Qwen2-Audio系列学习笔记
模型介绍
GitHub - QwenLM/Qwen2-Audio: The official repo of Qwen2-Audio chat & pretrained large audio language model proposed by Alibaba Cloud.
https://arxiv.org/pdf/2407.10759
https://zhuanlan.zhihu.com/p/712987238
We introduce the latest progress of Qwen-Audio, a large-scale audio-language model called Qwen2-Audio, which is capable of accepting various audio signal inputs and performing audio analysis or direct textual responses with regard to speech instructions. We introduce two distinct audio interaction modes:
- voice chat: users can freely engage in voice interactions with Qwen2-Audio without text input;
- audio analysis: users could provide audio and text instructions for analysis during the interaction;
We've released two models of the Qwen2-Audio series: Qwen2-Audio-7B and Qwen2-Audio-7B-Instruct.
根据 Qwen2-Audio 技术报告,它在语音聊天和音频分析之间实现了无缝切换,不需要明确的系统提示。这两种模式是联合训练的,用户可以自然地与模型交互,模型会根据输入(语音或文本)智能地理解用户的意图,并自动选择适合的模式。
- 语音聊天模式:允许用户进行自由的语音对话,可以直接通过语音与模型互动并获取实时响应。
- 音频分析模式:用户可以通过音频或文本输入,要求模型对音频内容进行分析,例如检测声音、对话或其他音频信息。
这种设计使得用户无需手动切换模式,模型会根据交互内容自动适应两种模式的需求,提供流畅的用户体验。
- 2024.8.9 🎉 We released the checkpoints of both
Qwen2-Audio-7BandQwen2-Audio-7B-Instructon ModelScope and Hugging Face. - 2024.7.15 🎉 We released the paper of Qwen2-Audio, introducing the relevant model structure, training methods, and model performance. Check our report for details!
- 2023.11.30 🔥 We released the Qwen-Audio series.
预训练
训练策略
Model Architecture The training process of Qwen2-Audio is depicted in Figure 2, which contains an audio
encoder and a large language model. Given the paired data (a,x), where the a and x denote the audio
sequences and text sequences, the training objective is to maximize the next text token probability as
Pθ(xt|x<t,Encoderϕ(a)),(1) conditioning on audio representations and previous text sequences x<t, where θ and ϕ denote the trainable parameters of the LLM and audio encoder respectively.
Different from Qwen-Audio, the initialization of the audio encoder of Qwen2-Audio is based on the Whisper large-v3 model (Radford et al., 2023). To preprocess the audio data, we resamples it to a frequency of 16kHz and converts the raw waveform into 128-channel mel-spectrogram using a window size of 25ms and a hop size of 10ms. Additionally, a pooling layer with a stride of two is incorporated to reduce the length of the audio representation. As a result, each frame of the encoder output approximately corresponds to a 40ms segment of the original audio signal. Qwen2-Audio still incorporates the large language model Qwen-7B (Bai et al., 2023) as its foundational component. The total parameters of Qwen2-Audio is 8.2B parameters.
