PostgreSQL 18 异步 I/O(AIO)调优指南
导语:PostgreSQL 18 中最大的变化是引入了异步 I/O (AIO) 子系统,这引出了一个问题:如何根据工作负载调整它?Tomas Vondra 这篇博客提供了如何设置 AIO 配置,并根据你的工作负载进行测试的实用指南。
PostgreSQL 18 已正式发布,该版本包含大量改进。其中一项重大架构变更是异步 I/O(Asynchronous I/O,简称 AIO) ——它支持对 I/O 操作进行异步调度,使数据库能更好地控制存储资源,同时提升存储利用率。
本文不会详细解释 AIO 的工作原理,也不会展示详尽的基准测试结果。本文的核心目标是分享 PostgreSQL 18 中 AIO 的调优建议,并解释其中一些固有的但却不显而易见的权衡关系与限制。
理想情况下,这些调优建议应被纳入官方文档,但这需要基于实践经验形成明确共识——而 AIO 作为全新特性,目前尚缺乏足够的生产环境验证数据。尽管在开发阶段我们已开展了大量基准测试,并据此设定了默认参数,但这无法替代实际生产系统的运行经验。因此,本文将基于个人经验,探讨如何(可能)调整默认参数,以及在此过程中需权衡的因素。
io_method / io_workers
有一系列与 AIO(或广义上的 I/O)相关的参数。但您可能只需要关注 Postgres 18 中引入的这两个:
- io_method = worker (options: sync, io_uring)
- io_workers = 3
其他参数(如 io_combine_limit)都有合理的默认值。对于如何调整它们,我没有太好的建议,所以暂时保持默认即可。在本文中,我将重点讨论这两个重要的参数。
io_method
io_method 决定了 AIO 实际处理请求的方式——由哪个进程执行 I/O,以及 I/O 是如何被调度的。它有三个可能的值:
sync- 这是一个"向后兼容"选项,在支持的情况下使用posix_fadvice进行同步 I/O。这会将数据预取到页面缓存中,而不是共享缓冲区里。worker- 创建一个"I/O 工作进程"池来执行实际的 I/O。当一个后端进程需要从数据文件中读取一个块时,它会将一个请求插入到共享内存中的队列里。一个 I/O 工作进程被唤醒,执行pread操作,将数据放入共享缓冲区,并通知后端进程。io_uring- 每个后端进程都有一个io_uring实例(一对队列)并使用它来执行 I/O。与worker的不同之处在于,它不是直接执行pread,而是通过io_uring提交请求。
默认值是 io_method = worker。我们确实考虑过将 sync 或 io_uring 都设为默认值,但我认为 worker 是正确的选择。它是真正"异步"的,并且随处可用(因为这是我们自己的实现)。
