【Redis-cli操作数据类型】Redis八大数据类型详解:从redis-cli操作到场景落地
文章目录
- 前言
- Redis八大数据类型详解:从redis-cli操作到场景落地
- 一、引言:为什么要关注Redis数据类型?
- 二、String:Redis的“基础积木”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 三、Hash:结构化数据的“容器”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 四、List:有序可重复的“队列/栈”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 五、Set:无序唯一的“集合”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 六、ZSet:有序唯一的“排行榜”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 七、Bitmap:省内存的“位状态”
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 八、HyperLogLog:百万级基数统计
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 九、Geospatial:地理位置查询
- 1. 特点
- 2. redis-cli操作示例
- 3. 典型场景
- 十、总结:八大数据类型选型表
- 十一、结语
前言
若对您有帮助的话,请点赞收藏加关注哦,您的关注是我持续创作的动力!有问题请私信或联系邮箱:funian.gm@gmail.com
Redis八大数据类型详解:从redis-cli操作到场景落地
Redis 作为高性能的键值存储数据库,其核心优势之一在于支持丰富的数据类型。不同于传统数据库的单一数据结构,Redis 的八大数据类型可针对性解决不同业务场景(如计数器、排行榜、地理位置查询等),极大提升开发效率。本文基于 redis-cli 终端操作,结合实例详解每种数据类型的特点、常用命令及典型应用,新手可直接复制命令实践。
一、引言:为什么要关注Redis数据类型?
Redis 并非简单的“键值对仓库”,其数据类型是“功能差异化”的核心:
- 避免“用String存储所有数据”的低效做法(如用String存列表需手动处理分隔符);
- 每种类型内置优化算法(如ZSet的跳表、Hash的哈希表),兼顾性能与易用性;
- 支持原子操作(如List的push/pop、ZSet的分数自增),减少并发问题。
本文所有示例基于 Redis 7.x 稳定版,需先确保 redis-cli 已连接服务(基础连接命令:redis-cli -h 你的IP -p 6379 -a 你的密码)。
二、String:Redis的“基础积木”
1. 特点
- 最基础的数据类型,存储字符串、数字或二进制数据(最大容量 512MB);
- 支持原子性增减、过期时间设置,是Redis使用频率最高的类型。
2. redis-cli操作示例