训练过程如图2所示,其中包含一个音频编码器和一个大型语言模型。给定配对数据(a, x),其中a和x表示音频序列和文本序列,训练目标是最大化下一个文本标记的概率为:
以音频表示和以前的文本序列x<t为条件,其中θ和φ分别表示LLM和音频编码器的可训练参数。
与Qwen2-Audio不同的是,Qwen2-Audio的音频编码器初始化是基于Whisperlarge-v3模型。
Qwen2-Audio仍然将大型语言模型Qwen-7B作为其基础组件。
Qwen2-Audio的总参数为8.2亿个参数。
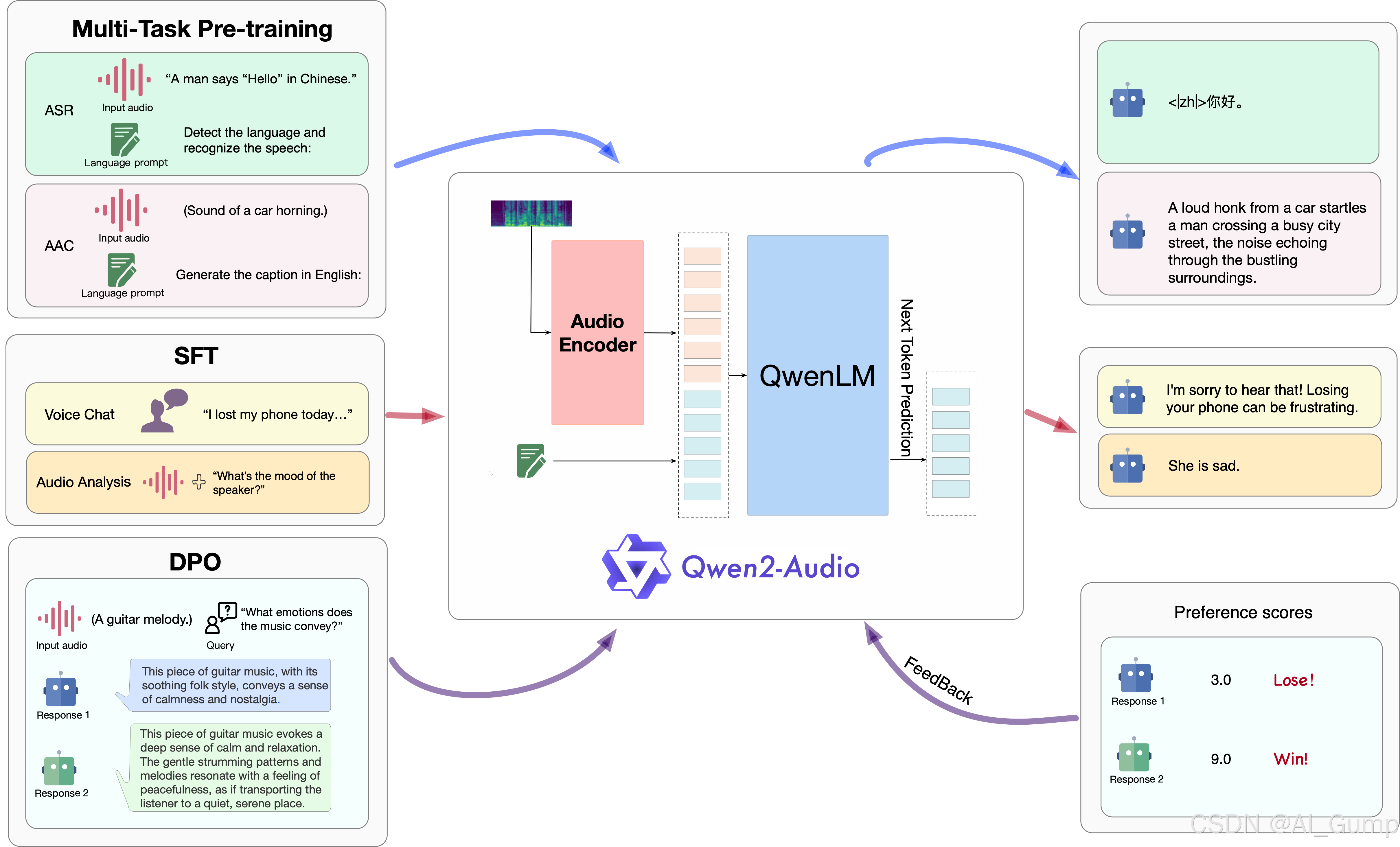
Pre-training 预训练阶段
At the pre-training stage, we replace the hierarchical tags (Chu et al., 2023) with the nat ural language prompts. As shown in Figure 2. We find that using language prompts can improve better generalization ability and better instruction following ability.
