LLAVA-MINI论文阅读

2025.3
1.摘要
background
大型多模态模型(LMMs)虽然强大,但计算成本极高,严重阻碍了其实时交互应用。这个成本主要来自两方面:庞大的语言模型(LLM)参数和巨量的视觉Token。现有提升效率的工作大多集中于缩小LLM的尺寸,却忽略了另一个关键问题:单个图像通常被编码成数百个视觉token(例如LLaVA-v1.5使用576个),这在处理高分辨率图像或视频(多帧)时,会极大地增加LLM的上下文长度,导致推理延迟高、显存占用大。
innovation
本文的核心洞察源于一个根本性问题:LMM是如何理解视觉token的?通过对LLaVA架构的逐层分析,作者发现:
1.视觉信息融合主要发生在LLM的浅层: 在LLM的早期层,文本token会给予视觉token极高的注意力权重,主动从中“吸收”和“融合”视觉信息。
2.视觉token在深层的重要性急剧下降: 一旦信息融合完成,在LLM的后期层,注意力就主要集中在文本token之间,视觉token几乎被“忽略”。
基于这一核心洞察,论文提出了LLaVA-Mini,其创新点在于:
1.模态预融合 (Modality Pre-fusion): 既然融合只在浅层发生,那么完全可以将这个过程移到LLM外部提前进行。LLaVA-Mini设计了一个“预融合模块”,让文本token在进入LLM主干之前,就与所有的原始视觉token进行交互,提前完成信息融合。
2.极限视觉压缩: 由于视觉信息已被文本“吸收”,原始的几百个视觉token就变得冗余。因此,模型可以放心地使用一个“压缩模块”将它们极限压缩,最少只保留一个token送入LLM,同时不丢失关键视觉信息。
好处与对比: 相比于LLaVA-v1.5,LLaVA-Mini在性能相当的情况下,将视觉token从576个减少到1个,带来了巨大的效率提升:计算量(FLOPs)降低77%,推理延迟从113ms降至40ms,每张图片的显存占用从360MB降至0.6MB。与其他直接在视觉编码器层面进行token合并的方法(如MQT-LLaVA, PruMerge)相比,LLaVA-Mini由于创新的“预融合”步骤,性能损失小得多,压缩率也更高。
2. 方法 Method
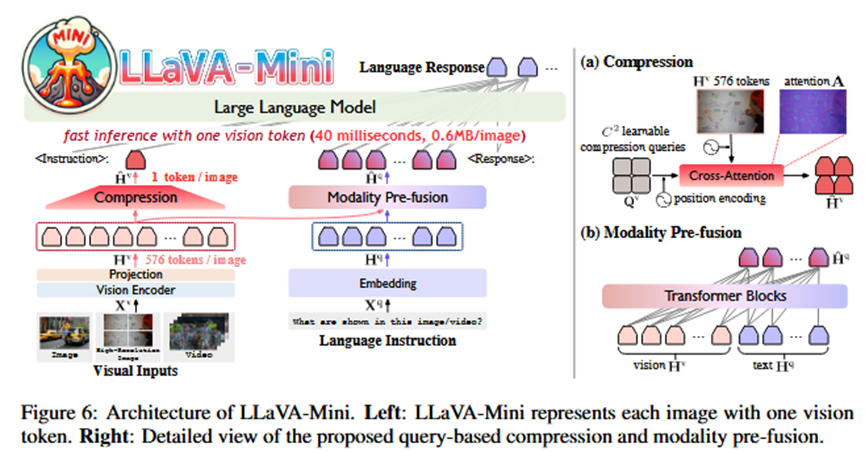
总体 Pipeline:
LLaVA-Mini的架构在标准LMM(视觉编码器->投影层->LLM)的基础上,在投影层和LLM之间插入了两个核心模块:视觉token压缩模块和模态预融合模块。
输入: 一张图片/视频帧 + 文本指令。
输出: 文本回答。
各部分详解:
1.视觉编码与投影 (同LLaVA):
输入: 图片 X^v。
过程: 使用CLIP ViT将图片编码成N x N个视觉token H^v(例如576个)。
2.模态预融合 (核心创新1):
输入: 原始的N x N个视觉token H^v 和 嵌入后的文本token H^q。
过程: 将 H^v 和 H^q 拼接后,送入一个由几个Transformer层构成的预融合模块。该模块结构与LLM层相同,使得文本token H^q 可以充分关注 H^v,将视觉信息融合进来。
输出: 携带了视觉信息的“融合文本token” Ĥ^q。
3.视觉token压缩 (核心创新2):
输入: 原始的N x N个视觉token H^v。
过程: 使用一个基于查询的压缩模块。该模块有C x C个可学习的查询向量(Queries),通过与H^v进行交叉注意力计算,将视觉信息“浓缩”到这些查询向量中。C可以设置得非常小,例如C=1。
输出: C x C个“压缩视觉token” Ĥ^v(例如1个)。
4.LLM主干推理:
输入: 将“压缩视觉token” Ĥ^v 和 “融合文本token” Ĥ^q 拼接。
过程: 将这个极短的token序列送入LLM主干进行处理。
输出: 最终的文本回答。
5.对高分辨率和视频的扩展:
高分辨率图像: 将大图切分为4个子图,分别提取特征后进行压缩和预融合。
视频: 逐帧处理,每帧都只用1个视觉token表示,然后将这些单token序列输入LLM,极大地节省了处理长视频的成本。
3. 实验 Experimental Results
数据集:
图像任务: 在11个主流图像基准上进行评测,包括 VQAv2, GQA, MMBench, SEED-Bench等。
视频任务: 在7个视频基准上进行评测,包括 MSVD-QA, MSRVTT-QA, ActivityNet-QA, MVBench, MLVU等。
实验结论:
1.性能与效率双赢 (Table 1, Figure 1): 在图像任务上,LLaVA-Mini仅用1个视觉token,其综合性能便与使用576个token的LLaVA-v1.5相当,同时计算量和延迟大幅降低。
2.视频理解能力强大 (Table 2, 3, 4): 由于每帧仅需1个token,LLaVA-Mini可以高效处理更多视频帧(例如1fps),相比于那些因token数量限制而只能稀疏采样几帧的模型(如Video-LLaVA),它能更好地理解视频的时序和内容,在多个视频基准上取得SOTA性能,甚至能处理长达数小时的视频。
3.预融合模块的优越性 (Table 6): 消融实验证明,预融合模块是成功的关键。在没有预融合的情况下,即使保留144个视觉token,模型的性能也远不如LLaVA-v1.5。这证明了“先融合,再压缩”的策略远优于直接压缩。
4.计算开销分析 (Table 14, Figure 9): 分析表明,新增的压缩和预融合模块计算开销极小,而LLM主干的计算量因输入token大幅减少而急剧下降,这是模型高效的根本原因。其显存效率高到可以在一块24GB的RTX 3090上处理超过1万帧的视频。
4. 总结 Conclusion
本文的核心信息是,LMM的效率瓶颈不仅在于模型大小,更在于输入token的数量。通过洞察到视觉信息融合主要发生在LLM的浅层这一机制,我们可以将融合过程解耦并前置,从而实现对视觉token的极限压缩,用单个视觉token即可达到与数百个token相当的性能,最终打造出兼具高性能和高效率的实时多模态模型。