linux入门5.5(高可用)
文章目录
- 练习
- 1.开发一个sum函数,当执行`sum 10`,则计算1到10的和。
- 2.开发一个备份脚本,将/etc/hos*文件复制到/backup目录,并添加时间后缀,例如hosts.20251011
- 3.开发批量管理服务器脚本weihu-cmd,服务器清单为server1-server10,当执行`weihu-cmd hostname`,服务器清单中所有主机执行hostname命令
- 4.开发一个猜数字游戏
- 高可用-Keepalived 全解析
- HA 集群能解决哪些问题?
- Keepalived 介绍
- VRRP 协议
- 工作原理
- 脑裂
- 脑裂产生的原因
- 脑裂的危害
- 如何避免脑裂?
- 总结
- Keepalvied 高可用技术实践
- 网络拓扑
- 基础配置
- 配置 router
- 配置 keepalived
- 配置 web2
- 配置 web1
- 高可用验证
练习
1.开发一个sum函数,当执行sum 10,则计算1到10的和。
[root@web1 ~ 17:11:20]# bash sum1.sh 10
55
[root@web1 ~ 17:11:39]# cat sum1.sh
#!/bin/bash
function sum1() {if(( $1==1 )); thensum=1elsesum=$[ $1 + $(sum1 $[ $1 - 1 ]) ]fiecho $sum
}
sum1 $1
2.开发一个备份脚本,将/etc/hos*文件复制到/backup目录,并添加时间后缀,例如hosts.20251011
[root@web1 ~ 17:16:44]# ls /backup/
host.conf.20251011 hosts.20251011 hosts.deny.20251011
hostname.20251011 hosts.allow.20251011
[root@web1 ~ 17:16:56]# cat time.sh
#!/bin/bash
[ -d /backup ] || mkdir /backup
cd /etc
for file in hos*
do
cp $file /backup/$file.$(date +%Y%m%d)
done
3.开发批量管理服务器脚本weihu-cmd,服务器清单为server1-server10,当执行weihu-cmd hostname,服务器清单中所有主机执行hostname命令
[root@web1 ~ 17:20:57]# bash cmd.sh hostname
在server1 上执行hostname
ssh: Could not resolve hostname server1: Name or service not known
在server2 上执行hostname
^C
[root@web1 ~ 17:21:25]# cat cmd.sh
#!/bin/bash
for host in server{1..10}
do
echo "在$host 上执行$1"
ssh $host $1
done
4.开发一个猜数字游戏
随机产生一个50以内数字,猜出该数字。
当提供的数字大于随机数,则提示猜大了。
当提供的数字小于随机数,则提示猜小了。
当提供的数字等于随机数,则提示猜对了。
每次猜数字的时候,提示猜了几次。
- 随机数 RANDOM
$[ RANDOM % 50 + 1 ] - 随机数如何保存:变量、文件?
- if多分支比较。
- 执行过程中提供,read
- 计数器 guess_count
- 猜对了,就退出 exit
- 没猜对,一直猜测,while true
[root@server ~ 10:17:59]# vim guess.sh
[root@server ~ 10:18:25]# cat guess.sh
#!/bin/bash
# 生成随机值,并存储到文件中
num=$[ RANDOM % 50 + 1 ]
echo $num > /tmp/num
echo "随机值已经生成。"guess_count=1
while true
doread -p "请输入猜测的数值:" guess_numif ((guess_num>num));thenecho "第${guess_count}次猜测: 猜大了,往小猜。"elif ((guess_num<num));thenecho "第${guess_count}次猜测: 猜小了,往大猜。"elseecho "第${guess_count}次猜测: 恭喜你,猜中了。"exitfilet guess_count=$[ $guess_count + 1 ]
done
[root@server ~ 10:18:30]# bash guess.sh
随机值已经生成。
请输入猜测的数值:25
第1次猜测: 猜大了,往小猜。
请输入猜测的数值:15
第2次猜测: 猜大了,往小猜。
请输入猜测的数值:10
第3次猜测: 猜大了,往小猜。
请输入猜测的数值:5
第4次猜测: 猜大了,往小猜。
请输入猜测的数值:2
第5次猜测: 恭喜你,猜中了。
高可用-Keepalived 全解析
官网 https://www.keepalived.org/
HA 集群能解决哪些问题?
当计划使用HA集群时候,有一个重要的问题需要回答:服务放到HA集群中,可用性是否会增加?
