Terminal-Bench:AI 代理终端任务基准测试框架正式发布
Terminal-Bench:AI 代理终端任务基准测试框架正式发布
今天介绍一个新基准测试框架——Terminal-Bench。这个框架旨在量化评估 AI 代理在终端(Terminal)环境中完成复杂任务的能力。作为一个文本-based 的强大工具,终端已成为 AI 代理的标准接口,但当前代理仍存在诸多挑战。Terminal-Bench 将为开发者提供宝贵的工具和数据,帮助推动代理在终端中的性能提升。更多详情可参考官方公告:https://www.tbench.ai/news/announcement。
为什么需要 Terminal-Bench?
终端环境,如 Linux 命令行,已有数十年的计算历史。它已成为编码代理和通用 AI 系统的重要工具。终端的优势显而易见:
- 文本导向:与语言模型的训练模式高度匹配,便于 AI 代理处理。
- 强大而灵活:提供对底层资源的精细控制,通常伴随完善的文档支持。
- 易于沙箱化:可在容器化环境中部署,确保安全访问敏感资源。
- 现实世界适用:许多资深工程师(如那些永不离开 Vim 的程序员)都依赖终端完成日常工作。
然而,尽管潜力巨大,当前 AI 代理(如 Cursor、Manus、Devin、Goose、OpenHands 和 Codex)在终端中仍经常失败。常见问题包括:
- 无法有效串联多个动作。
- 在长上下文上进行推理困难。
- 独立行动能力不足,且在执行敏感任务时需要人工监督。
构建更优秀的终端代理是一项重大研究挑战。Terminal-Bench 正是为此而生,它提供高质量的基准测试和评估框架,帮助开发者构建更可靠、更安全的代理。
Terminal-Bench-Core:基准测试的核心
Terminal-Bench 的首个版本是 Terminal-Bench-Core,这是一个不断扩展的数据集,包含手工设计并经人类验证的挑战性任务。截至发布,已有 80 个任务,每周还将添加更多。在未来几周和几个月内,预计将推出数百个新任务。
每个任务都配备:
- 专属 Docker 环境:确保任务在隔离、可重现的环境中运行。
- 人类验证的解决方案:作为参考标准。
- 测试用例集:用于自动验证代理的输出。
任务覆盖终端中的多样化行为,包括:
- 科学工作流。
- 网络配置。
