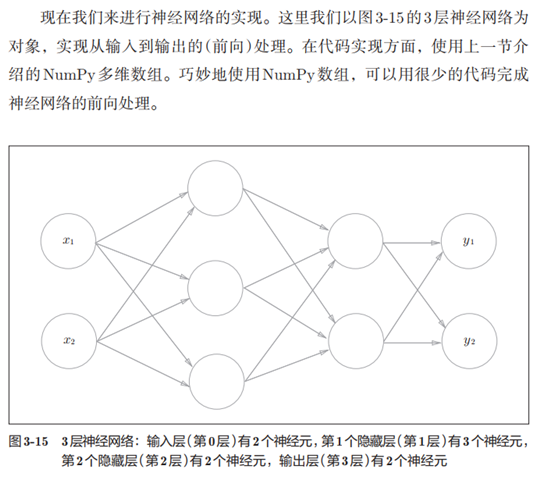
3. 3层神经网络的实现
3层神经网络的实现
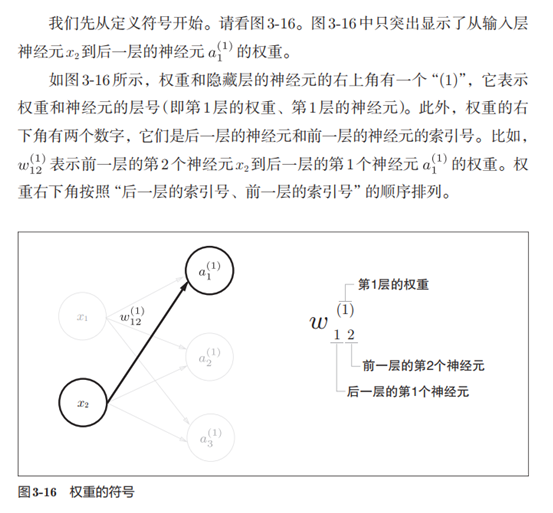
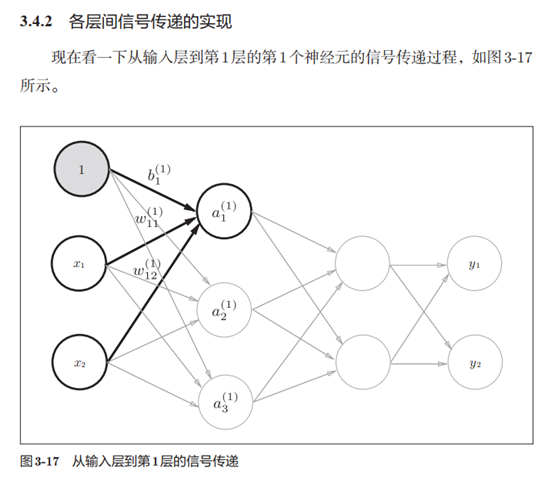
1. 输入层到第1层的第1个神经元的信号传递过程


>>> X = np.array([1.0, 0.5])
>>> W1 = np.array([[0.1, 0.3, 0.5],[0.2, 0.4, 0.6]])
>>> B1 = np.array([0.1, 0.2, 0.3])
>>> print(W1.shape)
(2, 3)
>>> print(X.shape)
(2,)
>>> print(B1.shape)
(3,)
>>> A1 = np.dot(X, W1) + B1
>>> A1
array([0.3, 0.7, 1.1])
>>>
这个运算和上一节进行的运算是一样的。 W1是2 × 3的数组, X是元素个
数为2的一维数组。这里, W1和X的对应维度的元素个数也保持了一致。
2.激活函数
隐藏层的加权和(加权信号和偏置的总和)用a表示,被
激活函数转换后的信号用z表示。此外,图中h()表示激活函数,这里我们
使用的是sigmoid函数。
Z1 = sigmod(A1)
print(Z1) # [0.57444252, 0.66818777, 0.75026011]
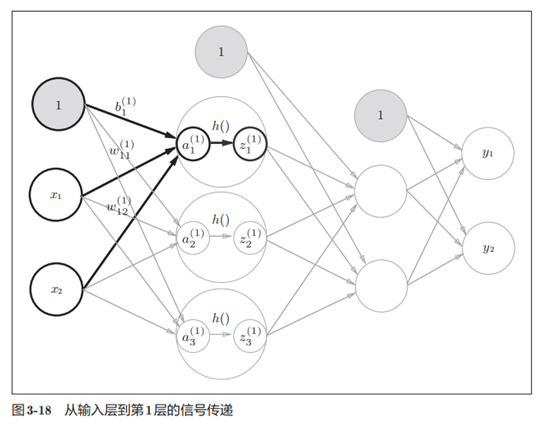
# 输入层到第1层的信号传递
X = np.array([1.0, 0.5])
W1 = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]]) # 2个输入,每个输入会发散出去3个权重分配给后面的3个神经元
B1 = np.array([0.1, 0.2, 0.3])
print(W1.shape) # (2, 3)
print(X.shape) # (2,)
print(B1.shape) # (3,)
A1 = np.dot(X, W1) + B1
Z1 = sigmoid(A1)
print(A1)
print(Z1)
3.实现第1层到第2层的信号传递
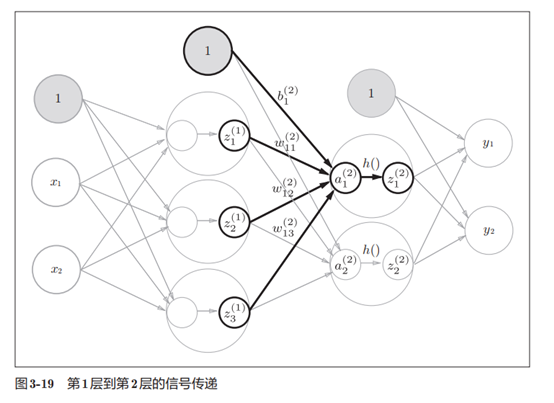
# 第1层到第2层的信号传递
W2 = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6]])
B2 = np.array([0.1, 0.2])
print(Z1.shape)
print(W2.shape)
print(B2.shape)
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2)
print(A2)
print(Z2)
4.实现第2层到输出层的信号传递
这里我们定义了 identity_function()函数(也称为“恒等函数”),并将
其作为输出层的激活函数。恒等函数会将输入按原样输出,因此,这个例子
中没有必要特意定义identity_function()。这里这样实现只是为了和之前的
流程保持统一。另外,图3-20中,输出层的激活函数用σ()表示,不同于隐
藏层的激活函数h()(σ读作sigma)
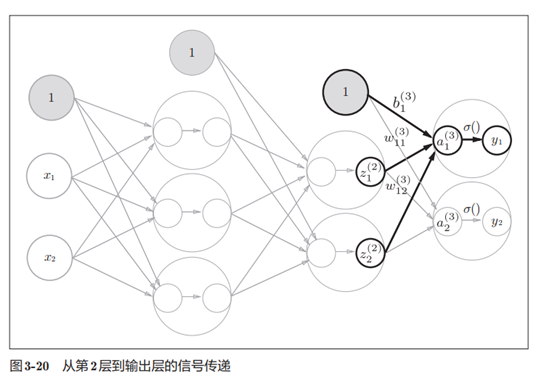
# 第2层到输出层的信号传递
def identify_function(x):return X