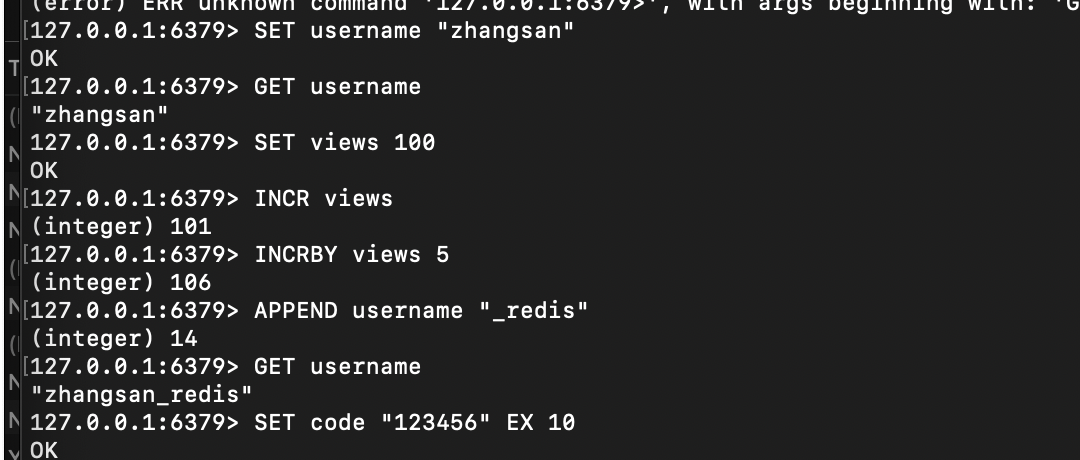
# 1. 设置键值(支持直接存字符串/数字)
127.0.0.1:6379> SET username "zhangsan" # 字符串
OK
127.0.0.1:6379> SET views 100 # 数字
OK# 2. 获取值
127.0.0.1:6379> GET username
"zhangsan"
127.0.0.1:6379> GET views
"100"# 3. 原子自增(适合计数器场景)
127.0.0.1:6379> INCR views # 自增1
(integer) 101
127.0.0.1:6379> INCRBY views 5 # 自定义步长(+5)
(integer) 106# 4. 追加字符串
127.0.0.1:6379> APPEND username "_redis" # 给username追加后缀
(integer) 13 # 返回新字符串长度
127.0.0.1:6379> GET username
"zhangsan_redis"# 5. 设置过期时间(10秒后自动删除)
127.0.0.1:6379> SET code "123456" EX 10
OK
3. 典型场景
- 缓存热点数据(如用户信息、商品详情);
- 计数器(文章阅读量、接口调用次数);
- 临时令牌(短信验证码、登录Token)。
三、Hash:结构化数据的“容器”
1. 特点
- 存储“键值对集合”(类似 JSON 对象),适合结构化数据;
- 可单独操作某个字段,无需修改整个对象(如只更新用户年龄,不改动姓名)。
2. redis-cli操作示例
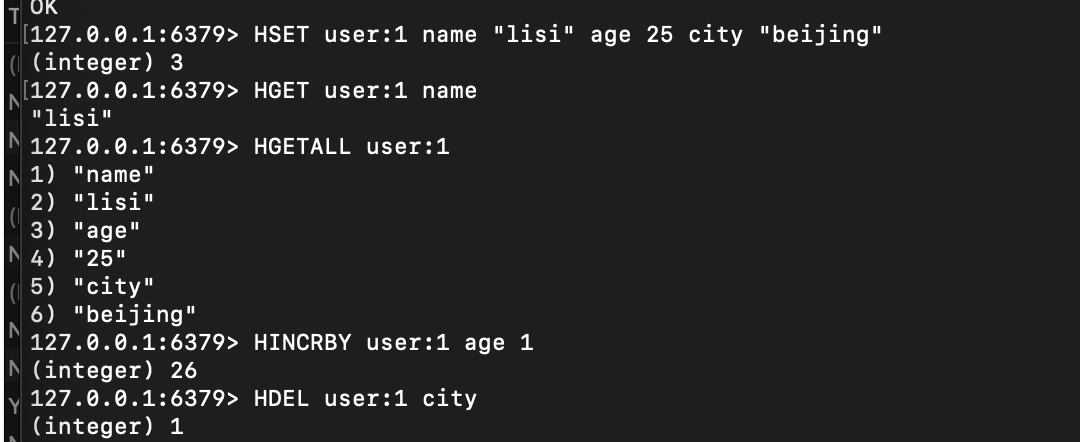
# 1. 存储用户信息(键:user:1,字段:name/age/city)
127.0.0.1:6379> HSET user:1 name "lisi" age 25 city "Beijing"
(integer) 3 # 成功设置的字段数# 2. 获取单个字段
127.0.0.1:6379> HGET user:1 name
"lisi"# 3. 获取所有字段和值(适合查看完整对象)
127.0.0.1:6379> HGETALL user:1
1) "name"
2) "lisi"
3) "age"
4) "25"
5) "city"
6) "Beijing"# 4. 字段原子自增(年龄+1)
127.0.0.1:6379> HINCRBY user:1 age 1
(integer) 26# 5. 删除无用字段
127.0.0.1:6379> HDEL user:1 city
(integer) 1 # 成功删除的字段数
3. 典型场景
- 存储用户信息、商品属性(如
product:1001存价格、库存、分类); - 配置项存储(如系统参数的键值对集合)。
四、List:有序可重复的“队列/栈”
1. 特点
- 基于双向链表实现,支持两端插入/删除(时间复杂度 O(1));
- 元素可重复,有序性由插入顺序决定,适合“先进先出”或“先进后出”场景。
