池化 (Pooling) 学习笔记
一、池化 (Pooling) 的核心概念
池化是卷积神经网络 (CNN) 中非常重要的操作,主要作用有:
- 降维:减少特征图的空间尺寸,降低计算复杂度
- 增强平移不变性:使模型对输入图像的微小位移不敏感
- 防止过拟合:通过信息聚合减少参数数量
可以用视频清晰度调节的过程来理解池化操作,两者核心逻辑非常相似:
低清晰度视频(类似池化输出)当你把视频调到 720P 时,画面会比 1080P 小一圈,细节也少一些。这就像池化后的矩阵 —— 尺寸变小(比如 4x4→2x2),但保留了关键信息。
高清晰度转低清晰度(类似池化过程)视频从 1080P 转 720P 时,系统会把相邻的像素块(比如 2x2 个像素)合并成 1 个像素,通常会保留这个块里最亮 / 最具代表性的信息。这就像最大池化:从 2x2 的数值块中取最大值,既缩小了规模,又保留了该区域的关键特征(比如视频里的明暗对比)。
为什么要这么做?
- 视频:低清视频加载更快,占用带宽更少
- 池化:缩小后的矩阵计算更快,还能过滤掉无关细节(比如视频里的噪点 vs 数据里的冗余信息)
简单说,池化就像给数据 "降清"—— 牺牲部分细节,换来更高的处理效率,同时保留核心特征
二、最大池化的工作原理
最大池化 (Max Pooling),即从指定区域中选取最大值作为输出。
以 2x2 的池化窗口为例,最大池化的操作过程如下:
- 从输入特征图的左上角开始,取 2x2 的区域
- 找出该区域中的最大值作为输出
- 将窗口向右移动(通常步长等于窗口大小)
- 重复上述操作,直到处理完整个特征图
例如,对以下 4x4 区域使用 2x2 的池化窗口:
输入: 池化后:
1 3 2 4 5 7
5 2 7 1 8 9
3 8 4 2
6 1 5 9 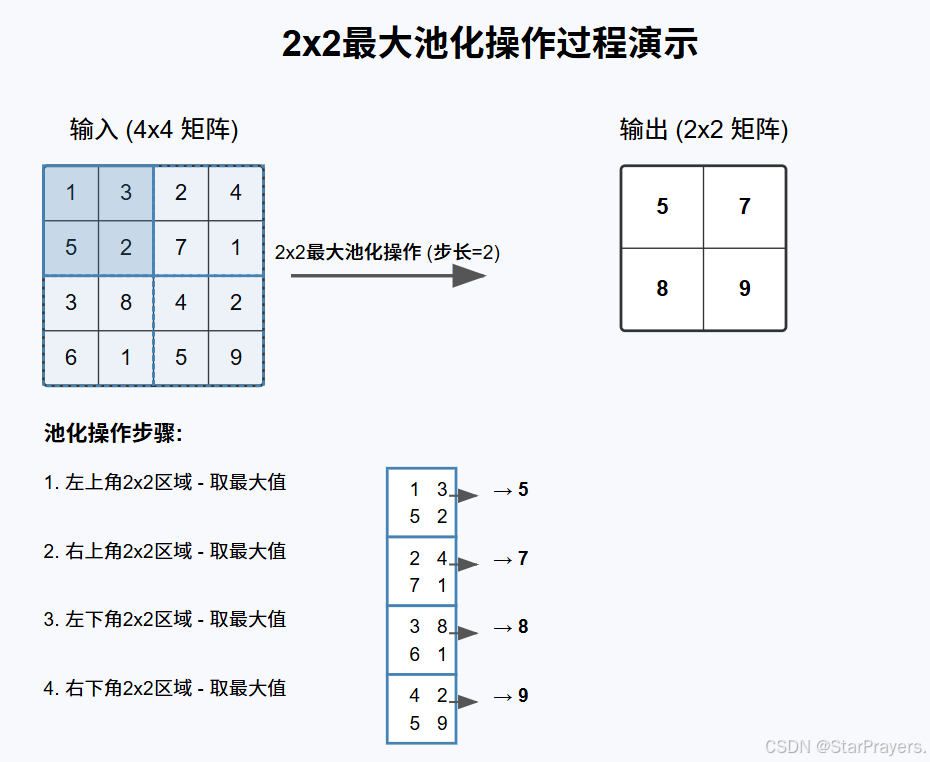
每个 2x2 区域的最大值构成了输出特征图。
三、运行代码后如何查看结果
运行代码后,在终端中执行以下命令启动 TensorBoard:
tensorboard --logdir=logs_maxpool
然后在浏览器中访问提示的地址,你将看到:
- 左侧面板可以切换查看原始图像和池化后的图像
- 池化后的图像尺寸明显变小,但保留了关键特征
- 图像的主要边缘和轮廓得以保留,细节信息减少
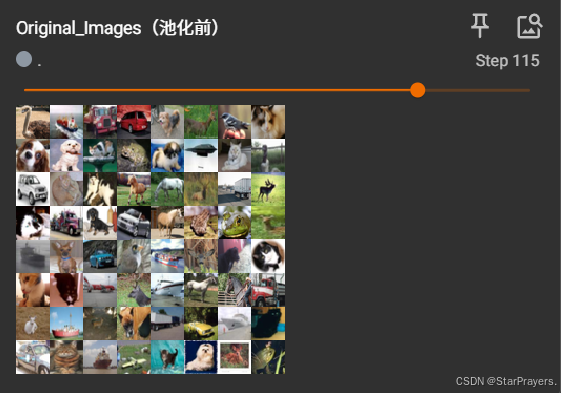
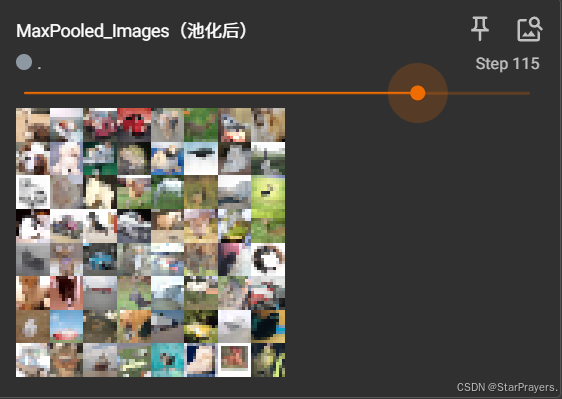
通过这种可视化方式,你可以直观理解最大池化如何保留重要特征同时减少数据量,这正是池化层在卷积神经网络中发挥的关键作用。
四、最大池化(Max Pooling)代码讲解
1. 数据准备部分
# 加载CIFAR10测试集(转换为Tensor格式)
dataset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=torchvision.transforms.ToTensor() # 输出形状[C, H, W],像素归一化到[0,1]
)# 创建数据加载器(批量大小64)
dataloader = DataLoader(dataset, batch_size=64)这里加载了 CIFAR10 数据集,每张图片的形状是[3, 32, 32](3 个颜色通道,32x32 像素)。通过 DataLoader 将数据按 64 张为一批进行处理。
2. 定义包含最大池化层的网络
class Prayer(nn.Module):def __init__(self):super(Prayer, self).__init__()# 3x3池化窗口,ceil_mode=True(边缘向上取整,避免丢失像素)self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):output = self.maxpool1(x)return outputMaxPool2d是 PyTorch 中的二维最大池化层kernel_size=3表示使用 3x3 的池化窗口ceil_mode=True表示当池化窗口不能整除输入尺寸时,使用向上取整计算输出尺寸
