去重表格的几种思路
Excel 本身自带的 去除重复项
1.找到数据选项卡,点击删除重复项

2.选择重复项的规则
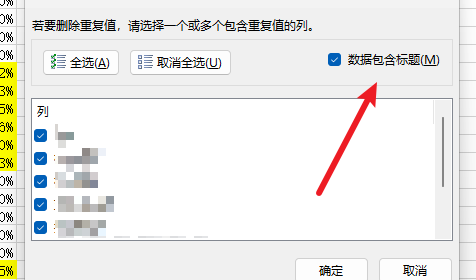
3.点击确认就可以了
Excel 公式
具体的场景是 现在有一个患者表,有姓名和年龄和出生日期,要对这个表进行去重判断
=IF(COUNTIFS(C$2:C$1000, C2, D$2:D$1000, D2, F$2:F$1000, F2)=1, "保留", "重复")
- 公式的设计思路
-
多条件去重:
传统去重可能只基于单列(如姓名),但实际业务中重复项常由多列共同定义(例如“姓名+日期+金额”唯一标识一条记录)。此公式通过COUNTIFS实现多列联合检查,确保准确性。 -
动态标识:
公式通过相对引用(如C2、D2、F2)在每行独立计算,当数据变化或新增行时,结果会自动更新(需拖动公式覆盖所有行)。 -
可视化标记:
输出“保留/重复”的文本标签,便于用户快速筛选(例如:使用Excel筛选功能过滤出“重复”行并删除)。
- 公式的具体讲解
这个公式用于基于多列条件标识数据中的唯一行或重复行。
具体来说:
-
COUNTIFS(C:C, C2, D:D, D2, F:F, F2):
这是一个多条件计数函数,检查整个数据范围内(C列、D列和F列)有多少行同时满足以下条件:
C列的值等于当前行(例如行2)的C2值。
D列的值等于当前行(例如行2)的D2值。
F列的值等于当前行(例如行2)的F2值。
返回值是满足这些条件的行数。
=1: -
将计数结果与1比较。如果计数等于1,说明当前行的C、D、F列值组合在整个数据中是唯一的(仅当前行符合);如果计数大于1,说明存在其他行具有相同的值组合(即重复)。
IF(…, “保留”, “重复”):
根据比较结果返回文本标签: -
如果计数为1,输出“保留”(表示该行唯一,应保留)。
如果计数大于1,输出“重复”(表示该行是重复项,可考虑删除或处理)。
Excel power query
-
步骤 1:将数据转换为 “表格”(Power Query 处理的前提)
打开 Excel,选中你的数据区域(包括标题行,比如从 A1 到 F100000)。
如果数据有标题行(如 “性别”“出生日期”“姓名”),一定要包含在内。
点击菜单栏「数据」→ 点击「从表格 / 区域」(在 “获取和转换数据” 组中)。
在弹出的 “创建表格” 对话框中,确认 “表包含标题” 已勾选(默认会自动识别),点击「确定」。
此时数据会变成蓝色的 “超级表”,并自动打开 Power Query 编辑器。 -
步骤 2:在 Power Query 中删除重复项
在 Power Query 编辑器中,找到你需要作为去重依据的列:
按住Ctrl键,依次点击列标题:性别(C 列)、出生日期(D 列)、姓名(F 列)(选中后列标题会变成橙色)。
点击菜单栏「开始」→ 点击「删除行」→ 选择「删除重复项」(在 “行” 组中)。
此时 Power Query 会自动删除这三列组合重复的行,只保留唯一值。
操作完成后,你会看到编辑器底部提示 “已移除 XX 个重复项”。 -
步骤 3:将处理结果加载回 Excel
点击 Power Query 编辑器左上角的「关闭并加载」→ 选择「关闭并加载」(默认选项)。
Excel 会自动新建一个工作表,展示去重后的结果(包含所有列,但已移除重复的患者记录)
pandas 代码 使用drop_duplicates进行简单去重
代码说明:
- 读取数据:pd.read_excel() 读取 Excel 文件,parse_dates=[“出生日期”] 确保出生日期被正确识别为日期类型(避免因格式不一致导致的去重错误,比如文本格式的 “2000/1/1” 和日期格式的 “2000-1-1” 被误判为不同)。
- 去重核心:drop_duplicates() 是 pandas 去重的核心函数:
- subset=[“性别”, “出生日期”, “姓名”]:指定以这三列的组合作为去重判断依据(完全相同才视为重复)。
- keep=“first”:保留第一次出现的记录,删除后续重复项(也可设为keep="last"保留最后一次出现的记录)。
保存结果:to_excel() 将去重后的数据保存到新文件,避免覆盖原始数据。
import pandas as pd# 1. 读取Excel文件(替换为你的文件路径)
# 注意:sheet_name指定工作表名称,默认为第一个工作表
df = pd.read_excel("患者数据.xlsx",sheet_name="Sheet1", # 替换为你的工作表名称parse_dates=["出生日期"] # 将"出生日期"列解析为日期格式(避免格式问题导致去重错误)
)# 2. 查看原始数据量
print(f"去重前数据行数:{len(df)}")# 3. 去重核心操作
# 基于"性别"、"出生日期"、"姓名"三列组合去重
# keep="first"表示保留第一次出现的记录,其他重复项删除
df_unique = df.drop_duplicates(subset=["性别", "出生日期", "姓名"], # 去重依据的列keep="first", # 保留第一个重复项inplace=False # 不修改原数据,返回新的去重后的数据框
)# 4. 查看去重后的数据量
print(f"去重后数据行数:{len(df_unique)}")
print(f"共移除重复项:{len(df) - len(df_unique)} 条")# 5. 将去重结果保存到新的Excel文件(避免覆盖原数据)
df_unique.to_excel("患者数据_去重后.xlsx",sheet_name="去重结果",index=False # 不保存索引列
)print("去重完成,结果已保存至:患者数据_去重后.xlsx")