sync 曾被视为一种"回退"选择,以防我们在 beta/RC 阶段遇到问题。但我们并没有遇到问题,而且也不确定使用 sync 是否真的会有帮助,因为它仍然要经过 AIO 基础设施。如果您希望模拟旧版本的行为,仍然可以使用 sync。
io_uring 是一种流行的异步 I/O 方式(不仅仅是磁盘 I/O)。它非常出色,高效且轻量级。但它是 Linux 特有的,而我们需要支持众多平台。我们本可以使用特定于平台的默认值(类似于 wal_sync_method),但这似乎带来了不必要的复杂性。
注意: 即使在 Linux 上,也很难验证
io_uring。一些容器运行时(例如 containerd)之前因为安全风险而禁用了io_uring支持。
没有任何一个 io_method 选项是"普遍最优的"。总会存在某些工作负载下 A 优于 B,反之亦然。最终,我们希望大多数系统都能使用 AIO 并从中受益,同时我们希望保持简单,所以选择了 worker。
💡建议: 我的建议是坚持使用 io_method = worker,并调整 io_workers 的值(如下一节所述)。
io_workers
Postgres 的默认配置非常保守。它甚至可以在像树莓派这样的小型机器上启动。但另一方面,对于通常拥有更多 RAM/CPU 的典型数据库服务器来说,这种保守配置的表现就很糟糕了。要在这样的大型机器上获得良好的性能,您需要调整一些参数(shared_buffers, max_wal_size 等)。
我希望我们能有一种自动化方法来为这些基本参数选择"合适"的初始值,但这比看起来要困难得多。这在很大程度上取决于上下文(例如,同一系统上可能还在运行其他东西)。不过,至少现在有像 PGTune 这样的工具,能为这些参数提供合理的推荐值。
这当然也适用于 io_workers = 3 这个默认值,它只创建 3 个 I/O 工作进程。对于拥有 8 个核心的小型机器来说,这可能没问题,但对于 128 个核心的机器来说,这绝对是不够的。
实际上,我可以通过一个基准测试的结果来证明这一点,这个测试是我为选择 io_method 默认值而进行的。该基准测试生成了一个合成数据集,然后运行匹配部分数据的查询(同时强制使用特定的扫描类型)。
注意: 该基准测试(连同脚本、大量结果和更详细的解释)最初在关于
io_method默认值的 pgsql-hackers 邮件列表线程中分享。请查看该线程以获取更多细节和其他人的反馈。展示的结果来自一台搭载 Ryzen 9900X(12 核/24 线程)和 4 块 NVMe SSD(配置为 RAID0)的小型工作站。