在预训练阶段,我们将分层标签替换为自然语言提示。如图2所示。我们发现,使用语言提示可以提高更好的泛化能力和更好的指令跟随能力。
Supervised Fine-tuning 监督微调阶段
The thorough pretraining of Qwen2-Audio has equipped the model with a comprehensive understanding of audio content. Building upon this, we employ instruction-based fine-tuning techniques to improve the ability of the model to align with human intent, resulting in an interactive chat model.
Our prelimilary study emphasizes the critical influence of the quality and complexity of SFT data on the model’s performance. Accordingly, a meticulously curated set of high-quality SFT data was collected, with rigorous quality control procedures implemented
We consider two distinct modes for human interactions:
• AudioAnalysis: In the audio analysis mode, users are afforded the flexibility to have Qwen2-Audio analyze a diverse array of audio. User instructions can be given either through audio or text. This mode is often used for offline analysis of audio files.
• Voice Chat: In the voice chat mode, users are encouraged to engage in voice conversations with Qwen2-Audio, asking a wide range of questions. Please feel free to consider it your voice chat assistant.
This mode is often used for online interaction with LALMs. For consistency and model uniformity, both interaction modes were jointly trained, thus users will not experience mode differentiation during use, nor is it necessary to switch between different modes using separate system prompts. The two modes are seamlessly integrated in actual use
Qwen2-Audio 的彻底预训练配备了对音频内容的全面理解的模型。在此基础上,我们采用基于指令的微调技术来提高模型与人类意图对齐的能力,从而产生交互式聊天模型。
我们的初步研究强调了SFT数据的质量和复杂性对模型性能的关键影响。因此,收集了一组精心策划的高质量SFT数据,实现了严格的质量控制程序。
我们考虑两种不同的人机交互模式:
•音频分析: 在音频分析模式下,用户可以灵活地使用Qwen2-Audio分析各种音频。用户指令可以通过音频或文本给出。该模式通常用于音频文件的离线分析。
•语音聊天:在语音聊天模式下,鼓励用户与Qwen2-Audio进行语音对话,询问各种问题。把它当作你的语音聊天助手。这种模式通常用于与lalm进行在线交互。
为了一致性和模型的统一性,两种交互模式是联合训练的,用户在使用过程中不会出现模式差异,也不需要使用单独的系统提示在不同模式之间切换。两种模式在实际使用中无缝结合。
Direct Preference Optimization偏好优化
We employ DPO (Rafailov et al., 2024) to further optimize models to follow human preferences
我们使用 DPO 进一步优化模型以遵循人类偏好。
评测
We evaluated the Qwen2-Audio's abilities on 13 standard benchmarks as follows:
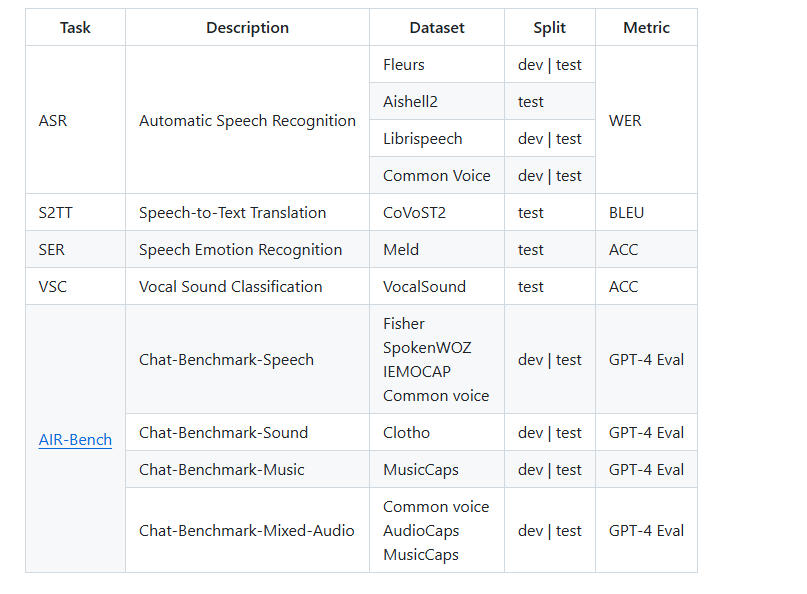
语音转文字翻译 (Speech-to-Text Translation, S2TT) 是一个引人注目的研究和应用领域,它将一种语言的语音转换为另一种语言的文本,从而实现无缝跨语言交流。
近年来的一项创新是使用端到端(E2E)模型,将音频编码和文本解码整合到一个过程之中。这种方法相比传统的分级系统减少了延迟,并最大限度地减少错误传播。例如,SeamlessM4T 模型 不仅支持 S2TT,还支持语音到语音和文本到文本的翻译,涵盖近百种语言。另一个创新方法是使用解码器式的大型语言模型 (LLMs),它们能直接处理语音表征以生成翻译文本。
