网站搭建装修风格大全2021新款简约
引言
在大数据领域,Apache Hive作为构建在Hadoop之上的数据仓库工具,因其类SQL的查询语言(HiveQL)和良好的扩展性而广受欢迎。然而,随着数据量的增长,查询性能往往成为瓶颈。本文将深入探讨Hive中两种关键的数据组织技术——分区(Partitioning)和分桶(Bucketing),它们是如何显著提升查询效率的利器。
1 Hive分区技术详解
1.1 什么是分区
分区(Partitioning)是Hive中将表数据按照某个或某几个列的值进行物理划分的技术。从逻辑上看,分区表仍然是一个完整的表,但在物理存储上,表数据被组织到不同的目录中,每个分区对应一个目录。
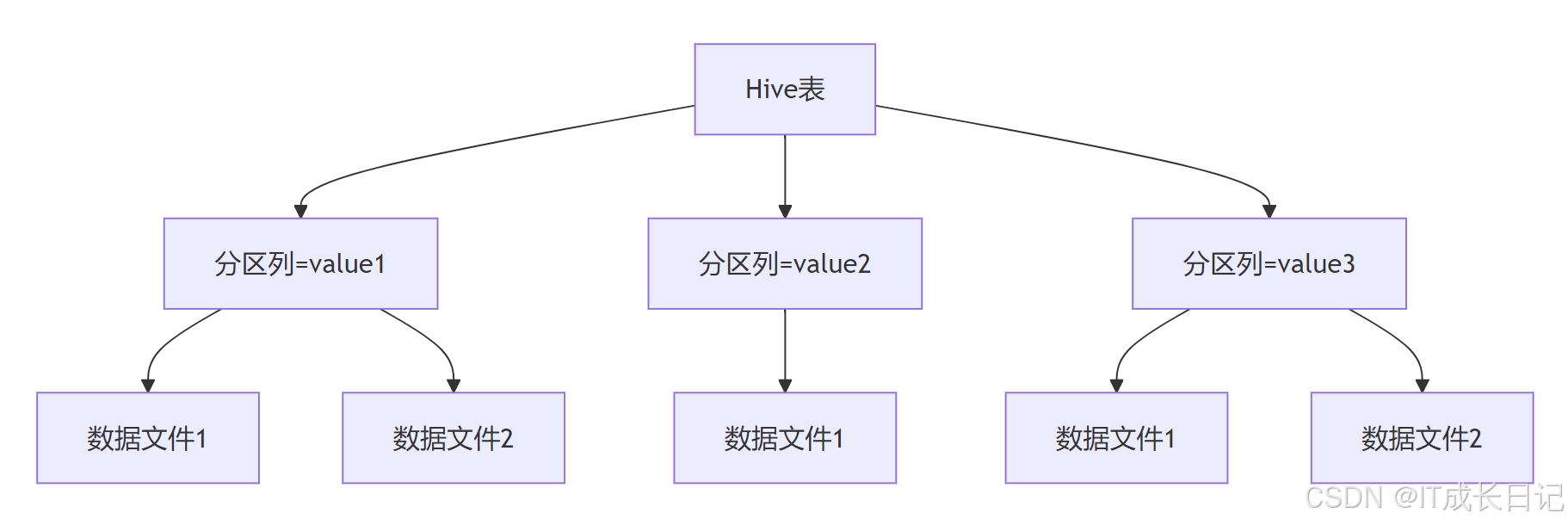
分区优势:
- 查询性能提升:通过分区剪枝(Partition Pruning),Hive可以只扫描相关分区,避免全表扫描
- 管理便捷:可以针对特定分区进行维护操作(如删除、备份)
- 成本节约:减少不必要的数据读取,降低计算资源消耗
1.2 分区类型与应用场景
1.2.1 静态分区
静态分区需要手动指定分区值,适用于分区值已知且数量有限的场景。
-- 创建分区表
CREATE TABLE logs (id string,message string
) PARTITIONED BY (dt string, country string);-- 静态分区插入
INSERT INTO TABLE logs PARTITION(dt='2023-01-01', country='US')
SELECT id, message FROM source_table;1.2.2 动态分区
动态分区根据查询结果自动确定分区值,适用于分区值多变或未知的场景。
