软件的基础原理
00 开篇词 掌握软件开发技术的第一性原理
计算机软件开发是一个日新月异的领域,几乎每天都有新的技术诞生。每隔几年,软件开发领域就会进行一次大的技术潮流变换,所以身处其中的软件开发技术人员也常常疲于奔命,不断学习各种新知识、新技术,生怕被这个快速变革的时代所抛弃。
但是每次从头开始学习一个新的技术,这个过程既痛苦又漫长,好不容易掌握得差不多了,新的技术又出现了,于是不断重复从入门到放弃这一过程。这个过程是如此痛苦、艰难,以至于整个行业形成了一种所谓的“共识”:随着学习能力和体力精力的下降,编程知识和技能逐渐衰退,35岁以后就不能写代码了。
其实很多看起来难以坚持、让人容易放弃的事情,并不是智力、体力或者意志力的问题,更多的是方法问题。很多时候,学习新知识和新技术之所以困难,是因为没有理解这些新技术背后的思想和原理,以及这些新技术诞生的来源。太阳底下没有新鲜事,绝大多数新技术其实都脱胎于一些既有的技术体系。
如果你能建立起这套技术思维体系,掌握这套技术体系背后的原理,那么当你接触一个新技术的时候,就可以快速把握住这个新技术的本质特征和思路方法,然后用你的技术思维体系快速推导出这个新技术是如何实现的。这个时候你其实不需要去学习这个新技术了,而是去验证这个新技术,你会去看它的文档和代码,去验证它是不是和你推导、猜测的实现方式一致,而不是去学习它怎么用了。那么,学习一个新技术就变成了一个简单、轻松、快速且充满乐趣的过程了。你不再惧怕学习新技术,而是开始抱怨:为什么技术革新得这么慢,太无聊了。你甚至可以开始自己创造新技术。
第一性原理——建立技术体系的起点
那么如何实现这一美好的愿景,建立自己的技术思维体系呢?
物理学有一个第一性原理, 指的是根据一些最基本的物理学常量,从头进行物理学的推导,进而得到整个物理学体系。有硅谷钢铁侠之称的埃隆·马斯克特别推崇第一性原理,他做电动汽车、做航空火箭,并没有去遵从别人的老路,而是从这个产品最本质的需求和实现原理出发,重新设计了产品最核心的关键以及发展路径,进而开发出自己独特创新的产品。Google的创始人拉里·佩奇说过:“让我自由地从物理规则出发去思考问题,而不是迎合那些所谓的世俗智慧。”其实也是第一性原理。
第一性原理就是让我们抓住事物最本质的特征原理,依据事物本身的规律,去推导、分析、演绎事物的各种变化规律,进而洞悉事物在各种具体场景下的表现形式,而不是追随事物的表面现象,生搬硬套各种所谓的规矩、经验和技巧,以至于在各种纷繁复杂的冲突和纠结中迷失了方向。
软件开发技术也是非常庞杂的,各种基础技术,各种编程语言,各种工具框架,各种设计模式,各种架构方法,很容易让人觉得无所适从。就算下定决心要从基础学起,上来一本厚厚的《操作系统原理》,好不容易咬牙坚持学完,回头一看,还是各种迷茫,不知道在讲什么。继续学下去,再来一套更厚的《TCP/IP详解》,彻底耗尽了意志力和兴趣,完全放弃。
其实,我们不需要一开始就精通操作系统进程调度的各种算法,也不需要上来就掌握TCP/IP协议里的各种帧格式。我们应该从软件技术的第一性原理出发,了解每个基础技术方向那些最关键的技术原理,明白这些原理是如何和我们日常开发工作发生关系的。
比如我们的程序是如何被操作系统调度执行的?为什么高并发的时候系统会崩溃,原理是什么?在编程时,什么场合下应该使用链表,什么场合下应该使用数组,为什么?当我们使用Hash表的时候,什么情况下它的性能会急剧降低,原理又是什么?我们用Redis这样的分布式缓存的时候,到底要解决什么问题?分布式缓存是如何工作的?还有哪些技术看起来和Redis毫不相干,其实工作原理是一样的?
如果我们能把这些基本问题都回答清楚了,那么这些问题背后的核心技术原理也都理解了,我们就开始建立起自己的技术思维体系了。当有新的问题和技术出现,你就可以思考,这是属于哪个技术领域的?它的核心原理和哪个技术方案本质是一样的?
如果你掌握了软件开发技术的第一性原理,那么当你为了解决某个新问题,去学习和研究一个新技术的时候,就算遇到了知识的盲点,也可以快速定位到自己技术体系的具体位置,进一步阅读相关的书籍资料,这个时候也许你就会深入到操作系统的调度算法实现或者通信协议头信息的具体编码里,但是这时,你不会觉得枯燥无聊,也不会觉得迷茫无措,只会觉得原来如此,太有意思了,甚至觉得这其实可以实现得更好。
专栏如何帮你建立技术体系
我想从软件技术的第一性原理出发,写一写软件技术那些最基本的知识原理和知识体系。在这个专栏中,我对自己过去二十年软件编程生涯和业界的技术发展历史进行回顾总结,将软件知识技术体系分成软件的基础原理、软件的设计原理、架构的核心原理三个部分。
软件的基础原理主要是操作系统、数据结构、数据库原理等等,我会从一个常见的问题入手,直达这些基础技术最本质的原理,并覆盖这些基础技术的主要关键技术点,让你理解这些基础技术原理和你日常开发工作的关联关系,对这些基础技术有一个全新的认知。
在软件的设计原理里,我会讲述如何设计一个强大灵活,易复用,易维护的软件。在这个过程中,应该依赖哪些工具和方法,遵循哪些原则和思想,使用哪些模式和手段。如果软件只是实现功能,那么程序员就没有高下之分,软件也没有好坏之分,技术也就不会有进步。好的软件究竟好在哪里?如何自己也写出一个好的程序?我将在这个模块一一道来。
架构的核心原理围绕目前主要的互联网分布式架构以及大数据物联网架构进行剖析,分析这些架构背后的原理,它们都遵循了怎样的驱动力和设计思想,有哪些看似不同的技术其实原理是一样的,以及如何通过这些技术实现系统的高可用和高性能。
软件开发是一个实践性很强的活动,如果你只是学习技术,那么就是在纸上谈兵。只有将知识技能应用到工作实践中,才能真正体会到技术的关键点在哪里,才能分辨出哪些技术是真正有用的,哪些方法是花拳绣腿。但是公司不是你实践技术的实验室,怎样才能处理好工作中的各种关系,得到充分的授权和信任,在工作中实践自己的技术思想,并为公司创造更多价值,得到更多的晋升和发挥的空间,使自己的技术成长和职业发展进入互相促进的正向通道?我将会在第四模块,技术人的思维修炼和你分享一些这方面的方法和认知。
我在学习几何的时候,开始常常困扰于各种定理、推论,我觉得它们都很相似,以至于进行几何证明的时候,不知道该用哪个。后来我索性不去管这些定理和推论,而是直接从公理开始证明,虽然证明步骤长了一点,但是总归能证明出来。后来做的题多了,发现有些中间推导结果总是重复出现,打开书再学习,发现这些重复出现的中间结果就是各种定理、推论。这个时候我不去记这些定理,也能随心所欲去用它们了。
其实我学几何的这种方式就是第一性原理。第一性原理是一种思维方式,一种学习方式,一种围绕事物核心推动事物正确前进的做事方式。也许这个专栏讲到的很多知识技术你已经掌握,但是这些知识技术和软件技术最基本的原理的关系你也许不甚了解。它们从何而来,又将如何构建出新的技术?如果把这些关系和原理都理解透彻了,你会发现,日常开发用到的各种技术,你不但可以随心所欲地去使用,甚至可以重新创造。
如果说具体的技术是一朵花,那么技术思维体系就是一棵树,希望你跟随我的专栏,种下自己的技术思维体系之树,收获一树繁花。
在学习的路上,你有哪些建议或者心得体会呢?
01 程序运行原理:程序是如何运行又是如何崩溃的?
软件的核心载体是程序代码,软件开发的主要工作产出也是代码,但是代码被存储在磁盘上本身没有任何价值,软件要想实现价值,代码就必须运行起来。那么代码是如何运行的?在运行中可能会出现什么问题呢?