W3 = np.array([[0.1, 0.3],[0.2, 0.4]])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
Y = identify_function(A3)
print("第2层到输出层的信号传递")
print(A3)
print(Y)
输出层所用的激活函数,要根据求解问题的性质决定。
一般地,回归问题可以使用恒等函数,二元分类问题可以使用 sigmoid函数,多元分类问题可以使用 softmax函数。关于输出层的激活函数,我
们将在下一节详细介绍。
5.代码实现小结
至此,我们已经介绍完了3层神经网络的实现。现在我们把之前的代码
实现全部整理一下。这里,我们按照神经网络的实现惯例,只把权重记为大
写字母W1,其他的(偏置或中间结果等)都用小写字母表示。
import numpy as np
import matplotlib.pyplot as pltdef sigmoid(x):return 1 / (1 + np.exp(-x))def identify_function(x):return xdef init_network():network = {}network['W1'] = np.array([[0.1, 0.3, 0.5], [0.2, 0.4, 0.6]])network['b1'] = np.array([0.1, 0.2, 0.3])network['W2'] = np.array([[0.1, 0.4],[0.2, 0.5],[0.3, 0.6]])network['b2'] = np.array([0.1, 0.2]) network['W3'] = np.array([[0.1, 0.3],[0.2, 0.4]])network['b3'] = np.array([0.1, 0.2])return networkdef forward(network, x):W1, W2, W3 = network['W1'], network['W2'], network['W3']b1, b2, b3 = network['b1'], network['b2'], network['b3']a1 = np.dot(x, W1) + b1z1 = sigmoid(a1)a2 = np.dot(z1, W2) + b2z2 = sigmoid(a2)a3 = np.dot(z2, W3) + b3y = identify_function(a3)return ynetwork = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y) # [0.31682708 0.69627909]
这里定义了 init_network()和 forward()函数。 init_network()函数会进
行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变
量 network中保存了每一层所需的参数(权重和偏置)。 forward()函数中则封
装了将输入信号转换为输出信号的处理过程。
另外,这里出现了forward(前向)一词,它表示的是从输入到输出方向
的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward,
从输出到输入方向)的处理。
至此,神经网络的前向处理的实现就完成了。通过巧妙地使用NumPy
多维数组,我们高效地实现了神经网络。
