[2]python爬虫实践,爬取网易云音乐热歌榜排行版名称
明确目标
我们先打开https://music.163.com/#/discover/toplist?id=3778678这个路径。
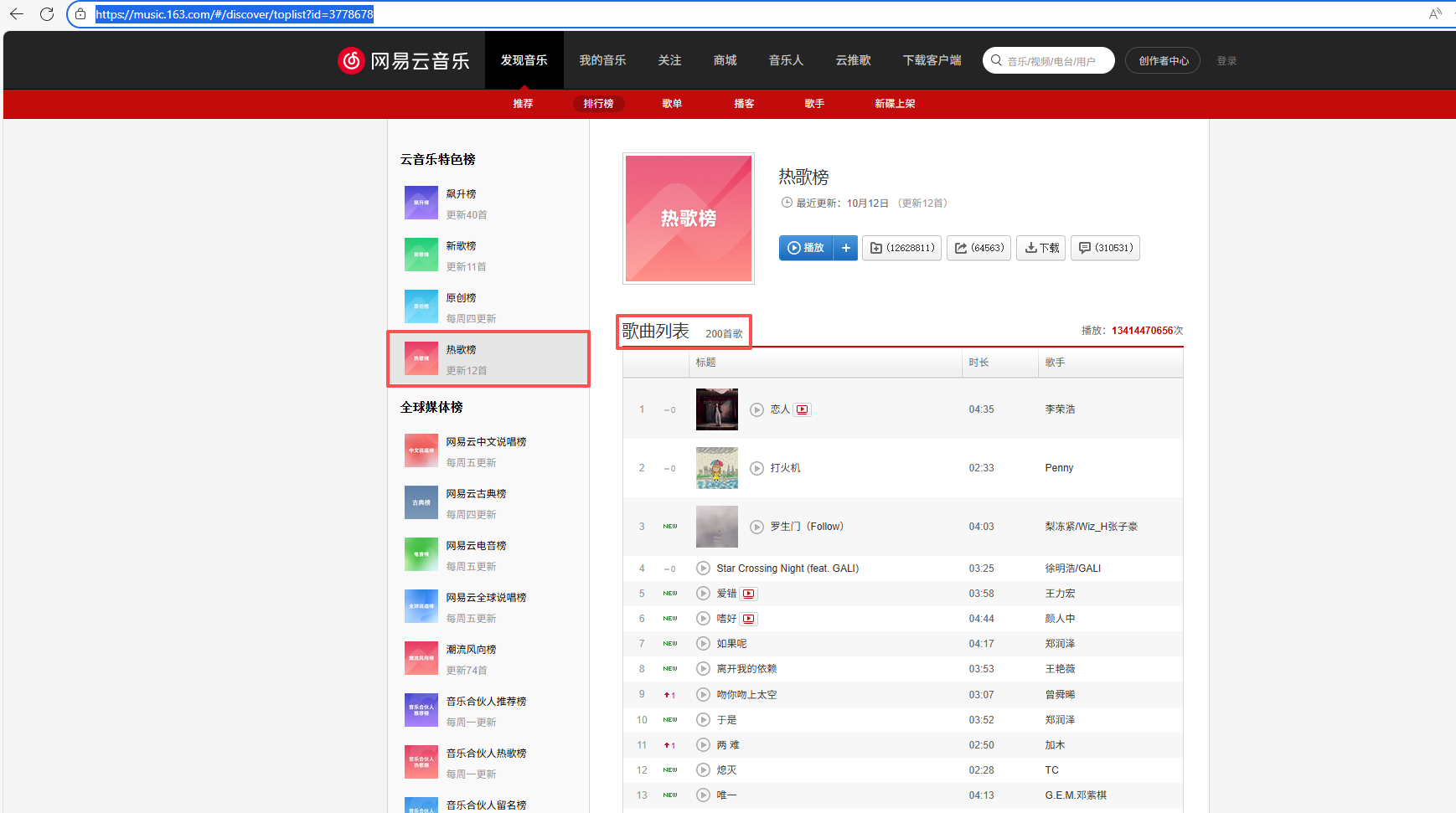
可以看到这个这个网页下的热歌榜有200首歌,我们的目标就是将热歌榜下的200首歌按照排名次序依次记录到txt文件里面。
完整代码
import requests
import random
from bs4 import BeautifulSoupuser_agent = ["Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
]agent = random.choice(user_agent)def get_user_agent():return {'User-Agent': agent}print(agent)# url1= 'https://music.163.com/#/discover/toplist?id=3778678'
url = 'https://music.163.com/discover/toplist?id=3778678'
# api_url = "https://music.163.com/api/playlist/detail?id=3778678"headers = {'User-Agent': random.choice(user_agent)}response = requests.get(url, headers=headers)
if response.status_code == 200:content_type = response.headers.get('content-type')# print(content_type)data = response.content.decode('utf-8')soup = BeautifulSoup(data, 'html.parser')print(soup)song_ul = soup.find('ul', class_='f-hide')if not song_ul:print('未找到ul')else:# print(song_ul)song_li = song_ul.find_all('li')# print(song_li)url_save = f'网易云热歌榜排行版.txt'with open(url_save, 'w', encoding='utf-8') as f:for index, li in enumerate(song_li, 1):song_a = li.find('a')if not (song_a):print('未找到song_a')else:song_name = song_a.text.strip()f.write(f"{index}.{song_name}\n")print('所有歌曲名称已保存到文件:{url_save}')
else:print(f'请求失败,状态码:{response.status_code}')代码解析
没有使用随机请求头
我们的这个代码没有使用随机请求头进行获取User-Agent,原因是如果使用了随机请求头,对于一部分的User-Agent会无法读取正确的HTML文件,所以我们将很多的随机请求头都删去,只留下能够访问的正确的请求头.
怎么查看一个有用的请求头
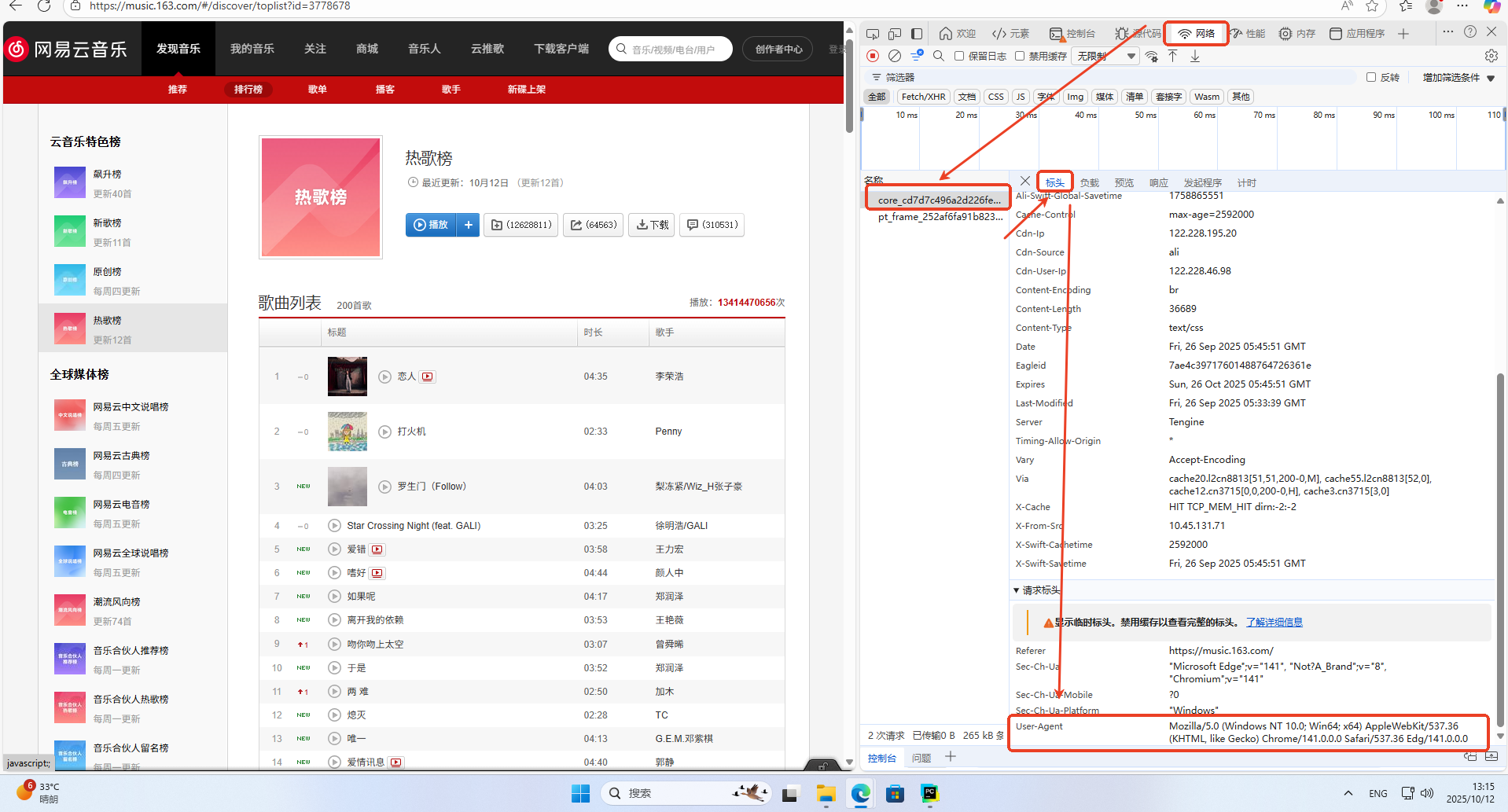
按下F12打开开发者模式,然后依次找到网络,随便点击一个名称,点击标头,拉到最下面找到User-Agent这一栏,里面的就是当前浏览器的请求头。
对于网址的修改