以下是对比不同 io_method 选项查询耗时的图表 PDF 文件:
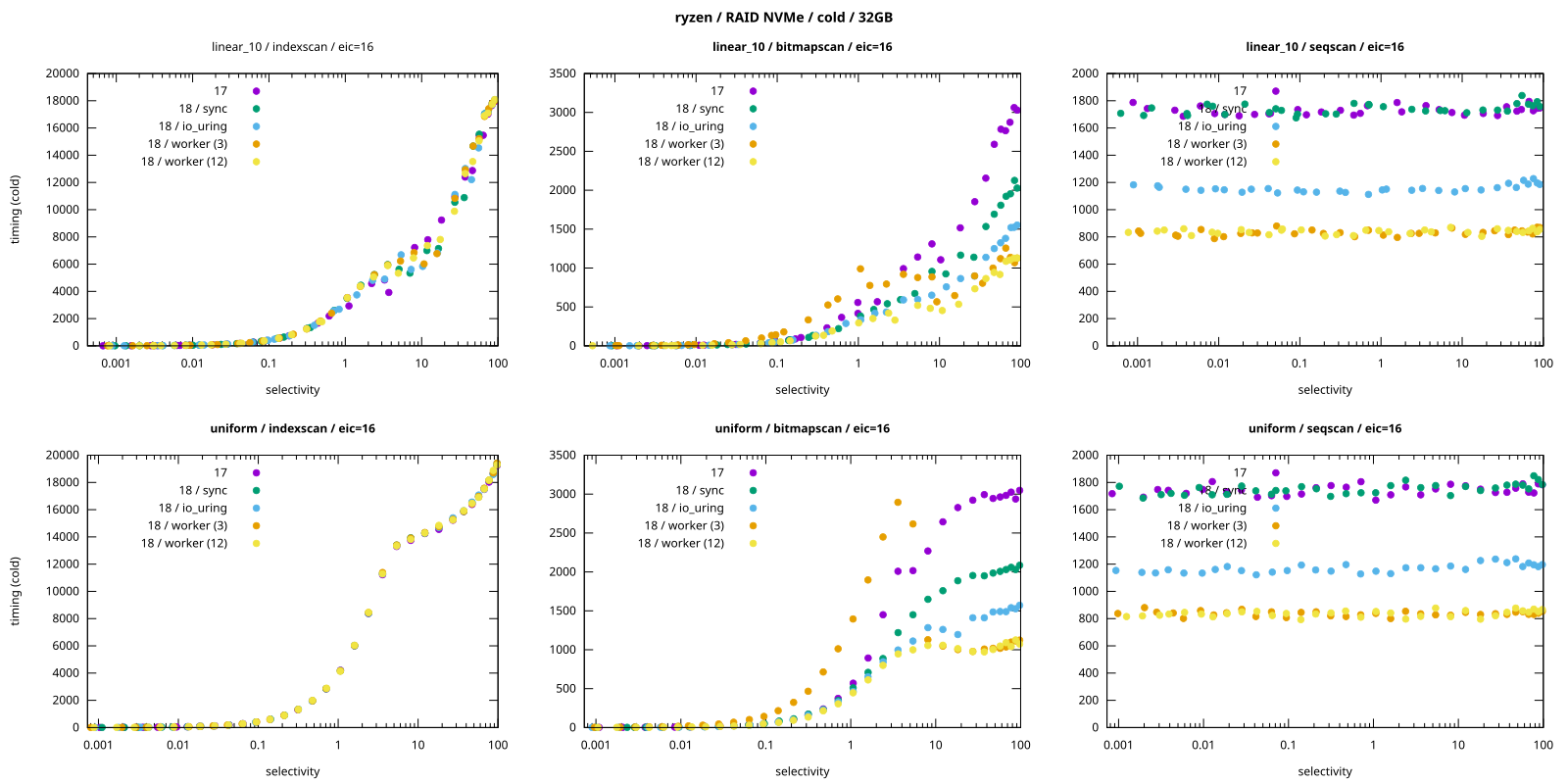
每种颜色代表不同的 io_method 值(17 代表 “Postgres 17”)。对于 “worker” 有两种数据序列,对应不同数量的工作进程(3 和 12)。这是针对两个数据集的:
uniform- 均匀分布(因此 I/O 完全是随机的)linear_10- 顺序分布带有一点随机性(不完美的相关性)
图表显示了一些非常有趣的现象:
- 索引扫描 :
io_method没有影响,这很好理解,因为索引扫描尚未使用 AIO(所有 I/O 都是同步的)。 - 位图扫描 : 行为更加混乱。
worker方法表现最好,但仅限于有 12 个工作进程时。使用默认的 3 个工作进程时,对于低选择性的查询,它的性能实际上很差。 - 顺序扫描 : 不同方法之间存在明显差异。
worker是最快的,比sync(和 PG17)快大约一倍。io_uring介于两者之间。
在纵轴(y 轴)采用对数刻度的图表中 PDF 文件,使用 3 个 I/O 工作进程(io_workers=3)的 worker 模式在 bitmap 扫描(位图扫描)场景下的性能劣势更为明显:
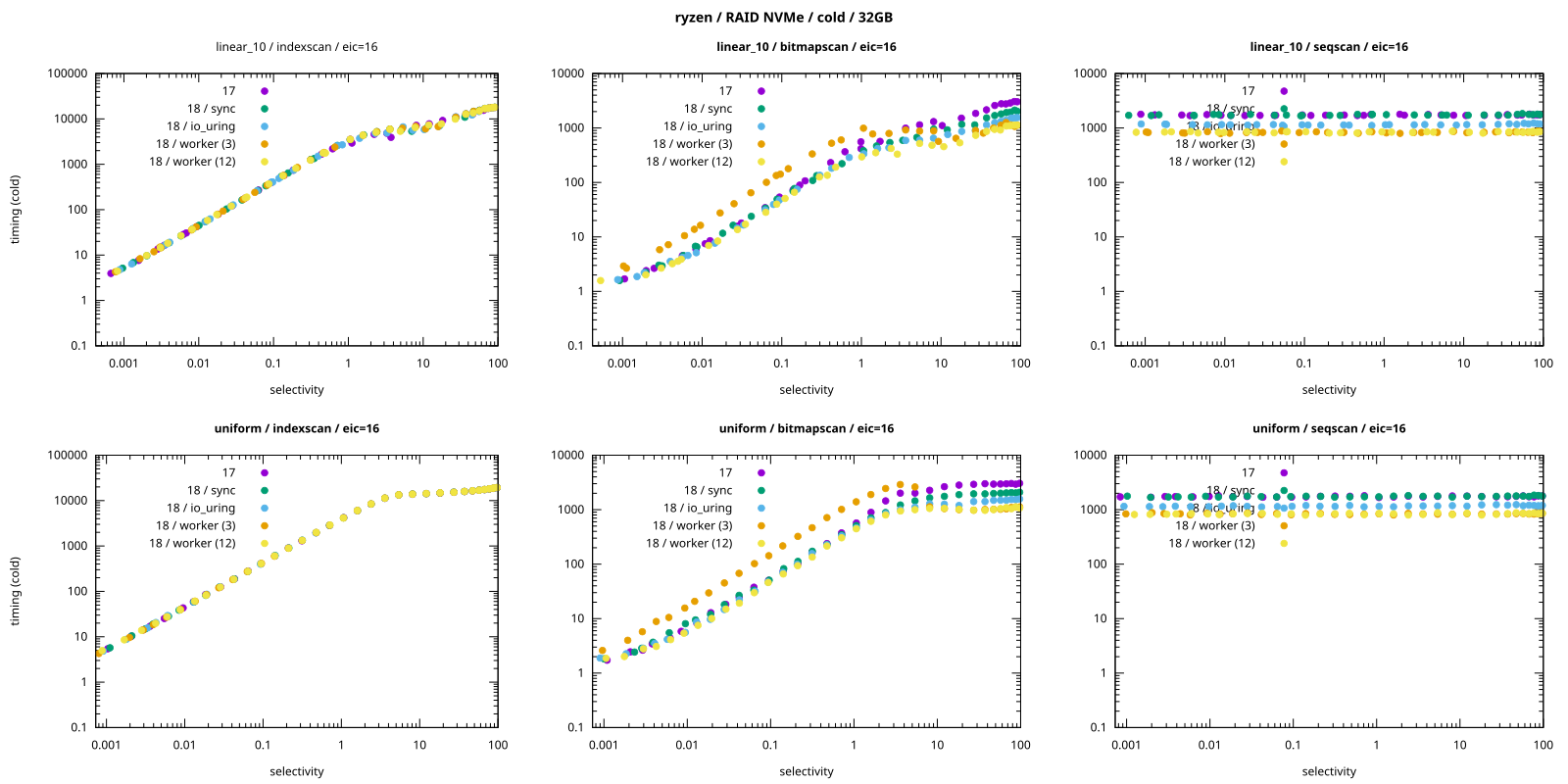
io_workers=3 的配置始终是最慢的(在线性图表中几乎难以察觉这一点)。
好的一面是,虽然 I/O 工作进程不是免费的,但它们的开销也不算高。因此,即便工作进程数量偏多,通常也比数量不足要好。
未来,我们可能会根据需求启动/停止工作进程,使其变得"自适应"。这样我们就能始终保持最优的进程数量。目前甚至已经有一个进行中的补丁,但它未能纳入 Postgres 18。
建议: 考虑增加 io_workers。目前尚无理想的推荐值或计算公式,或许设置为核心数的 1/4 是个可行的选择?
权衡
放之四海而皆准的最优配置是不存在的。我曾见过"使用 io_uring 以获得最高效率"的建议,但前面的基准测试清楚地表明,对于顺序扫描,io_uring 明显比 worker 慢。
别误会,我本身认可 io_uring,它确实是一个出色的接口,而且上述建议也并非"错误"。任何性能调优建议本质上都是一种简化表达,总会存在与之相悖的情况。现实世界从不像建议描述的那样简单:这类建议的核心意义,就在于用一条简洁的规则,掩盖背后繁杂的复杂细节。
那么,这些异步 I/O(AIO)方式之间,究竟存在哪些权衡与差异呢?
带宽
io_uring 和 worker 之间的一个重大区别在于任务的执行位置。对于 io_uring,所有任务都在后端进程内部执行;而对于 worker,这些任务会在独立的进程中进行。
