【Pycorrector实战】:基于pycorrector进行智能纠错
一、背景
最近做的项目里提到了一个需求,就是针对用户输入的文本要能够智能纠错,要可以识别到文本中有哪些错别字。针对这个需求在网上各种查资料,发现了pycorrector这个神器,感觉还是蛮好用的。这里记录下并且为了分享给各位小伙伴~,不喜勿喷,多谢~。
二、概述
pycorrector is a toolkit for text error correction. 文本纠错,中文文本纠错工具,支持中文音似、形似、语法错误纠正,python3.8开发。pycorrector实现了Kenlm、ConvSeq2Seq、BERT、MacBERT、ELECTRA、ERNIE、GPT等多种模型的文本纠错,评估各模型的效果,开箱即用。
三、正文
(一)、pycorrector体验
https://www.mulanai.com/product/corrector/#docs
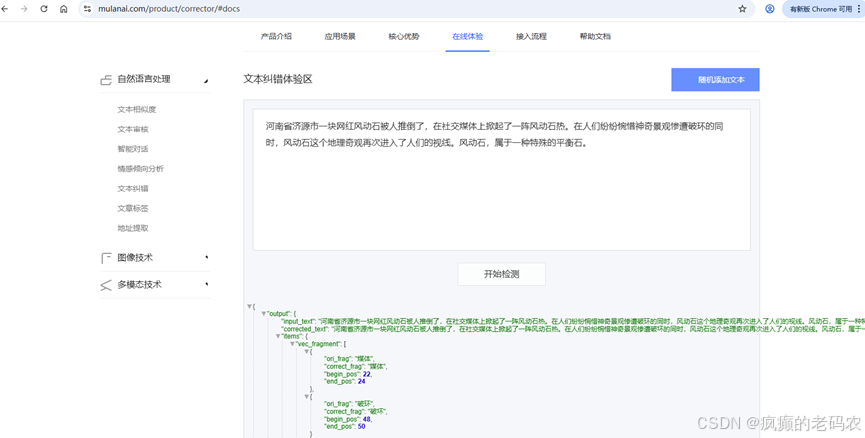
详细介绍地址:https://shibing624.github.io/pycorrector/
Pycorrector执行对文本纠错是需要依赖模型的,模型列表如下:
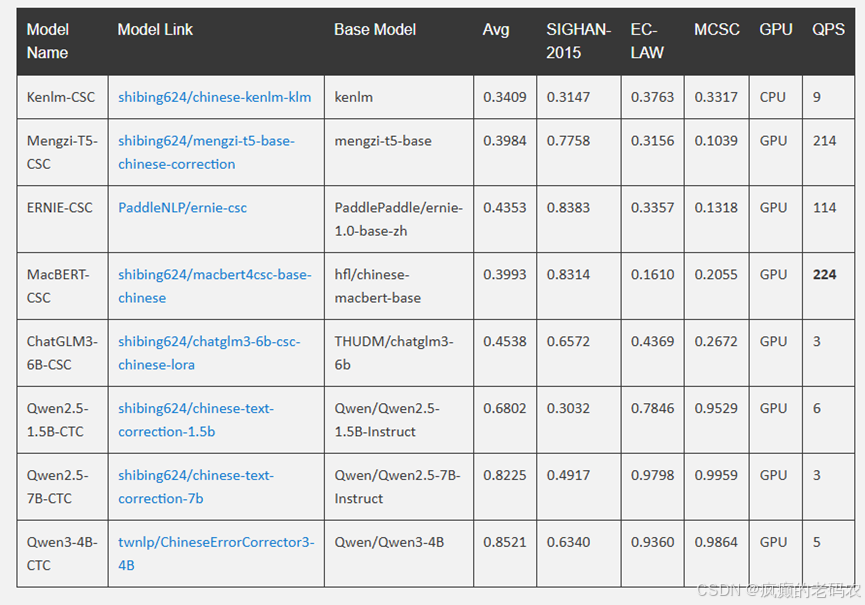
(二)、pycorrector开源
https://github.com/shibing624/pycorrector
(三)、pycorrector安装
官方写的安装方式有3种:
方式1:直接安装
pip install -U pycorrector方式2:基于源码安装
pip install -r requirements.txtgit clone https://github.com/shibing624/pycorrector.gitcd pycorrectorpip install --no-deps .方式3:docker使用
docker run -it -v ~/.pycorrector:/root/.pycorrector shibing624/pycorrector:0.0.2基于https://shibing624.github.io/pycorrector/这里提到的模型,准备下载一个
