【MySQL】从零开始了解数据库开发 --- 基本查询

你感觉自己被埋葬,
实际上你是被培植。
-- 《粉熊救兵》--
从零开始了解数据库开发
- 1 增加数据
- 2 修改数据
- 3 删除语句
- 4 基本的数据查询
- 4.1 基本查询
- 4.2 单表查询
- 4.3 聚合函数
数据库中有经典的CRUD(create增, retrieve读, update更新 ,delete删除)增删查改的操作。数据库中最最重要也是最频繁的操作的是查询操作,今天我们我们就来学习一下数据库的增删查改,主要学习数据库的查询。
1 增加数据
增加数据的最经典语法是:
insert [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ]
[IGNORE] INTO 数据表名
[(字段名...)] values [(值...)]
[ON DUPLICATE key UPDATE 字段名 = 表达式]
- [LOW_PRIORITY | DELAYED | HIGH_PRIORITY ] :可选项 , 表示语句执行的优先级:
- LOW_PRIORITY是insert ,update ,Delete语句都支持的一种可选修饰符,通常用于多用户访问数据库的情况下,用于指示mysql降低insert ,update ,Delete语句执行的优先级;
- DELAYED 是Insert语句支持的可选修饰符,用于指定mysql服务器把待插入的行数据放到了一个缓冲器中,知道待插入数据的表空闲是才真正的插入数据。
- HIGH_PRIORITY 是insert与SELECT语句支持的一种可选修饰符,用于指定insert和select操作优先执行。
- [ignore]:可选项,表示在执行insert语句时,所表现出来的错误都会被当做警告处理,即忽略错误阻塞。
- [(字段名…)] values [(值…)]:表示对数据表的对应列插入数据,注意前后顺序需要一致。
- [ON DUPLICATE key UPDATE 字段名 = 表达式]:可选子句,用于指定向表中插入行时,如果导致unique key 或者 primary key出现冲突,则会根据update语句修改原有行的数据。
insert在使用时通常由以下三种用法:
- 插入完整数据:使用insert语句插入完成的记录,即所有字段都进行赋值。
- 只插入部分数据:使用insert语句只插入部分字段的数据,对于为插入的数据会使用默认值,如果为设置默认值则会判断是否可以为空
- 同时插入多条数据:使用insert语句同时插入多条数据,效率相比使用若干次insert会更好
除了insert…values…还有另外两个语法:
- insert…set…:set是将对应字段设置为指定值,其他使用默认值
- insert…select…:根据筛选结果插入数据,注意字段的匹配!
2 修改数据
修改语句的语法是:
Update [LOW_PRIORITY][ignore]
set 字段1 = 值1 , [字段2 = 值2]
[WHERE 条件表达式]
[order by ...]
[limit...]
- [LOW_PRIORITY]: LOW_PRIORITY是insert ,update ,Delete语句都支持的一种可选修饰符,通常用于多用户访问数据库的情况下,用于指示mysql降低insert ,update ,Delete语句执行的优先级,当没有用户读取数据时才会进行更新操作。
- [ingore]:在mysql中当使用update语句功更新表的多行数据时,如果出现错误,整个更新操作都会被取消,错误发生前所有行都会被恢复到修改前的状态。因此如果想要发生了错误也要继续更新可以使用关键字ignore
- set 字段1 = 值1 , [字段2 = 值2]:更新语句中要对表中什么数据进行更新,可以使用表达式,也可以指定使用默认值DEFAULT
- [WHERE 条件表达式]:可选项,用于限定修改表中哪些数据的值。虽然是可选项,但是每次更新都要加上,否则造成的影响就是全表别修改!