我们的目标网址是https://music.163.com/#/discover/toplist?id=3778678但是我们爬取的网址却是https://music.163.com/discover/toplist?id=3778678
是因为 #及其后面的内容(hash)不会被发送到服务器,只会在浏览器端被JavaScript处理。在传统Web和HTTP协议中,#及其后面的部分被称为 片段标识符(Fragment Identifier) 或 哈希(Hash)。当浏览器向服务器发起请求时,#及之后的所有内容都不会被发送到服务器。
你请求的URL是:https://music.163.com/#/discover/toplist?id=3778678
浏览器实际发送给 music.163.com服务器的请求是:https://music.163.com/
服务器根本不知道你后面还有 #/discover/toplist?id=3778678这部分。
当你的爬虫请求 https://music.163.com/discover/toplist?id=3778678
这个完整的URL(包括路径 /discover/toplist和参数 id=3778678)会被发送到网易云的服务器。
服务器识别到这个路径,直接在服务器端生成包含排行榜数据的HTML页面,然后把这个完整的HTML返回给你的爬虫。
headers = { ‘User-Agent’: random.choice(user_agent)}
headers = { 'User-Agent': random.choice(user_agent)}请求头是一个字典数据类型,在Python中,大括号 {}最主要和最常用的用途确实是表示字典(dictionary)这种数据类型。字典是一种非常强大的内置数据结构,用于存储键值对(key-value pairs)的集合。字典中的每个元素都由一个键(key)和一个值(value)组成,键和值之间用冒号 :分隔,不同的键值对之间用逗号 ,分隔,所有元素被包裹在一对大括号 {}中.
