大模型训练语料(通俗易懂) 第一篇
本系列文章我们把数据从 [ 来源分散、格式各异、重复冗余、质量参差 ] 一步步打磨为[ 能用、合规、去冗、优质 ] 的训练语料,并串起可审计、可复现的产线流程。
一、 来源与许可
而训练语料也是如此,将数据的来源,版权许可、原文进行存入数据库,才能在模型训练结果评估时引用可追溯信息。
1.1 具体步骤:
- 标注数据来源:网页、书籍、代码仓库、对话/工单、产品手册、FAQ、合成数据等。
- 明确许可(license):是否允许采集的数据进行训练、商用。
- 记录原数据来源信息并落表,便于后续溯源。
示例:
```
{
"doc_id": "policy_2025_10_001233",
"source": "web",
"url": "https://example.com/x",
"license": "CC-BY-4.3",
"collected_at": "2025-10-07T12:30:00+08:00",
}
```
二、原始清洗
不同来源的数据,数据格式不同,是无法统一处理的。因此必须先统一格式,再进行后续处理。系统内的数据在入库前进行了“ 字符与格式规范 ”的归一化处理。
2.1 推荐规则:
- 编码与 Unicode:统一使用 UTF-8 编码格式;全角→半角(A→A,123→123)。
- 空白与换行:`\r\n/\r → \n`;连续空白折叠;引号/括号对齐。
- 大小写:非代码可小写化;代码与标识符保留,确保代码块完整性,避免语义被改。
- 噪音剔除:移除乱码、抓取错误、过短/过长段、海量重复标点或广告页。
- 分隔符/标点统一:统一引号(中文直角/英文直引号归一)、省略号、破折号;保证 JSON/代码相关的 { } [ ] : , " 不被误替换。
前后对比:
处理前: ABC123¥ 2025年10月7日 访问https://xx.com?a=1&utm_source=...
处理后: ABC123¥ 2025年10月7日 访问https://xx.com?a=1&utm_source=...
分析:
处理前,字母ABC是全角英文字符(可以直观的看到字符之间的间距),而数字123是半角字符。因此需要统一字符格式,这里统一为半角字符。
三、去重与近重复
顾名思义,删去数据中重复的信息,留下有效、且不重复的数据。在系统中的数据中采用混合去重策略,在减少重复文字的同时识别语义上的相似性。
比较对象:基于自身数据样本比对。
3.1 混合策略:
精确去重(哈希):文档/段落都进行哈希,若哈希值完全一致的信息直接剔除其中一条。
相似度去重:
· 近重复(MinHash)+LSH 筛选:判断高度相似但不完全相同的文本。
补充:
- 在相似度去重中,可选择其中的一种方式对比相似度,再进行去重处理。
MinHash + LSH 筛选:
首先将文本A、B分别切分为 n 个小片(shingles)。
再拿 k 个哈希函数,同时对 A和B的n 个小片进行哈希函数,得到每个小片的k个哈希值,然后取每个小片的最小哈希值拼成 “长签名”。
LSH筛选:把长签名切成几段(band),比较A和B的某段是否相同,相同就将这对文本段标记为候选相似对,进行计算Jaccard确认相似度。
在下列表中,呈现的就是MinHash+LSH结合的输出结果。k=32代表的是32个哈希函数,B=8代表的是Band(段)=8段,R=4指的是每个段中包含的数值个数为4。
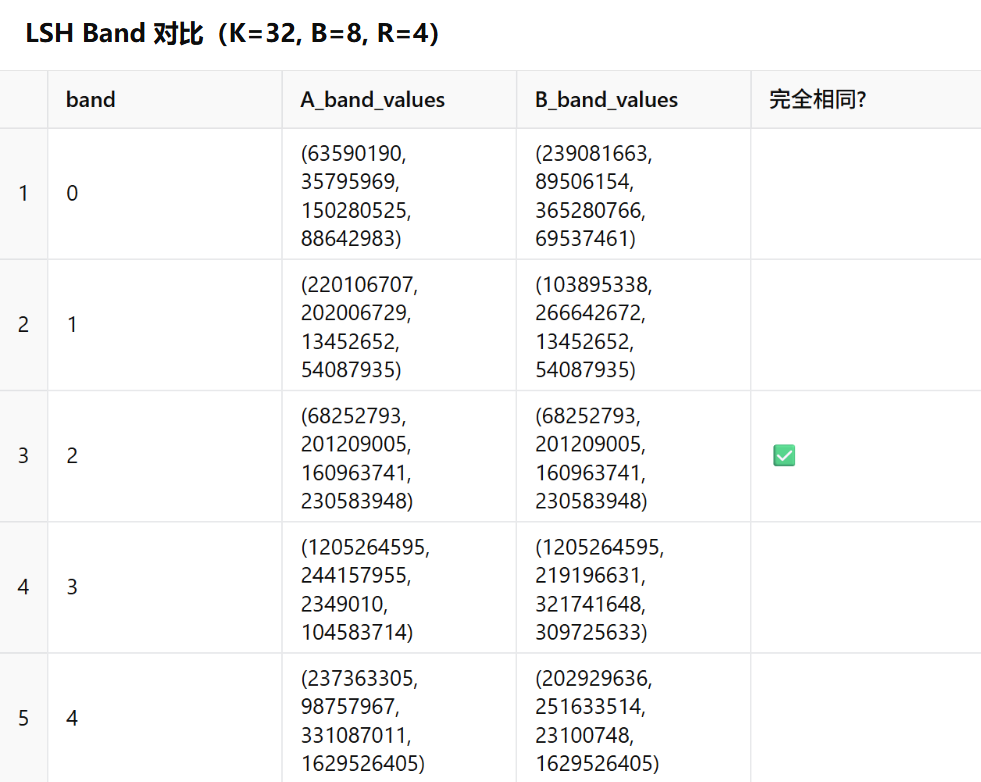
很明显在第3段中,A与B的数值完全一致,那么就需要进一步计算Jaccard确认相似度。
3.2 答疑:
混合去重的原因:
- 入库前去重,避免在千万级数据上与历史库逐条比对,防止计算量爆炸、避免系统过载。
- 杜绝同段内容反复出现,减少模型对同一数据顺序的记忆,训练更稳更泛化
四、质量与合规过滤
数据的质量检测类似于海关安检:把广告、违规内容拦在门外。
4.1 常见质量信息
重复比:计算n-gram重复率,重复率高的判为低质,得到rep_ratio重复率,减少符号堆砌、关键词刷屏的情况。
语言/领域识别:lang(语言)/domain(领域)分类器给出相应的权重;领域外降低权重(为质量计算提供数据)。
分类器过滤:广告/垃圾、NSFW/毒性、仇恨/暴力、低质量机器翻译、事实性差内容。
PII/DLP:手机号、地址等敏感信息一律按规则脱敏或删除;黑名单命中直接丢弃或改写。
白名单:允许引用到答案里的字段(如 policy_id/version/chunk_id)。
黑名单:禁止引用的内容。内部机密、越权承诺相关字段。
4.2 名词解释:
重复 n-gram:n 元语法就是由相邻的 n 个 token【词、字、子词、标点都可】组成的片段。
五、结构化与分块
5.1 目标:
把长文本切成模型易处理的片段,同时做到不丢语义( 保证一句话的完整性)、不跨文档,为预训练提供一致的最小处理单位chunk。
5.2 信息切分:
按结构/标点切:优先按段落、标题、句号/问号/顿号等切分,避免把一句话截断。
示例:(按标题划分)
{
"doc_id": "DOC-001",
"doc_title": "智能客服系统设计白皮书",
"page": 1,
"chunk_id": "DOC-001_p1_c01",
"pos_in_page": 1,
"type": "title",
"split_strategy": "by-structure",
"content": "第1章 概述"
}
保留文档边界:严格 不跨文档拼接;为每块生成chunk_id,记录文档编码/页码/位置。
指令模板化:统一成<|system|>
(系统提示词)、<|user|>(用户提示词)、<|assistant|>(标准答案)三段式,用于放置各类引用信息。示例:(按照提示词结构划分)
{
"doc_id": "DOC-001",
"doc_title": "智能客服系统设计白皮书",
"page": 1,
"chunk_id": "DOC-001_p1_c03",
"pos_in_page": 3,
"type": "prompt_template",
"split_strategy": "template-3part",
"content": "<|system|>\n你是电商服装领域的智能客服助理,需遵循平台政策,引用仅限白名单文档。\n\n<|user|>\n用户问题:{user_query}\n补充数据:{order_info},{policy_snippets}\n\n<|assistant|>\n请在不暴露内部推理的前提下,给出分步可执行方案,并在末尾列出来源编号。"
}
代码块:按函数/类/文件段切分,保留代码块标记<code>……<code/>,作为整体进行处理。
{
"doc_id": "DOC-002",
"doc_title": "算法代码样例",
"page": 3,
"chunk_id": "DOC-002_p3_c02",
"pos_in_page": 2,
"type": "code",
"split_strategy": "by-codeblock",
