目录
- 一、知识蒸馏概述
- 二、知识蒸馏技术
- 1.知识蒸馏步骤
- 1.1训练教师模型
- 1.2生成软标签
- 1.3训练学生模型
- 2.关键技术方法
- 1.软标签和温度参数
- 2.损失函数设计
- 3.蒸馏层次分类
- 4.教师模型优化
- 5.知识蒸馏的变体
- 三、应用场景分析
一、知识蒸馏概述
1.核心概念
- 知识蒸馏(Knowledge Distillation, KD) 是一种模型压缩与优化技术,旨在将复杂高性能模型(教师模型,Teacher Model)的 “知识” 迁移到轻量模型(学生模型,Student Model)中,使学生模型在参数量和计算成本大幅降低的同时,尽可能保留教师模型的性能。 该技术由Hinton等人在2015年提出,广泛应用于模型压缩、迁移学习和模型加速等领域。
2.核心思想
- 教师模型:通常是复杂、参数量大的模型,具有较高的准确率,但计算成本高。
- 学生模型:结构更简单、参数更少的轻量模型,目标是模仿教师模型的行为。
- 核心目标:学生模型不仅学习真实标签(硬标签),还学习教师模型输出的概率分布(软标签),从而捕获教师模型学到的“暗知识”(如类别间的关系、不确定性的分布等)。
- 核心思想:教师模型不仅输出硬标签(Hard Label,如分类任务中的真实类别),还通过软标签(Soft Label,如输出层的概率分布)向学生传递更丰富的隐含知识,例如类别之间的相似性和决策边界。
3.发展历程
- 起源(2014-2015)
- 最早由 Hinton 等人在 2015 年的论文《Distilling the Knowledge in a Neural Network》中提出,首次证明通过软标签训练学生模型可提升性能。
- 核心创新:引入温度参数(Temperature, T)调整软标签的 “软化程度”,使教师模型的输出概率分布包含更多类别关联信息。
- 技术扩展(2016-2020)
- 分层蒸馏:从仅蒸馏输出层扩展到中间层特征(如卷积神经网络的特征图、Transformer 的注意力矩阵),例如 FitNet(2016)、DistilBERT(2019)。
- 多样化教师:使用多个教师模型(Ensemble)或异构教师(如不同架构的模型)提升知识多样性,如 Multi-Teacher KD。
- 自适应蒸馏:根据学生模型的学习进度动态调整蒸馏目标,减少冗余知识传递。
- 前沿方向(2021 至今)
- 跨模态蒸馏:在图像、文本、语音等不同模态间迁移知识,例如将视觉模型的知识迁移到语言模型。
- 无教师蒸馏:无需预训练教师模型,通过自蒸馏(Self-KD)或数据增强生成伪教师,降低对教师模型的依赖。