response = requests.get(url, headers=headers)
这段代码 response = requests.get(url, headers=headers)是使用 Python 的 requests 库发送 HTTP GET 请求的标准写法,它的作用是向指定的 URL 发送一个网络请求并获取服务器的响应。
requests 是 Python 中最流行的 HTTP 客户端库,它封装了底层的 HTTP 通信细节,提供了简单易用的 API 来发送各种 HTTP 请求,其中 get() 方法专门用于发送 GET 请求,这是 HTTP 协议中最常用的请求方法,主要用于从服务器获取数据而不对服务器资源进行修改。
url 参数指定了你要请求的目标网址,这是一个字符串类型的变量,通常包含完整的 HTTP 或 HTTPS 协议地址,比如 https://music.163.com/discover/toplist?id=3778678,这个地址就是你要爬取的网易云音乐排行榜页面。
headers 参数是一个字典类型的变量,包含了要随请求一起发送的 HTTP 头部信息,在这个例子中它至少包含了一个 ‘User-Agent’ 字段,User-Agent 是用来标识客户端身份的重要头部,服务器会根据这个值判断请求是来自浏览器还是爬虫程序,设置合适的 User-Agent 可以帮助你的请求看起来更像正常的浏览器访问,从而降低被服务器识别为爬虫并拦截的风险。
content_type = response.headers.get(‘content-type’)
if response.status_code == 200:content_type = response.headers.get('content-type')print(content_type)
if response.status_code == 200:这一行是条件判断语句,它的作用是检查 HTTP 请求的响应状态码是否等于 200。在 HTTP 协议中,状态码是服务器返回的三位数字代码,用于表示请求的处理结果,其中 200 是最重要的状态码之一,它明确表示"OK",即请求已成功处理,服务器正常返回了所请求的数据,没有发生错误。
content_type = response.headers.get(‘content-type’)这一行代码是从 HTTP 响应头中获取名为 ‘content-type’ 的字段值,并将其赋值给变量 content_type。HTTP 响应头是服务器在返回数据时附带的一系列元信息,其中 ‘content-type’ 是一个非常关键的头部字段,它告诉客户端(也就是你的 Python 程序)服务器返回的数据是什么类型,比如是 HTML 文档、JSON 数据、纯文本、图片还是其他格式。