2. redis-cli操作示例
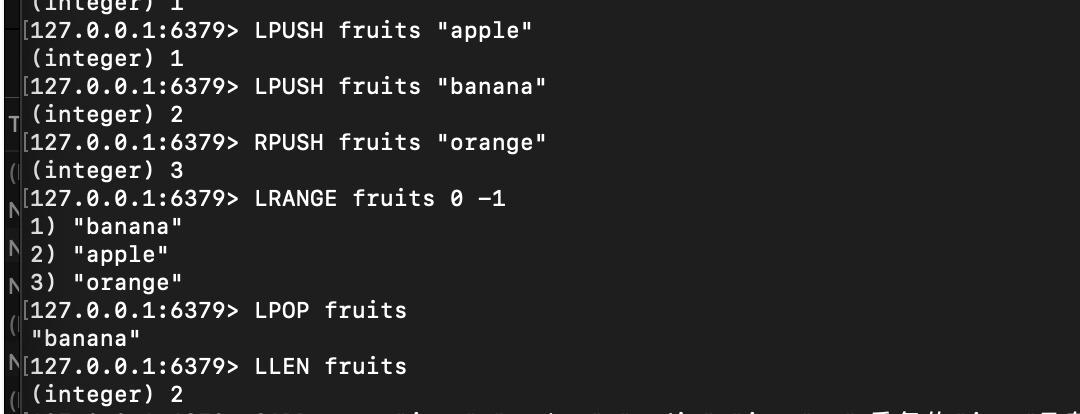
# 1. 左侧插入(栈结构:先进后出)
127.0.0.1:6379> LPUSH fruits "apple"
(integer) 1
127.0.0.1:6379> LPUSH fruits "banana" # 新元素插在最前面
(integer) 2# 2. 右侧插入(队列结构:先进先出)
127.0.0.1:6379> RPUSH fruits "orange" # 新元素插在最后面
(integer) 3# 3. 查看列表(0=-1 表示所有元素,顺序为插入顺序)
127.0.0.1:6379> LRANGE fruits 0 -1
1) "banana" # LPUSH的第二个元素
2) "apple" # LPUSH的第一个元素
3) "orange" # RPUSH的元素# 4. 左侧删除(弹出最前面的元素)
127.0.0.1:6379> LPOP fruits
"banana"# 5. 查看列表长度
127.0.0.1:6379> LLEN fruits
(integer) 2
3. 典型场景
- 消息队列(如异步任务队列,用
LPUSH生产、RPOP消费); - 最新列表(如“最近浏览商品”“最新评论”,用
LPUSH新增,LRANGE取前10条)。
五、Set:无序唯一的“集合”
1. 特点
- 元素唯一(自动去重),无序;
- 支持交集、并集、差集运算,适合“关系计算”场景。
2. redis-cli操作示例
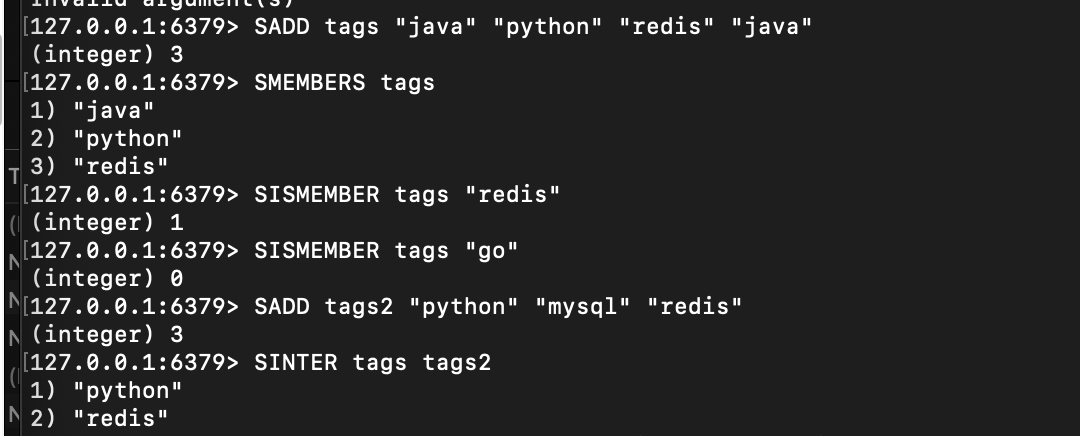
# 1. 添加元素(重复元素会自动过滤)
127.0.0.1:6379> SADD tags "java" "python" "redis" "java"
(integer) 3 # 实际新增3个元素(重复的"java"被忽略)# 2. 查看所有元素(顺序不固定)
127.0.0.1:6379> SMEMBERS tags
1) "python"
2) "java"
3) "redis"# 3. 判断元素是否存在(1=存在,0=不存在)
127.0.0.1:6379> SISMEMBER tags "redis"
(integer) 1
127.0.0.1:6379> SISMEMBER tags "go"
(integer) 0# 4. 集合运算(交集:两个集合的共同元素)
127.0.0.1:6379> SADD tags2 "python" "mysql" "redis" # 新建第二个集合
(integer) 3
127.0.0.1:6379> SINTER tags tags2 # 求tags和tags2的交集
1) "python"
2) "redis"
3. 典型场景
- 标签系统(如文章标签,自动去重);
- 好友关系(如“共同好友”用交集计算,“我的好友但他不是”用差集);
- 去重统计(如“今日访问IP列表”,避免重复计数)。
六、ZSet:有序唯一的“排行榜”
1. 特点
- 元素唯一,但每个元素关联一个“分数(score)”,按分数排序;
