pandas 数据的拼接
数据的拼接
-
需要使用函数
concat -
函数的使用方法
# 引用 pandas import pandas as pd # concat 的使用 pd.concat(objs,axis,join,ignore_index)函数:拼接多个 DataFrame 可以选择横向纵向拼接 参数1: objs = 要进行拼接的数据对象(格式为列表,可以包含多个DataFrame和Series) 参数2: axis = 选择拼接的方向 axis = 0 按行方向拼接(默认) axis = 1 按列方向拼接 参数3: join = 处理索引的对齐 join = 'outer' 为并集 join = inner 为交集 默认join = 'outer'取并集 参数4: 是否忽略原索引,生成新的索引 ignore_index = True/False True 为生成新的 False 为使用原来的索引 默认为False -
例如:
定义数据:
# 数据的拼接 # 引用 pandas import pandas as pd # 创建数据 data1 = { "学生ID":[1,2,3,4], "姓名":["张三","李四","王五","赵六"], "成绩":[85,90,79,82] } data2 = { "班级":["一班","二班","三班","四班"] } # 创建 DataFrame df1 = pd.DataFrame(data1) df2 = pd.DataFrame(data2) print(df1) print(df2)结果:
学生ID 姓名 成绩 0 1 张三 85 1 2 李四 90 2 3 王五 79 3 4 赵六 82 班级 0 一班 1 二班 2 三班 3 四班

-
当
axis = 1时 按着列的方向进行拼接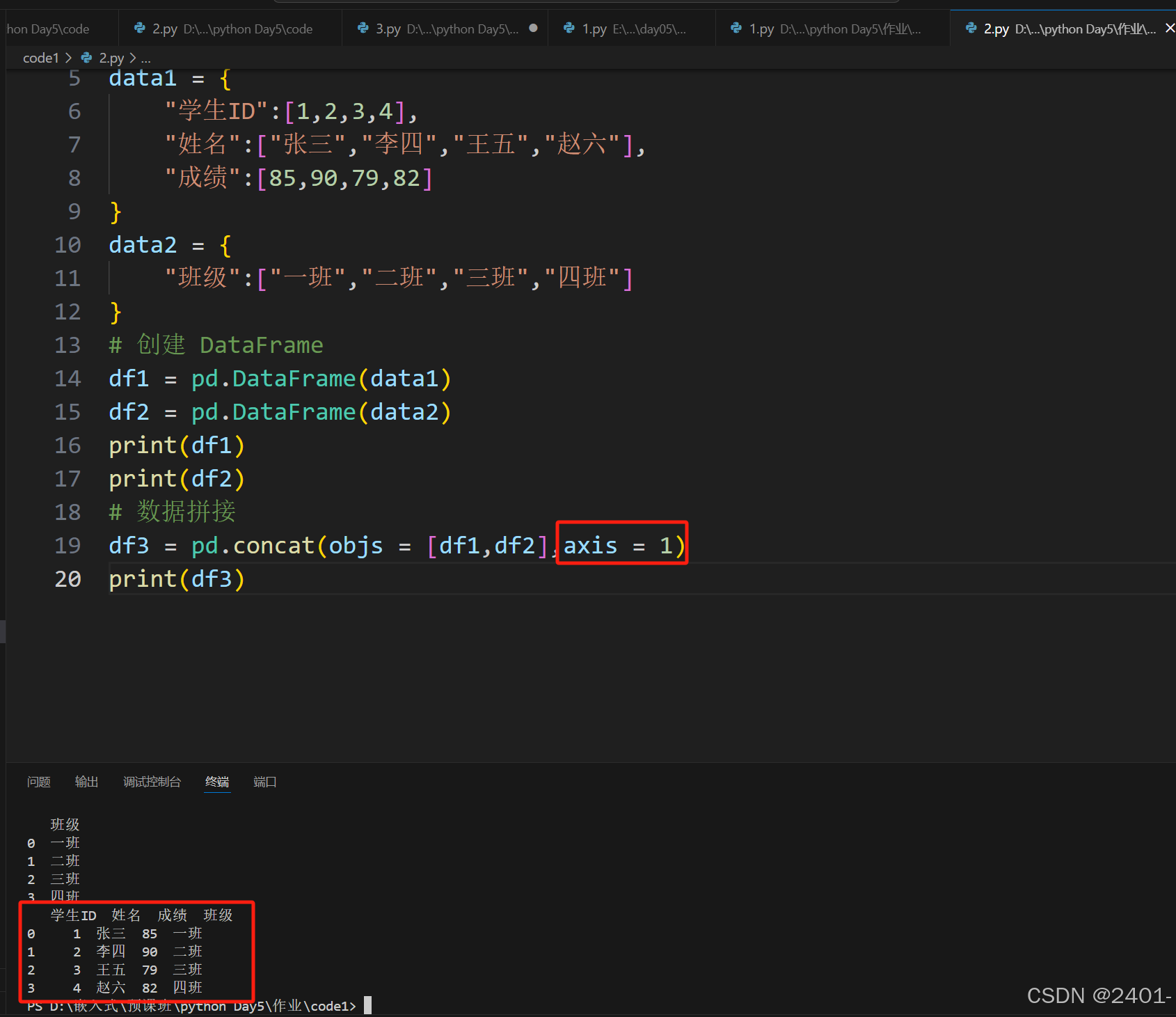
-
当
axis = 0时 按着行的方向进行拼接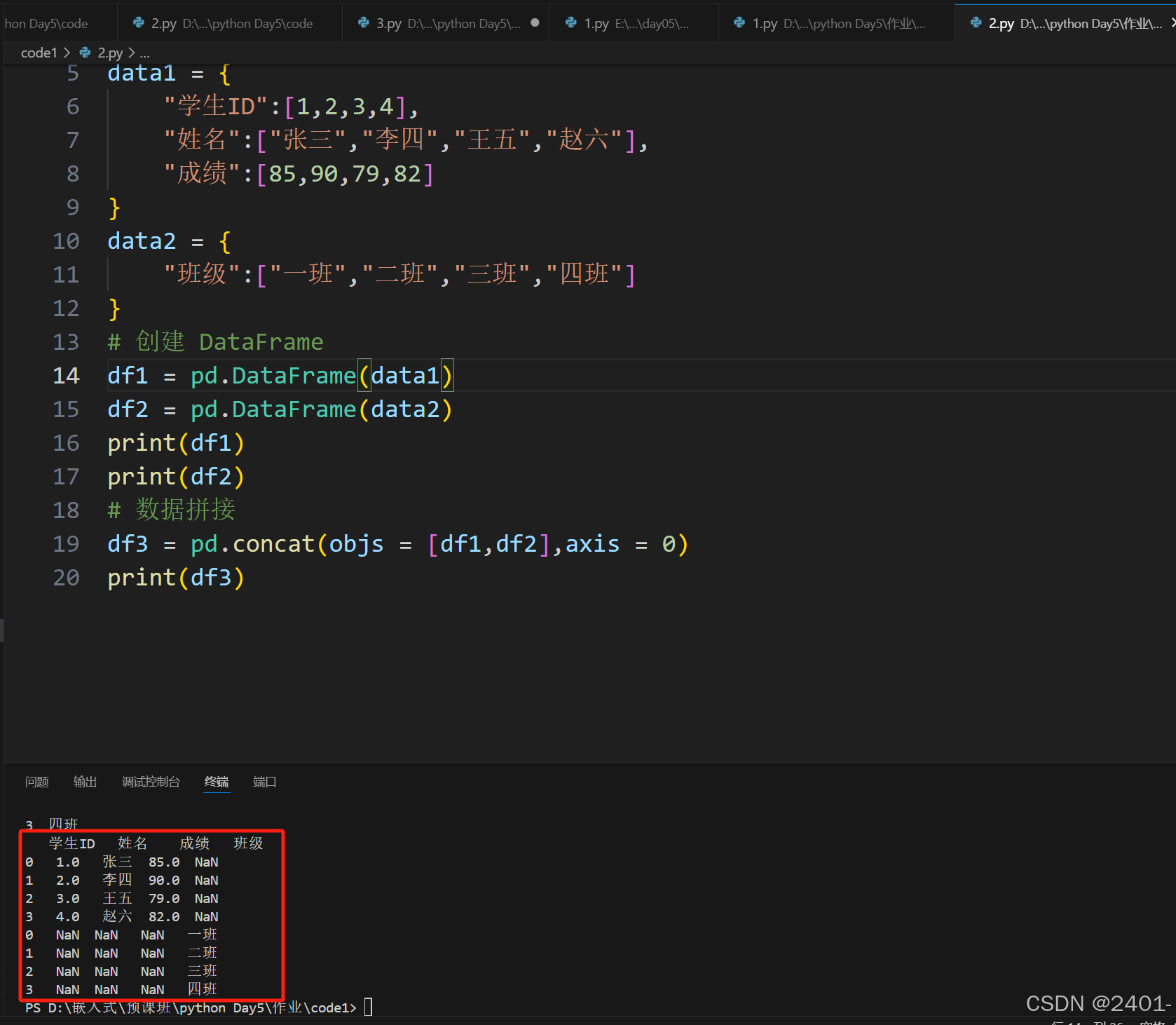
-
ignore_index = True与ignore_index = False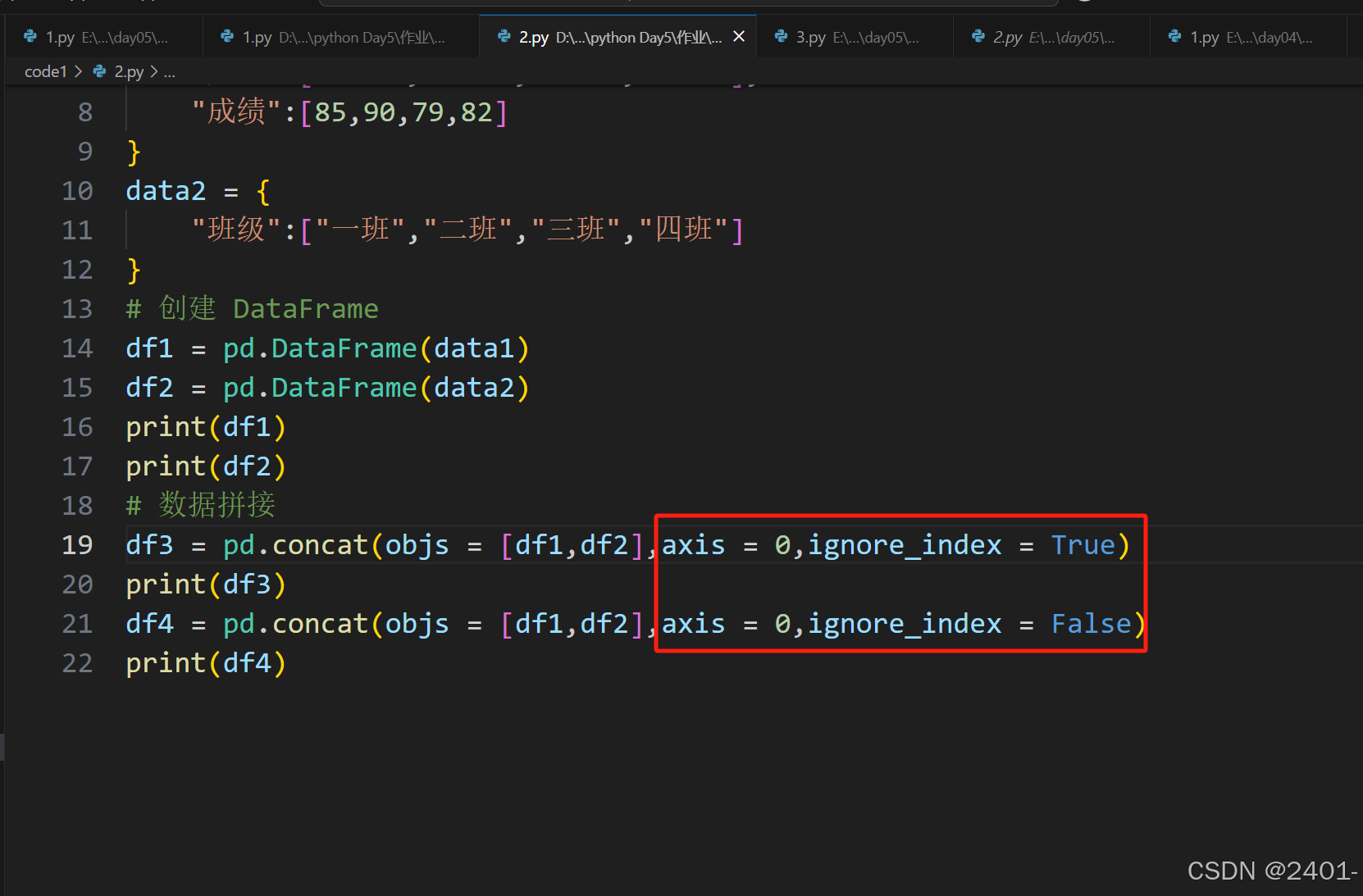
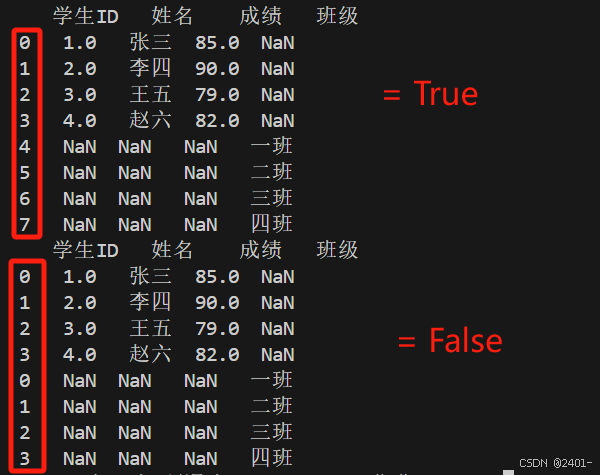
-
join = 'inner'与join = 'outer'的区别