程序是如何运行起来的
软件被开发出来,是文本格式的代码,这些代码通常不能直接运行,需要使用编译器编译成操作系统或者虚拟机可以运行的代码,即可执行代码,它们都被存储在文件系统中。不管是文本格式的代码还是可执行的代码,都被称为程序,程序是静态的,安静地呆在磁盘上,什么也干不了。要想让程序处理数据,完成计算任务,必须把程序从外部设备加载到内存中,并在操作系统的管理调度下交给CPU去执行,去运行起来,才能真正发挥软件的作用,程序运行起来以后,被称作进程。
进程除了包含可执行的程序代码,还包括进程在运行期使用的内存堆空间、栈空间、供操作系统管理用的数据结构。如下图所示:
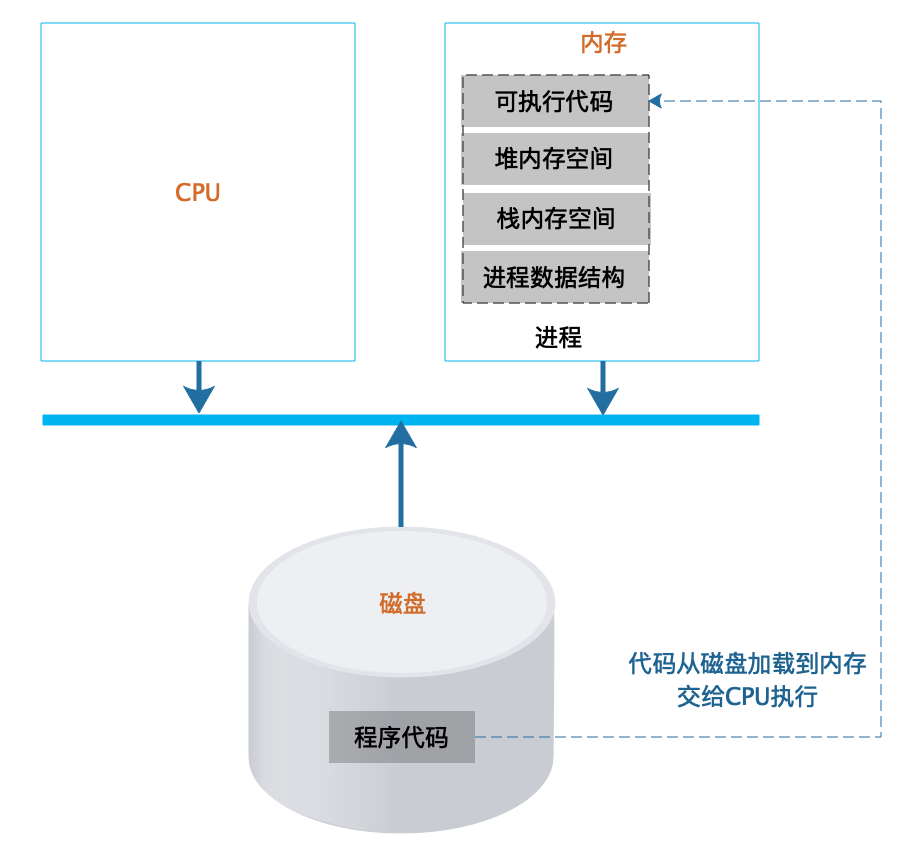 操作系统把可执行代码加载到内存中,生成相应的数据结构和内存空间后,就从可执行代码的起始位置读取指令交给CPU顺序执行。指令执行过程中,可能会遇到一条跳转指令,即CPU要执行的下一条指令不是内存中可执行代码顺序的下一条指令。编程中使用的循环for…,while…和if…else…最后都被编译成跳转指令。
操作系统把可执行代码加载到内存中,生成相应的数据结构和内存空间后,就从可执行代码的起始位置读取指令交给CPU顺序执行。指令执行过程中,可能会遇到一条跳转指令,即CPU要执行的下一条指令不是内存中可执行代码顺序的下一条指令。编程中使用的循环for…,while…和if…else…最后都被编译成跳转指令。
程序运行时如果需要创建数组等数据结构,操作系统就会在进程的堆空间申请一块相应的内存空间,并把这块内存的首地址信息记录在进程的栈中。堆是一块无序的内存空间,任何时候进程需要申请内存,都会从堆空间中分配,分配到的内存地址则记录在栈中。
栈是严格的一个后进先出的数据结构,同样由操作系统维护,主要用来记录函数内部的局部变量、堆空间分配的内存空间地址等。
我们以如下代码示例,描述函数调用过程中,栈的操作过程:
void f() {int x = g(1);x++; //g函数返回,当前堆栈顶部为f函数栈帧,在当前栈帧继续执行f函数的代码。
}int g(int x){return x + 1;
}
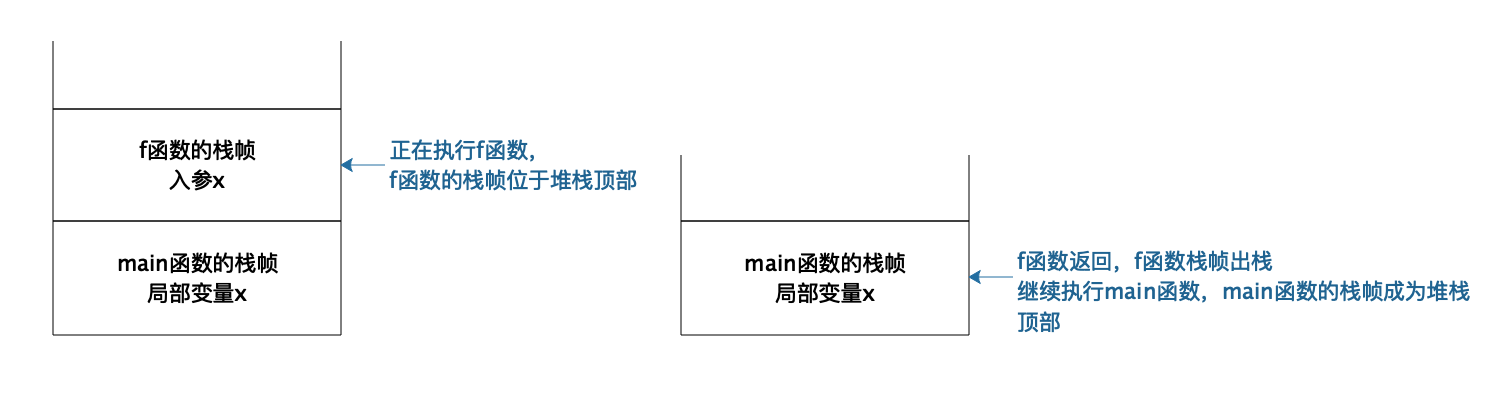
每次函数调用,操作系统都会在栈中创建一个栈帧(stack frame)。正在执行的函数参数、局部变量、申请的内存地址等都在当前栈帧中,也就是堆栈的顶部栈帧中。如下图所示:
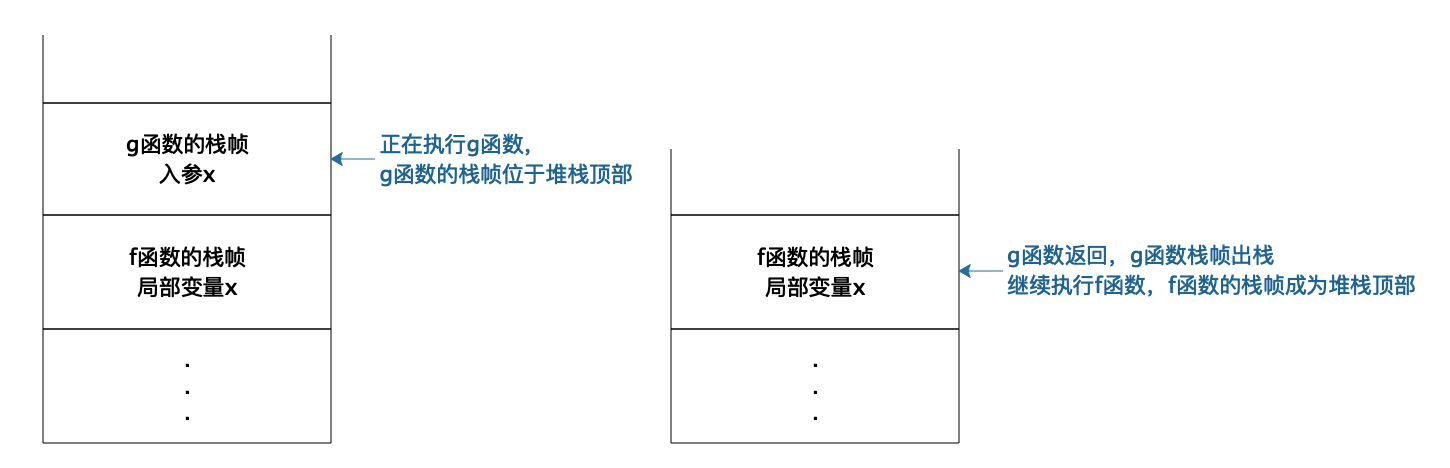
当f函数执行的时候,f函数就在栈顶,栈帧中存储着f函数的局部变量,输入参数等等。当f函数调用g函数,当前执行函数就变成g函数,操作系统会为g函数创建一个栈帧并放置在栈顶。当函数g()调用结束,程序返回f函数,g函数对应的栈帧出栈,顶部栈帧变又为f函数,继续执行f函数的代码,也就是说,真正执行的函数永远都在栈顶。而且因为栈帧是隔离的,所以不同函数可以定义相同的变量而不会发生混乱。
一台计算机如何同时处理数以百计的任务
我们自己日常使用的PC计算机通常只是一核或者两核的CPU,我们部署应用程序的服务器虽然有更多的CPU核心,通常也不过几核或者几十核。但是我们的PC计算机可以同时编程、听音乐,而且还能执行下载任务,而服务器则可以同时处理数以百计甚至数以千计的并发用户请求。
那么为什么一台计算机服务器可以同时处理数以百计,以千计的计算任务呢?这里主要依靠的是操作系统的CPU分时共享技术。如果同时有很多个进程在执行,操作系统会将CPU的执行时间分成很多份,进程按照某种策略轮流在CPU上运行。由于现代CPU的计算能力非常强大,虽然每个进程都只被执行了很短一个时间,但是在外部看来却好像是所有的进程都在同时执行,每个进程似乎都独占一个CPU执行。
所以虽然从外部看起来,多个进程在同时运行,但是在实际物理上,进程并不总是在CPU上运行的,一方面进程共享CPU,所以需要等待CPU运行,另一方面,进程在执行I/O操作的时候,也不需要CPU运行。进程在生命周期中,主要有三种状态,运行、就绪、阻塞。
- 运行:当一个进程在CPU上运行时,则称该进程处于运行状态。处于运行状态的进程的数目小于等于CPU的数目。
- 就绪:当一个进程获得了除CPU以外的一切所需资源,只要得到CPU即可运行,则称此进程处于就绪状态,就绪状态有时候也被称为等待运行状态。
- 阻塞:也称为等待或睡眠状态,当一个进程正在等待某一事件发生(例如等待I/O完成,等待锁……)而暂时停止运行,这时即使把CPU分配给进程也无法运行,故称该进程处于阻塞状态。
不同进程轮流在CPU上执行,每次都要进行进程间CPU切换,代价是非常大的,实际上,每个用户请求对应的不是一个进程,而是一个线程。线程可以理解为轻量级的进程,在进程内创建,拥有自己的线程栈,在CPU上进行线程切换的代价也更小。线程在运行时,和进程一样,也有三种主要状态,从逻辑上看,进程的主要概念都可以套用到线程上。我们在进行服务器应用开发的时候,通常都是多线程开发,理解线程对我们设计、开发软件更有价值。
系统为什么会变慢,为什么会崩溃
现在的服务器软件系统主要使用多线程技术实现多任务处理,完成对很多用户的并发请求处理。也就是我们开发的应用程序通常以一个进程的方式在操作系统中启动,然后在进程中创建很多线程,每个线程处理一个用户请求。
