嵌入模型蓝图与扫盲
引入
作为一个AI开发者,Emebdding是经常接触的,然而大部分停留在文本嵌入模型做RAG匹配,并未对嵌入模型做一个全局的了解,这篇文章介绍嵌入模型技术蓝图以及蓝图中的概念进行扫盲。
技术蓝图
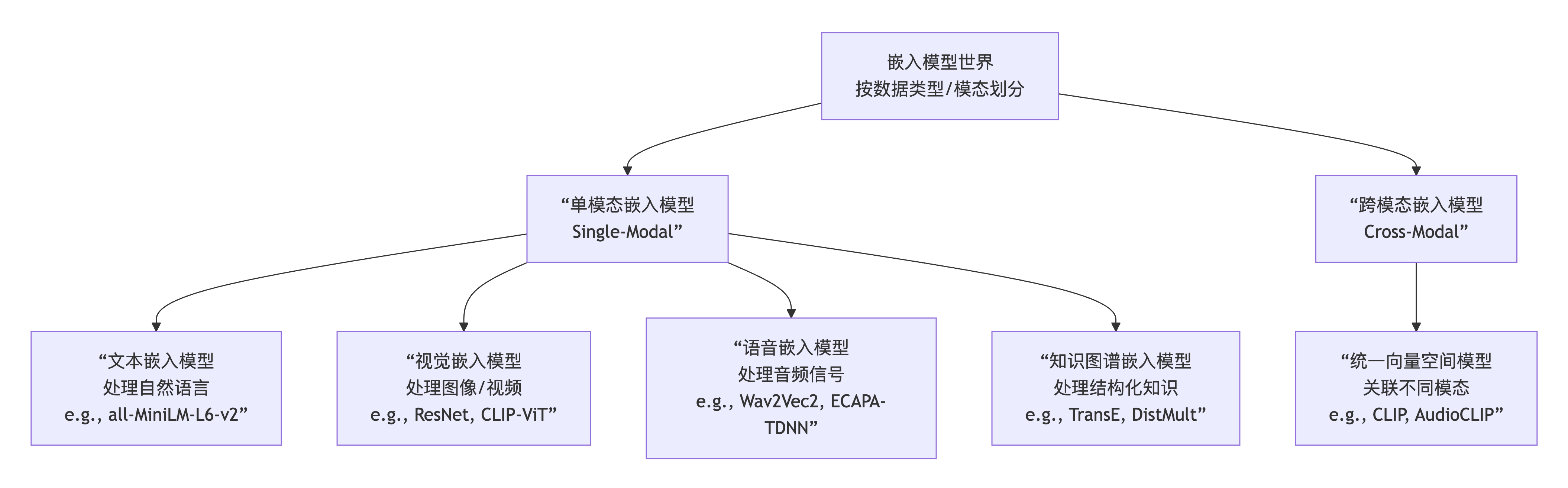
单模态
NLP自然语言处理是大家最了解的,比如传统向量匹配,进行问答,就是切片之后对使用文本嵌入模型进行向量化。
CV
计算机视觉,多多少少也接触到过,使用过,图像嵌入模型。
KGE
知识图谱领域,KnowledgeGraphEmbedding知识图谱嵌入是图谱领域中使用的Embedding模型,
是专门针对结构化知识的嵌入领域,有其独特的、与Transformer无关的核心算法思想(如翻译模型、张量分解模型)。
简单理解
Transformer 看作是处理文本序列的“主流兵器”。
而把 KGE模型(TransE, DistMult等) 看作是处理知识三元组的“专属神兵”。
CV计算机视觉是处理图像一类的图像嵌入模型。
语音识别,处理音频
单模态模型是基础,它们各自在垂直领域深耕。
跨模态模型是未来,它致力于融合这些单模态的能力,向着更通用、更接近人类理解方式的人工智能迈进。
自然语言处理嵌入模型扫盲(文本嵌入模型)
做什么?