-- 启用动态分区
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;-- 动态分区插入
INSERT INTO TABLE logs PARTITION(dt, country)
SELECT id, message, dt, country FROM source_table;1.3 分区最佳实践
- 选择合适的分区键:选择高基数(不同值多)且常用于过滤条件的列
- 避免过度分区:分区过多会导致小文件问题,影响NameNode性能
- 分区粒度选择:时间字段常用年/月/日,地理位置可用国家/省份
- 分区命名规范:建议使用有意义的命名,如dt=2025-04-20
2 Hive分桶技术深入
2.1 分桶概念解析
分桶(Bucketing)是另一种数据组织方式,它根据哈希函数将数据均匀分布到固定数量的桶中。
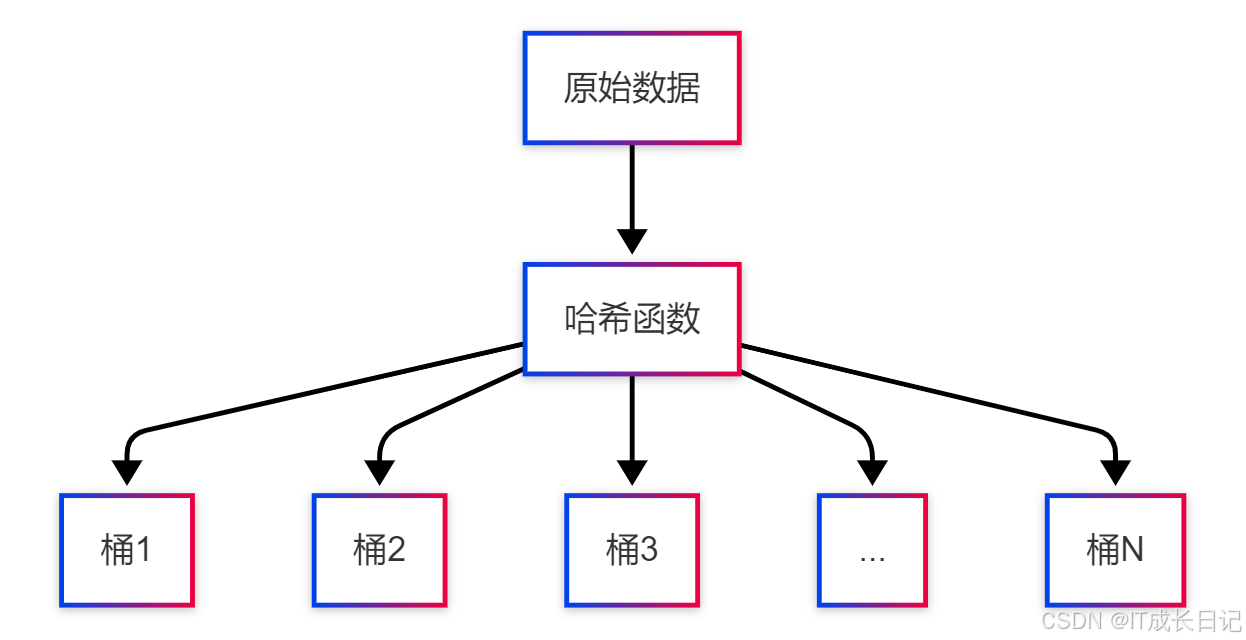
分桶核心特点:
- 每个桶对应一个文件
- 数据按照分桶列的哈希值分配到各个桶
- 桶的数量在表创建时固定
2.2 分桶实现原理

关键参数:
- hive.enforce.bucketing:设置为true确保数据正确分桶
- hive.exec.reducers.bytes.per.reducer:控制每个Reducer处理的数据量
2.3 分桶与分区对比
| 特性 | 分区 | 分桶 |
| 数据组织方式 | 按列值划分目录 | 按哈希值划分文件 |
| 适用场景 | 高基数列 | 低基数列 |
| 性能影响 | 避免全表扫描 | 优化JOIN和采样效率 |
| 文件数量 | 与分区数成正比 | 固定桶数 |
| 数据倾斜 | 可能严重 | 相对均匀 |
3 分区与分桶联合应用