以Java的web开发为例,似乎我们编程的时候通常并不需要自己创建和启动线程,那么我们的程序是如何被多线程并发执行,同时处理多个用户请求的呢?实际中,启动多线程,为每个用户请求分配一个处理线程的工作是在web容器中完成的,比如常用的Tomcat容器。
如下图所示:
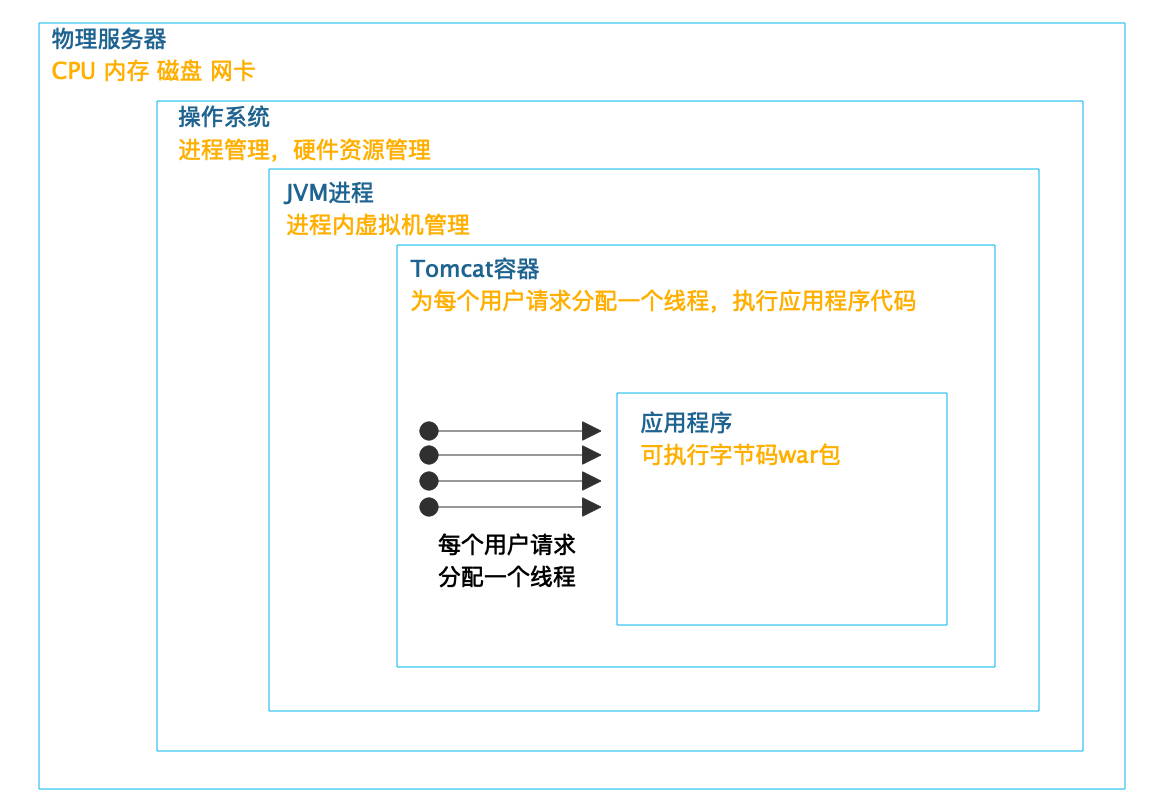 Tomcat启动多个线程,为每个用户请求分配一个线程,调用和请求URL路径相对应的Servlet(或者Controller)代码,完成用户请求处理。而Tomcat则在JVM虚拟机进程中,JVM虚拟机则被操作系统当做一个独立进程管理。真正完成最终计算的,是CPU、内存等服务器硬件,操作系统将这些硬件进行分时(CPU)、分片(内存)管理,虚拟化成一个独享资源让JVM进程在其上运行。
Tomcat启动多个线程,为每个用户请求分配一个线程,调用和请求URL路径相对应的Servlet(或者Controller)代码,完成用户请求处理。而Tomcat则在JVM虚拟机进程中,JVM虚拟机则被操作系统当做一个独立进程管理。真正完成最终计算的,是CPU、内存等服务器硬件,操作系统将这些硬件进行分时(CPU)、分片(内存)管理,虚拟化成一个独享资源让JVM进程在其上运行。
以上就是一个Java web应用运行时的主要架构,有时也被称作架构过程视图。需要注意的是,这里有个很多web开发者容易忽略的事情,那就是不管你是否有意识,你开发的web程序都是被多线程执行的,web开发天然就是多线程开发。
CPU以线程为单位进行分时共享执行,可以想象代码被加载到内存空间后,有多个线程在这些代码上执行,这些线程从逻辑上看,是同时在运行的,每个线程有自己的线程栈,所有的线程栈都是完全隔离的,也就是每个方法的参数和方法内的局部变量都是隔离的,一个线程无法访问到其他线程的栈内数据。
但是当某些代码修改内存堆里的数据的时候,如果有多个线程在同时执行,就可能会出现同时修改数据的情况,比如,两个线程同时对一个堆中的数据执行+1操作,最终这个数据只会被加一次,这就是人们常说的线程安全问题,实际上线程的结果应该是依次加一,即最终的结果应该是+2。
多个线程访问共享资源的这段代码被称为临界区,解决线程安全问题的主要方法是使用锁,将临界区的代码加锁,只有获得锁的线程才能执行临界区代码,如下:
lock.lock(); //线程获得锁
i++; //临界区代码,i位于堆中
lock.unlock(); //线程释放锁
如果当前线程执行到第一行,获得锁的代码的时候,锁已经被其他线程获取并没有释放,那么这个线程就会进入阻塞状态,等待前面释放锁的线程将自己唤醒重新获得锁。
锁会引起线程阻塞,如果有很多线程同时在运行,那么就会出现线程排队等待锁的情况,线程无法并行执行,系统响应速度就会变慢。此外I/O操作也会引起阻塞,对数据库连接的获取也可能会引起阻塞。目前典型的web应用都是基于RDBMS关系数据库的,web应用要想访问数据库,必须获得数据库连接,而受数据库资源限制,每个web应用能建立的数据库的连接是有限的,如果并发线程数超过了连接数,那么就会有部分线程无法获得连接而进入阻塞,等待其他线程释放连接后才能访问数据库,并发的线程数越多,等待连接的时间也越多,从web请求者角度看,响应时间变长,系统变慢。
被阻塞的线程越多,占据的系统资源也越多,这些被阻塞的线程既不能继续执行,也不能释放当前已经占据的资源,在系统中一边等待一边消耗资源,如果阻塞的线程数超过了某个系统资源的极限,就会导致系统宕机,应用崩溃。
解决系统因高并发而导致的响应变慢、应用崩溃的主要手段是使用分布式系统架构,用更多的服务器构成一个集群,以便共同处理用户的并发请求,保证每台服务器的并发负载不会太高。此外必要时还需要在请求入口处进行限流,减小系统的并发请求数;在应用内进行业务降级,减小线程的资源消耗。高并发系统架构方案将在专栏的第三模块中进一步探讨。
小结
事实上,现代CPU和操作系统的设计远比这篇文章讲的要复杂得多,但是基础原理大致就是如此。为了让程序能很好地被执行,软件开发的时候要考虑很多情况,为了让软件能更好地发挥效能,需要在部署上进行规划和架构。软件是如何运行的,应该是软件工程师和架构师的常识,在设计开发软件的时候,应该时刻以常识去审视自己的工作,保证软件开发在正确的方向上前进。
思考题
线程安全的临界区需要依靠锁,而锁的获取必须也要保证自己是线程安全的,也就是说,不能出现两个线程同时得到锁的情况,那么锁是如何保证自己是线程安全的呢?或者说,在操作系统以及CPU层面,锁是如何实现的?
02 数据结构原理:Hash表的时间复杂度为什么是O(1)?
大概十年前,我在阿里巴巴工作的时候,曾经和另一个面试官一起进行一场技术面试,面试过程中我问了一个问题:Hash表的时间复杂度为什么是O(1)?候选人没有回答上来。面试结束后我和另一个面试官有了分歧,我觉得这个问题没有回答上来是不可接受的。而他则觉得,这个问题有一点难度,回答不上来不说明什么。
因为有了这次争执,后来这个问题成了我面试时的必考题。此后十年间,我用这个问题面试了大约上千人,这些面试经历让我更加坚定了一个想法:这个问题就是候选人技术水平的一个分水岭,是证明一个技术人员是否具有必备专业技能和技术悟性的一个门槛。这个槛过不去是不可接受的。
为什么呢?我很难相信,如果基本的数据结构没有掌握好,如何能开发好一个稍微复杂一点的程序?