这个场景大家肯定不说熟悉,基本不陌生,做RAG,做相似度匹配。
代表架构:Transformer
总结—“文本嵌入模型基本都是Transformer架构”——完全符合当前的技术现状。
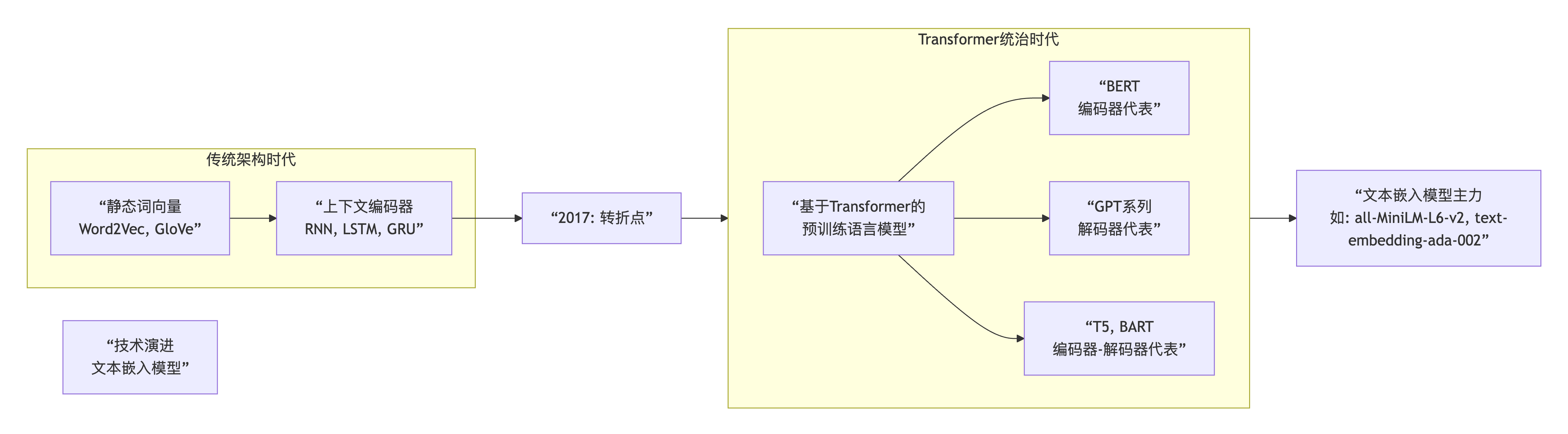
当前几乎所有最先进、最常用的文本嵌入模型,都基于 Transformer 架构。 Transformer 凭借其强大的自注意力机制,已经彻底统治了现代自然语言处理领域。
详细NLP技术演进
1. “很老的传统模型”:Transformer 之前的世界
在 Transformer 出现之前,主流模型确实是 RNN、LSTM 和 GRU。
核心特点:顺序处理。它们像一个人一个字一个字地阅读,必须等前一个字处理完,才能处理下一个。这导致了:
计算效率低:无法并行计算,训练慢。
长程依赖问题:当句子很长时,模型容易“忘记”开头的信息,难以捕捉远距离词语之间的关系。
2. Transformer 的革命:自注意力机制
Transformer 的核心是自注意力机制。
核心特点:全局感知。它不是顺序处理,而是可以同时关注输入序列中的所有词,并计算每个词与其他所有词之间的“关联度”。
优势1:强大的上下文捕捉能力。无论词语相隔多远,自注意力都能直接建立连接,从而更好地理解句子的完整含义。
优势2:极高的并行化能力。因为所有词是同时处理的,所以可以充分利用GPU等硬件进行并行计算,训练速度极大提升。
3. 为什么文本嵌入模型基本是 Transformer?
我们目前使用的文本嵌入模型,绝大多数都是在大型预训练语言模型 的基础上,通过特定任务(如对比学习)微调得到的。而这些预训练语言的基石,就是 Transformer。
BERT 家族(如 all-MiniLM-L6-v2 的“老师”BERT):使用 Transformer 的编码器,非常适合做文本理解任务,是生成高质量句子嵌入的主力。
GPT 家族:使用 Transformer 的解码器,更擅长文本生成。
所以,当您看到一个现代的文本嵌入模型时,几乎可以断定它的骨架是一个 Transformer。它之所以能很好地理解语义、生成高质量的向量表示,根本原因就在于其内部的自注意力机制。
总结一下:
过去时:RNN, LSTM -> 用于处理序列,但效率低且有长程依赖问题。
现在时:Transformer (自注意力) -> NLP 的基础架构,是当前所有主流文本嵌入模型的引擎。
Transformer与文本嵌入模型的关系
Transformer 架构,就是当今所有主流大语言模型(的GPT、DeepSeek、Qwen、豆包等)以及文本嵌入模型共同的核心引擎和基石。
为什么Transformer是目前LLM大语言模型以及文本嵌入模型的基石?
解决了核心瓶颈:
在它之前,RNN/LSTM等模型无法有效处理长文本依赖,且计算无法并行,效率低下。
Transformer的自注意力机制 一举解决了这两个问题,让模型能够真正地“通读全文”并深刻理解上下文。
提供了可扩展的骨架:
Transformer的编码器-解码器设计非常灵活。
主要走编码器路线:专注于“理解”任务。例如:BERT 系列、文本嵌入模型。它们非常适合做分类、阅读理解、生成句子向量。
主要走解码器路线:专注于“生成”任务。例如:GPT 系列、DeepSeek、Qwen、豆包。它们根据上文自动生成下一个词,从而实现对话、创作、推理等能力。
T5、BART 等模型则同时使用编码器和解码器,擅长摘要、翻译等“理解后生成”的任务。
催生了“预训练-微调”范式:
Transformer架构使得我们能够先用海量无标注数据(如整个互联网的文本)训练一个庞大的基础模型。这个模型学会了语言的通用语法、知识和逻辑。
然后,我们可以像给一个“通才”进行“职业技能培训”一样,用少量特定任务的数据对这个基础模型进行微调,就能得到各种专家模型,比如:
微调用于生成句向量的,就是 文本嵌入模型。
微调用于对话的,就是 聊天机器人。
微调用于写代码的,就是 代码助手。
总结:
目前我们大多数接触的都是基于Transformer架构衍生出来的产品,预训练+微调这种范式,诞生了各种专家模型,比如聊天机器人、代码助手、文本嵌入模型。
KGE知识图谱嵌入
做什么?