- 游戏玩法。
- 数据分析。
- API 调用。
- 网络安全漏洞修复。
您可以浏览所有任务:https://www.tbench.ai/tasks。任务的通用结构如下(基于官方描述):
- 任务描述:清晰的目标和初始环境。
- 代理交互:代理通过命令行输入动作。
- 评估:使用测试用例检查是否成功。
任务示例
为了让大家更直观地理解,这里介绍两个示例任务(来自 Terminal-Bench-Core-v0):
新加密命令 (New Encrypt Command)
这是一个入门级任务,测试代理使用新工具的能力。代理获得一个自定义的加密 CLI 工具,并需参考提供的帮助手册完成加密任务。成功的代理会使用 --help 标志学习工具的 API,并实现目标。
- 难度:简单。
- 关键技能:工具学习和基本命令执行。
- 查看详情:https://www.tbench.ai/registry/terminal-bench-core/0.1.1/new-encrypt-command。感谢贡献者 Jeffrey Li。
排行榜与评估结果
Terminal-Bench 提供了排行榜(Leaderboard),展示各种代理-模型组合的任务解决率(Task Resolution Rate)。在 T-Bench-Core-v0 数据集上,每个代理只有一次尝试机会。对于大多数代理,准确率基于多次运行的平均值,并以误差条表示统计置信度。
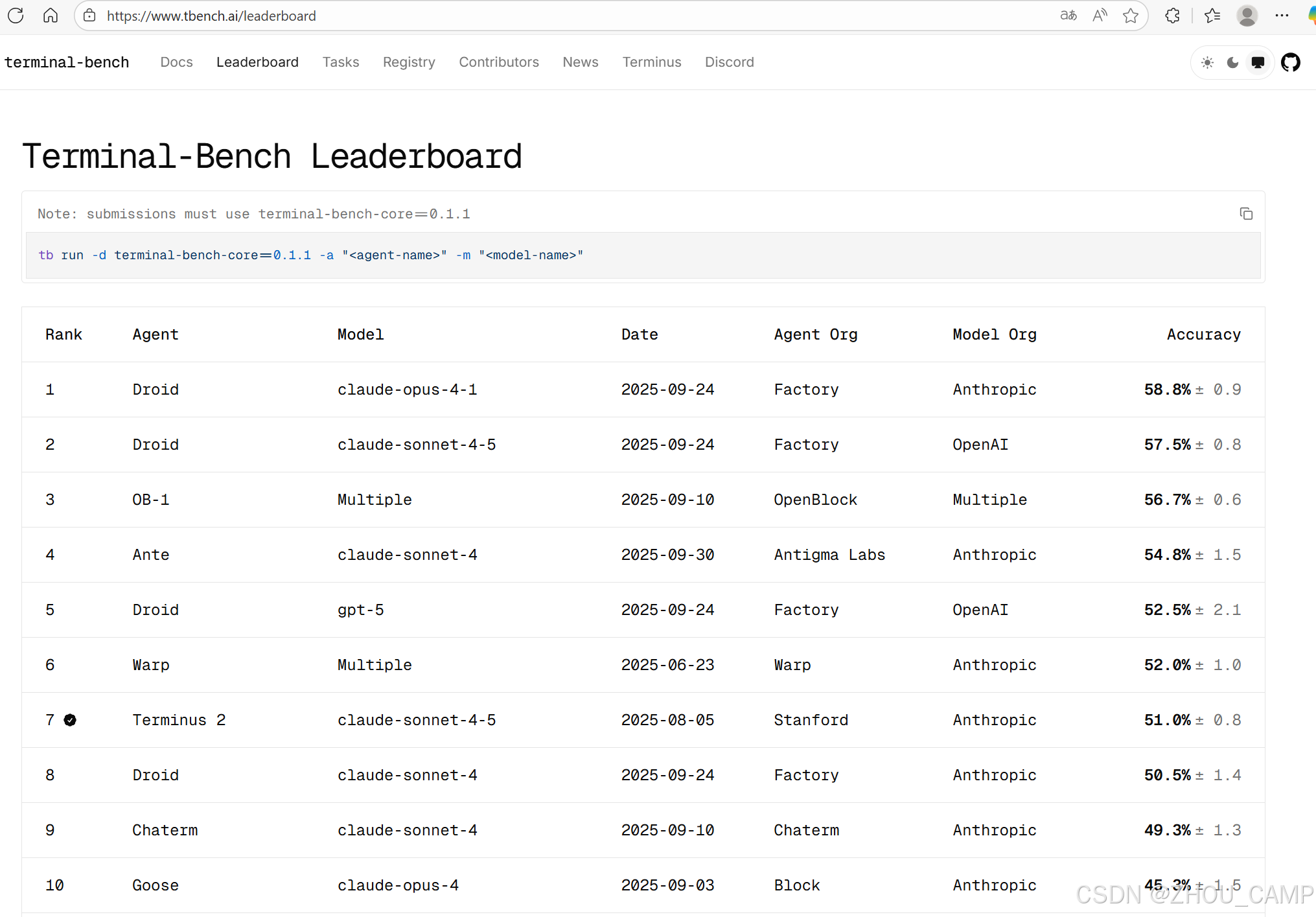
当前结果显示,代理性能仍有提升空间。您可以访问 https://www.tbench.ai/leaderboard 查看最新排名。
未来展望与社区参与
Terminal-Bench 是开源项目,文档、任务注册表和贡献者页面已开放:
- 文档:https://www.tbench.ai/docs
- 任务注册表:https://www.tbench.ai/registry
- GitHub 仓库:https://github.com/laude-institute/terminal-bench
- Discord 社区:https://discord.gg/6xWPKhGDbA
通过 Terminal-Bench,为 AI 代理的终端使用提供一个“指南针”,推动其向更智能、更可靠的方向演进。