创建数据
# 引入
import pandas as pd
# 不同列表的合并
df1 = pd.DataFrame({
"学生ID":[1,2],
"姓名":["张三","李四"],
"班级":["三班","四班"]
})
df2 = pd.DataFrame({
"成绩":[85,90],
"班级":["一班","二班"]
})
结果:

学生ID 姓名 班级
0 1 张三 三班
1 2 李四 四班
成绩 班级
0 85 一班
1 90 二班


- 自定义行索引并拼接
# 引用 pandas
import pandas as pd
# 创建 DataFrame
df1 = pd.DataFrame({
'成绩':[45,78],
'班级':['一班','二班']
},index = ['张三','李四'])
df2 = pd.DataFrame({
'成绩':[89,92],
'班级':['三班','四班']
},index = ['王五','赵六'])
# 拼接
df3 = pd.concat(objs = [df1,df2],axis = 0,join = 'inner',ignore_index = False)
print(df3)
结果:
成绩 班级
张三 45 一班
李四 78 二班
王五 89 三班
赵六 92 四班
-
DataFrame与Series拼接# DataFrame 与 Series拼接 # 引用 pandas import pandas as pd # 创建 DataFrame df = pd.DataFrame({ '姓名':['张三','李四','王五','赵六'], '性别':['男','男','女','男'] }) # 定义 Series data1 = [67,78,69,97] data2 = ['一班','二班','三班','四班'] ser1 = pd.Series(data1,name = '成绩') ser2 = pd.Series(data2,name = '班级') # 拼接 df1 = pd.concat(objs = [df,ser1,ser2],axis = 1,join = 'outer',ignore_index = False) print(df1)结果:
姓名 性别 成绩 班级 0 张三 男 67 一班 1 李四 男 78 二班 2 王五 女 69 三班 3 赵六 男 97 四班