- 支持按分数范围查询、分数自增,是实现排行榜的最佳选择。
2. redis-cli操作示例
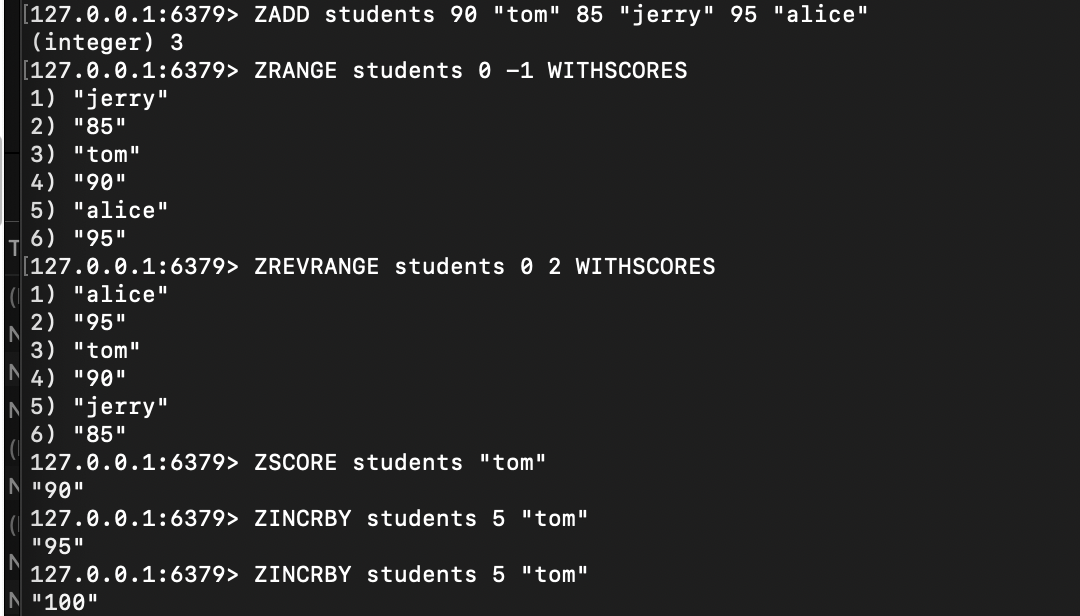
# 1. 添加元素(格式:ZADD 键 分数1 元素1 分数2 元素2 ...)
127.0.0.1:6379> ZADD students 90 "tom" 85 "jerry" 95 "alice"
(integer) 3# 2. 按分数升序查看(WITHSCORES 显示分数)
127.0.0.1:6379> ZRANGE students 0 -1 WITHSCORES
1) "jerry" # 分数85(最低)
2) "85"
3) "tom" # 分数90
4) "90"
5) "alice" # 分数95(最高)
6) "95"# 3. 按分数降序查看(取前三名)
127.0.0.1:6379> ZREVRANGE students 0 2 WITHSCORES
1) "alice"
2) "95"
3) "tom"
4) "90"
5) "jerry"
6) "85"# 4. 分数原子自增(给tom加5分)
127.0.0.1:6379> ZINCRBY students 5 "tom"
"95" # 新增分数
3. 典型场景
- 排行榜(如“积分排行榜”“销量排行榜”,按分数降序展示);
- 优先级队列(如任务按紧急程度设分数,分数高的先执行)。
七、Bitmap:省内存的“位状态”
1. 特点
- 基于String实现,用二进制位(0/1)表示状态;
- 极致省内存:1个字节可存8个状态,1MB可存100万+状态。
2. redis-cli操作示例
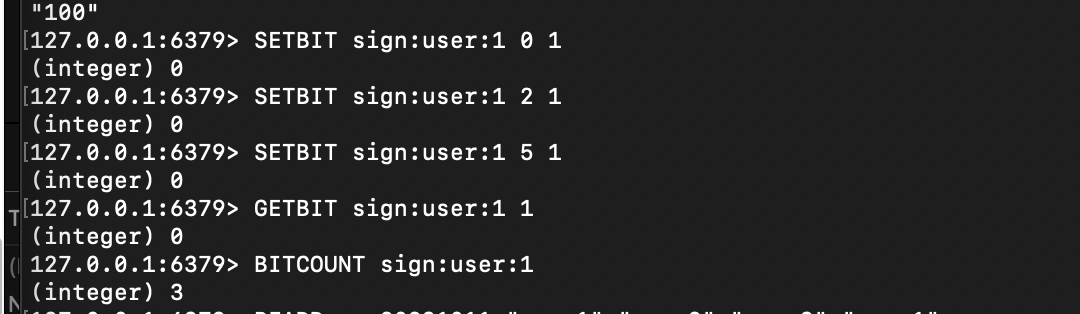
# 场景:记录用户每月签到(偏移量=日期-1,1=签到,0=未签)
127.0.0.1:6379> SETBIT sign:user:1 0 1 # 1号签到(偏移量0)
(integer) 0 # 原始位值(初始为0)
127.0.0.1:6379> SETBIT sign:user:1 2 1 # 3号签到(偏移量2)
(integer) 0
127.0.0.1:6379> SETBIT sign:user:1 5 1 # 6号签到(偏移量5)
(integer) 0# 查看2号是否签到(偏移量1)
127.0.0.1:6379> GETBIT sign:user:1 1
(integer) 0 # 未签到# 统计当月签到次数(统计所有值为1的位)