输出内容:
text/html;charset=utf8
data = response.content.decode(‘utf-8’)
response.content
这是 requests库 Response 对象的一个属性,它包含了服务器返回的原始二进制响应内容。无论服务器返回的是 HTML 文档、JSON 数据、图片还是其他任何类型的文件,response.content都会以字节串(bytes)的形式完整保留这些数据,不会对内容做任何解码或解释。这种原始二进制格式的数据是通用的,可以表示任何类型的信息,但人类无法直接阅读,程序也需要进一步处理才能理解其具体含义。
.decode(‘utf-8’)
这是 Python 字节串(bytes 类型)的一个方法,用于将二进制数据解码为 Unicode 文本字符串(str 类型)。decode()方法需要指定一个字符编码方案(encoding scheme),在这里使用的是 ‘utf-8’,这是目前互联网上最广泛使用的字符编码标准,能够支持包括中文、英文、日文等几乎所有语言的字符。
soup = BeautifulSoup(data, ‘html.parser’)
soup = BeautifulSoup(data, ‘html.parser’) 这行代码是将前面通过 requests 获取并解码后的 HTML 文本数据 data 交给 BeautifulSoup 库进行解析,目的是把原始的、可能结构复杂或格式不规范的 HTML 文档转换成一个结构化的、可以用 Python 代码方便操作和提取信息的对象,也就是 BeautifulSoup 对象
在这个过程中 BeautifulSoup 会分析 HTML 中的各种标签、属性和它们之间的嵌套关系,构建出一个类似树状的 DOM 模型,使得你可以通过标签名、类名、ID、属性等条件快速定位到 HTML 文档中的特定元素,比如你想要提取的歌曲列表所在的 ul 标签或者其中的 li 标签
打印soup 并且搜索歌名
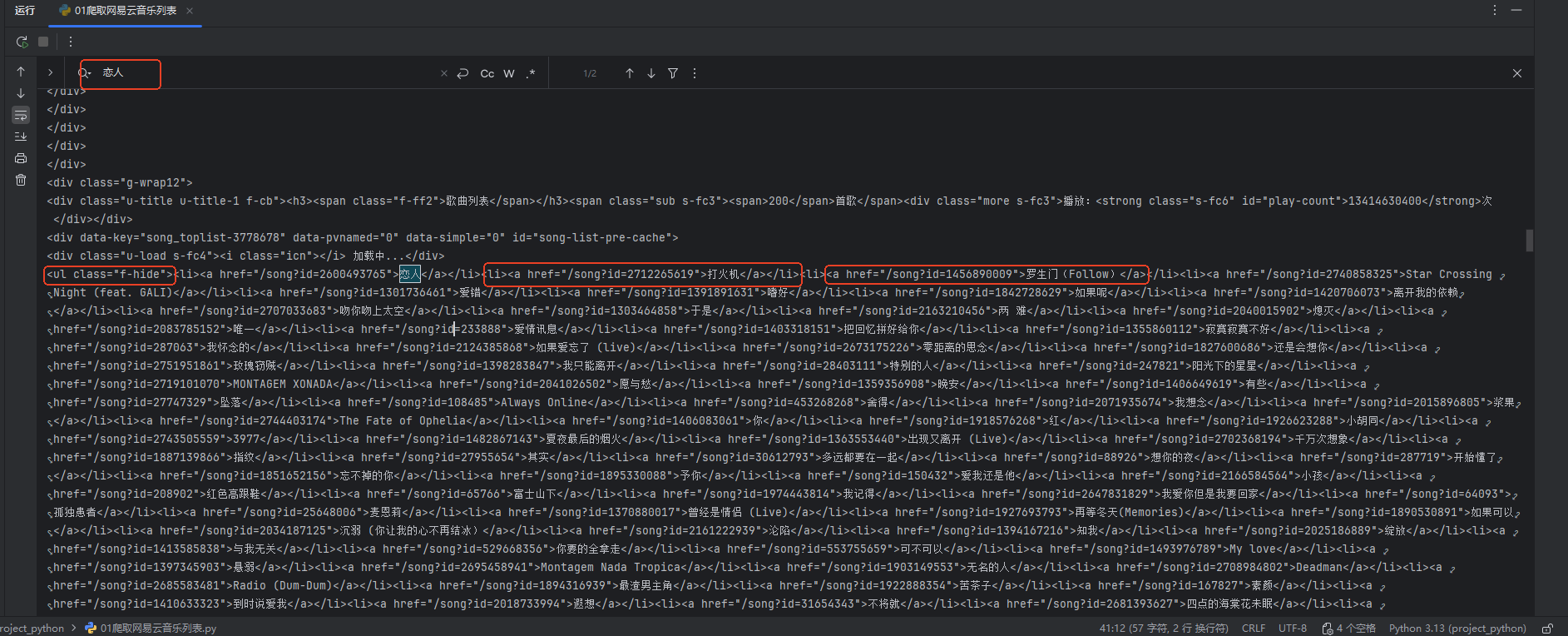
对于所有的歌名我们发现他们都位于< ul class=“f-hide”>标签下,而里面的每一首歌名都位于里面的 < li>标签下的 < a>标签下.