回答这个问题,需要弄清楚服务的能力和该服务的客户端如何配置。
-
取决于解决方案,例如DNS和LDAP自带故障转移或者负载均衡,放到HA集群中没什么好处。DNS或者LDAP服务使用多个服务,具备master/slave角色,或者多个master关系。该服务可在多个服务器之间配置数据冗余。DNS和LDAP的客户端也可以使用多个服务器,这里就没有故障转移,因此,这种服务放置到HA集群中不会增加服务的可用性。
-
那些未自带Failover或者LB的服务,如果配置为HA集群,将会有很多好处。例如在 Openstack 平台解决方案中,将 RabbitMQ 和 Galera 放置到HA集群中,可以带来很多好处。
并不是每个可用性问题都可以通过HA集群解决:
-
如果应用程序存因bug导致crash,即使配置为HA集群,应用同样会crash。这种情况下,服务将会转移到其他节点。但是其他节点上的应用也存在相同的bug问题,同样会导致crash。
-
HA集群同样不提供端到端的冗余。集群本身可以正常提供服务,但是网络架构存在问题,导致集群不可达,客户端仍然无法访问服务。因此需要慎重考虑集群架构,避免单点故障,包括集群中的任何组件。
Keepalived 介绍
Keepalived 是一个用 C 语言编写的路由软件。这个项目的主要目标是为 Linux 系统和基于 Linux 的基础设施的负载平衡和高可用性提供简单而健壮的设施。
Keepalived 起初是为LVS设计的,专门用来监控集群系统中各个服务节点的状态,它根据TCP/IP参考模型的第三、第四层、第五层机制检测每个服务节点的状态,如果某个服务器节点出现异常,或者工作出现故障,Keepalived将检测到,并将出现的故障的服务器节点从集群系统中剔除,这些工作全部是自动完成的,不需要人工干涉,需要人工完成的只是修复出现故障的服务节点。
后来Keepalived又加入了VRRP的功能,VRRP(Vritrual Router Redundancy Protocol,虚拟路由冗余协议)出现的目的是解决静态路由出现的单点故障问题,通过VRRP可以实现网络不间断稳定运行,因此Keepalvied 一方面具有服务器状态检测和故障隔离功能,另外一方面也有HA cluster功能。
VRRP 协议
在现实的网络环境中,主机之间的通信都是通过配置静态路由或者(默认网关)来完成的,而主机之间的路由器一旦发生故障,通信就会失效。因此这种通信模式当中,路由器就成了一个单点瓶颈,为了解决这个问题,就引入了VRRP协议。
VRRP协议是一种主备模式的协议,通过VRRP可以在网络发生故障时透明的进行设备切换而不影响主机之间的数据通信。
VRRP可以将两台或者多台物理路由器设备虚拟成一个虚拟路由,这个虚拟路由器通过虚拟IP(一个或者多个)对外提供服务,而在虚拟路由器内部十多个物理路由器协同工作,同一时间只有一台物理路由器对外提供服务,这台物理路由设备被成为:主路由器(Master角色),一般情况下Master是由选举算法产生,它拥有对外服务的虚拟IP,提供各种网络功能,如:ARP请求,ICMP 数据转发等,而且其它的物理路由器不拥有对外的虚拟IP,也不提供对外网络功能,仅仅接收MASTER的VRRP状态通告信息,这些路由器被统称为“BACKUP的角色”,当主路由器失败时,处于BACKUP角色的备份路由器将重新进行选举,产生一个新的主路由器进入MASTER角色,继续提供对外服务,整个切换对用户来说是完全透明的。
每个虚拟路由器都有一个唯一的标识号,称为VRID,一个VRID与一组IP地址构成一个虚拟路由器,在VRRP协议中,所有的报文都是通过IP多播方式发送的,而在一个虚拟路由器中,只有处于Master角色的路由器会一直发送VRRP数据包,处于BACKUP角色的路由器只会接受Master角色发送过来的报文信息,用来监控Master运行状态,一般不会发生BACKUP抢占的情况,除非它的优先级更高,而当MASTER不可用时,BACKUP也就无法收到Master发过来的信息,于是就认定Master出现故障,接着多台BAKCUP就会进行选举,优先级最高的BACKUP将称为新的MASTER,这种选举角色切换非常之快,因而保证了服务的持续可用性。
工作原理
Keepalived通过VRRP实现高可用性,它还能实现对集群中服务器运行状态的监控以及故障隔离。
Keepalived工作在TCP/IP 参考模型的 三层、四层、七层,也就是分别为:网络层,传输层和应用层。
根据TCP/IP参数模型隔层所能实现的功能,Keepalived运行机制如下:
-
网络层:提供四个重要的协议,互联网络IP协议、互联网络可控制报文协议ICMP、地址转换协议ARP、反向地址转换协议RARP。