6.输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出
层的激活函数。
一般而言,回归问题用恒等函数,分类问题用softmax函数。
机器学习的问题大致可以分为分类问题和回归问题。
分类问题是数据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性
的问题就是分类问题。
回归问题是根据某个输入预测一个(连续的)数值的问题。比如,根据一个人的图像预测这个人的体重的问题就是回归问题(类似“57.4kg”这样的预测)。
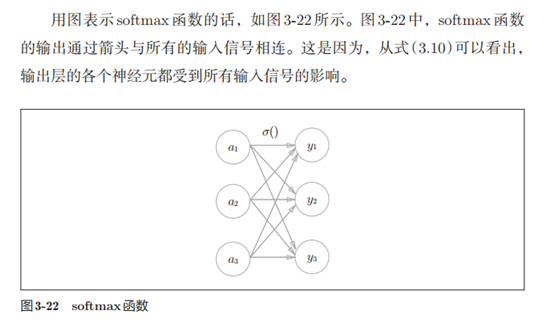
6.1 恒等函数和softmax函数
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直
接输出。因此,在输出层使用恒等函数时,输入信号会原封不动地被输出。
另外,将恒等函数的处理过程用之前的神经网络图来表示的话,则如图3-21
所示。和前面介绍的隐藏层的激活函数一样,恒等函数进行的转换处理可以
用一根箭头来表示。

import numpy as np
import matplotlib.pyplot as pltdef softmax(a):exp_a = np.exp(a)sum_exp_a = np.sum(exp_a)y = exp_a / sum_exp_areturn y
上面的softmax函数的实现虽然正确描述了式(3.10),但在计算机的运算
上有一定的缺陷。这个缺陷就是溢出问题。 softmax函数的实现中要进行指
数函数的运算,但是此时指数函数的值很容易变得非常大。比如, e10的值
会超过20000, e100会变成一个后面有40多个0的超大值, e1000的结果会返回
一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现“不
确定”的情况。
计算机处理“数”时,数值必须在4字节或8字节的有限数据宽度内。
这意味着数存在有效位数,也就是说,可以表示的数值范围是有
限的。因此,会出现超大值无法表示的问题。这个问题称为溢出,
在进行计算机的运算时必须(常常)注意。

import numpy as np
import matplotlib.pyplot as pltdef softmax(a):c = np.max(a)exp_a = np.exp(a - c)sum_exp_a = np.sum(exp_a)y = exp_a / sum_exp_areturn ya = np.array([0.3, 2.9, 4.0])
y = softmax(a)
print(y) # [0.01821127 0.24519181 0.73659691]
print(np.sum(y)) # 1.0
如上所示, softmax函数的输出是0.0到1.0之间的实数。并且, softmax
函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正
因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。
并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此,
神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中,
由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数
一般会被省略。