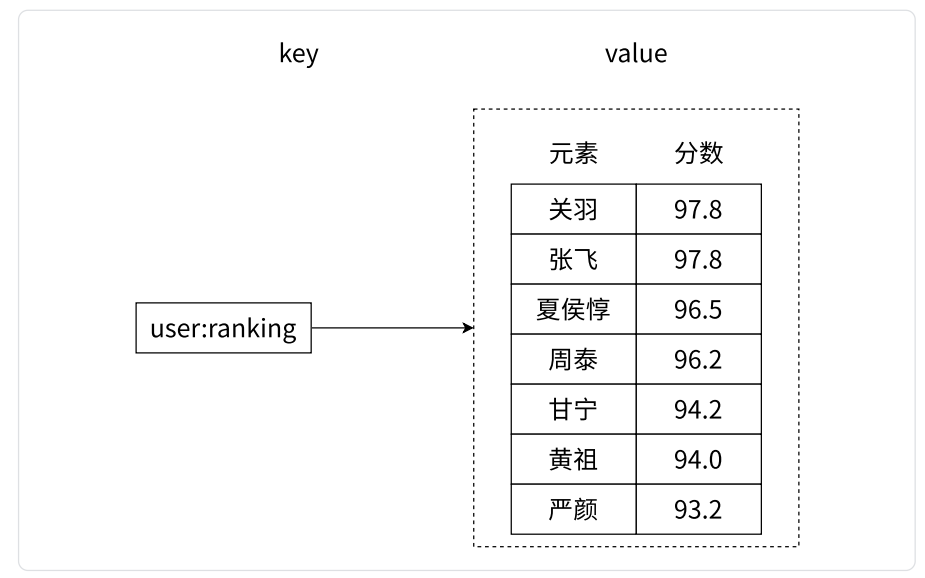
Redis-Zest
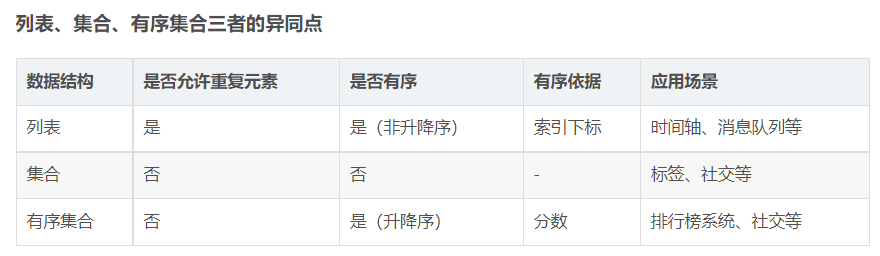
Zest有序集合
zest集合不能有重复成员特点,与集合不同的是,有序集合的每一个元素都有唯一一个浮点类型的分数跟value关联。有序集合的元素不能重复,但是关联的分数可以重复。
zset命令
zadd命令
添加或者更新指定元素以及关联的分数到zest中
ZADD key [NX | XX] [GT | LT] [CH] [INCR] score member [score member ...]