- [order by …]:用于限定更新数据的顺序
- [limit]:可选项用于指定被修改的行数
3 删除语句
在数据库中,当有些数据失去意义或者是存在错误时,此时就需要删除它们。在mysql中可以使用delete或者trauncate table删除一行或者多行数据。实际开发中正常业务的数据库删除是采用软删除的方法,就是使用一个字段来标识该数据是否生效,只有出现脏数据或者是业务调整时才会真正的去删除数据表中的数据。
DELETE语句的语法
DELETE [low_priority][quick][ignore] from 数据表名[where 条件表达式] [order by...][limit 行数]
- LOW_PRIORITY是insert ,update ,Delete语句都支持的一种可选修饰符,通常用于多用户访问数据库的情况下,用于指示mysql降低insert ,update ,Delete语句执行的优先级,当没有用户读取数据时才会进行删除操作。
- [quick]:可选项,用于加快部分种类的删除操作速度
- [ignore]:在mysql中当使用update语句删除表的多行数据时,如果出现错误,整个更新操作都会被取消,错误发生前所有行都会被恢复到修改前的状态。因此如果想要发生了错误也要继续更新可以使用关键字ignore。
- **[where 条件表达式] **:用于限定删除的数据范围!注意一定要添加,否则就会删除全表数据。
- [order by…]:用于决定删除的次序
- limit:用于限定被删除的行数
trauncate 语句的语法很简单:
truncate [table]数据表名
直接删除整张表的数据
4 基本的数据查询
重头戏来了,数据表中最最最最频繁的操作就数据查询!数据表存了数据是为了什么?当然就是进行数据查询!可以说数据表的其他操作都是在为数据查询服务的。数据查询的知识是很多的:
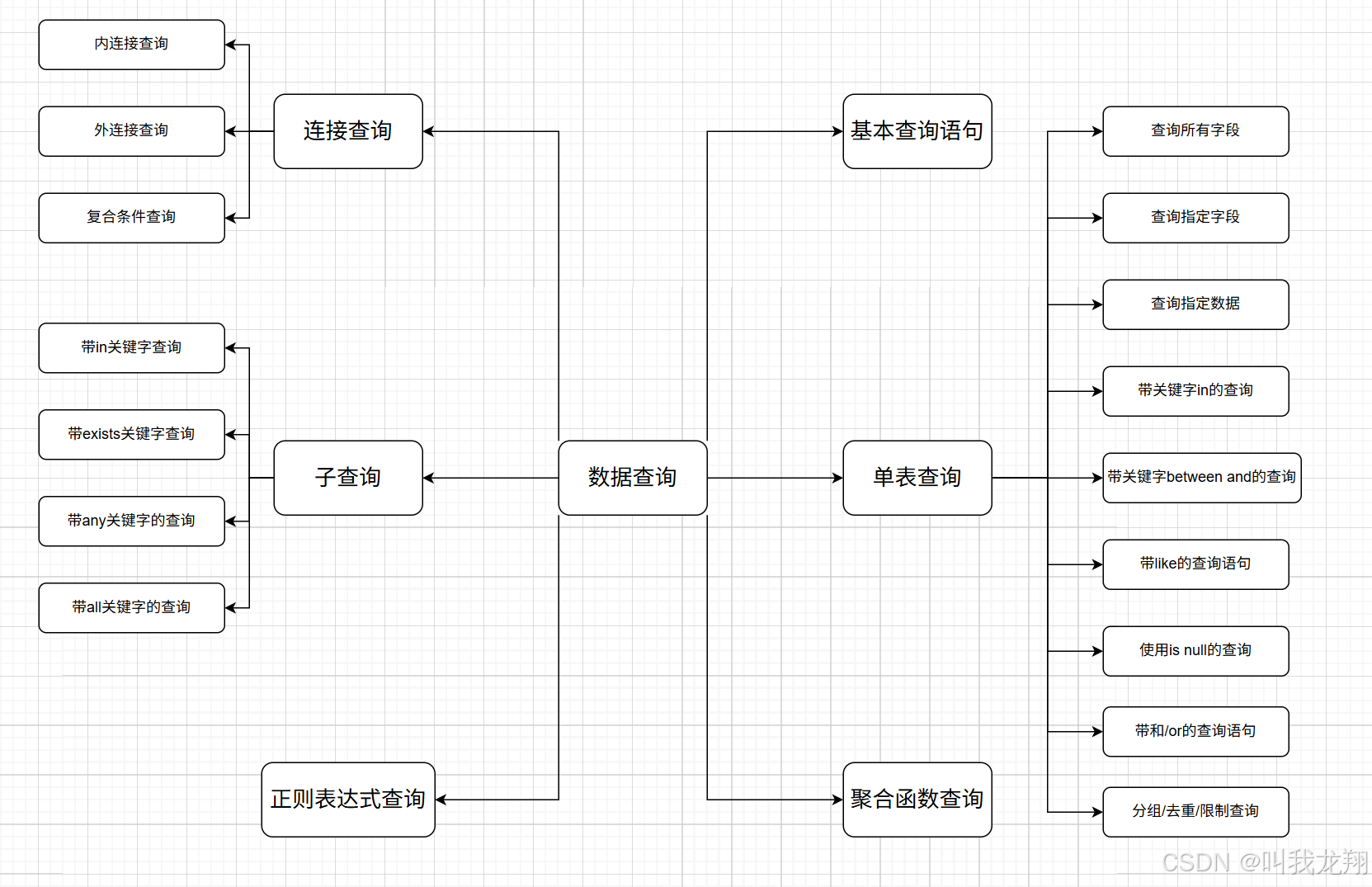
4.1 基本查询
这里先讲解基本的查询语法:
select selection_list -- 要查询的内容
from 数据表名
where condition -- 查询时需要满足的条件 源数据筛选
group by grouping_col -- 结如何对结果进行分组
order by sorting_condition -- 排序条件
having secondary_condition -- 查询时满足的第二条件 结果筛选 常用于分组查询
limit count -- 限制条数
面试题:SQL查询中各个关键字的执行先后顺序