对于 32x32 的输入图像,使用 3x3 的池化窗口:
- 若
ceil_mode=True,输出尺寸为 11x11(32÷3=10.666,向上取整为 11) - 若
ceil_mode=False,输出尺寸为 10x10(向下取整)
3. 池化操作与可视化
# 初始化模型和TensorBoard写入器
prayer = Prayer()
writer = SummaryWriter("logs_maxpool")
step = 0# 遍历数据集,可视化池化前后的图像
for data in dataloader:imgs, targets = data # imgs形状:[64, 3, 32, 32]# 写入原始图像writer.add_images("Original_Images(池化前)", imgs, step)# 执行最大池化output = prayer(imgs) # output形状:[64, 3, 11, 11]# 写入池化后的图像writer.add_images("MaxPooled_Images(池化后)", output, step)step += 1writer.close()这段代码将原始图像和经过池化处理的图像都写入 TensorBoard,便于直观对比。
- 输入图像形状:
[64, 3, 32, 32](64 张图片,3 通道,32x32 像素) - 池化后形状:
[64, 3, 11, 11](空间尺寸减小,通道数不变)
4.完整代码
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 1. 加载CIFAR10测试集(转换为Tensor格式)
dataset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=torchvision.transforms.ToTensor() # 输出形状[C, H, W],像素归一化到[0,1]
)# 2. 创建数据加载器(批量大小64)
dataloader = DataLoader(dataset, batch_size=64)# 3. 定义仅含最大池化层的网络
class Prayer(nn.Module):def __init__(self):super(Prayer, self).__init__()# 3x3池化窗口,ceil_mode=True(边缘向上取整,避免丢失像素)self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)def forward(self, x):output = self.maxpool1(x)return output# 4. 初始化模型和TensorBoard写入器
prayer = Prayer()
writer = SummaryWriter("E:/pycharm/learn_pytorch/logs_maxpool")
# writer = SummaryWriter("../logs_maxpool") # 日志保存路径
step = 0# 5. 遍历数据集,可视化池化前后的图像
for data in dataloader:imgs, targets = data # imgs形状:[64, 3, 32, 32](批量64张,3通道,32x32像素)# 关键修正1:用add_images()处理批量图像(而非add_image())# add_images()支持4维张量[B, C, H, W],自动显示批量中的多张图writer.add_images("Original_Images(池化前)", imgs, step)# 对批量图像执行最大池化output = prayer(imgs) # output形状:[64, 3, 11, 11](32÷3向上取整=11)# 关键修正2:池化后的图像也用add_images()写入writer.add_images("MaxPooled_Images(池化后)", output, step)step += 1 # 步数递增,避免TensorBoard中图像重叠# 关闭写入器,释放资源