XX: 仅用于更新已经存在的元素,不会添加新元素。NX: 仅用于添加新元素,不会更新已经存在的元素。
LT:只更新已经存在的元素,如果新的分数比当前的分数小,成功,否则不更新GT:只更新已经存在的元素,如果新的分数比当前的分数大,成功,否则不更新CH: 默认情况下,ZADD 返回的是本次添加的元素个数,但指定这个选项之后,就会还包含本次更新的元素的个数。INCR: 此时命令会类似 ZINCRBY 的效果,将元素的分数加上指定的分数。此时只能指定一个元素和分数。
不添加NX和XX选项时,就会有同时有两个效果,member不存在时,会添加新的member进来,如果存在就会更新member的值。
Redis 的实际行为是:忽略无效的
IX选项,并将命令解析为普通的ZADD更新操作。也就是说,它会更新已存在成员的分数(如果成员存在),或添加新成员(如果成员不存在)。
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 1 "uno"
(integer) 0
redis> ZADD myzset 2 "two" 3 "three"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZADD myzset 10 one 20 two 30 three
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "10"
3) "two"
4) "20"
5) "three"
6) "30"
redis> ZADD myzset IX 100 one 200 two 300 three
(integer) 3
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "100"
3) "two"
4) "200"
5) "three"
6) "300"
redis> ZADD myzset XX 1 one 2 two 3 three 4 four 5 five
(integer) 0
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
7) "four"
8) "4"
9) "five"
10) "5"
redis> ZADD myzset -inf "negative infinity" +inf "positive infinity"
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "negative infinity"
2) "-inf"
3) "uno"
4) "1"
5) "one"
6) "2"
7) "two"
8) "20"
9) "three"
10) "30"
11) "four"
12) "4"
13) "five"
14) "5"
15) "positive infinity"
16) "inf"zcard命令
获取一个zest的基数,也就是zest的元素个数
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZCARD myzset
(integer) 2
zsocre命令
返回指定元素的分数
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZSCORE myzset "one"
"1"
zrank命令
按照元素的排名,升序形式
> ZADD leaderboard 1500 "player1" 2000 "player2" 1800 "player3" 1700 "player4"
(integer) 4> ZRANK leaderboard "player3"
(integer) 2 # player3在排行榜中是第三名> ZREVRANK leaderboard "player3"
(integer) 1 # 从高到低排序时,player3是第二名zrevrank命令
按照元素排名,降序形式,与zrank相反的结果
zrem命令
删除指定元素
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREM myzset "two"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"zincrby命令
指定元素对其关联的分数进行添加一个值
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZINCRBY myzset 2 "one"
"3"
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "one"
4) "3"
zrange命令
返回指定区间里的元素,分数按照升序,带上WITHSCORES可以把分数也返回
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
5) "three"
6) "3"
redis> ZRANGE myzset 0 -1
1) "one"
2) "two"
3) "three"
redis> ZRANGE myzset 2 3
1) "two"
2) "three"
redis> ZRANGE myzset -2 -1
1) "two"
2) "three"zrevrange命令
跟zrange命令相反,这里是按照降序
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREVRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
3) "two"
4) "2"
5) "one"
6) "1"
redis> ZREVRANGE myzset 0 -1
1) "three"
2) "two"
3) "one"
redis> ZREVRANGE myzset -2 -1
1) "two"
2) "one"zrangebyscore命令
返回分数在min和max之间的元素,max和min默认是闭合的
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZRANGEBYSCORE myzset -inf +inf
1) "one"
2) "two"
3) "three"
redis> ZRANGEBYSCORE myzset 1 2
1) "one"
2) "two"
redis> ZRANGEBYSCORE myzset (1 2
1) "two"
redis> ZRANGEBYSCORE myzset (1 (2
(empty array)zpopmax命令(zpopmin)
删除并返回分数最高的count个元素,若是有多个分数相同,则就按照字典值最大的返回(strcmp)