要了解Hash表,需要先从数组说起。
数组
数组是最常用的数据结构,创建数组必须要内存中一块连续的空间,并且数组中必须存放相同的数据类型。比如我们创建一个长度为10,数据类型为整型的数组,在内存中的地址是从1000开始,那么它在内存中的存储格式如下。
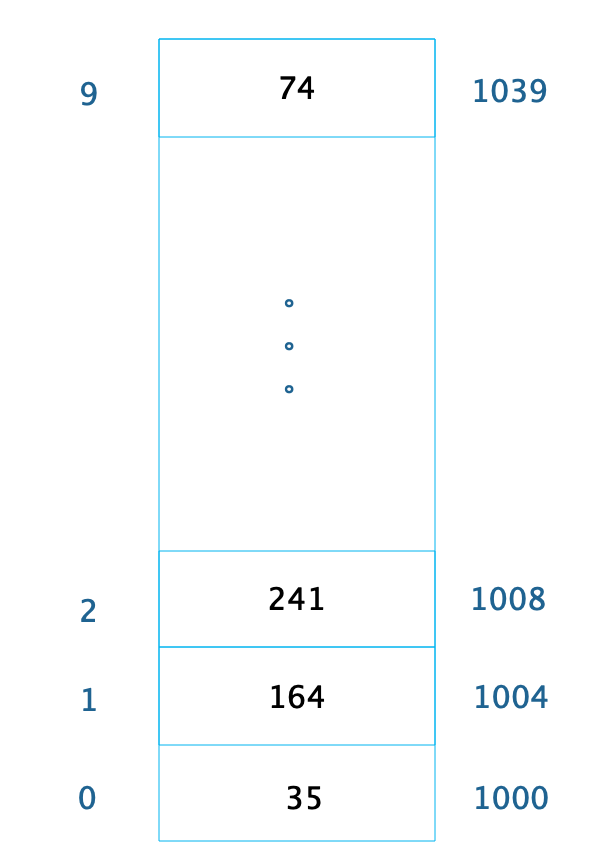
由于每个整型数据占据4个字节的内存空间,因此整个数组的内存空间地址是1000~1039,根据这个,我们就可以轻易算出数组中每个数据的内存下标地址。利用这个特性,我们只要知道了数组下标,也就是数据在数组中的位置,比如下标2,就可以计算得到这个数据在内存中的位置1008,从而对这个位置的数据241进行快速读写访问,时间复杂度为O(1)。
随机快速读写是数组的一个重要特性,但是要随机访问数据,必须知道数据在数组中的下标。如果我们只是知道数据的值,想要在数组中找到这个值,那么就只能遍历整个数组,时间复杂度为O(N)。
链表
不同于数组必须要连续的内存空间,链表可以使用零散的内存空间存储数据。不过,因为链表在内存中的数据不是连续的,所以链表中的每个数据元素都必须包含一个指向下一个数据元素的内存地址指针。如下图,链表的每个元素包含两部分,一部分是数据,一部分是指向下一个元素的地址指针。最后一个元素指向null,表示链表到此为止。
 因为链表是不连续存储的,要想在链表中查找一个数据,只能遍历链表,所以链表的查找复杂度总是O(N)。
因为链表是不连续存储的,要想在链表中查找一个数据,只能遍历链表,所以链表的查找复杂度总是O(N)。
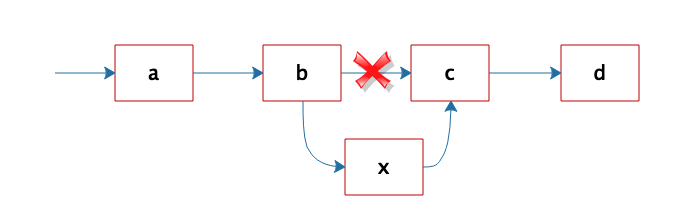
但是正因为链表是不连续存储的,所以在链表中插入或者删除一个数据是非常容易的,只要找到要插入(删除)的位置,修改链表指针就可以了。如图,想在b和c之间插入一个元素x,只需要将b指向c的指针修改为指向x,然后将x的指针指向c就可以了。
 相比在链表中轻易插入、删除一个元素这种简单的操作,如果我们要想在数组中插入、删除一个数据,就会改变数组连续内存空间的大小,需要重新分配内存空间,这样要复杂得多。
相比在链表中轻易插入、删除一个元素这种简单的操作,如果我们要想在数组中插入、删除一个数据,就会改变数组连续内存空间的大小,需要重新分配内存空间,这样要复杂得多。
Hash表
前面说过,对数组中的数据进行快速访问必须要通过数组的下标,时间复杂度为O(1)。如果只知道数据或者数据中的部分内容,想在数组中找到这个数据,还是需要遍历数组,时间复杂度为O(N)。
事实上,知道部分数据查找完整数据的需求在软件开发中会经常用到,比如知道了商品ID,想要查找完整的商品信息;知道了词条名称,想要查找百科词条中的详细信息等。
这类场景就需要用到Hash表这种数据结构。Hash表中数据以Key、Value的方式存储,上面例子中,商品ID和词条名称就是Key,商品信息和词条详细信息就是Value。存储的时候将Key、Value写入Hash表,读取的时候,只需要提供Key,就可以快速查找到Value。
Hash表的物理存储其实是一个数组,如果我们能够根据Key计算出数组下标,那么就可以快速在数组中查找到需要的Key和Value。许多编程语言支持获得任意对象的 HashCode,比如Java 语言中 HashCode 方法包含在根对象 Object 中,其返回值是一个 Int。我们可以利用这个Int类型的HashCode计算数组下标。最简单的方法就是余数法,使用 Hash 表的数组长度对 HashCode 求余, 余数即为 Hash 表数组的下标,使用这个下标就可以直接访问得到 Hash 表中存储的 Key、Value。
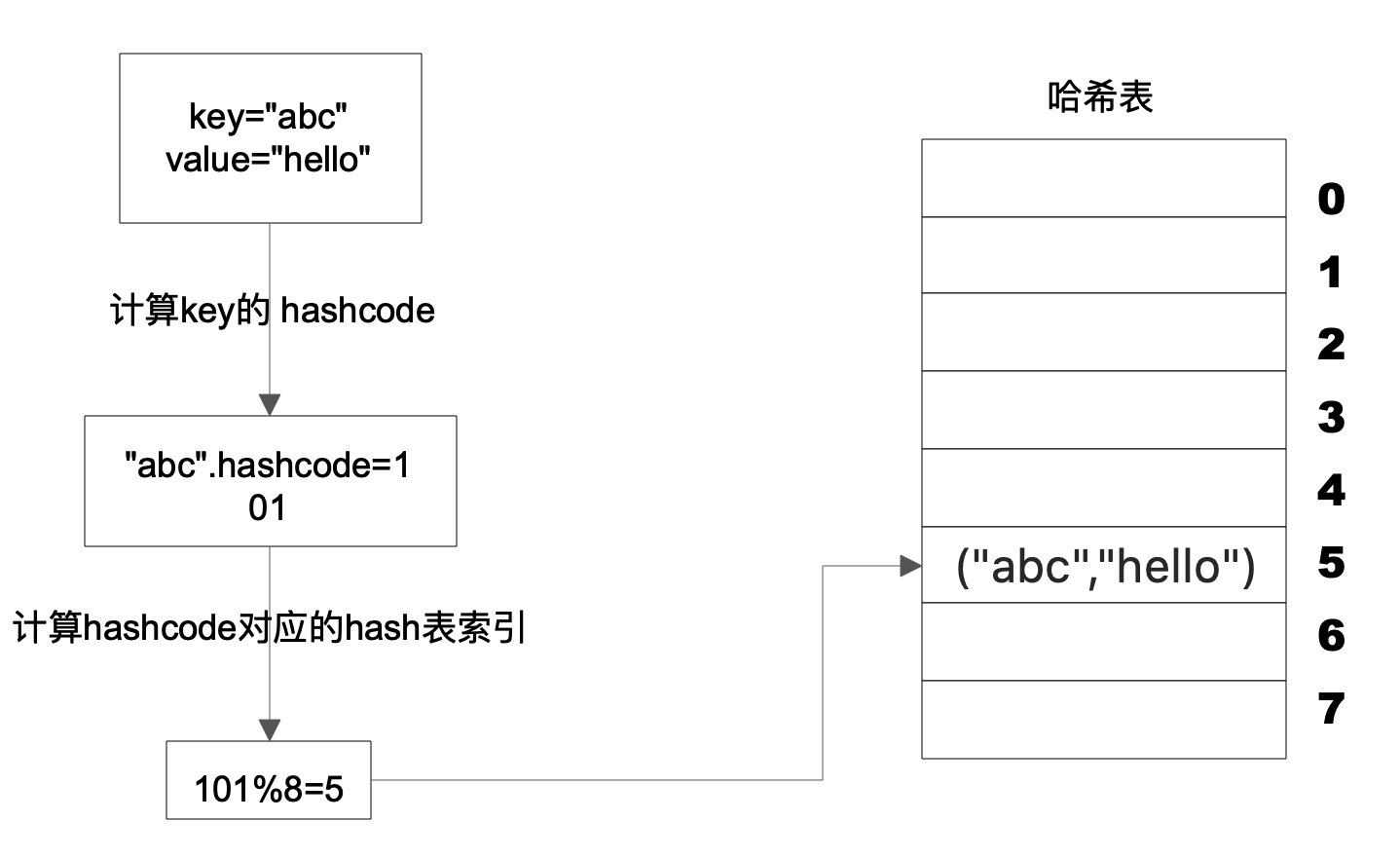 上图这个例子中,Key是字符串abc,Value是字符串hello。我们先计算Key的哈希值,得到101这样一个整型值。然后用101对8取模,这个8是哈希表数组的长度。101对8取模余5,这个5就是数组的下标,这样就可以把(“abc”,“hello”)这样一个Key、Value值存储在下标为5的数组记录中。
上图这个例子中,Key是字符串abc,Value是字符串hello。我们先计算Key的哈希值,得到101这样一个整型值。然后用101对8取模,这个8是哈希表数组的长度。101对8取模余5,这个5就是数组的下标,这样就可以把(“abc”,“hello”)这样一个Key、Value值存储在下标为5的数组记录中。
当我们要读取数据的时候,只要给定Key abc,还是用这样一个算法过程,先求取它的HashCode 101,然后再对8取模,因为数组的长度不变,对8取模以后依然是余5,那么我们到数组下标中去找5的这个位置,就可以找到前面存储进去的abc对应的Value值。
