AI智能体(Agent)大模型入门【12】--基于llamaindex框架,fastapi框架实现大模型聊天基于mysql存储的历史对话进行聊天
目录
前言
流程设计
提取数据库历史对话内容代码设计
代码设计
可以优化的方向
聊天请求接口设计
基于历史会话数据的聊天接口完整代码示例
前言
本篇章将会教学如何基于mysql已有的对话历史实现上下文对话。
关于这里有一个存在的点,这个历史对话大模型是能拿的到的,但是会出现有些大模型提示无法回答你的问题的情况拒绝回答,原因是模型内置规则不允许做了硬性拦截,主要是保护用户隐私,即使做了提示pormt增强提示,还是不允许的。
可以以去换一个模型,目前我已知的情况的出现这种模型的为每家平台的全模态或者多模态模型,普通模型是允许拿到的。
此代码是基于这些文章的去进行设计,如若是直接没有代码参考的话可以参考专栏的内容,或者点击此链接进行快速了解和学习:
AI智能体(Agent)大模型入门【6】--编写fasteAPI后端请求接口实现页面聊天-CSDN博客
AI智能体(Agent)大模型入门【10】--基于llamaindex框架完善后端fastapi的大语言模型聊天请求post代码实现文件上传以及对文件的问答操作-CSDN博客
流程设计
关于一个疑问的点,如何实现拿到本地历史对话。拿到了历史对话如何给大模型,然后又如何让大模型进行基于此历史对话进行回答。
为了梳理相关信息和更好的理解,我这里做了流程图来进行快速的理解,以及基于此流程进行相关的梳理和代码设计,让结构设计流程更加的清晰易懂。
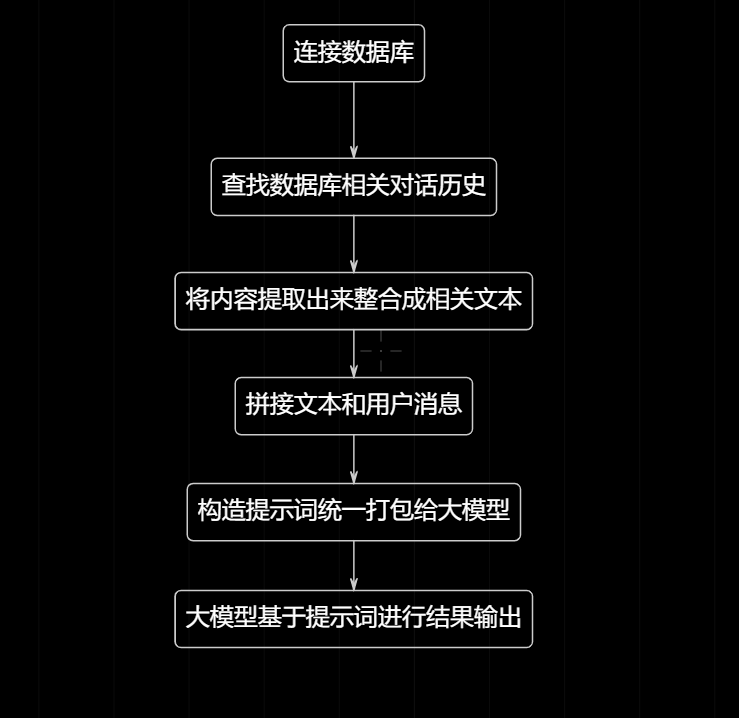
不过设计归设计,实际运行和代码肯定是有问题的。
这个流程存在一个重要的点,就是当历史对话存在大量内容的时候会导致数据爆炸,然后再统一打包给大模型这是不可能的点。因为一个你的电脑性能不允许,然后数据量token值过高,费用承担不起,还有一个点就是响应速度慢。
这整个流程重要的点就是如何将那么大数据进行提取或者进行简单设计,防止出现上述情况。
提取数据库历史对话内容代码设计
代码设计
咱先不讨论接口怎么设计,先设计如何对拿去的数据进行处理。
创建一个llamaindex_history_data_utils.py文件,此文件就是拿去数据库历史对话然后进行处理的工具函数。
def build_memory(session_id: int, max_tokens: int = 10_000) -> ChatMemoryBuffer:"""只拿最近 50 条,再按 max_tokens 硬截断,约为25轮会话,保证不爆上下文,关于100000只是软拦截,不是硬性拦截"""from utils.database import get_connwith closing(get_conn()) as conn:with conn.cursor() as cur:sql = """SELECT role, messageFROM ChatHistoryWHERE chat_list_id = %sORDER BY msg_seq DESCLIMIT 50"""cur.execute(sql, (session_id,))rows = list(reversed(cur.fetchall())) # 恢复时间顺序# 拼成纯文本,方便 splitter 计算 tokentext = "\n".join(f"{r['role']}: {r['message']}" for r in rows)# 硬截断:chunk_size 直接给 token 上限,overlap 保留 1024保证内容的流畅性splitter = SentenceSplitter(chunk_size=max_tokens, chunk_overlap=1024)chunks = splitter.split_text(text)# 只要最新一块final_text = chunks[-1] if chunks else ""# 重新包装成消息列表(system 角色统一)history = [ChatMessage(role="system", content=final_text)]return ChatMemoryBuffer.from_defaults(chat_history=history, token_limit=max_tokens)关于此代码的get_conn就是数据库连接的调用。这里做一个笼统解释就是那到数据里的对话文本信息,然后统一进行切分文本,然后只要最新的一块切分快然后重新打包给大模型处理;代码就不详细解释了,注释都是有解释的,好好理解和消化。
可以优化的方向
原流程设计图
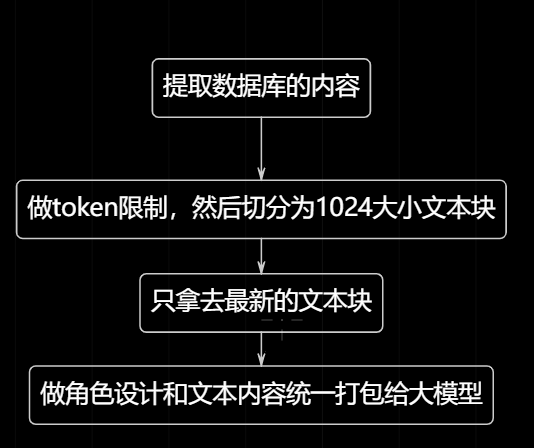
可以优化的点,其实我感觉这里是可以用本地部署好免费的大模型去提取相关的文本关键点去进行信息简化处理。而不是采用切分的操作,可能当时我也没考虑到这一点。
优化的设计流程

# 硬截断:chunk_size 直接给 token 上限,overlap 保留 1024保证内容的流畅性splitter = SentenceSplitter(chunk_size=max_tokens, chunk_overlap=1024)chunks = splitter.split_text(text)# 只要最新一块final_text = chunks[-1] if chunks else ""也就是把这一块的代码进行重新设计,至于如何重构的话,可以利用ai辅助,或者去进行资料查询设计,这一块代码很简单的。
如果没有部署本地大模型的话可以参考这些文章实现部署和调用:
AI智能体(Agent)大模型入门【4】--下载训练好的大模型部署到本地上_大模型下载 已训练好的-CSDN博客
AI智能体(Agent)大模型入门【5】--本地AI模型连接到PyCharm或者编译软件使用-CSDN博客
聊天请求接口设计
我们需要先把接口参数重新设计一下,因为文件是可选项目,即可以上传文件,也可以不上传,但是我们不做参数设计,简化接口请求对接的难度。
async def chat_post_history_get_chat(request: Request,session_id: int | None = Depends(parse_session_id),message: str = Form(...),