song_ul = soup.find(‘ul’, class_=‘f-hide’)
song_ul = soup.find(‘ul’, class_=‘f-hide’) 这行代码的作用是从之前用 BeautifulSoup 解析得到的 HTML 文档对象 soup 中,查找第一个符合特定条件的 ul 标签元素,具体来说就是查找一个 ul 标签,这个标签的 class 属性值为 f-hide
这行代码执行后会返回一个 Tag 对象(如果找到了符合条件的 ul 标签),这个 Tag 对象就代表了 HTML 文档中第一个满足 ul 标签且 class 为 f-hide 的那个元素,你可以通过这个 Tag 对象进一步获取该 ul 标签内部的子元素、属性信息或者文本内容
如果 soup 中不存在符合条件的 ul 标签,也就是在 HTML 文档里没有找到任何一个既是 ul 标签同时 class 属性又为 f-hide 的元素,那么 soup.find 方法会返回 None,所以在后续的代码逻辑中通常需要对这个返回值进行检查,判断是否为 None,以避免在找不到元素的情况下继续调用 find_all 或其他方法导致程序出错
song_li = song_ul.find_all(‘li’)
song_li = song_ul.find_all(‘li’) 这行代码的作用是从之前找到的存放歌曲列表的 ul 标签元素 song_ul 中,提取出该 ul 标签下包含的所有 li 标签元素,并将它们作为一个列表返回,这些 li 标签通常就对应着排行榜中的每一首歌曲
这里使用的是 BeautifulSoup 对象的 find_all 方法,它是一个非常核心和常用的方法,用于查找并返回 HTML 文档中所有符合指定条件的标签元素,这行代码中传入的参数 ‘li’ 明确告诉 BeautifulSoup 你需要在 song_ul 这个 ul 标签内部查找所有标签名为 li 的子元素
执行这行代码后,song_li 变量将得到一个包含多个 Tag 对象的列表,列表中的每一个 Tag 对象都代表 HTML 文档中的一个 li 标签,也就是排行榜中的一首歌曲对应的列表项,通过这个列表你就可以进一步遍历每一个 li 标签,从中提取出你真正需要的歌曲名称、歌曲链接或其他相关信息
with open(url_save, ‘w’, encoding=‘utf-8’) as f:
首先,open 是 Python 内置的文件操作函数,用于打开或创建一个文件,它接收多个参数,其中 url_save 是文件名变量,代表你想要保存数据的本地文件的路径和名称.
其次,‘w’ 是文件的打开模式,表示以写入(write)模式打开文件,如果指定的文件 url_save 已经存在,使用 ‘w’ 模式会先清空该文件原有的所有内容,然后从头开始写入新的数据;如果文件不存在,则会自动创建一个新的文件.
接着,encoding=‘utf-8’ 参数指定了文件的编码格式为 UTF-8,这是一个非常重要的设置,因为 UTF-8 能够支持包括中文在内的几乎所有语言的字符,确保当你写入包含中文歌曲名称的文本内容时不会出现乱码问题
最后,as f 将打开的文件对象赋值给变量 f,这个 f 变量代表了一个文件句柄,通过它你可以在接下来的代码块中对该文件进行读写操作,在 with 语句块内部(也就是缩进在 with open(…) as f: 下面的代码区域),你可以使用这个 f 变量来调用 write() 方法,将数据写入到文件中
使用 with 上下文管理器的好处是不需要手动调用 f.close() 来关闭文件,当 with 代码块中的所有操作执行完毕后,Python 会自动关闭文件句柄,释放系统资源,这样可以避免因为忘记关闭文件或者程序异常导致文件没有正确关闭而引发的问题,比如数据没有完全写入磁盘或者文件句柄泄露
for index, li in enumerate(song_li, 1):
for index, li in enumerate(song_li, 1): 这行代码使用了 Python 的内置函数 enumerate() 来遍历之前获取到的包含所有歌曲列表项(li 标签)的列表 song_li,同时为每个列表项生成一个从 1 开始自动递增的序号 index,它的作用是为排行榜中的每一首歌曲创建一个有序的编号,以便在后续处理和保存数据时能够清晰地标识每首歌曲在排行榜中的位置