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZPOPMAX myzset
1) "three"
2) "3"
bzpopmax命令(bzpopmin)
zpopmax的阻塞版本
# 1. 正确添加数据
DEL zset1
ZADD zset1 10 "apple" 20 "banana" 30 "cherry"# 2. 阻塞弹出(立即返回,因有数据)
BZPOPMAX zset1 0
# 返回:1) "zset1" 2) "cherry" 3) "30"# 3. 空集合阻塞示例(需另开客户端插入数据测试)
DEL zset2
BZPOPMAX zset2 5 # 最多等待5秒
# 超时返回:(nil)
zcount命令
返回的分数在min和max之间的元素个数,min和max都是包含的,而要排除边界就要 (
命令示例 | 数学表示 | 匹配分数范围 | 匹配结果 |
|---|---|---|---|
| [1, 3] | 1 ≤ x ≤ 3 | one, two, three |
| (1, 3) | 1 < x < 3 | two |
| [1, 3) | 1 ≤ x < 3 | one, two |
| (1, 3) | 1 < x < 3 | two |
zremrangebyrank命令
按照排名以升序形式删除指定范围的元素,左闭有闭,rank是下标,以下标范围来指定范围
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYRANK myzset 0 1
(integer) 2
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "three"
2) "3"
zremrangebyscore命令
与zremrangebyrank不同,以分数来指定范围
redis> ZADD myzset 1 "one"
(integer) 1
redis> ZADD myzset 2 "two"
(integer) 1
redis> ZADD myzset 3 "three"
(integer) 1
redis> ZREMRANGEBYSCORE myzset -inf (2
(integer) 1
redis> ZRANGE myzset 0 -1 WITHSCORES
1) "two"
2) "2"
3) "three"
4) "3"
zinterstore命令
选中集合求集合元素的交集并保存到一个有序集合中
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
estination: 目标有序集合的名称。
numkeys: 输入有序集合的数量。
key: 输入有序集合的名称。
[WEIGHTS weight [weight ...]]: 为每个输入有序集合指定一个权重。
[AGGREGATE <SUM | MIN | MAX>]: 指定分数聚合方式。
这里需要numkeys的理由就像http协议需要在报头位置提供这个报文的总大小
-- 清除可能存在的旧数据
DEL zset1 zset2 result1 result2 result3 result4 result5-- 创建两个有序集合作为测试数据
ZADD zset1 10 "apple" 20 "banana" 30 "cherry"
ZADD zset2 15 "banana" 25 "cherry" 35 "date"-- 查看原始数据
ECHO "==== 原始数据 ===="
ECHO "zset1:"
ZRANGE zset1 0 -1 WITHSCORES
ECHO "zset2:"
ZRANGE zset2 0 -1 WITHSCORES-- 示例1:基本交集运算(默认SUM聚合)
ECHO "\n==== 示例1:基本交集(SUM)===="
ZINTERSTORE result1 2 zset1 zset2
ZRANGE result1 0 -1 WITHSCORES-- 示例2:带权重的交集(zset1×2,zset2×3)
ECHO "\n==== 示例2:带权重(2和3)===="
ZINTERSTORE result2 2 zset1 zset2 WEIGHTS 2 3
ZRANGE result2 0 -1 WITHSCORES-- 示例3:MIN聚合方式(取较小值)
ECHO "\n==== 示例3:MIN聚合 ===="
ZINTERSTORE result3 2 zset1 zset2 AGGREGATE MIN
ZRANGE result3 0 -1 WITHSCORES-- 示例4:MAX聚合方式(取较大值)
ECHO "\n==== 示例4:MAX聚合 ===="
ZINTERSTORE result4 2 zset1 zset2 AGGREGATE MAX
ZRANGE result4 0 -1 WITHSCORES-- 示例5:权重+MAX聚合组合
ECHO "\n==== 示例5:权重(1,2)+MAX ===="
ZINTERSTORE result5 2 zset1 zset2 WEIGHTS 1 2 AGGREGATE MAX
ZRANGE result5 0 -1 WITHSCORES结果
==== 原始数据 ====
zset1:
1) "apple"
2) "10"
3) "banana"
4) "20"
5) "cherry"
6) "30"
zset2:
1) "banana"
2) "15"
3) "cherry"
4) "25"
5) "date"
6) "35"==== 示例1:基本交集(SUM)====
1) "banana"
2) "35"
3) "cherry"
4) "55"==== 示例2:带权重(2和3)====
1) "banana"
2) "85"
3) "cherry"
4) "135"==== 示例3:MIN聚合 ====
1) "banana"
2) "15"
3) "cherry"
4) "25"==== 示例4:MAX聚合 ====
1) "banana"
2) "20"
3) "cherry"
4) "30"==== 示例5:权重(1,2)+MAX ====
1) "banana"
2) "30"
3) "cherry"
4) "50"zunionstore命令
选中的集合以合集形式存储在新的有序集合中
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE <SUM | MIN | MAX>]
estination: 目标有序集合的名称。
numkeys: 输入有序集合的数量。需要有这个字段是因为 numkeys 描述出 key 的个数之后,就可以明确的知道,后面的“选项”是从哪里开始的,避免选项和 keys 混淆!