在语音转文字翻译 (S2TT) 中,BLEU (Bilingual Evaluation Understudy) 是一种常用的评估指标,用于衡量机器翻译结果与人工参考翻译之间的相似度。它通过比较翻译文本中的n-grams(如单词、双词组等)与参考翻译中的 n-grams 的匹配程度来计算分数。
具体来说,BLEU 分数的范围是从 0 到 1,其中:
- 1 表示机器翻译与参考翻译完全一致(这种情况非常罕见)。
- 0 表示没有任何匹配。
在 CoVoST2 数据集的测试中,BLEU 分数用于评估模型在不同语言对之间的翻译质量。例如,英语到德语 (en-de) 或中文到英语 (zh-en) 的翻译性能。分数越高,说明模型生成的翻译越接近人工翻译
推理
Voice Chat Inference
conversation = [
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"},
]},
{"role": "assistant", "content": "Yes, the speaker is female and in her twenties."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/translate_to_chinese.wav"},
]},
]第一个url的音频:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav,是一个年轻女生说法,让模型猜测性别和年年;“I heard that you can understand what people say and even know their're age and gender so can you guess my age and gender from my voice?”
第二个url的音频:“Everyone wants to be appreciated, so if you appreciate someone, don't keep it a secret.”
Audio Analysis Inference
conversation = [
{'role': 'system', 'content': 'You are a helpful assistant.'},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/glass-breaking-151256.mp3"},
{"type": "text", "text": "What's that sound?"},
]},
{"role": "assistant", "content": "It is the sound of glass shattering."},
{"role": "user", "content": [
{"type": "text", "text": "What can you do when you hear that?"},
]},
{"role": "assistant", "content": "Stay alert and cautious, and check if anyone is hurt or if there is any damage to property."},
{"role": "user", "content": [
{"type": "audio", "audio_url": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/1272-128104-0000.flac"},
{"type": "text", "text": "What does the person say?"},
]},
]第一个audio_url是一个玻璃打碎的声音;
第二个audio_url对应的内容是:“mr quilter is the apostle of the middle classes and we are glad to welcome his gospel.”
Batch Inference
Batch Inference 是指一次性对多个输入数据进行推理或预测的过程,而不是逐一单独处理每个输入。这种方法常用于提高机器学习模型的处理效率,尤其是在批量数据处理中。
例如,在语音处理任务中,如语音转文字翻译(S2TT),如果您有多个音频文件需要转换和翻译,可以将它们打包成一个批次(batch)输入模型。这不仅能充分利用硬件资源(如 GPU 的并行计算能力),还可以减少每次单独加载数据的开销,从而提升整体性能。
以下是 Batch Inference 的优点:
- 高效性:同时处理多个输入可以减少时间开销。
- 一致性:确保对数据处理的设置和模型参数保持一致。
- 资源优化:充分利用硬件的计算能力,尤其是 GPU。
总结
In this paper, we present Qwen2-Audio, which builds upon Qwen-Audio’s capability to analyze various types of audio while also being endowed with voice interaction abilities.