这可能会对带宽产生一些值得关注的影响,具体取决于处理 I/O 的开销大小。而这个开销可能相当高,因为它涉及:
- 实际的 I/O 操作
- 校验和验证(在 Postgres 18 中默认启用)
- 将数据复制到共享缓冲区
对于 io_uring,所有这些都发生在后端进程本身。I/O 部分可能更高效,但校验和验证与内存复制(memcpy)这两个步骤却可能成为性能瓶颈。对于 worker,这项工作实际上在工作进程之间分配。如果您有 1 个后端进程和 3 个工作进程,限制就提高了 3 倍。
当然,反之亦然。如果有 16 个连接,那么对于 io_uring,就是 16 个进程可以验证校验和等等。对于 worker,限制就是 io_workers 设置的值。
这就是我建议将 io_workers 设置为核心数约 25% 的原因。我认为还可以设得更高,可能达到每个核心一个 I/O 工作进程。无论如何,3 看起来明显太低了。
注意: 我相信这种将开销分散到多个进程的能力,是
worker在顺序扫描上优于io_uring的原因。在本次基准测试中,约 20% 的差异对于校验和内存复制来说似乎是合理的。
信号
另一个重要的细节是后端进程与 I/O 工作进程之间进程间通信的开销,这是基于 UNIX 信号的。一次 I/O 操作的执行流程如下:
- 后端进程将一个读取请求添加到共享内存的队列中
- 后端进程向一个 I/O 工作进程发送信号,将其唤醒
- I/O 工作进程执行后端请求的 I/O,并将数据复制到共享缓冲区
- I/O 工作进程向后端进程发送信号,通知其 I/O 已完成
在最坏情况下,这意味着每处理一个 8KB 大小的数据块,就需要完成一次 “双向信号传输”(共 2 次信号交互)。问题在于,信号传输并非 “零成本”—— 一个进程每秒能处理的信号数量是有限的。
我写了一个简单的基准测试,用于测试两个进程之间的信号传递性能。在我的机器上,测试结果显示能达到每秒 25 万至 50 万次往返通信。如果每个 8KB 的数据块都需要一次往返通信,这意味着传输速度仅为 2-4GB/s。这并不算快,尤其是考虑到数据可能已经在页面缓存中,而不仅仅是从存储中读取的冷数据。根据一项从页缓存复制数据的测试,一个进程可以达到 10-20GB/s 的速度,大约是信号传递方式的 4 倍。显然,信号可能会成为一个性能瓶颈。
注意: 具体的限制因硬件而异,在老旧的机器上可能会低得多。但在我能访问的所有机器上,这个普遍观察结果都成立。
不过好消息是,这只会影响"最坏情况"的工作负载,即需要逐个读取 8KB 页面。大多数常规工作负载并非如此。后端进程通常会在共享内存中找到很多缓冲区(因此不需要 I/O)。或者,由于预读,I/O 以更大的块发生,这将信号开销分摊到了多个数据块上。因此,我不认为这会成为一个严重的问题。