KGE最主要、最独特的作用是对知识图谱本身进行推理和补全。
想象一下,知识图谱就像一个庞大的、记录了世界知识的蜘蛛网,但这个网上有很多漏洞。KGE的作用就是预测并补上这些漏洞。
核心作用归纳
链接预测 - 核心中的核心
问题:知识图谱是不完整的,缺少大量事实。例如,我们知道(马云,创立,阿里巴巴),但可能缺少(马云,出生地,?)。
作用:KGE模型可以计算所有候选实体(如“杭州”、“北京”、“上海”)的得分,预测最有可能的尾实体是“杭州”。这就是在发现缺失的链接。
关系推理
问题:如何从已知事实中推断出新事实?
作用:通过学习到的向量表示,模型可以捕捉关系的逻辑规律。
对称关系:如果 (A, 夫妻, B) 成立,那么 (B, 夫妻, A) 也成立。模型会学到 夫妻 关系向量接近零向量,因为 A + 0 ≈ B 且 B + 0 ≈ A。
逆关系:(A, 雇主, B) 的逆是 (B, 雇员, A)。模型会学到 雇主 和 雇员 的向量近似相反。
组合关系:如果 (A, 出生于, B) 且 (B, 位于, C),那么可以推断 (A, 籍贯, C)。模型会学到 出生于 + 位于 ≈ 籍贯。
知识图谱补全
这是链接预测和关系推理的最终目的。通过不断预测缺失的链接,让整个知识图谱变得更加完整和丰富。
实体分类
问题:判断一个实体属于哪个类别。
作用:在向量空间中,同类别的实体会聚集在一起。通过聚类或分类算法,可以判断“苹果”和“香蕉”都是“水果”类别的实体。
推荐系统
问题:如何给用户推荐商品或内容?
作用:将用户和物品都视为知识图谱中的实体。通过分析用户与物品、物品与物品之间的关系(如购买、浏览、属于同一类别),在向量空间中寻找距离用户最近(最相关)的物品。
KGE 的意义
KGE的意义在于它解决了符号主义AI的核心难题。
难题:传统的知识图谱由离散的符号(实体、关系)组成,计算机无法直接计算“北京”和“中国”之间的逻辑关系。
KGE的解决之道:通过嵌入,它将符号逻辑世界和向量数值世界架起了一座桥梁。
可计算:符号变成了向量,逻辑关系变成了向量运算(如加法、点积),计算机可以高效处理。
泛化能力:即使某些关系没有在训练数据中明确出现,模型也能通过向量空间中的几何关系进行推测,具备了“举一反三”的能力。
与深度学习融合:使得符号知识能够被深度学习模型理解和利用,推动了符号主义与连接主义的融合,是迈向更通用AI的重要一步。
原理简单解释
KGE的原理可以用一个简单的比喻来理解:地图导航。
目标:将知识图谱中的所有实体和关系,映射到一张高维“地图”(向量空间)中。
核心思想:在这张地图上,一个真实的三元组 (头实体, 关系, 尾实体) 应该满足一个特定的几何关系。
以最经典的 TransE 模型为例:
规则:它规定的关系法则是 “平移”。
操作:如果你从“北京”这个点出发,沿着“是…的首都”这个关系向量所指的方向走一段路,你应该恰好到达“中国”这个点。
公式:向量(北京) + 向量(是…的首都) ≈ 向量(中国)
训练:模型通过不断调整所有实体和关系的向量位置,让所有真实的三元组都尽量满足这个“平移”规则,同时让虚假的三元组不满足这个规则。
其他模型:
TransR:认为不同的关系应该在各自的“子地图”上做平移。比如“地理关系”一张图,“职业关系”另一张图。
DistMult/ComplEx:它们的规则不是“平移”,而是“匹配度”。它们会计算 (北京, 是…的首都, 中国) 这个组合的“匹配分数”,目标是让真实三元组的分数远高于虚假三元组。
总结
知识图谱的这种符号数据(实体+关系),是无法直接被计算机分析计算的,
KGE的作用就是把结构化的知识,图谱三元组,实体+关系这样的符号,让他们通过embedding技术,创造一种向量几何空间,让知识图谱数据在向量几何空间中进行推理,计算。
PS:中国的首都,是北京,就是最常见的例子,通过KGE技术,进行链接预测,把中国的首都,链接到北京。