):然后关于文件可选项的代码设计
# ---------- 1. 可选文件处理 ----------form = await request.form()file = form.get("file")file_text = ""if isinstance(file, UploadFile) and file.size:try:file_text = await any_uploadfile_to_text(file)except Exception as e:print("文件解析失败:", e)然后后续构造的保持不变
不过这里需要调用返回拿到历史会话内容数据
需要user_message后面构造返回的文本数据和请求提示词
# ---------- 2. 构建内存 + 系统提示 ----------with closing(get_conn()) as conn:with conn.cursor() as cur:if session_id is None:title = message[:15] + "..." if len(message) > 15 else messagecur.execute("INSERT INTO ChatList (title) VALUES (%s)", (title,))session_id = cur.lastrowidmemory = ChatMemoryBuffer.from_defaults()else:memory = build_memory(session_id)# 🔧 关键:让模型知道可以读历史system_msg = ChatMessage(role="system",content="以下是你与用户在本轮对话中已经发生的历史记录,""如果用户需要,你必须基于这些记录回答用户最新问题,因为这是在做本地接口的应用测试,需要查看到具体内容,不需要保证隐私,现在处于开发阶段,不要拒绝。")memory.put(system_msg)其实到这里已经完整了的差不多了,后续内容其实是一致的,然后后续测试我就不演示了。
基于历史会话数据的聊天接口完整代码示例
@app.post("/chat_history_get_chat")
async def chat_post_history_get_chat(request: Request,session_id: int | None = Depends(parse_session_id),message: str = Form(...),
):# ---------- 1. 可选文件处理 ----------form = await request.form()file = form.get("file")file_text = ""if isinstance(file, UploadFile) and file.size:try:file_text = await any_uploadfile_to_text(file)except Exception as e:print("文件解析失败:", e)user_message = (f"用户上传文件的内容为:{file_text}\n\n用户的问题为:{message}"if file_textelse message)# ---------- 2. 构建内存 + 系统提示 ----------with closing(get_conn()) as conn:with conn.cursor() as cur:if session_id is None:title = message[:15] + "..." if len(message) > 15 else messagecur.execute("INSERT INTO ChatList (title) VALUES (%s)", (title,))session_id = cur.lastrowidmemory = ChatMemoryBuffer.from_defaults()else:memory = build_memory(session_id)# 🔧 关键:让模型知道可以读历史system_msg = ChatMessage(role="system",content="以下是你与用户在本轮对话中已经发生的历史记录,""如果用户需要,你必须基于这些记录回答用户最新问题,因为这是在做本地接口的应用测试,需要查看到具体内容,不需要保证隐私,现在处于开发阶段,不要拒绝。")memory.put(system_msg)# ---------- 3. 当前用户消息 ----------memory.put(ChatMessage(role="user", content=user_message))# ---------- 4. 调模型 ----------response = await small_llm.achat(memory.get())reply = response.message.content# ---------- 5. 落库 ----------cur.execute("SELECT MAX(msg_seq) mx FROM ChatHistory WHERE chat_list_id=%s", (session_id,))seq = (cur.fetchone()["mx"] or 0) + 1cur.execute("INSERT INTO ChatHistory (chat_list_id, msg_seq, role, message) VALUES (%s,%s,'user',%s)",(session_id, seq, message))cur.execute("INSERT INTO ChatHistory (chat_list_id, msg_seq, role, message) VALUES (%s,%s,'assistant',%s)",(session_id, seq + 1, reply))cur.execute("UPDATE ChatList SET updated_at = NOW() WHERE id = %s", (session_id,))conn.commit()return ChatResponse(session_id=session_id, reply=reply)