YOLO v1:目标检测领域的单阶段革命之作
文章目录
- 一、YOLO v1的核心思想:把检测变成“回归问题”
- 二、YOLO v1的网络架构:借鉴GoogLeNet,简化设计
- 三、YOLO v1的损失函数:平衡分类、定位与置信度误差
- 1. 边界框位置误差(加权系数=5)
- 2. 置信度误差(正样本加权系数=1,负样本加权系数=0.5)
- 3. 类别误差(加权系数=1)
- 四、YOLO v1的后处理:非极大值抑制(NMS)
- 五、YOLO v1的性能与优缺点
- 1. 性能表现(对比传统算法)
- 2. 优点
- 3. 缺点
- 六、总结:YOLO v1的意义与影响
在目标检测技术发展历程中,2016年Joseph Redmon等人提出的YOLO(You Only Look Once)算法无疑是一座重要的里程碑。作为单阶段目标检测的开创者之一,YOLO v1打破了传统两阶段检测算法的固有框架,以“端到端”的思路将目标检测问题转化为回归问题,极大地提升了检测速度,为实时目标检测场景(如自动驾驶、视频监控)奠定了基础。
一、YOLO v1的核心思想:把检测变成“回归问题”
传统目标检测算法(如R-CNN系列)采用“两阶段”流程:先生成候选框(Region Proposal),再对候选框进行分类和位置修正,步骤繁琐且速度较慢。而YOLO v1提出了一种更简洁的思路——将目标检测直接转化为单神经网络的回归任务,具体可拆解为3个关键点:
-
网格划分(Grid Cell)
将输入图像均匀划分为 S×SS \times SS×S 个网格(YOLO v1中默认 S=7S=7S=7)。如果某个目标的中心点落在某个网格内,那么该网格就负责预测这个目标的类别和位置。这种设计让每个网格“各司其职”,避免了对全图所有可能区域的遍历。
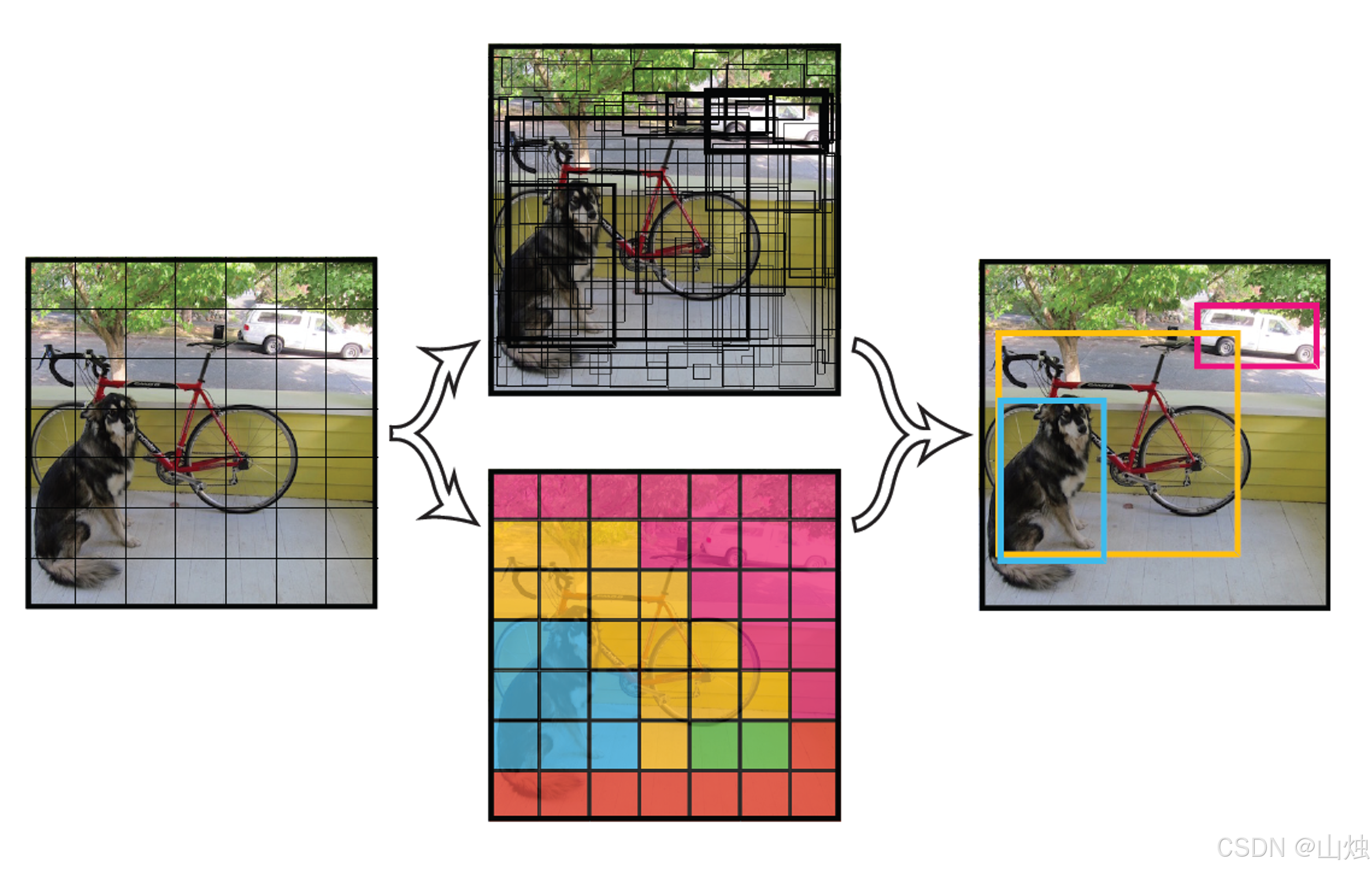
-
边界框与置信度预测
每个网格会预测 BBB 个边界框(Bounding Box,YOLO v1中 B=2B=2B=2),每个边界框包含5个回归参数:- (x,y)(x, y)(x,y):边界框中心点相对于当前网格左上角的偏移量(归一化到0-1,确保偏移范围在网格内);
- (w,h)(w, h)(w,h):边界框的宽和高(相对于整幅图像的尺寸归一化到0-1);
- ccc:置信度(Confidence),表示该边界框包含目标的概率,计算公式为:
c=Pr(Object)×IoU(pred, ground truth)c = \text{Pr(Object)} \times \text{IoU(pred, ground truth)}c=Pr(Object)×IoU(pred, ground truth)