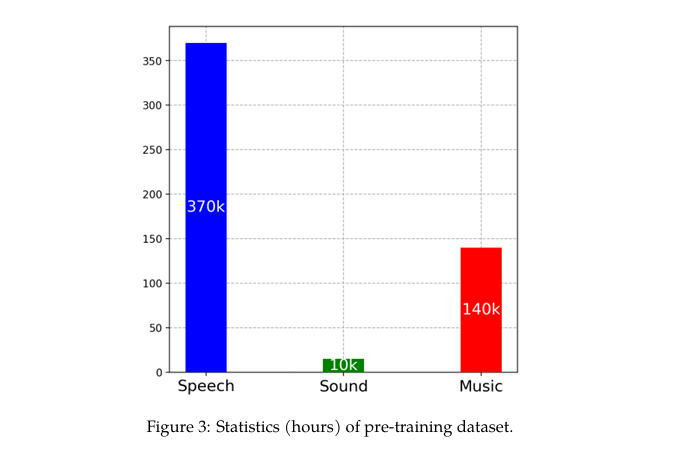
During the pre-training stage, we utilized natural language prompts for different data and tasks and have further expanded the data volume.
In the SFT phase, we enhanced Qwen2-Audio’s alignment with human interaction by increasing the quantity, quality, and complexity of SFT data, thereby enabling seamless voice and text interactions. Additionally, we improved Qwen2-Audio’s response quality through the DPO stage.
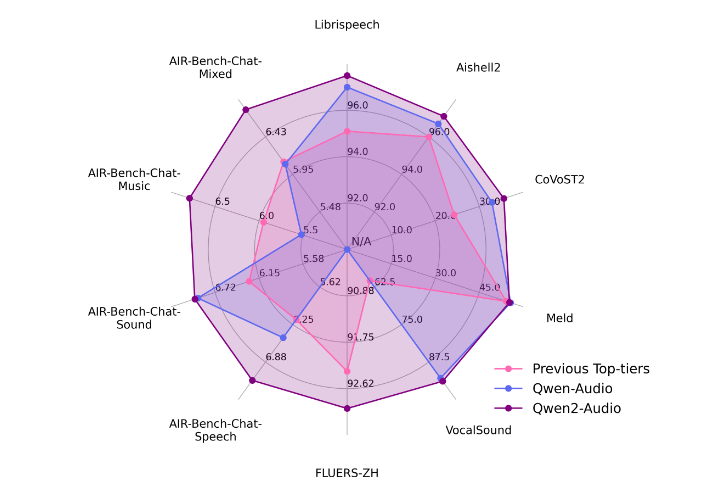
Objective metrics tested on diverse benchmarks demonstrate Qwen2-Audio’s proficiency in audio understanding and dialogue capabilities. The cases presented within the paper also illustrate Qwen2-Audio’s fluent and flexible voice interaction capability.
在本文中,我们提出了Qwen2-Audio,它建立在Qwen2-Audio分析各种类型音频的能力的基础上,同时也被赋予了语音交互能力。
在预训练阶段,我们对不同的数据和任务使用自然语言提示,进一步扩大了数据量。
在SFT阶段,我们通过增加SFT数据的数量、质量和复杂性来增强Qwen2-Audio与人类交互的一致性,从而实现无缝的语音和文本交互。
此外,我们通过DPO阶段提高了Qwen2-Audio的响应质量。
在不同的基准测试中,客观指标证明了Qwen2-Audio在音频理解和对话能力方面的熟练程度。
case study也说明了Qwen2-Audio流畅灵活的语音交互能力
上手实战
说明
音频分析模式,对应着阿里百炼的音频理解能力,
音频理解_大模型服务平台百炼(Model Studio)-阿里云帮助中心
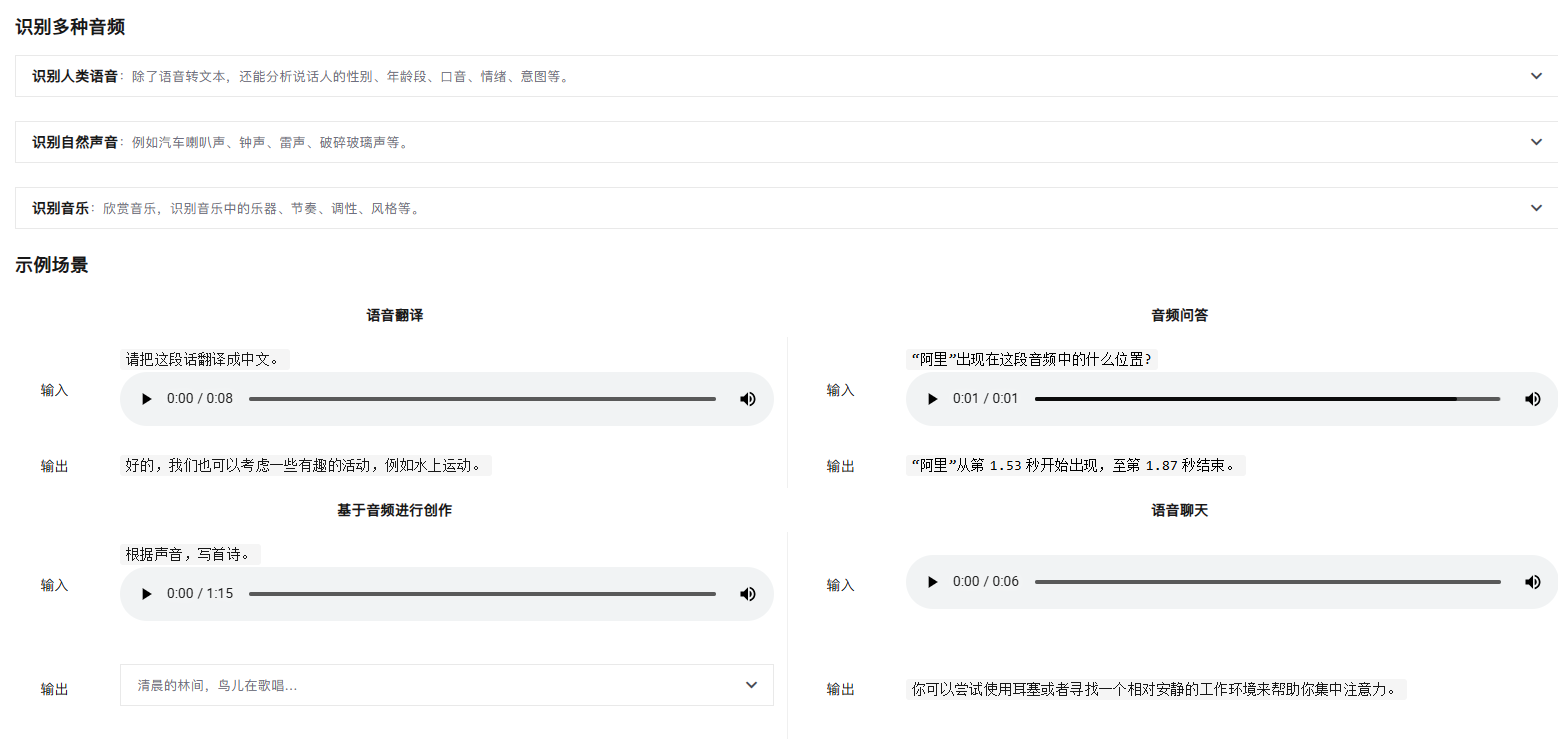
模型可使用开源的

- 支持的音频文件
-
- 音频文件大小不超过10 MB。
- 音频的时长建议不超过30秒,如果超过30秒,模型会自动截取前30秒的音频。
- 音频文件的格式支持大部分常见编码的音频格式,例如AMR、WAV(CodecID: GSM_MS)、WAV(PCM)、3GP、3GPP、AAC、MP3等。
- 音频中支持的语言包括中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
代码
#
# https://help.aliyun.com/zh/model-studio/user-guide/audio-language-model?spm=a2c4g.11186623.help-menu-2400256.d_1_0_3.68cb695bPKCWAZ&scm=20140722.H_2845960._.OR_help-T_cn~zh-V_1#a78bd7546c4v4
# 支持语音对话
# 支持流式输出文本
# 支持音频理解
# 支持多轮对话
import os