但是如果不同的Key计算出来的数组下标相同怎么办?HashCode101对8取模余数是5,HashCode109对8取模余数还是5,也就是说,不同的Key有可能计算得到相同的数组下标,这就是所谓的Hash冲突,解决Hash冲突常用的方法是链表法。
事实上,(“abc”,“hello”)这样的Key、Value数据并不会直接存储在Hash表的数组中,因为数组要求存储固定数据类型,主要目的是每个数组元素中要存放固定长度的数据。所以,数组中存储的是Key、Value数据元素的地址指针。一旦发生Hash冲突,只需要将相同下标,不同Key的数据元素添加到这个链表就可以了。查找的时候再遍历这个链表,匹配正确的Key。
如下图:
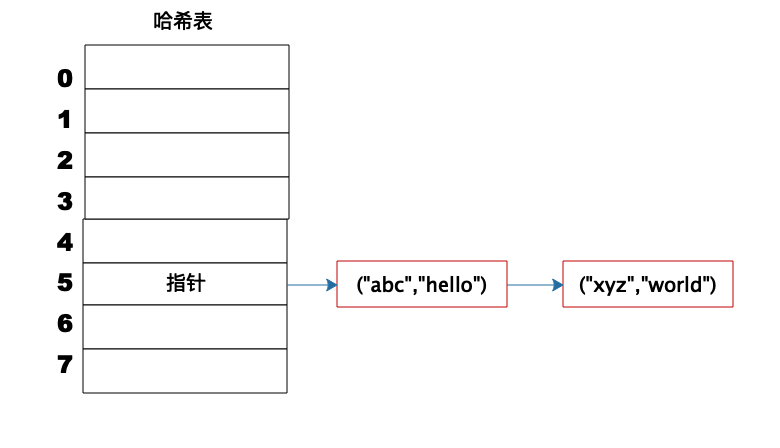
因为有Hash冲突的存在,所以“Hash表的时间复杂度为什么是O(1)?”这句话并不严谨,极端情况下,如果所有Key的数组下标都冲突,那么Hash表就退化为一条链表,查询的时间复杂度是O(N)。但是作为一个面试题,“Hash表的时间复杂度为什么是O(1)”是没有问题的。
栈
数组和链表都被称为线性表,因为里面的数据是按照线性组织存放的,每个数据元素的前面只能有一个(前驱)数据元素,后面也只能有一个(后继)数据元素,所以称为线性表。但是对数组和链表的操作可以是随机的,可以对其上任何元素进行操作,如果对操作方式加以限制,就形成了新的数据结构。
栈就是在线性表的基础上加了这样的操作限制条件:后面添加的数据,在删除的时候必须先删除,即通常所说的“后进先出”。我们可以把栈可以想象成一个大桶,往桶里面放食物,一层一层放进去,如果要吃的时候,必须从最上面一层吃,吃了几层后,再往里放食物,还是从当前的最上面一层放起。
栈在线性表的基础上增加了操作限制,具体实现的时候,因为栈不需要随机访问、也不需要在中间添加、删除数据,所以可以用数组实现,也可以用链表实现。那么在顺序表的基础上增加操作限制有什么好处呢?
我们上篇提到的程序运行过程中,方法的调用需要用栈来管理每个方法的工作区,这样,不管方法如何嵌套调用,栈顶元素始终是当前正在执行的方法的工作区。这样,事情就简单了。而简单,正是我们做软件开发应该努力追求的一个目标。
队列
队列也是一种操作受限的线性表,栈是后进先出,而队列是先进先出。
 在软件运行期,经常会遇到资源不足的情况:提交任务请求线程池执行,但是线程已经用完了,任务需要放入队列,先进先出排队执行;线程在运行中需要访问数据库,数据库连接有限,已经用完了,线程进入阻塞队列,当有数据库连接释放的时候,从阻塞队列头部唤醒一个线程,出队列获得连接访问数据库。
在软件运行期,经常会遇到资源不足的情况:提交任务请求线程池执行,但是线程已经用完了,任务需要放入队列,先进先出排队执行;线程在运行中需要访问数据库,数据库连接有限,已经用完了,线程进入阻塞队列,当有数据库连接释放的时候,从阻塞队列头部唤醒一个线程,出队列获得连接访问数据库。
我在上面讲堆栈的时候,举了一个大桶放食物的例子,事实上,如果用这种方式存放食物,有可能最底下食物永远都吃不到,最后过期了。
现实中也是如此,超市在货架上摆放食品的时候,其实是按照队列摆放的,而不是堆栈摆放的。工作人员在上架新食品的时候,总是把新食品摆在后面,使食品成为一个队列,以便让以前上架的食品被尽快卖出。
树
数组、链表、栈、队列都是线性表,也就是每个数据元素都只有一个前驱,一个后继。而树则是非线性表,树是这样的。
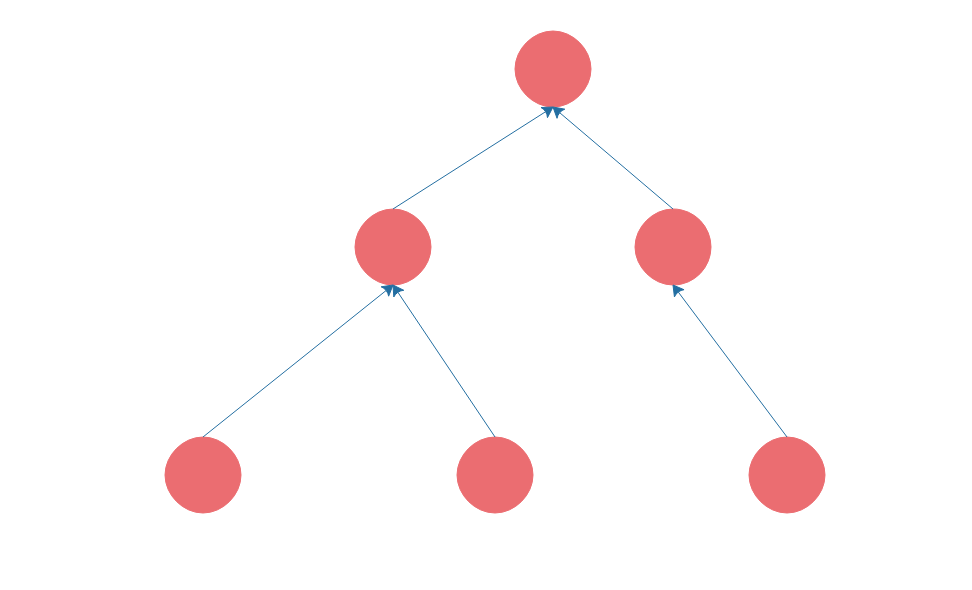
软件开发中,也有很多地方用到树,比如我们要开发一个OA系统,部门的组织结构就是一棵树;我们编写的程序在编译的时候,第一步就是将程序代码生成抽象语法树。传统上树的遍历使用递归的方式,而我个人更喜欢用设计模式中的组合模式进行树的遍历,具体我将会在设计模式部分详细讨论。
小结
这是一篇关于数据结构的专栏文章,面试中问数据结构是一个非常有意思的话题,很多拥有绚丽简历和多年工作经验的候选人在数据结构的问题上翻了船,这些人有时候会解释说,这些知识都是大学时学过的,工作这些年用不着,记不太清楚了。
事实上,我很难相信,如果这些基本数据结构没有掌握好,如何能开发好一个稍微复杂一点的程序。但欣慰的是,在这些年的面试过程中,我发现候选者中能够正确回答基本数据结构问题的比例越来越高了,我也越来越坚定用数据结构问题当做是否跨过专业工程师门槛的试金石。作为一个专业软件工程师,不管有多少年经验,说不清楚基础数据结构的工作原理是不能接受的。
思考题
链表结构虽然简单,但是各种组合变换操作却可以很复杂。关于链表的操作也是面试官最喜欢问的数据结构问题之一,我在面试过程中喜欢问的一个链表问题是:
有两个单向链表,这两个单向链表有可能在某个元素合并,如下图所示的这样,也可能不合并。现在给定两个链表的头指针,如何快速地判断这两个链表是否合并?如果合并,找到合并的元素,也就是图中的x元素。
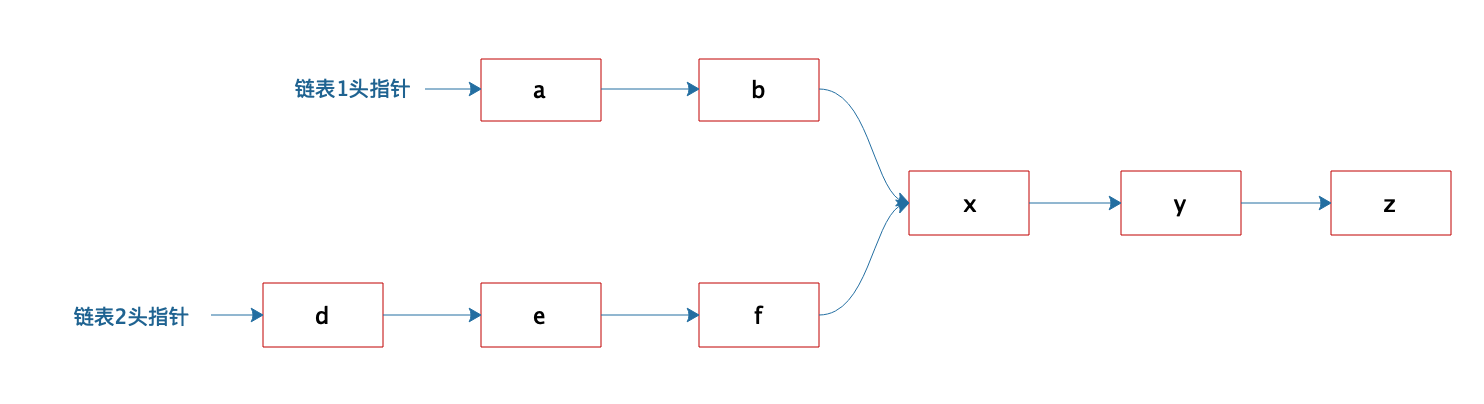
关于这道题,你的答案是什么呢?