若网格内无目标,c=0c=0c=0;若有目标,则 Pr(Object)=1\text{Pr(Object)}=1Pr(Object)=1,置信度等于边界框与真实框的IoU(交并比)。
-
类别概率预测
每个网格还会预测 CCC 个类别概率(YOLO v1针对VOC数据集,C=20C=20C=20),表示该网格包含目标时,目标属于某一类别的概率 Pr(Classi| Object)\text{Pr(Class}_i\text{ | Object)}Pr(Classi | Object)。
最终,YOLO v1的输出是一个 S×S×(B×5+C)S \times S \times (B \times 5 + C)S×S×(B×5+C) 的张量。以 S=7,B=2,C=20S=7, B=2, C=20S=7,B=2,C=20 为例,输出维度为 7×7×307 \times 7 \times 307×7×30,完美涵盖了所有网格的预测信息。
二、YOLO v1的网络架构:借鉴GoogLeNet,简化设计
YOLO v1的网络结构以GoogLeNet为基础,移除了复杂的Inception模块,改用“1×1卷积+3×3卷积”的组合来减少参数并提升特征提取能力,整体分为卷积层(特征提取) 和全连接层(回归预测) 两部分,共24个卷积层+2个全连接层:
| 网络层类型 | 具体配置 | 作用 |
|---|---|---|
| 输入层 | 448×448×3(RGB图像) | 原始图像输入,需统一尺寸(训练时先以224×224预训练分类,再微调至448×448) |
| 卷积层(共24层) | 交替使用1×1卷积(降维,减少计算量)和3×3卷积(提取空间特征),搭配MaxPooling(下采样) | 逐步提取图像的低、中、高维特征,最终得到7×7×1024的特征图 |
| 全连接层(2层) | 第1层:7×7×1024 → 4096;第2层:4096 → 7×7×30 | 将卷积层输出的特征图映射为最终的预测张量 |
需要注意的是,YOLO v1没有使用全连接层常见的Dropout(防止过拟合),而是通过限制全连接层的参数规模(4096维)来平衡性能与过拟合风险。
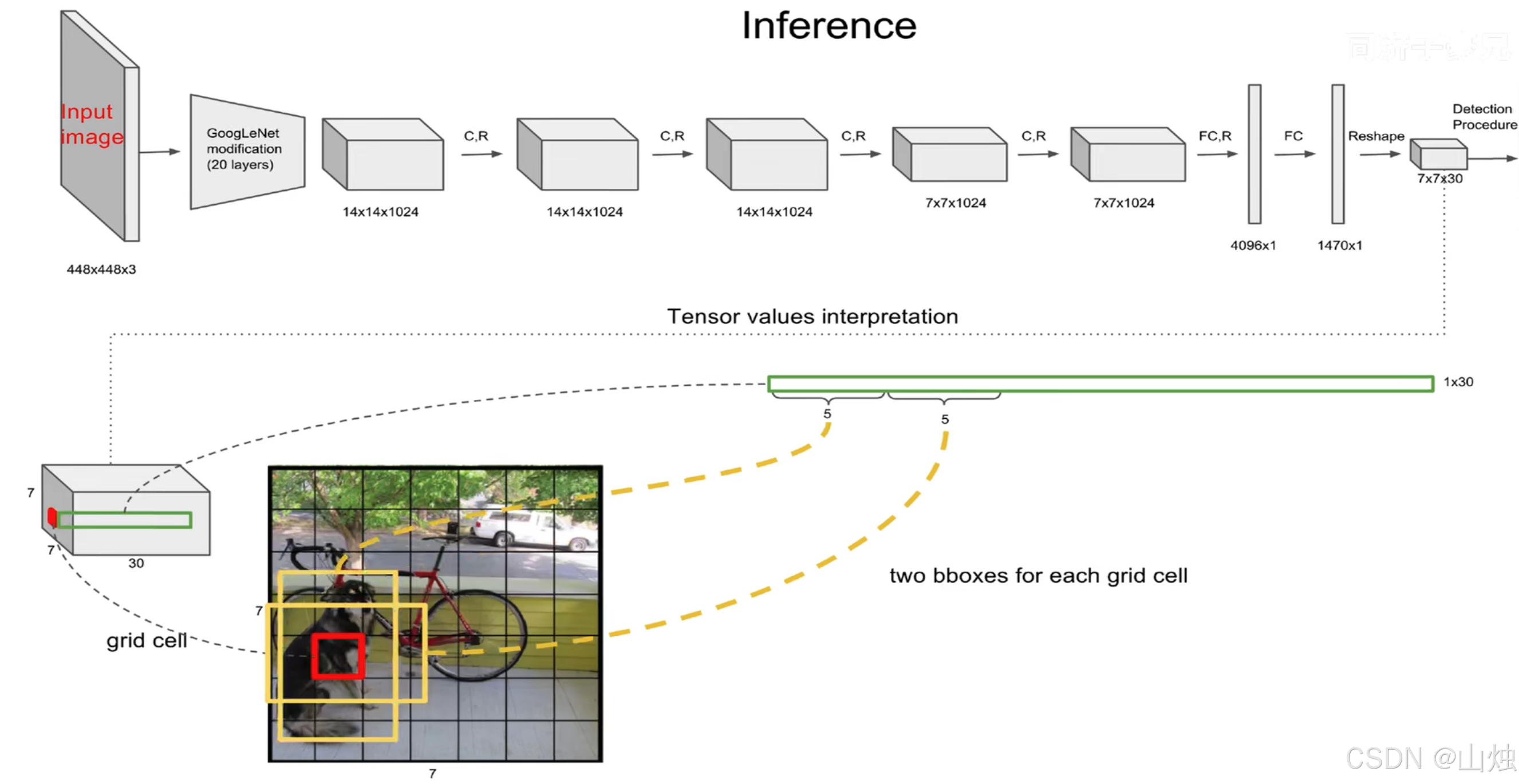
三、YOLO v1的损失函数:平衡分类、定位与置信度误差
由于YOLO v1将检测视为回归问题,损失函数采用均方误差(MSE),但为了避免不同类型误差(如位置误差、置信度误差、类别误差)的权重失衡,设计了加权损失函数,具体分为3部分:
1. 边界框位置误差(加权系数=5)
对包含目标的网格中,与真实框IoU更大的边界框(“负责”预测该目标的边界框)的位置误差进行加权,公式为:
λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2+(wi−w^i)2+(hi−h^i)2]\lambda_{\text{coord}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[ (x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2 + (\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2 \right]λcoord∑i=0S2∑j=0B1ijobj[(xi−x^i)2+(yi−y^i)2+(wi−w^i)2+(hi−h^i)2]
- 1ijobj\mathbb{1}_{ij}^{\text{obj}}1ijobj:指示函数,若网格iii的第jjj个边界框负责预测目标,取1,否则取0;
- 对www和hhh开根号:因为小边界框的位置误差对检测结果影响更大,开根号后能让小框的误差在损失中占比更高(例如,同样是10像素的宽误差,小框的相对误差远大于大框)。
2. 置信度误差(正样本加权系数=1,负样本加权系数=0.5)
- 正样本(网格有目标):计算负责预测的边界框的置信度误差,权重为1;
- 负样本(网格无目标):计算所有边界框的置信度误差,权重为0.5(避免无目标网格的置信度误差淹没正样本误差);
公式为:
∑i=0S2∑j=0B1ijobj(ci−c^i)2+λnoobj∑i=0S2∑j=0B1ijnoobj(ci−c^i)2\sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} (c_i - \hat{c}_i)^2 + \lambda_{\text{noobj}} \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{noobj}} (c_i - \hat{c}_i)^2∑i=0S2∑j=0B1ijobj(ci−c^i)2+λnoobj∑i=0S2∑j=0B1ijnoobj(ci−c^i)2
其中λnoobj=0.5\lambda_{\text{noobj}}=0.5λnoobj=0.5。
3. 类别误差(加权系数=1)
仅对包含目标的网格计算类别概率误差,公式为:
∑i=0S21iobj∑c∈classes(pi(c)−p^i(c))2\sum_{i=0}^{S^2} \mathbb{1}_{i}^{\text{obj}} \sum_{c \in \text{classes}} (p_i(c) - \hat{p}_i(c))^2∑i=0S21iobj∑c∈classes(pi(c)−p^i(c))2
整体损失函数通过加权,优先保证了位置误差和正样本的预测精度,这对目标检测任务至关重要。
四、YOLO v1的后处理:非极大值抑制(NMS)