Keepalived在网络层采用最常见的工作方式是**通过ICMP协议向服务器集群中的每一个节点发送一个ICMP数据包(**有点类似与Ping的功能),如果某个节点没有返回响应数据包,那么认为该节点发生了故障,Keepalived将报告这个节点失效,并从服务器集群中剔除故障节点。
-
传输层:提供两个主要的协议:传输控制协议TCP和用户数据协议UDP。传输控制协议TCP可以提供可靠的数据输出服务、IP地址和端口,代表TCP的一个连接端,要获得TCP服务,需要在发送机的一个端口和接收机的一个端口上建立连接。
Keepalived在传输层里利用了TCP协议的端口连接和扫描技术来判断集群节点的端口是否正常,比如对于常见的WEB服务器80端口。或者SSH服务22端口,Keepalived一旦在传输层探测到这些端口号没有数据响应和数据返回,就认为这些端口发生异常,然后强制将这些端口所对应的节点从服务器集群中剔除掉。
-
应用层:可以运行FTP,TELNET,SMTP,DNS等各种不同类型的高层协议,Keepalived的运行方式也更加全面化和复杂化,用户可以通过自定义Keepalived工作方式,例如:可以通过编写程序或者脚本来运行Keepalived,而Keepalived将根据用户的设定参数检测各种程序或者服务是否允许正常,如果Keepalived的检测结果和用户设定的不一致时,Keepalived将把对应的服务器从服务器集群中剔除。
脑裂
在 keepalived 高可用集群中,脑裂(Split-Brain) 是指主从节点(或双主节点)之间因通信中断,导致各自认为对方故障,从而同时争抢资源(如虚拟 IP),引发集群状态混乱的现象。
脑裂产生的原因
脑裂的核心是节点间心跳检测失败,但实际节点均正常运行,常见情况可能导致:
- 网络问题:主从节点间的心跳线路(如专用网线、交换机)故障、断网或延迟过高。
- 防火墙规则:节点间的
VRRP协议端口(默认112端口,UDP 协议)被防火墙屏蔽。 - 资源耗尽:某节点因 CPU、内存耗尽或负载过高,无法响应心跳请求。
- 配置错误:
keepalived配置中vrrp_instance的state、priority或authentication等参数不一致,导致节点间无法正常协商。
脑裂的危害
- 双节点同时持有虚拟 IP(VIP),导致客户端请求混乱(部分请求成功,部分失败)。
- 若集群管理的是数据库、存储等资源,可能引发数据不一致(如双写冲突)。
- 集群失去高可用意义,甚至因资源竞争导致服务崩溃。
如何避免脑裂?
通过 多重检测机制 和 资源隔离策略 预防脑裂,常用方案如下:
- 增加心跳检测线路
-
除了主网络,添加备用通信线路(如独立网卡、交叉网线),避免单线路故障导致心跳中断。
在 keepalived.conf中指定多网卡检测:
vrrp_instance VI_1 {state MASTERinterface eth0 # 主网卡virtual_router_id 51priority 100advert_int 1# 同时检测备用网卡(如eth1)track_interface {eth0eth1} }
- 启用 VRRP 认证
-
配置节点间的认证机制,防止非法节点干扰集群,同时确保心跳信息的可靠性。
vrrp_instance VI_1 {# ... 其他配置authentication {auth_type PASS # 认证类型(PASS或AH)auth_pass 123456 # 密码(所有节点必须一致)} }
- 配置防火墙规则
-
允许节点间通过 VRRP协议通信(开放 UDP 112 端口):
# 允许VRRP协议(CentOS示例) firewall-cmd --add-protocol=vrrp --permanent firewall-cmd --reload
- 部署第三方检测工具
-
使用
fence机制(如fence_virsh、fence_ipmilan)或脚本,当检测到脑裂时强制隔离异常节点。示例:在 keepalived.conf中配置 notify 脚本,检测到节点成为主节点后,检查对方是否存活,若存活则强制关闭对方服务:
vrrp_instance VI_1 {# ... 其他配置notify_master "/etc/keepalived/check_split_brain.sh master"notify_backup "/etc/keepalived/check_split_brain.sh backup" }脚本逻辑:通过 ping、端口检测等方式确认对方状态,若脑裂则执行
kill或
reboot操作。
- 降低脑裂影响范围
- 结合业务层设计,如数据库使用主从复制 + 读写分离,避免双写冲突;存储使用分布式锁(如 Redis)控制资源独占。