03 Java虚拟机原理:JVM为什么被称为机器(machine)?
人们常说,Java是一种跨平台的语言,这意味着Java开发出来的程序经过编译后,可以在Linux上运行,也可以在Windows上运行;可以在PC、服务器上运行,也可以在手机上运行;可以在X86的CPU上运行,也可以在ARM的CPU上运行。
因为不同操作系统,特别是不同CPU架构,是不可能执行相同的指令的。而Java之所以有这种神奇的特性,就是因为Java编译的字节码文件不是直接在底层的系统平台上运行的,而是在Java虚拟机JVM上运行,JVM屏蔽了底层系统的不同,为Java字节码文件构造了一个统一的运行环境。JVM本质上也是一个应用程序,启动以后加载执行Java字节码文件。JVM的全称是Java Virtual Machine,你有没有想过,这样一个程序为什么被称为机器(Machine)呢?
其实,如果回答了这个问题,也就了解了JVM的底层构造了。这样在进行Java开发的时候,如果遇到各种问题,都可以思考一下在JVM层面是如何的?然后进一步查找资料、分析问题,直至真正地解决问题。
JVM的组成构造
要想知道这个问题的答案,我们首先需要了解JVM的构造。JVM主要由类加载器、运行时数据区、执行引擎三个部分组成。
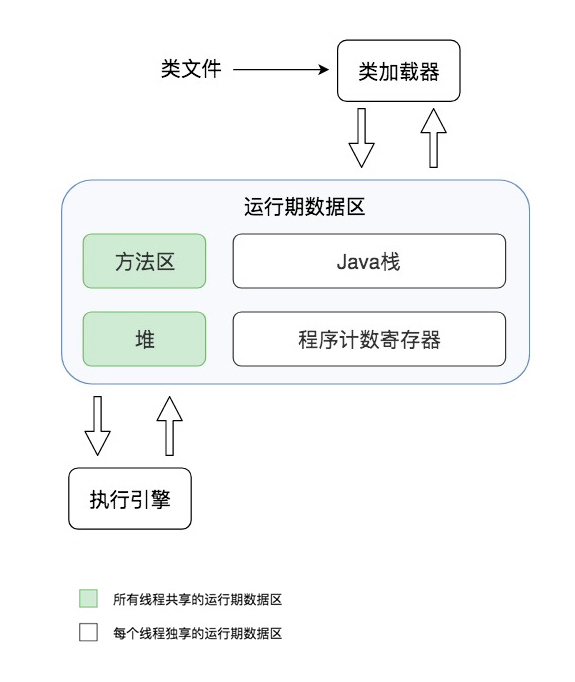
运行时数据区主要包括方法区、堆、Java栈、程序计数寄存器。
方法区主要存放从磁盘加载进来的类字节码,而在程序运行过程中创建的类实例则存放在堆里。程序运行的时候,实际上是以线程为单位运行的,当JVM进入启动类的main方法的时候,就会为应用程序创建一个主线程,main方法里的代码就会被这个主线程执行,每个线程有自己的Java栈,栈里存放着方法运行期的局部变量。而当前线程执行到哪一行字节码指令,这个信息则被存放在程序计数寄存器。
一个典型的Java程序运行过程是下面这样的。
通过Java命令启动JVM,JVM的类加载器根据Java命令的参数到指定的路径加载.class类文件,类文件被加载到内存后,存放在专门的方法区。然后JVM创建一个主线程执行这个类文件的main方法,main方法的输入参数和方法内定义的变量被压入Java栈。如果在方法内创建了一个对象实例,这个对象实例信息将会被存放到堆里,而对象实例的引用,也就是对象实例在堆中的地址信息则会被记录在栈里。堆中记录的对象实例信息主要是成员变量信息,因为类方法内的可执行代码存放在方法区,而方法内的局部变量存放在线程的栈里。
程序计数寄存器一开始存放的是main方法的第一行代码位置,JVM的执行引擎根据这个位置去方法区的对应位置加载这行代码指令,将其解释为自身所在平台的CPU指令后交给CPU执行。如果在main方法里调用了其他方法,那么在进入其他方法的时候,会在Java栈中为这个方法创建一个新的栈帧,当线程在这个方法内执行的时候,方法内的局部变量都存放在这个栈帧里。当这个方法执行完毕退出的时候,就把这个栈帧从Java栈中出栈,这样当前栈帧,也就是堆栈的栈顶就又回到了main方法的栈帧,使用这个栈帧里的变量,继续执行main方法。这样,即使main方法和f方法都定义相同的变量,JVM也不会弄错。这部分内容我们在第一篇已经讨论过,JVM作为一个machine,和操作系统的处理线程栈的的方法是一样的。
 Java的线程安全常常让人困惑,你可以试着从Java栈的角度去理解,所有在方法内定义的基本类型变量,都会被每个运行这个方法的线程放入自己的栈中,线程的栈彼此隔离,所以这些变量一定是线程安全的。如果在方法里创建了一个对象实例,这个对象实例如果没有被方法返回或者放入某些外部的对象容器中的话,也就是说这个对象的引用没有离开这个方法,虽然这个对象被放置在堆中,但是这个对象不会被其他线程访问到,也是线程安全的。
Java的线程安全常常让人困惑,你可以试着从Java栈的角度去理解,所有在方法内定义的基本类型变量,都会被每个运行这个方法的线程放入自己的栈中,线程的栈彼此隔离,所以这些变量一定是线程安全的。如果在方法里创建了一个对象实例,这个对象实例如果没有被方法返回或者放入某些外部的对象容器中的话,也就是说这个对象的引用没有离开这个方法,虽然这个对象被放置在堆中,但是这个对象不会被其他线程访问到,也是线程安全的。
相反,像Servlet这样的类,在Web容器中创建以后,会被传递给每个访问Web应用的用户线程执行,这个类就不是线程安全的。但这并不意味着一定会引发线程安全问题,如果Servlet类里没有成员变量,即使多线程同时执行这个Servlet实例的方法,也不会造成成员变量冲突。这种对象被称作无状态对象,也就是说对象不记录状态,执行这个对象的任何方法都不会改变对象的状态,也就不会有线程安全问题了。事实上,Web开发实践中,常见的Service类、DAO类,都被设计成无状态对象,所以虽然我们开发的Web应用都是多线程的应用,因为Web容器一定会创建多线程来执行我们的代码,但是我们开发中却可以很少考虑线程安全的问题。
我们再回过头看JVM,它封装了一组自定义的字节码指令集,有自己的程序计数器和执行引擎,像CPU一样,可以执行运算指令。它还像操作系统一样有自己的程序装载与运行机制,内存管理机制,线程及栈管理机制,看起来就像是一台完整的计算机,这就是JVM被称作machine(机器)的原因。
JVM的垃圾回收
事实上,JVM比操作系统更进一步,它不但可以管理内存,还可以对内存进行自动垃圾回收。所谓自动垃圾回收就是将JVM堆中的已经不再被使用的对象清理掉,释放宝贵的内存资源。那么要想进行垃圾回收,首先一个问题就是如何知道哪些对象是不再被使用的,可以清理的呢?