import dashscope
from dashscope import MultiModalConversation
print('\r\Voice Conversation with nincremental_output Demo')
messages = [
{
"role": "user",
"content": [
{"audio": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20240916/kvkadk/%E6%8E%A8%E8%8D%90%E4%B9%A6.wav"}#对话,对应的文本“我想读一些文学类的书,有推荐吗”
]
}
]
response = dashscope.MultiModalConversation.call(
#api_key=os.getenv("DASHSCOPE_API_KEY"),
model='qwen-audio-turbo-latest',
messages=messages,
stream=True,
incremental_output=True,
result_format="message")
print(response)
for chunk in response:
print(chunk)
print('\r\nMultiModalConversation Demo')
messages = [
{
"role": "user",
"content": [
{"audio": "https://dashscope.oss-cn-beijing.aliyuncs.com/audios/welcome.mp3"},#文件对应的文本‘欢迎使用阿里云’
{"text": "这段音频在说什么?"},
]
}
]
response = MultiModalConversation.call(model='qwen-audio-turbo-latest', messages=messages)
print("第1次回复:", response)
# 将模型回复到messages中,并添加新的用户消息
messages.append({
'role': response.output.choices[0].message.role,
'content': response.output.choices[0].message.content
})
messages.append({
"role": "user",
"content": [
{"text": "简单介绍这家公司。"}
]
})
response = MultiModalConversation.call(model='qwen-audio-turbo-latest', messages=messages)
print("第2次回复:", response)
print('\r\nMultiModalConversation Demo')
# 请用您的本地音频的绝对路径替换 ABSOLUTE_PATH/welcome.mp3
audio_file_path = "guess_age_gender.wav"
messages = [
{
"role": "system",