127.0.0.1:6379> BITCOUNT sign:user:1
(integer) 3 # 共签到3天
3. 典型场景
- 签到系统(如“连续签到”“月度签到次数”);
- 在线状态(如“用户是否在线”,1=在线,0=离线);
- 布隆过滤器(结合多个Bitmap实现高效去重)。
八、HyperLogLog:百万级基数统计
1. 特点
- 用于“基数统计”(即不重复元素的个数),无需存储所有元素;
- 内存占用极低:无论数据量多大,仅需约12KB内存,误差率<1%。
2. redis-cli操作示例
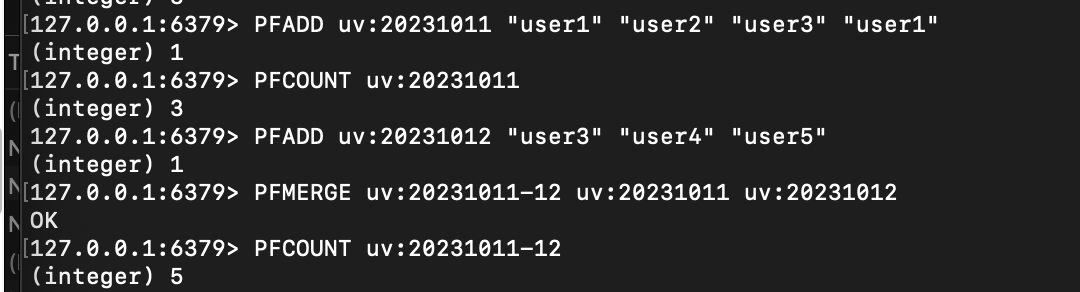
# 场景:统计网站独立访客(UV)
127.0.0.1:6379> PFADD uv:20231011 "user1" "user2" "user3" "user1"
(integer) 1 # 1=结构更新,0=无更新# 统计当天UV(自动去重)
127.0.0.1:6379> PFCOUNT uv:20231011
(integer) 3 # 3个独立用户# 合并两天UV(10月11日 + 10月12日)
127.0.0.1:6379> PFADD uv:20231012 "user3" "user4" "user5"
(integer) 1
127.0.0.1:6379> PFMERGE uv:20231011-12 uv:20231011 uv:20231012# 统计合并后的总UV
127.0.0.1:6379> PFCOUNT uv:20231011-12
(integer) 5 # 总独立用户:user1-user5
3. 典型场景
- UV统计(网站/页面的独立访客数);
- 搜索关键词去重计数(如“今日热门搜索词个数”)。
九、Geospatial:地理位置查询
1. 特点
- 存储经纬度信息,支持距离计算、范围查询;
- 基于GeoHash编码实现,适合LBS(位置服务)场景。
2. redis-cli操作示例
# 1. 添加城市经纬度(格式:GEOADD 键 经度 纬度 地点)
127.0.0.1:6379> GEOADD cities 116.40 39.90 "Beijing" # 北京
(integer) 1
127.0.0.1:6379> GEOADD cities 121.47 31.23 "Shanghai" # 上海
(integer) 1
127.0.0.1:6379> GEOADD cities 113.26 23.13 "Guangzhou" # 广州