JVM通过一种可达性分析算法进行垃圾对象的识别,具体过程是:从线程栈帧中的局部变量,或者是方法区的静态变量出发,将这些变量引用的对象进行标记,然后看这些被标记的对象是否引用了其他对象,继续进行标记,所有被标记过的对象都是被使用的对象,而那些没有被标记的对象就是可回收的垃圾对象了。所以你可以看出来,可达性分析算法其实是一个引用标记算法。
进行完标记以后,JVM就会对垃圾对象占用的内存进行回收,回收主要有三种方法。
第一种方式是清理:将垃圾对象占据的内存清理掉,其实JVM并不会真的将这些垃圾内存进行清理,而是将这些垃圾对象占用的内存空间标记为空闲,记录在一个空闲列表里,当应用程序需要创建新对象的时候,就从空闲列表中找一段空闲内存分配给这个新对象。
但这样做有一个很明显的缺陷,由于垃圾对象是散落在内存空间各处的,所以标记出来的空闲空间也是不连续的,当应用程序创建一个数组需要申请一段连续的大内存空间时,即使堆空间中有足够的空闲空间,也无法为应用程序分配内存。
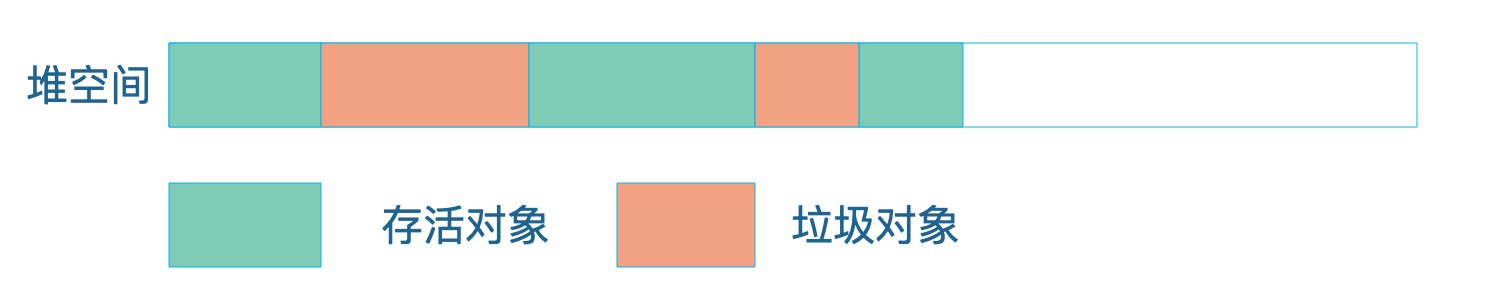
第二种方式是压缩:从堆空间的头部开始,将存活的对象拷贝放在一段连续的内存空间中,那么其余的空间就是连续的空闲空间。
第三种方法是复制:将堆空间分成两部分,只在其中一部分创建对象,当这个部分空间用完的时候,将标记过的可用对象复制到另一个空间中。JVM将这两个空间分别命名为from区域和to区域。当对象从from区域复制到to区域后,两个区域交换名称引用,继续在from区域创建对象,直到from区域满。
下面这系列图可以让你直观地了解JVM三种不同的垃圾回收机制。
回收前:
 清理:
清理:
 压缩:
压缩:
 复制:
复制:
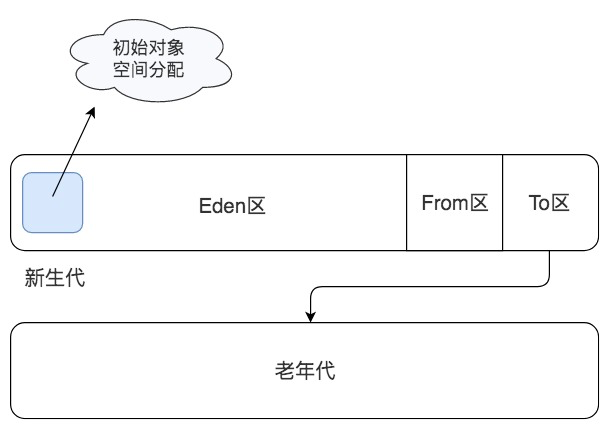
 JVM在具体进行垃圾回收的时候,会进行分代回收。绝大多数的Java对象存活时间都非常短,很多时候就是在一个方法内创建对象,对象引用放在栈中,当方法调用结束,栈帧出栈的时候,这个对象就失去引用了,成为垃圾。针对这种情况,JVM将堆空间分成新生代(young)和老年代(old)两个区域,创建对象的时候,只在新生代创建,当新生代空间不足的时候,只对新生代进行垃圾回收,这样需要处理的内存空间就比较小,垃圾回收速度就比较快。
JVM在具体进行垃圾回收的时候,会进行分代回收。绝大多数的Java对象存活时间都非常短,很多时候就是在一个方法内创建对象,对象引用放在栈中,当方法调用结束,栈帧出栈的时候,这个对象就失去引用了,成为垃圾。针对这种情况,JVM将堆空间分成新生代(young)和老年代(old)两个区域,创建对象的时候,只在新生代创建,当新生代空间不足的时候,只对新生代进行垃圾回收,这样需要处理的内存空间就比较小,垃圾回收速度就比较快。
新生代又分为Eden区、From区和To区三个区域,每次垃圾回收都是扫描Eden区和From区,将存活对象复制到To区,然后交换From区和To区的名称引用,下次垃圾回收的时候继续将存活对象从From区复制到To区。当一个对象经过几次新生代垃圾回收,也就是几次从From区复制到To区以后,依然存活,那么这个对象就会被复制到老年代区域。
当老年代空间已满,也就是无法将新生代中多次复制后依然存活的对象复制进去的时候,就会对新生代和老年代的内存空间进行一次全量垃圾回收,即Full GC。所以根据应用程序的对象存活时间,合理设置老年代和新生代的空间比例对JVM垃圾回收的性能有很大影响,JVM设置老年代新生代比例的参数是-XX:NewRatio。
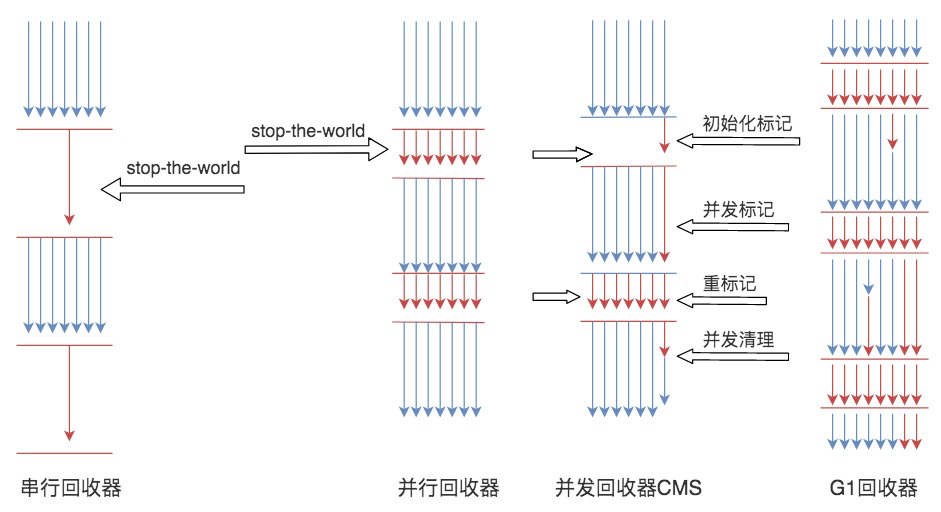
 JVM中,具体执行垃圾回收的垃圾回收器有四种。
JVM中,具体执行垃圾回收的垃圾回收器有四种。
第一种是Serial 串行垃圾回收器,这是JVM早期的垃圾回收器,只有一个线程执行垃圾回收。
第二种是Parallel 并行垃圾回收器,它启动多线程执行垃圾回收。如果JVM运行在多核CPU上,那么显然并行垃圾回收要比串行垃圾回收效率高。
在串行和并行垃圾回收过程中,当垃圾回收线程工作的时候,必须要停止用户线程的工作,否则可能会导致对象的引用标记错乱,因此垃圾回收过程也被称为stop the world,在用户视角看来,所有的程序都不再执行,整个世界都停止了。
第三种CMS 并发垃圾回收器,在垃圾回收的某些阶段,垃圾回收线程和用户线程可以并发运行,因此对用户线程的影响较小。Web应用这类对用户响应时间比较敏感的场景,适用CMS垃圾回收器。
最后一种是G1 垃圾回收器,它将整个堆空间分成多个子区域,然后在这些子区域上各自独立进行垃圾回收,在回收过程中垃圾回收线程和用户线程也是并发运行。G1综合了以前几种垃圾回收器的优势,适用于各种场景,是未来主要的垃圾回收器。
小结
我们为什么需要了解JVM呢?JVM有很多配置参数,Java开发过程中也可能会遇到各种问题,了解了JVM的基本构造,就可以帮助我们从原理上去解决问题。
比如遇到OutOfMemoryError,我们就知道是堆空间不足了,可能是JVM分配的内存空间不足以让程序正常运行,这时候我们需要通过调整-Xmx参数增加内存空间。也可能是程序存在内存泄漏,比如一些对象被放入List或者Map等容器对象中,虽然这些对象程序已经不再使用了,但是这些对象依然被容器对象引用,无法进行垃圾回收,导致内存溢出,这时候可以通过jmap命令查看堆中的对象情况,分析是否有内存泄漏。
如果遇到StackOverflowError,我们就知道是线程栈空间不足,栈空间不足通常是因为方法调用的层次太多,导致栈帧太多。我们可以先通过栈异常信息观察是否存在错误的递归调用,因为每次递归都会使嵌套方法调用更深入一层。如果调用是正常的,可以尝试调整-Xss参数增加栈空间大小。
如果程序运行卡顿,部分请求响应延迟比较厉害,那么可以通过jstat命令查看垃圾回收器的运行状况,是否存在较长时间的FullGC,然后调整垃圾回收器的相关参数,使垃圾回收对程序运行的影响尽可能小。
执行引擎在执行字节码指令的时候,是解释执行的,也就是每个字节码指令都会被解释成一个底层的CPU指令,但是这样的解释执行效率比较差,JVM对此进行了优化,将频繁执行的代码编译为底层CPU指令存储起来,后面再执行的时候,直接执行编译好的指令,不再解释执行,这就是JVM的即时编译JIT。Web应用程序通常是长时间运行的,使用JIT会有很好的优化效果,可以通过-server参数打开JIT的C2编译器进行优化。
总之,如果你理解了JVM的构造,在进行Java开发的时候,遇到各种问题,都可以思考一下,这在JVM层面是如何的?然后进一步查找资料、分析问题,这样就会真正解决问题,而且经过这样不断地思考分析,你对Java,对JVM,甚至对整个计算机的原理体系以及设计理念都会有更多认识和领悟。
思考题
你在Java开发过程中遇到过什么样的问题?这些问题和JVM底层原理是怎样的关系?
04 网络编程原理:一个字符的互联网之旅
我们开发的面向普通用户的应用程序,目前看来几乎都是互联网应用程序,也就是说,用户操作的应用程序,不管是浏览器还是移动App,核心请求都会通过互联网发送到后端的数据中心进行处理。这个数据中心可能是像微信这样的自己建设的、在多个地区部署的大规模机房,也可能是阿里云这样的云服务商提供的一个虚拟主机。
但是不管这个数据中心的大小,应用程序都需要在运行期和数据中心交互。比如我们在淘宝的搜索框随便输入一个字符“a”,就会在屏幕上看到一大堆商品。那么我们的手机是如何通过互联网完成这一操作的?这个字符如何穿越遥远的空间,从手机发送到淘宝的数据中心,在淘宝计算得到相关的结果,然后将结果再返回到我们的手机上,从而完成自己的互联网之旅呢?