YOLO v1输出7×7×2=98个边界框,其中存在大量冗余(多个边界框预测同一个目标),因此需要非极大值抑制(NMS) 过滤冗余框,步骤如下:
- 置信度阈值筛选:先过滤掉置信度低于阈值(如0.2)的边界框,减少候选框数量;
- 类别概率修正:将每个边界框的置信度与对应网格的类别概率相乘,得到“类别置信度”(表示该框为某类目标的最终置信度):
Pr(Classi| Object)×Pr(Object)×IoU=Pr(Classi)×IoU\text{Pr(Class}_i\text{ | Object)} \times \text{Pr(Object)} \times \text{IoU} = \text{Pr(Class}_i\text{)} \times \text{IoU}Pr(Classi | Object)×Pr(Object)×IoU=Pr(Classi)×IoU - NMS迭代过滤:对每个类别,按类别置信度降序排序,取置信度最高的框作为“基准框”,删除所有与基准框IoU大于阈值(如0.5)的候选框;重复此过程,直到所有冗余框被过滤。
通过NMS,YOLO v1能从98个候选框中筛选出少量精准的边界框,得到最终检测结果。
五、YOLO v1的性能与优缺点
1. 性能表现(对比传统算法)
在VOC 2007数据集上,YOLO v1的mAP(平均精度均值)为63.4%,虽然低于Faster R-CNN(73.2%),但检测速度达到45 FPS(远快于Faster R-CNN的7 FPS),甚至能满足实时视频检测(24 FPS以上)的需求。
2. 优点
- 速度快:端到端单阶段检测,无候选框生成步骤,适合实时场景;
- 泛化能力强:对自然场景的小目标、遮挡目标有一定鲁棒性(相较于传统DPM算法);
- 结构简洁:基于CNN的统一架构,易于训练和部署。
3. 缺点
- 小目标检测精度低:每个网格仅预测2个边界框,且对小目标的位置误差敏感,容易漏检密集小目标;
- 边界框预测粗糙:仅依赖网格内的边界框回归,对长宽比特殊的目标(如细长物体)拟合效果差;
- 类别预测局限:每个网格仅预测1个类别,若网格内有多个不同类别的目标(如重叠目标),会导致类别误判。
六、总结:YOLO v1的意义与影响
YOLO v1虽然存在精度不足、小目标检测能力弱等问题,但它开创了“单阶段目标检测”的新范式,证明了“端到端回归”在目标检测任务中的可行性。其核心思想(网格划分、边界框回归、置信度设计)为后续YOLO系列(v2、v3、v5)及其他单阶段算法(如SSD、RetinaNet)提供了重要借鉴。
如果说R-CNN系列奠定了目标检测的深度学习基础,那么YOLO v1则开启了实时目标检测的新时代。对于刚接触目标检测的开发者,理解YOLO v1的设计思路,是掌握后续复杂算法的关键一步。