在关于索引预取的邮件列表线程中,有关于 AIO 开销(不仅仅是由于信号)的更长时间讨论。
关于异步 I/O(AIO)的开销(不仅限于信号带来的开销),在 “索引预取”的邮件列表线程中还有更深入的探讨。
文件限制
io_uring 无需任何进程间通信(IPC),因此它不受信号开销或类似问题的影响。但 io_uring 同样存在限制,只是限制点有所不同。
例如,每个进程都会受到 “进程级带宽限制”(比如单个进程最多能执行多少内存复制操作)。但根据页面缓存测试判断,这些限制相当高——大约 10-20GB/s。
另一个需要考虑的问题是,io_uring 可能需要相当多的文件描述符。正如这个 pgsql-hackers 线程中所解释的:
问题在于,使用
io_uring时,我们需要为每个可能的子进程创建一个文件描述符(FD),以便一个后端进程可以等待由另一个后端进程发起的 I/O 完成。这些io_uring实例需要在主进程中创建,以便所有后端进程都能访问。显然,如果max_connections设置得较高,这有助于更快地达到未调整的软性RLIMIT_NOFILE限制。
因此,如果您决定使用 io_uring,您可能也需要调整 ulimit -n。
注意: 这并非 Postgres 代码中您可能遇到文件描述符限制的唯一地方。大约一年前,我提了一个与文件描述符缓存相关的补丁构想。每个后端进程最多保持
max_files_per_process个打开的文件描述符,默认情况下该 GUC 设置为 1000。这在过去是足够的,但在使用分区(或按租户的模式)的情况下,很容易触发大量频繁且开销较高的打开/关闭调用。那是一个独立但类似的问题。
总结
AIO 是 PostgreSQL 18 的一项重大架构变更,但目前仍存在局限性:仅支持读操作,部分操作仍依赖旧的同步 I/O 机制。这些限制并非永久性的,预计将在未来版本中逐步解决。
基于本文的分析,最终的 AIO 调优建议如下:
- 保留
io_method = worker的默认值:除非通过基准测试证明io_uring对您的工作负载更优,否则不建议切换。仅在需要模拟 PostgreSQL 17 行为时使用sync(即使这可能导致部分场景性能下降)。 - 根据 CPU 核心数调整
io_workers:建议从核心数的 25% 开始配置,在 I/O 密集场景下可尝试提高至 100%。
若您在调优过程中发现有趣的结论,欢迎将其反馈给作者,更推荐发布到 pgsql-hackers 邮件列表。这些经验将帮助官方完善未来文档中的调优建议。
原文链接:https://vondra.me/posts/tuning-aio-in-postgresql-18/