- 限制虚拟 IP 的使用场景,仅在确认集群状态正常时对外提供服务。
- 监控与告警
- 通过
zabbix、prometheus等工具监控keepalived状态(如vrrp_script检测),当发现双主节点同时存在时及时告警。
总结
脑裂的本质是节点通信失效与状态判断不一致,预防核心在于 “多重检测 + 自动隔离”:通过多线路心跳、认证机制降低误判概率,结合脚本和第三方工具在脑裂发生时快速隔离异常节点,同时配合监控及时干预,保障集群稳定。
Keepalvied 高可用技术实践
网络拓扑
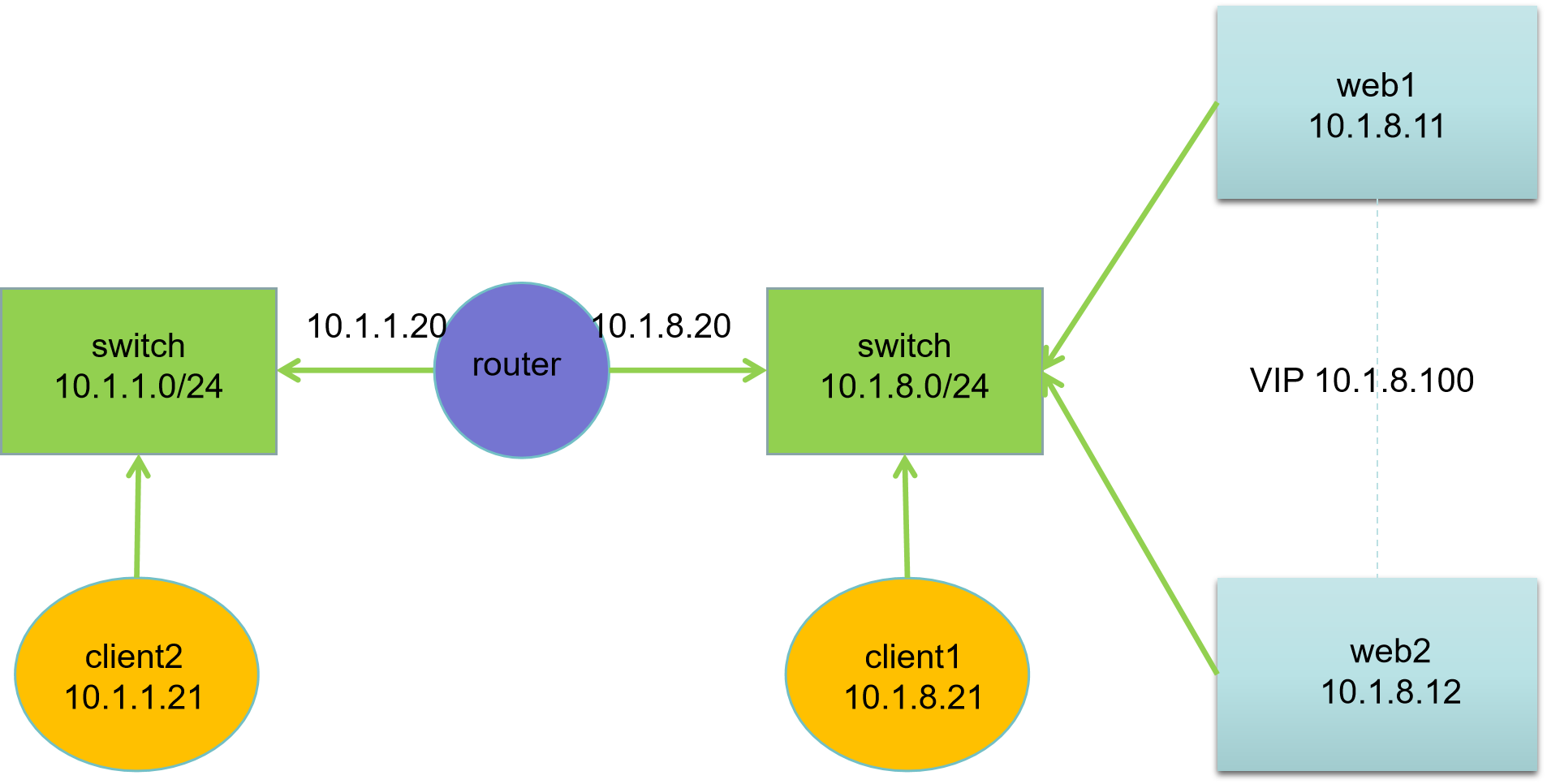
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.laoma.cloud | 10.1.1.21 | 客户端 |
| client1.laoma.cloud | 10.1.8.21 | 客户端 |
| router.laoma.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| web1.laoma.cloud | 10.1.8.11 | Web 服务器 |
| web2.laoma.cloud | 10.1.8.12 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens192
- 默认第一块网卡模式为 nat,第二块网卡模式为 hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
基础配置
-
主机名
-
IP 地址
-
网关
# 网关配置命令参考# 10.1.1.0/24 网段网关为10.1.1.20 nmcli connection modify ens33 ipv4.gateway 10.1.8.20 nmcli connection up ens33# 10.1.8.0/24 网段网关为10.1.8.20 nmcli connection modify ens33 ipv4.gateway 10.1.1.20 nmcli connection up ens33
配置 router
[root@router ~ 15:41:34]# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
[root@router ~ 15:45:38]# sysctl -p
net.ipv4.ip_forward = 1
配置 keepalived
配置 web2
web2 作为备节点。
[root@web2 ~ 15:54:58]# echo cp /etc/keepalived/keepalived.conf{,.ori}
cp /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.ori
[root@web2 ~ 16:03:34]# cp /etc/keepalived/keepalived.conf{,.ori}
[root@web2 ~ 16:03:37]# vim /etc/keepalived/keepalived.conf
[root@web2 ~ 16:06:20]# systemctl enable keepalived.service --now
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@web2 ~ 16:06:40]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 10.1.8.12/24 10.1.8.100/32 fe80::20c:29ff:fe26:abef/64
[root@web2 ~ 16:06:45]# systemctl stop keepalived.service
[root@web2 ~ 16:10:01]# systemctl enable keepalived.service --now
[root@web2 ~ 16:10:21]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {router_id web2
}vrrp_instance web {state MASTERinterface ens33virtual_router_id 51priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {10.1.8.100}
}
说明:
router_id web2,定义路由器名称,每个节点使用不同的名称。state BACKUP,定义节点角色为备节点,MASTER则代表主节点。interface ens33,定义VIP配置到该接口。virtual_router_id 51,定义虚拟路由器ID,范围1-255,每个节点使用相同名称。priority 100,定义节点优先级,值越大优先级越高。authentication,定义心跳认证。virtual_ipaddress,定义虚拟VIP。
配置 web1
web1 作为主节点。
[root@web1 ~ 15:55:06]# cp /etc/keepalived/keepalived.conf{,.ori}
[root@web1 ~ 16:07:06]# vim /etc/keepalived/keepalived.conf
[root@web1 ~ 16:08:59]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 10.1.8.11/24 fe80::20c:29ff:fe25:ec31/64
[root@web1 ~ 16:09:08]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 10.1.8.11/24 fe80::20c:29ff:fe25:ec31/64
[root@web1 ~ 16:09:10]# systemctl enable keepalived.service --now
Created symlink from /etc/systemd/system/multi-user.target.wants/keepalived.service to /usr/lib/systemd/system/keepalived.service.
[root@web1 ~ 16:09:31]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 10.1.8.11/24 10.1.8.100/32 fe80::20c:29ff:fe25:ec31/64
[root@web1 ~ 16:09:33]# systemctl stop keepalived.service
[root@web1 ~ 16:10:33]# cat /etc/keepalived/keepalived.conf
! Configuration File for keepalivedglobal_defs {router_id web1
}vrrp_instance web {state MASTERinterface ens33virtual_router_id 51priority 200advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {10.1.8.100}
}
高可用验证
[root@client1 ~ 15:16:44]# curl 10.1.8.11
Welcome to web1.wsf.com
[root@client1 ~ 15:53:03]# curl 10.1.8.12
Welcome to web2.wsf.com
[root@client1 ~ 15:53:07]# curl 10.1.8.100
Welcome to web2.wsf.com
#开启web1的keepalived服务后
[root@client1 ~ 16:06:52]# curl 10.1.8.100
Welcome to web1.wsf.com
[root@client1 ~ 16:09:40]# curl 10.1.8.100
Welcome to web1.wsf.com
[root@client1 ~ 16:10:07]# curl 10.1.8.100
Welcome to web1.wsf.com
[root@client1 ~ 16:10:08]# curl 10.1.8.100
Welcome to web2.wsf.com
#持续监测
[root@client1 ~ 16:10:38]# while true;do curl -s http://10.1.8.100;sleep 1;done
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
Welcome to web2.wsf.com
#开启web1的keepalived服务后
Welcome to web1.wsf.com
Welcome to web1.wsf.com
Welcome to web1.wsf.com
Welcome to web1.wsf.com