- 与其他技术结合:如对比学习、神经架构搜索(NAS),优化蒸馏效率。
二、知识蒸馏技术
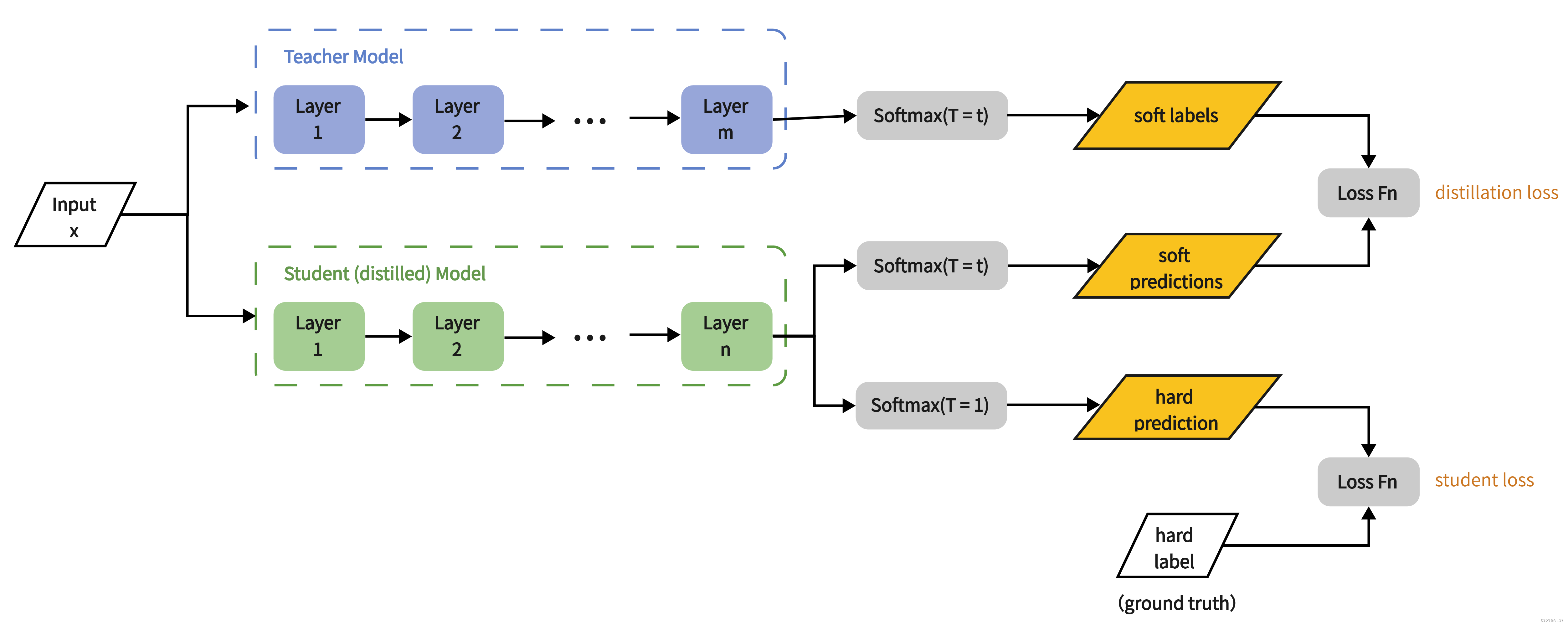
1.知识蒸馏步骤
1.1训练教师模型
- 教师模型在训练集上独立训练,直到收敛,获得高精度。
1.2生成软标签
- 教师模型对训练数据的预测结果(概率分布)称为“软标签”。
- 温度参数(Temperature, T):通过调节温度参数对输出概率分布进行平滑,公式如下:
qi=exp(zi/T)/∑jexp(zj/T)qi=exp(zi/T)/∑jexp(zj/T) qi=exp(zi/T)/∑jexp(zj/T) - T=1:标准 Softmax,软标签等于教师模型的原始输出。
- T>1:软标签更平滑,类别差异被弱化,传递更多类别相关性知识。
- T<1:软标签更尖锐,接近硬标签,蒸馏效果减弱。
1.3训练学生模型
- 学生模型同时学习:真实标签的交叉熵损失(硬标签)和模仿教师输出的KL散度损失(软标签)。
L=λ⋅Lhard+(1−λ)⋅LsoftL=λ⋅Lhard+(1−λ)⋅Lsoft L=λ⋅Lhard+(1−λ)⋅Lsoft - LhardLhard:学生预测与真实标签的交叉熵。
- LsoftLsoft:学生与教师输出的KL散度(带温度参数 TT)。
- λλ:平衡两种损失的权重系数(通常取较小值,如0.1)。
2.关键技术方法
1.软标签和温度参数
- 软标签(Soft Target):教师模型在最后一层输出的概率分布(如 Softmax 结果),反映类别之间的相对相似性。例如,输入一张 “猫” 的图片,教师模型可能对 “狗” 的概率输出为 10%,远高于随机猜测,这一信息可帮助学生模型理解两类的相似性。
- 温度参数T的作用
- 高温(T≫1)时,教师模型的输出概率更“软”,突出不同类别间的相对关系。
- 低温(T=1)时,恢复原始概率分布。
- 学生模型训练时使用相同的 T,推理时恢复 T=1。
2.损失函数设计
- 通常结合软标签损失和硬标签损失,公式为:L=α⋅Lsoft+(1−α)⋅Lhard
- 软标签损失(蒸馏损失):常用 KL 散度(Kullback-Leibler Divergence)衡量学生与教师软标签的差异
- 硬标签损失(监督损失):学生模型对真实标签的交叉熵损失
3.蒸馏层次分类
- 输出层蒸馏(Logits Distillation):直接迁移教师模型的 logits 或 Softmax 输出,简单高效,经典方法如 Hinton 原始蒸馏。
- 中间层蒸馏(Feature Distillation):迁移教师模型中间层的特征(如 CNN 的卷积激活值、Transformer 的隐藏层输出),保留高层语义信息,例如:
- FitNet:要求学生模型的中间层特征与教师模型的对应层特征匹配。
- Deep Mutual Learning:学生模型之间相互学习,无固定教师,属于自蒸馏变种。
- 关系蒸馏(Relational Distillation):迁移样本间的关系知识,如样本对的相似性、注意力矩阵的依赖关系,适用于图神经网络或结构化数据。
4.教师模型优化
- 教师模型选择:通常为高性能模型,或集成模型(提升知识多样性)。
- 知识提炼技巧:教师模型可先在大规模数据上预训练,再通过蒸馏将知识压缩到学生模型,例如 DistilBERT 基于 BERT 蒸馏,参数减少 40%,速度提升 60%,性能仅下降 3%。
5.知识蒸馏的变体
- 基于响应的蒸馏(Response-Based):学生直接模仿教师模型的最终输出(如分类概率),代表方法:Hinton的原始方法
- 基于特征的蒸馏(Feature-Based):学生模仿教师模型的中间层特征表示 ,代表方法:FitNets(通过“提示学习”对齐中间层特征)
- 基于关系的蒸馏(Relation-Based):学生模仿样本间的关系(如特征相似性、距离等), 代表方法:RKD(Relational Knowledge Distillation)
三、应用场景分析
1.典型应用场景
- 自然语言处理(NLP)
- 压缩预训练模型:如 DistilBERT、TinyBERT,解决 BERT 等模型推理速度慢的问题,适用于移动端部署。
- 跨任务蒸馏:将在大规模语料上训练的通用模型(如 GPT)的知识迁移到特定任务的轻量模型。
- 计算机视觉(CV)
- 轻量化图像分类模型:如 MobileNet 通过蒸馏提升精度,适用于手机、嵌入式设备。
- 目标检测与分割:蒸馏教师模型的定位和语义信息,平衡速度与精度。
- 语音识别与生成
- 降低语音模型的计算复杂度,满足实时交互需求(如智能音箱)。
- 资源受限场景
- 边缘计算、移动端设备(如手机、IoT 芯片),需在低算力、低功耗下运行模型。
2.优缺点分析
- 优点
- 模型轻量化:学生模型参数量和计算量显著减少,推理速度提升,部署成本降低。
- 性能保持:在不显著损失精度的前提下实现压缩,甚至可通过多教师蒸馏超越单一教师模型。
- 灵活性:适用于异构模型(如教师为 CNN,学生为 Transformer),支持跨架构知识迁移。
- 缺点
- 依赖教师模型:教师模型需足够强且训练良好,否则学生模型性能受限。
- 知识损失风险:软标签可能包含噪声,中间层特征匹配需精细设计,否则蒸馏效果不佳。
- 训练成本:需先训练教师模型,再训练学生模型,增加整体流程复杂度。