"content": [{"text": "You are a helpful assistant."}]},
{
"role": "user",
"content": [{"audio": audio_file_path}, {"text": "音频里在说什么?"}],
}
]
response = MultiModalConversation.call(model="qwen-audio-turbo-latest", messages=messages)
print(response)
audio_file_path = "translate_to_chinese.wav"
messages = [
{
"role": "system",
"content": [{"text": "You are a helpful assistant."}]},
{
"role": "user",
"content": [{"audio": audio_file_path}, {"text": "音频里在说什么?"}],
}
]
response = MultiModalConversation.call(model="qwen-audio-turbo-latest", messages=messages)
print(response)
audio_file_path = "1272-128104-0000.flac"
messages = [
{
"role": "system",
"content": [{"text": "You are a helpful assistant."}]},
{
"role": "user",
"content": [{"audio": audio_file_path}, {"text": "音频里在说什么?"}],
}
]
response = MultiModalConversation.call(model="qwen-audio-turbo-latest", messages=messages)
print(response)
# 将模型回复到messages中,并添加新的用户消息
messages.append({
'role': response.output.choices[0].message.role,
'content': response.output.choices[0].message.content
})
messages.append({
"role": "user",
"content": [
{"text": "翻译成中文。"}
]
})
response = MultiModalConversation.call(model='qwen-audio-turbo-latest', messages=messages)
print("第2次回复:", response)其它
Qwen-Audio的ASR专用优化版本
通义千问ASR基于Qwen-Audio训练的专用于语音识别的模型,支持中英文识别。目前为Beta版本。
通义千问Audio模型按输入和输出的总Token数进行计费。
音频转换为Token的规则:每一秒钟的音频对应25个Token。若音频时长不足1秒,则按25个Token计算。
虽然通义千问ASR基于Qwen-Audio进行训练,但它不支持多轮对话和自定义的System Prompt及User Prompt。
语音识别_大模型服务平台百炼(Model Studio)-阿里云帮助中心