(integer) 1# 2. 计算两地距离(单位:km,支持m/km/mi/ft)
127.0.0.1:6379> GEODIST cities Beijing Shanghai km
"1317.3378" # 北京到上海约1317公里# 3. 按半径查询(北京周围1000公里内的城市)
127.0.0.1:6379> GEORADIUS cities 116.40 39.90 1000 km
1) "Beijing" # 仅北京在范围内(上海超1000km)# 4. 获取地点经纬度(返回GeoHash编码,可解码为具体坐标)
127.0.0.1:6379> GEOHASH cities Guangzhou
1) "ws10y62k1c0"

3. 典型场景
- 附近的人/商家(如“查找5公里内的餐厅”);
- 地理位置围栏(如“用户进入某区域触发通知”)。
十、总结:八大数据类型选型表
| 数据类型 | 核心特点 | 典型场景 | 关键命令 |
|---|---|---|---|
| String | 基础键值,原子增减 | 计数器、缓存、Token | SET/GET/INCR/EXPIRE |
| Hash | 结构化键值对,字段独立操作 | 用户信息、商品属性 | HSET/HGET/HGETALL/HINCRBY |
| List | 有序可重复,双向操作 | 消息队列、最新列表 | LPUSH/RPUSH/LRANGE/LPOP |
| Set | 无序唯一,支持集合运算 | 标签、好友关系、去重 | SADD/SMEMBERS/SINTER/SISMEMBER |
| ZSet | 有序唯一,按分数排序 | 排行榜、优先级队列 | ZADD/ZRANGE/ZREVRANGE/ZINCRBY |
| Bitmap | 位状态存储,省内存 | 签到、在线状态 | SETBIT/GETBIT/BITCOUNT |
| HyperLogLog | 基数统计,低内存 | UV统计、关键词去重 | PFADD/PFCOUNT/PFMERGE |
| Geospatial | 地理位置,距离/范围查询 | 附近的人、LBS服务 | GEOADD/GEODIST/GEORADIUS |
十一、结语
Redis 数据类型的选择,本质是“场景与性能的匹配”:无需过度追求复杂类型(如用ZSet存简单列表),也不要用基础类型硬扛复杂场景(如用String存排行榜)。建议结合本文示例,在 redis-cli 中实际操作一遍,既能理解每种类型的特性,也能在开发中快速选型。