](x) # 通过对应的卷积层x = self.layer_norm[group_index](x) # 归一化if self.dropout is not None:x = self.dropout(x) # 如果有dropout,则应用return xdef forward(self, x):# 将输入按组分割split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kacn(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone()) # 保存输出y = torch.cat(output, dim=1) # 将所有组的输出拼接return y
代码核心部分说明:
KACNConvNDLayer: 这是一个自定义的卷积层,支持多维卷积(1D, 2D, 3D),并且使用了多项式卷积的思想。
初始化方法: 该方法中初始化了输入输出维度、卷积参数、归一化层和多项式卷积层,并进行了参数有效性检查。
前向传播方法: forward_kacn 方法实现了对输入的处理,包括激活、变换、卷积和归一化。forward 方法则实现了对输入的分组处理,并将各组的输出拼接在一起。
这个程序文件定义了一个名为 kacn_conv.py 的深度学习模块,主要用于实现一种新的卷积层,称为 KACN(KACN是某种特定的卷积神经网络结构)。该模块使用 PyTorch 框架,包含了一个基类 KACNConvNDLayer 和三个子类,分别用于一维、二维和三维卷积。
在 KACNConvNDLayer 类的构造函数中,首先初始化了一些参数,包括输入和输出维度、卷积核大小、分组数、填充、步幅、扩张率、维度和 dropout 率。构造函数还会检查分组数的有效性以及输入和输出维度是否可以被分组数整除。接着,使用给定的归一化类和卷积类创建了相应的层,并将它们存储在 ModuleList 中。
forward_kacn 方法实现了 KACN 的前向传播逻辑。首先对输入进行激活,然后通过一系列的数学变换和卷积操作,最后应用归一化和 dropout(如果有的话)。该方法的输入包括数据和组索引,输出是经过处理的结果。
forward 方法则是对输入数据进行分组处理,针对每个组调用 forward_kacn 方法,并将结果拼接在一起返回。
此外,文件中还定义了三个子类:KACNConv3DLayer、KACNConv2DLayer 和 KACNConv1DLayer,它们分别用于实现三维、二维和一维卷积层。这些子类通过调用基类的构造函数,传入相应的卷积和归一化类,以及其他参数,简化了不同维度卷积层的实现。
整体来看,这个模块为 KACN 卷积层的实现提供了灵活的结构,支持多种维度的卷积操作,并通过归一化和 dropout 技术提高了模型的性能和稳定性。
源码文件
源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式