key: 输入有序集合的名称。
[WEIGHTS weight [weight ...]]: 为每个输入有序集合指定一个权重。
[AGGREGATE <SUM | MIN | MAX>]: 指定分数聚合方式。
-- 清除可能存在的旧数据
DEL zset1 zset2 result1 result2 result3 result4 result5-- 创建两个有序集合作为测试数据
ZADD zset1 10 "apple" 20 "banana" 30 "cherry"
ZADD zset2 15 "banana" 25 "cherry" 35 "date"-- 查看原始数据
ECHO "==== 原始数据 ===="
ECHO "zset1:"
ZRANGE zset1 0 -1 WITHSCORES
ECHO "zset2:"
ZRANGE zset2 0 -1 WITHSCORES-- 示例1:基本并集运算(默认SUM聚合)
ECHO "\n==== 示例1:基本并集(SUM)===="
ZUNIONSTORE result1 2 zset1 zset2
ZRANGE result1 0 -1 WITHSCORES-- 示例2:带权重的并集(zset1×2,zset2×3)
ECHO "\n==== 示例2:带权重(2和3)===="
ZUNIONSTORE result2 2 zset1 zset2 WEIGHTS 2 3
ZRANGE result2 0 -1 WITHSCORES-- 示例3:MIN聚合方式(取较小值)
ECHO "\n==== 示例3:MIN聚合 ===="
ZUNIONSTORE result3 2 zset1 zset2 AGGREGATE MIN
ZRANGE result3 0 -1 WITHSCORES-- 示例4:MAX聚合方式(取较大值)
ECHO "\n==== 示例4:MAX聚合 ===="
ZUNIONSTORE result4 2 zset1 zset2 AGGREGATE MAX
ZRANGE result4 0 -1 WITHSCORES-- 示例5:权重+MAX聚合组合
ECHO "\n==== 示例5:权重(1,2)+MAX ===="
ZUNIONSTORE result5 2 zset1 zset2 WEIGHTS 1 2 AGGREGATE MAX