3.1 组合使用场景
在实际生产中,分区和分桶经常结合使用以达到最佳效果:
CREATE TABLE user_behavior (user_id bigint,item_id bigint,behavior_type int,timestamp string
)
PARTITIONED BY (dt string)
CLUSTERED BY (user_id) INTO 32 BUCKETS;3.2 组合策略的优势
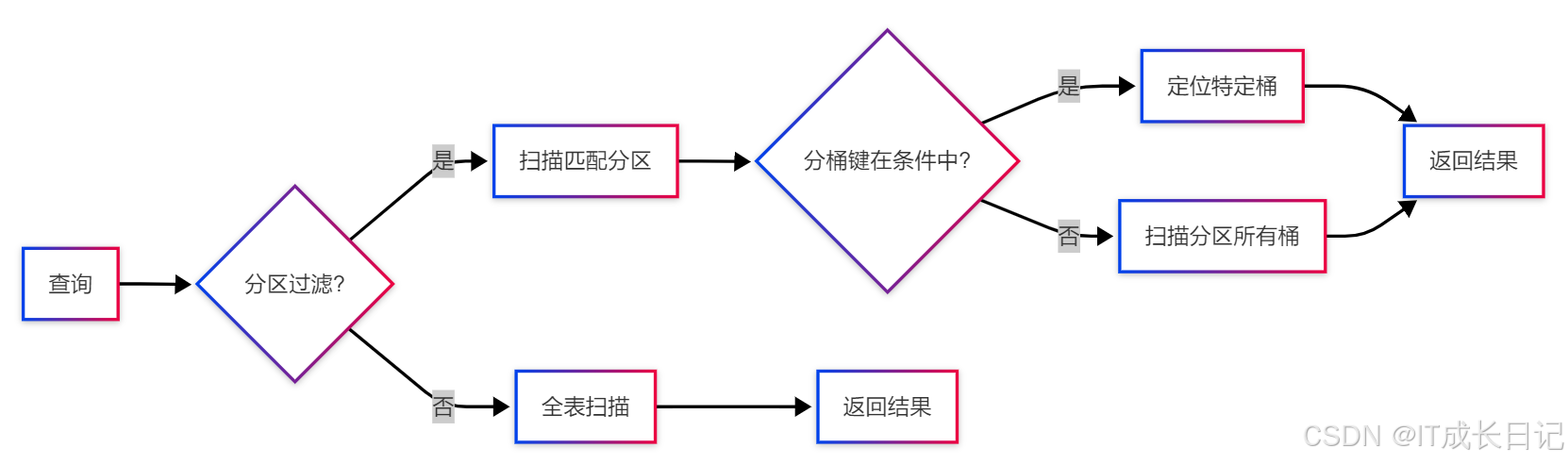
- 双重剪枝:先通过分区过滤数据,再通过分桶精确查找
- 高效JOIN:相同分桶列的表可进行高效的桶对桶JOIN
- 采样优化:分桶使数据均匀分布,采样更准确
4 性能优化实战技巧
4.1 分区优化策略
- 避免分区过多:监控分区数量,定期合并小分区
- 合理设置分区粒度:根据查询模式调整,如从按天分区改为按月分区
- 使用虚拟列:Hive 2.0+支持虚拟列(INPUT__FILE__NAME)实现灵活查询
4.2 分桶优化策略
- 选择合适桶数:通常设置为集群Reducer数量的倍数
- 分桶列选择:优先选择JOIN、GROUP BY或采样常用的列
- 数据倾斜处理:对倾斜值单独处理,再UNION ALL其他结果
4.3 监控与维护
-- 查看分区信息
SHOW PARTITIONS table_name;-- 查看分桶信息
DESCRIBE FORMATTED table_name;-- 修复分区元数据
MSCK REPAIR TABLE table_name;5 总结
Hive分区和分桶是优化大数据查询性能的两大核心技术。分区通过数据物理隔离实现快速定位,分桶则通过哈希分布实现高效JOIN和采样。合理结合两者可以显著提升查询效率,降低资源消耗。