Kenlm-CSC模型,于是从https://huggingface.co/shibing624/chinese-kenlm-klm地址中进行下载,发现国内的网络访问不了huggingface。
由于我的Linux服务器可以上外网,基于目前的状况,于是选择了docker方式进行安装,直接执行下面命令:
docker run -it -v ~/.pycorrector:/root/.pycorrector shibing624/pycorrector:0.0.2当执行之后,自动就把镜像下载下来了,如下:

(四)、pycorrector验证
1、错误检测-执行如下代码:
from pycorrector import Correctorm = Corrector()idx_errors = m.detect('少先队员因该为老人让坐')print(idx_errors)如下效果:
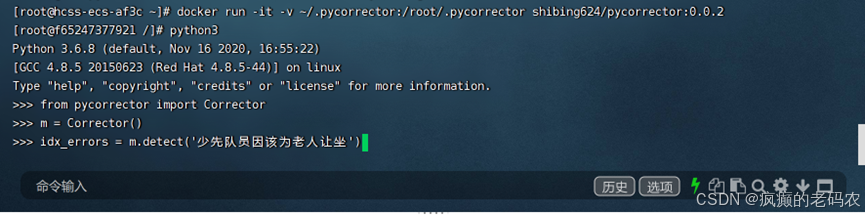
当执行idx_errors = m.detect('少先队员因该为老人让坐')的时候自动就下载了模型,花了半个小时的时候终于把模型自动下载下来了,如下信息:
zh_giga.no_cna_cmn.prune01244.klm
接着执行:
print(idx_errors)如下结果:
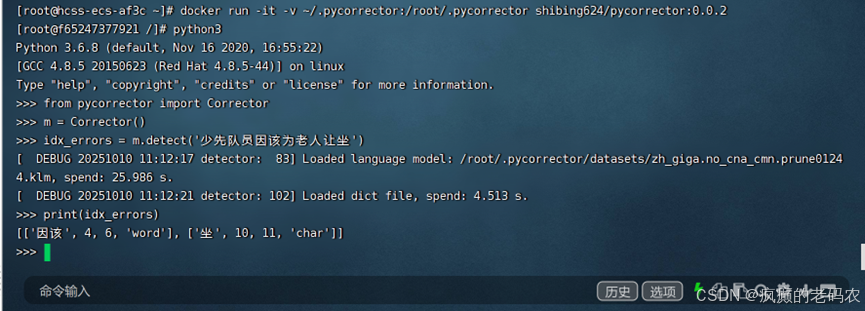
通过这个截图可以看出来,已经成功的找出来错别字了
[['因该', 4, 6, 'word'], ['坐', 10, 11, 'char']]2、错误纠正-执行如下代码:
from pycorrector import Correctorm = Corrector()print(m.correct('少先队员因该为老人让坐'))如下效果:
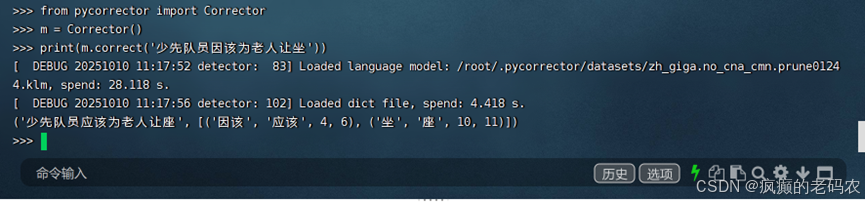
通过这个截图可以看出来,已经成功的纠正了
('少先队员应该为老人让座', [('因该', '应该', 4, 6), ('坐', '座', 10, 11)])四、结束语
基于这里相关的能力,完全可以对中文文本进行错别字识别和智能纠错。