writer.close()
print("可视化完成!请启动TensorBoard查看结果。")五、其他常见的池化操作
1. 平均池化(Average Pooling)
- 原理:从池化窗口中取所有元素的平均值作为输出,而非最大值。
- 特点:保留区域整体特征,对噪声更稳健,但可能会弱化强信号(相比最大池化)。
- 适用场景:需要保留全局特征的场景,如语义分割的某些层、特征图平滑处理等。
- PyTorch 实现:
nn.AvgPool2d(kernel_size=2, stride=2) # 2x2窗口,步长2的平均池化2. 求和池化(Sum Pooling)
- 原理:取池化窗口中所有元素的总和作为输出。
- 特点:保留区域的强度信息,输出值可能比平均池化更大(未归一化)。
- 适用场景:较少单独使用,有时用于特定任务(如计数类任务)或自定义网络层。
3. 全局池化(Global Pooling)
- 原理:将整个特征图作为一个池化窗口,直接输出一个值(替代全连接层的常见方案)。
- 全局最大池化(Global Max Pooling):取整个特征图的最大值。
- 全局平均池化(Global Average Pooling):取整个特征图的平均值。
- 特点:极大减少参数数量,增强模型泛化能力,避免过拟合。
- 适用场景:卷积神经网络的末端(替代全连接层),如 ResNet、Inception 等网络。
- PyTorch 实现:
# 全局平均池化(对H×W维度全局池化)
nn.AdaptiveAvgPool2d((1, 1)) # 无论输入尺寸,输出固定为1x14. 随机池化(Stochastic Pooling)
- 原理:根据池化窗口中元素的数值大小分配概率,随机选择一个元素作为输出(值越大,被选中的概率越高)。
- 特点:引入随机性,类似 Dropout 的正则化效果,训练时随机选择,推理时等效于平均池化。
- 适用场景:需要防止过拟合的场景,在某些图像分类任务中表现优于最大池化。
5. 混合池化(Mixed Pooling)
- 原理:结合多种池化方式(如最大池化 + 平均池化),通过学习权重决定每种池化的贡献。
- 特点:兼顾不同池化的优势,更灵活,但会增加少量计算成本。
- 适用场景:需要自适应选择池化策略的复杂任务。
6. 可学习池化(Learnable Pooling)
- 原理:池化过程中的权重的权重是可学习的参数(而非固定操作),通过训练优化池化方式。
- 典型代表:
- 基于注意力的池化(Attention-based Pooling):给不同位置分配可学习的注意力权重。
- 胶囊网络(Capsule Network)中的动态路由(Dynamic Routing):一种特殊的可学习池化机制。
- 特点:灵活性高,能自适应任务需求,但结构更复杂。
六、各类池化的核心差异与选择
| 池化方式 | 核心操作 | 主要优势 | 典型应用场景 |
|---|---|---|---|
| 最大池化 | 取窗口最大值 | 保留局部显著特征(如边缘) | 图像分类、目标检测 |
| 平均池化 | 取窗口平均值 | 保留全局特征,抗噪声 | 语义分割、特征平滑 |
| 全局池化 | 对整个特征图池化 | 减少参数,防过拟合 | 替代全连接层 |
| 随机池化 | 按概率随机选择元素 | 正则化效果,提升泛化能力 | 防止过拟合的场景 |
| 可学习池化 | 权重通过训练优化 | 自适应任务需求 | 复杂场景、定制化网络 |
实际应用中,最大池化和平均池化是最常用的两种,全局池化在现代 CNN 中也被广泛采用(如 ResNet 用全局平均池化替代全连接层)。选择时需根据任务特点(如是否需要保留细节特征、是否容易过拟合等)决定。