ZRANGE result5 0 -1 WITHSCORES结果
==== 原始数据 ====
zset1:
1) "apple"
2) "10"
3) "banana"
4) "20"
5) "cherry"
6) "30"
zset2:
1) "banana"
2) "15"
3) "cherry"
4) "25"
5) "date"
6) "35"==== 示例1:基本并集(SUM)====
1) "apple"
2) "10"
3) "date"
4) "35"
5) "banana"
6) "35"
7) "cherry"
8) "55"==== 示例2:带权重(2和3)====
1) "apple"
2) "20"
3) "date"
4) "105"
5) "banana"
6) "85"
7) "cherry"
8) "135"==== 示例3:MIN聚合 ====
1) "apple"
2) "10"
3) "date"
4) "35"
5) "banana"
6) "15"
7) "cherry"
8) "25"==== 示例4:MAX聚合 ====
1) "apple"
2) "10"
3) "date"
4) "35"
5) "banana"
6) "20"
7) "cherry"
8) "30"==== 示例5:权重(1,2)+MAX ====
1) "apple"
2) "10"
3) "date"
4) "70"
5) "banana"
6) "30"
7) "cherry"
8) "50"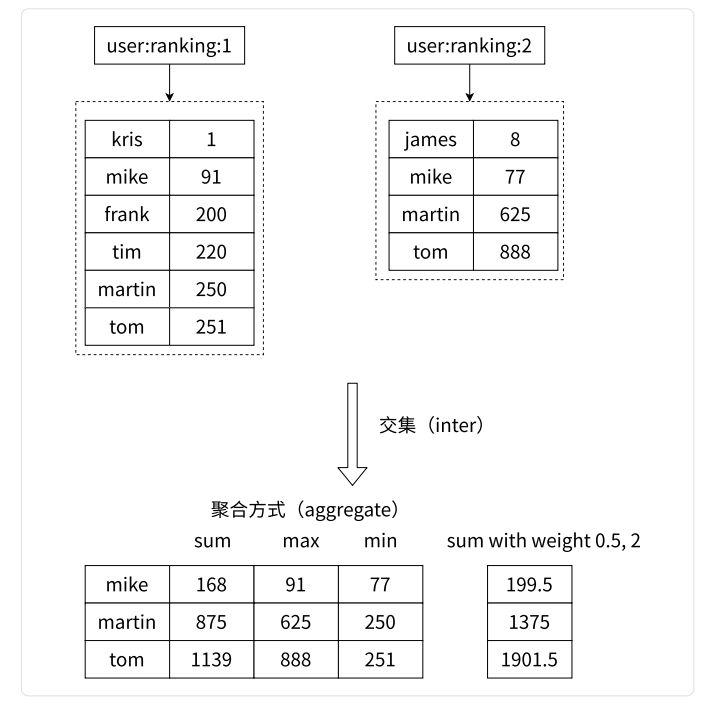
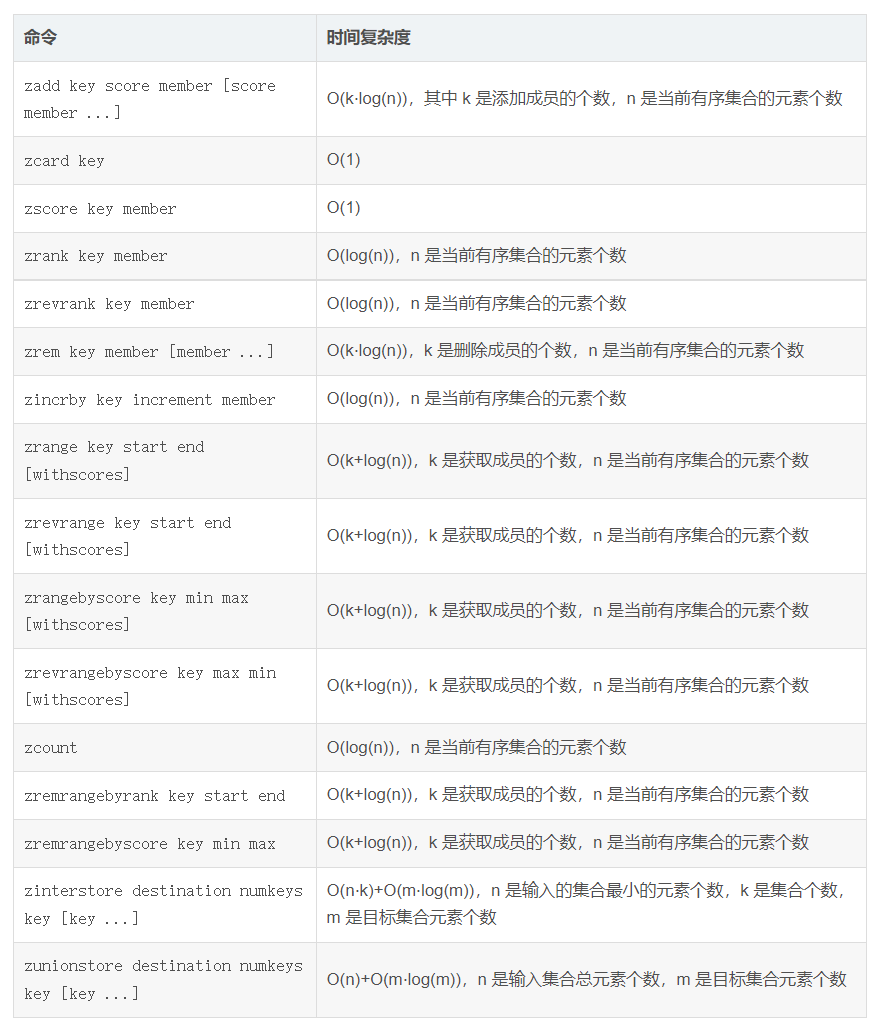
命令总结
内部编码
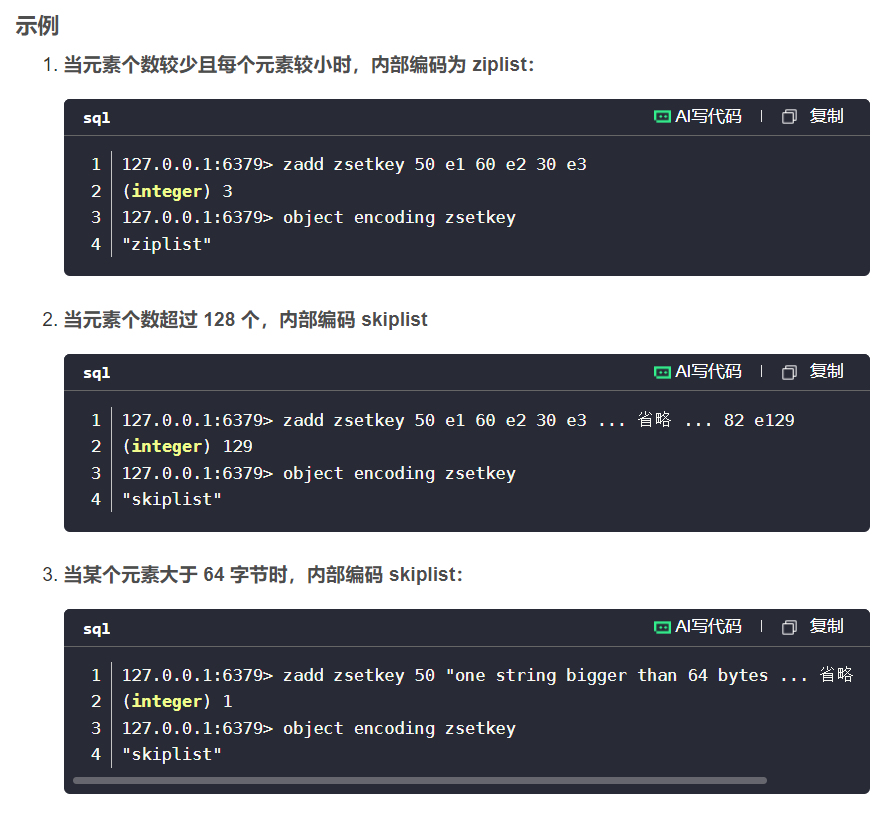
1.ziplist压缩列表:
当有序集合的元素个数小于 zset-max-ziplist-entries 配置(默认 128 个),同时每个元素的值都小于 zset-max-ziplist-value 配置(默认 64 字节)时,Redis 会用 ziplist 来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
2.skiplist跳表:
当 ziplist 条件不满足时,有序集合会使用 skiplist 作为内部实现,因为此时 ziplist 的操作效率会下降。
使用场景
排行榜系统
微博热搜
根据话题的热度(如浏览量、点赞量、转发量、评论量等)进行排行,热度是实时变化的,需要高效更新排行。
热度是一个综合数值,由多个维度加权计算得出。
游戏天梯排行
根据玩家的天梯积分进行排序,玩家的分数会随着游戏结果实时变化,需要及时更新排名。
排名可能会影响匹配机制。
成绩排行
适用于各种需要根据分数进行排名的场景,如考试成绩、比赛成绩等。
其他需要动态排序的场景
只要需要利用 ZSet 的有序特性,都可以考虑使用 ZSet 或类似的有序集合数据结构。
ZSet 的优势
高效更新
ZSet 能够在 O(log n) 的时间复杂度内更新分数和排名,适合实时变化的场景。
方便查询
可以通过分数范围或排名范围进行快速查询,操作简单且高效。
存储空间分析
存储需求
假设每个玩家信息(如用户 ID)占用 4 字节,分数(如天梯积分)占用 8 字节,每个玩家总共需要 12 字节。
对于 1 亿玩家,存储空间需求为:
1亿×12字节=1.2GB即使对于 10 亿玩家,存储空间也仅为 12GB,现代服务器和家用电脑都能轻松应对。
数据量级理解
学会快速估算数据量级,如 thousand(千)对应 KB,million(百万)对应 MB,billion(十亿)对应 GB。
这种估算能力对于评估系统需求和优化性能非常重要。
复杂排行榜的实现
微博热度计算
热度是一个综合数值,由多个维度(如浏览量、点赞量、转发量、评论量等)加权计算得出。
权重分配通常由专业团队通过人工智能和数据模型进行优化。
ZSet 的加权操作
可以使用 ZINTERSTORE 或 ZUNIONSTORE 命令,为每个维度的有序集合分配权重,计算出综合热度。
例如,将浏览量、点赞量、转发量、评论量分别存储在不同的有序集合中,然后通过加权并集或交集操作得到最终的热度排行。
学习 ZSet 的意义
启发和参考
学习 ZSet 不仅是为了直接使用 Redis,更是为了理解其背后的机制和原理。
这些原理可以应用于其他场景,如使用其他语言库实现有序集合,或者自己实现类似的数据结构。
知识迁移
学习任何技术或原理的目的是为了在不同场景中灵活应用,如操作系统、网络、数据库等领域的知识,都能为解决问题提供思路。