音视频学习(六十九):视音频噪声
基本概念
音视频信号是对声音和图像信息的电气化或数字化表示。声音信号对应空气振动的波形,视频信号则对应光强、颜色变化的空间分布。理想的音视频信号应完全还原真实世界的声画信息,但在采集、传输、存储和播放等过程中,不可避免会受到各种干扰,这些不属于原始信号的非期望成分被称为噪声(Noise)。
噪声是一种随机信号,它会降低音视频的清晰度、对比度、色彩还原度和听觉质量。无论是模拟系统还是数字系统,噪声都普遍存在,只是表现形式和影响机制不同。
音频噪声的类型与来源
音频噪声主要表现为音质劣化、底噪、杂音或爆音等。根据产生原因,可分为以下几类:
- 热噪声(Thermal Noise)
由电子元件中的热运动引起,具有高斯分布特性,是最常见的基础噪声。它在音频系统中表现为均匀的“嘶嘶”声。 - 电磁干扰(EMI)与射频噪声(RFI)
外部电器设备、无线电信号或电源线感应产生的干扰信号,会在录音或放大环节引入嗡嗡声或脉冲干扰。 - 量化噪声(Quantization Noise)
数字音频在模拟/数字转换(ADC)过程中,由于量化精度有限导致信号离散化误差,从而产生噪声。其能量与采样位深成反比,位深越高,量化噪声越小。 - 压缩噪声(Compression Artifacts)
使用有损压缩算法(如 MP3、AAC)时,部分听觉不敏感的频率被舍弃,若压缩比过高,会出现“金属声”“水声”等伪影。 - 背景噪声(Ambient Noise)
来自录音环境的自然声源,如风声、空调声、人声杂谈等,是录音质量控制的重要难点。
音频噪声的评价常用指标是信噪比(SNR, Signal-to-Noise Ratio),其定义为:
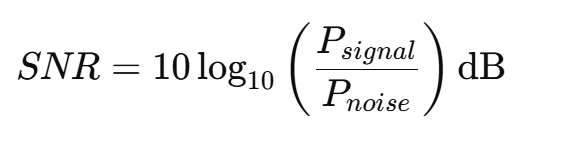
SNR 越高,说明信号质量越好。
视频噪声的种类与特征
视频噪声是指图像信号中不属于原场景的亮度或色度随机波动。根据产生机制与表现形式,可分为以下几类:
- 亮度噪声(Luminance Noise)
在图像亮度通道中出现的灰度随机波动,表现为画面颗粒感或闪烁点。 - 色度噪声(Chrominance Noise)
出现在色彩通道中,使颜色出现偏移、斑点或彩条,常见于低光照视频中。 - 椒盐噪声(Salt-and-Pepper Noise)
由传感器或数据丢包导致的随机黑白点噪声。 - 高斯噪声(Gaussian Noise)
常见于模拟信号传输系统或高感光度传感器,亮度变化服从正态分布。 - 压缩伪影(Compression Artifacts)
视频编码(如 H.264/H.265)过程中采用块匹配与量化导致的方块效应、马赛克、色块边缘失真等。 - 条纹与固定图样噪声(Fixed Pattern Noise)
摄像头传感器中像素响应不均一造成的条纹或暗斑,尤其在低照度下明显。
噪声与信号失真的区别
噪声是随机性干扰,而**失真(Distortion)**则是系统非线性或传输误差引起的系统性变形。例如:
- 幅度失真:不同频率的增益不一致,导致音色或亮度偏差。
- 相位失真:信号的相位被改变,造成声音模糊或视频运动抖动。
- 压缩失真:编码器丢弃信息后产生结构性伪影。
噪声是随机的、不可预测的;失真则是可确定的、可建模的。实际系统中二者往往共存。
数字音视频系统中的噪声来源
在数字音视频处理链路中,噪声可在多个阶段引入:
- 采集阶段:传感器热噪声、镜头暗电流、ADC 量化误差。
- 传输阶段:信号带宽受限、丢包、码流抖动。
- 存储阶段:数据压缩误差、比特错误、文件损坏。
- 解码与播放阶段:解码算法近似误差、插值重建误差。
现代系统通常通过降噪滤波(Denoising)、错误校正(FEC)及编码优化来控制噪声影响。
常见的音视频降噪方法
音频降噪
- 时域平均法:通过平滑滤波减少随机波动。
- 频域噪声估计:利用傅里叶变换识别噪声频段并衰减。
- 谱减法(Spectral Subtraction):估计噪声功率谱并从信号谱中减去。
- 自适应滤波(ANC, Adaptive Noise Cancellation):通过 LMS/NLMS 算法实时估计噪声路径。
- 深度学习降噪:采用 DNN、RNN、Transformers 等网络模型实现语音增强。
视频降噪
- 空间滤波:如均值滤波、中值滤波、高斯滤波,适合静态噪声。
- 时域滤波:利用相邻帧的相似性,降低动态噪声。
- 非局部均值算法(NLM):基于像素块相似度加权平均,保持细节。
- BM3D、V-BM4D:基于块匹配与三维变换的高性能算法。
- 深度神经网络降噪(DNN Denoising):通过卷积网络或Transformer学习噪声分布,实现实时视频增强。
信噪比与客观评价指标
音视频质量的客观评价常采用以下指标:
-
SNR(信噪比):衡量信号功率与噪声功率之比。
-
PSNR(峰值信噪比):常用于视频图像质量评估,计算公式为:
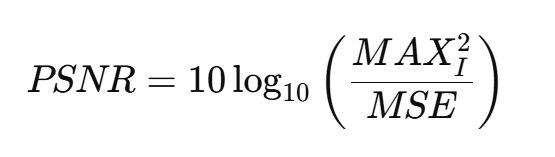
其中 MAXI 为像素最大值,MSE 为均方误差。PSNR 通常高于 35 dB 表示视觉质量较好。
-
SSIM(结构相似度):从亮度、对比度、结构三个维度度量图像质量,更符合人眼视觉感知。
-
MOS(主观意见得分):通过人工听/视测评分,反映主观体验。
噪声控制与系统设计原则
- 采集端优化:选用低噪声传感器、合理曝光与增益控制。
- 信号链设计:高品质前端放大器与抗干扰布线。
- 数字处理:高精度量化、带宽自适应、编码优化。
- 后期增强:AI 降噪、音频均衡、视频去伪影。
- 存储与传输容错:采用冗余编码、CRC 校验、RTCP 报告机制等。
通过系统级的噪声抑制设计,可以显著提升音视频质量,尤其在监控、会议、直播、电影后期制作等场景中具有重要意义。
总结
噪声是音视频信号处理中最普遍且最具挑战性的问题之一。随着传感器技术、数字信号处理和人工智能的发展,现代音视频系统对噪声的抑制能力不断增强。从早期的模拟滤波器到今天的深度学习算法,降噪已成为音视频质量提升的重要环节。理解噪声的产生机理、特征以及控制手段,是音视频工程师进行系统设计与优化的基础。只有在全链路层面控制噪声,才能实现高保真、高体验的音视频传输与呈现。