from > on > join > where > group by > with > having > select > distinct > order by > limit
根据语法,可以有以下几种常用查询:
- 全列查询 :
select * from 数据表 where ...,可以把满足条件的所有数据列都查询出来 - 指定列查询:
select col1 , col2 from 数据表 where ...,可以把满足条件的指定数据列都查询出来 - 多表查询:
select db1.col1 , db2.col2 from db1 , db2 where ...,可以把满足条件的指定数据列都查询出来
4.2 单表查询
我们先来看简单的单表查询,同时熟悉查询语句中的常用关键字。
- 全列查询 :
select * from 数据表 where ...,可以把满足条件的所有数据列都查询出来 - 指定列查询:
select col1 , col2 from 数据表 where ...,可以把满足条件的指定数据列都查询出来 - 带in关键字的查询:
select col1 , col2 from 数据表 where col1 [not] in ( t1 , t2, ...)in关键字可以判断某个字段是否在指定集合中,进而筛选数据。 - 带between and的范围查询:
select col1 , col2 from 数据表 where 条件 [not] between 值1 and 值2 ;可以找到[值1,值2]区间的数据 - 带like的字符串匹配:like语法的字符串匹配规则是’%‘可以表示若干个字符,’_'只能表示一个字符
- 带is null 的关键字查询:可以使用is null关键字判断值是否为null
- and/or:数据库中的 与/或 判断逻辑
- Distinct:可以对查询出来的数据进行去重
- order by:语法
order by sorting_condition[ASC | DESC],asc表示升序,desc表示降序。默认是升序 - group by:按照某列进行分组,实现分组查询。实现逻辑类似树展开。注意分组查询不能出现分组外的字段SQL规定:SELECT 后面的列,要么是分组的依据(就是 GROUP BY 后面跟的列),要么就得用聚合函数(COUNT(), SUM(), MAX(), MIN(), AVG())处理一下。
- limir :对筛选处理的结果进行数量上的限制。
4.3 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
group by通常结合聚合函数进行查询。使用group分组后,SELECT 后面的列,要么是分组的依据(就是 GROUP BY 后面跟的列),要么就得用聚合函数处理。