"content": "<code>\n# 示例:基于N-gram的简单下一词预测伪码\ncontext = tokens[-(n-1):]\ncandidates = vocab\nscores = {w: count((context,w))+k \\ (count(context) + k*|V|) for w in candidates}\nnext_word = argmax(scores)\n</code>"
}
表格:将表格内容转化为结构化文本。示例(表格转成结构化文本)
{
"doc_id": "DOC-001",
"doc_title": "智能客服系统设计白皮书",
"page": 2,
"chunk_id": "DOC-001_p2_c01",
"pos_in_page": 1,
"type": "table->structured",
"split_strategy": "table-to-text",
"content": "表:退换货政策(结构化)\n- 规则[1]: 条件=7天无理由且完好; 结果=可退/可换; 运费=责任方承担\n- 规则[2]: 商家错发/少件; 结果=退货/退款/补发; 运费=商家承担\n- 规则[3]: 物流破损; 结果=理赔流程; 运费=物流承担"
}
最后将文本的处理结果以JSON格式输出,记录字段与对应的值。
六、词表与分词
6.1 目标:
训练一套能覆盖你的语域的分词器与词表,并把角色/代码/占位符等“不可拆”的符号标记为 special tokens,保证训练与推理一致。
6.2 分词操作步骤:
选择分词算法:中文/英文常用 SentencePiece-Unigram 或 BPE进行分词。
归一化策略对齐:
- 货币统一:
¥/元/RMB → CNY 199.00 / 59.00 / 1299.00(可按需要保留两位小数)。 - 日期统一:
2025/10/10 → 2025-10-10。 - 长 ID:统一用
<ORDER_ID_18>占位(作为 special token)。 - URL:对于数据中出现的URL链接,示例1直接
<URL>;示例2仅保留路径shop.xxxx.com/help/refund。 - Emoji:
😄 → :smile:。 - 对话结构化:固定三段式
<|system|> / <|user|> / <|assistant|>,并以<EOT>结束一轮、<EOS>作为样本结束标记。 - PII/DLP:手机号、地址等以
<PHONE_11> / <ADDR>表示,训练与输出仅用占位符。 - special tokens:在
meta行声明,no_split: true表示分词与BPE阶段不可拆。
- 货币统一:
词表版本化:保存词表的版本号信息,训练/推理用同一版本。
6.3 名词解释:
BPE/Unigram:两种常用子词分词训练算法。
byte_fallback:当等于true时,SentencePiece中遇到未知字符使用其UTF-8编码字节表示。
Normalizer:分词前的标准化环节(大小写/全半角等)。
鲁棒性:系统在数据中错误信息、噪音等干扰下,仍能处理正确的能力。
6.4 答疑:
数据训练的第二步和第六步都进行“归一化”处理的原因:
二者各自管辖的领域不同:第二步是数据入库前的归一化,把不同来源的原始文本先统一成同一写法(编码、全角半角……),便于去重、泄漏防护、数据库写入等操作。
第六步是进入模型前的 tokenizer 归一化,以便后续进行采样配方、训练样本构造、切分与去泄露的操作。
总结:
本篇围绕数据产线阐述了如何将杂乱数据变为可训练语料,为后续训练样本集划分、训练目标设定、数据审计等环节打下基础。如果你觉得这篇文章有帮助,不妨点个赞或收藏支持一下!
未完待续。。。