首先,song_li 是一个列表,其中包含了通过 soup.find_all(‘li’) 方法从 HTML 中提取出的所有 li 标签元素,这些 li 标签在网页结构中通常代表排行榜中的每一首歌曲,每一个 li 元素都包含了对应歌曲的相关信息,比如歌曲名称和链接,它们一般位于 li 标签内部的 a 标签中
其次,enumerate() 是 Python 的一个非常实用的 built-in 函数,它的主要功能是对一个可迭代对象(比如列表、元组、字符串等)进行遍历的同时,为每一个元素附加一个自动递增的计数器,也就是索引值,默认情况下这个索引是从 0 开始的,但在我们的代码中,enumerate(song_li, 1) 的第二个参数设置为 1,这意味着索引计数将从 1 开始,而不是默认的 0,这样的设置更符合大多数排行榜展示的习惯,即第一首歌曲编号为 1,第二首为 2,以此类推
在每次循环迭代过程中,enumerate() 会返回一个包含两个值的元组:第一个值是当前元素的序号(从 1 开始的 index),第二个值是 song_li 列表中对应的当前 li 标签元素(li),通过使用 Python 的多重赋值语法,你将这两个返回值分别赋给了变量 index 和 li,这样在循环体内你就可以同时访问到歌曲的序号和对应的 li 标签元素
song_name = song_a.text.strip()
song_a 是我之前通过 li.find(‘a’) 方法从当前的 li 标签元素中查找到的 a 标签对象,在网易云音乐的 HTML 结构里,每首歌曲的名称通常被包裹在 li 标签内部的 a 标签中,这个 a 标签不仅包含歌曲名称的文本,还可能包含指向歌曲详情页的链接和其他属性。
text 是 BeautifulSoup 提供的属性,当我访问 song_a.text 时,它返回的是该 a 标签内部包含的所有文本内容,也就是我歌曲列表中显示的歌曲名称,但这个文本内容往往会包含一些额外的空白字符,比如换行符、制表符或者多余的空格,这些字符会影响我最终保存或展示的歌曲名称的整洁性。
strip() 是 Python 字符串的一个内置方法,我使用它来移除 song_a.text 返回的字符串开头和结尾的所有空白字符,包括空格、制表符(\t)、换行符(\n)等,通过调用 strip(),我确保提取出的歌曲名称字符串是干净的,没有不必要的空白字符干扰,只包含纯粹的歌曲名称文本。
将这两步结合起来,song_a.text.strip() 先获取 a 标签中的全部文本内容,然后去除其首尾的空白字符,最终得到一个格式整洁、可直接使用的歌曲名称字符串,我将其赋值给变量 song_name,这样在我后续的代码中就可以直接使用这个变量来表示当前歌曲的名称,并将其与歌曲的排行榜序号一起保存到文件中,或者进行其他的数据处理和展示操作。
f.write(f"{index}.{song_name}\n")
f 是我通过 with open(url_save, ‘w’, encoding=‘utf-8’) as f: 语句打开并获得的文件对象,它代表了我之前定义的用于保存排行榜数据的文本文件(例如“网易云热歌榜排行版.txt”),这个文件已经以写入模式(‘w’)打开,并且设置了正确的 UTF-8 编码以确保包含中文的歌曲名称能够正确保存而不会出现乱码问题。
write() 是文件对象的一个方法,用于将指定的字符串内容写入到文件中,我通过调用 f.write() 将格式化后的歌曲信息字符串写入文件,实现数据的持久化存储,这样在我爬虫程序运行结束后,我可以在本地文件系统中找到这个文本文件,查看完整的排行榜歌曲列表。
f"{index}.{song_name}\n" 是一个 f-string(格式化字符串字面值),这是 Python 3.6 及以上版本支持的一种简洁且强大的字符串格式化方法,它允许我直接在字符串中嵌入变量和表达式。在这行代码中,我使用了 f-string 将我之前通过 enumerate() 获取到的歌曲序号变量 index 和通过 song_a.text.strip() 提取并清理后的歌曲名称变量 song_name 组合成一个格式统一的字符串。
结尾
最后,感谢您阅读我的文章,希望这些内容能够对您有所启发和帮助。如果您有任何问题或想要分享您的观点,请随时在评论区留言。
同时,不要忘记订阅我的博客以获取更多有趣的内容。在未来的文章中,我将继续探讨这个话题的不同方面,为您呈现更多深度和见解。
谢谢您的支持,期待与您在下一篇文章中再次相遇!