虽然我们在编程的时候,很少要自己直接开发网络通信代码,服务器由Tomcat这样的WEB容器管理网络通信,服务间网络通信通过Dubbo这样的分布式服务框架完成网络通信。但是由于我们现在开发的应用主要是互联网应用,它们构建在网络通信基础上,网络通信的问题可能会出现在系统运行的任何时刻。了解网络通信原理,了解互联网应用如何跨越庞大的网络构建起来,对我们开发一个互联网应用系统很有帮助,对我们解决系统运行过程中各种因为网络通信而出现的各种问题更有帮助。
DNS
我们先从DNS说起。
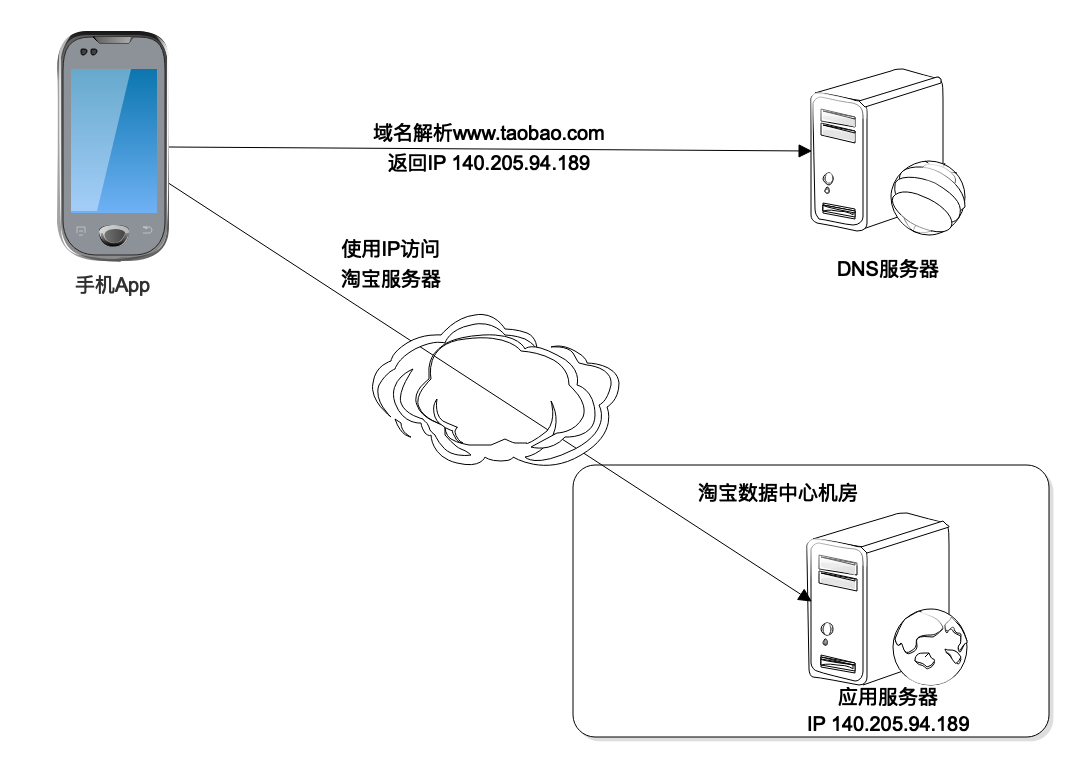
构成互联网Internet的最基本的网络协议就是互联网协议Internet Protocol,简称IP协议。IP协议里面最重要的部分是IP地址,各种计算机设备之间能够互相通信,首先要能够找到彼此,IP地址就是互联网的地址标识。手机上的淘宝App能够访问淘宝的数据中心,就是知道了淘宝数据中心负责请求接入的服务器的IP地址,然后建立网络连接,进而处理请求数据。
那么手机上的淘宝App如何知道数据中心服务器的IP地址呢?当然淘宝的工程师可以在App里写死这个IP地址,但是这样做会带来很多问题,比如影响编程的灵活性以及程序的可用性等。
事实上这个IP地址是通过DNS域名解析服务器得到的。当我们打开淘宝App的时候,淘宝要把App首页加载进来,这时候就需要连接域名服务器进行域名解析,将xxx.taobao.com这样的域名解析为一个IP地址,然后连接目标服务器。
CDN
事实上DNS解析出来的IP地址,并不一定是淘宝数据中心的IP地址,也可能是淘宝CDN服务器的IP地址。
CDN是内容分发网络Content Delivery Network的缩写。我们能够用手机或者电脑上网,是因为运营服务商为我们提供了互联网接入服务,将我们的手机和电脑连接到互联网上。App请求的数据最先到达的是运营服务商的机房,然后运营商通过自己建设的骨干网络和交换节点,将我们请求数据的目的地址发往互联网的任何地方。
为了提高用户请求访问的速度,也为了降低数据中心的负载压力,淘宝会在全国各地各个主要的运营服务商的接入机房中部署一些缓存服务器,缓存那些静态的图片、资源文件等,这些缓存服务器构成了淘宝的CDN。
如果用户请求的数据数据是静态的资源,这些资源的URL通常以image.taobao.com之类的二级域名进行标识,域名解析的时候就会解析为淘宝CDN的IP地址,请求先被CDN处理,如果CDN中有需要的静态文件,就直接返回,如果没有,CDN会将请求发送到淘宝的数据中心,CDN从淘宝数据中心获得静态文件后,一方面缓存在自己的服务器上,一方面将数据返回给用户的App。
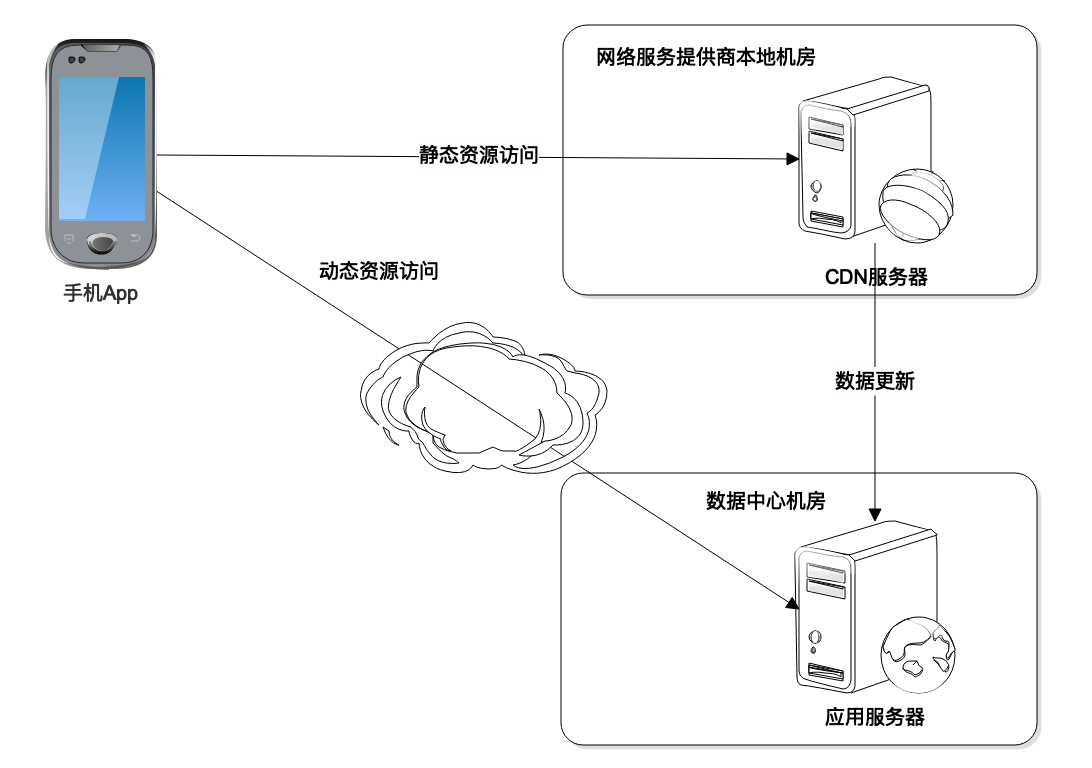 而如果请求的数据是动态的,比如要搜索关键词为“a”的商品列表,请求的域名可能会是search.taobao.com这样的二级域名,就会直接被DNS解析为淘宝的数据中心的服务器IP地址,App请求发送到数据中心处理。
而如果请求的数据是动态的,比如要搜索关键词为“a”的商品列表,请求的域名可能会是search.taobao.com这样的二级域名,就会直接被DNS解析为淘宝的数据中心的服务器IP地址,App请求发送到数据中心处理。
HTTP
不管发送到CDN还是数据中心,App请求都会以HTTP协议发送。
HTTP是一个应用层协议,当我们进行网络通信编程的时候,通常需要关注两方面的内容,一方面是应用层的通信协议,主要是我们通信的数据如何编码,既能使网络传输过去的数据携带必要的信息,又使通信的两方都能正确识别这些数据,即通信双方应用程序需要约定一个数据编码协议。另一方面就是网络底层通信协议,即如何为网络上需要通信的两个节点建立连接完成数据传输,目前互联网应用中最主要的就是TCP协议。
在TCP传输层协议层面,就是保证建立通信两方的稳定通信连接,将一方的数据以bit流的方式源源不断地发送到另一方,至于这些数据代表什么意思,哪里是两次请求的分界点,TCP协议统统不管,需要应用层面自己解决。如果我们基于TCP协议自己开发应用程序,就必须解决这些问题。而互联网应用需要在全球范围为用户提供服务,将全球的应用和全球的用户联系在一起,需要一个统一的应用层协议,这个协议就是HTTP协议。
 这张图是HTTP的请求头的例子,包括请求方法和请求头参数。请求方法主要有GET、POST,这是我们最常用的两种,此外还有DELETE、PUT、HEAD、TRACE等几种方法;请求头参数包括缓存控制Cache-Control、响应过期时间Expires、Cookie等等。
这张图是HTTP的请求头的例子,包括请求方法和请求头参数。请求方法主要有GET、POST,这是我们最常用的两种,此外还有DELETE、PUT、HEAD、TRACE等几种方法;请求头参数包括缓存控制Cache-Control、响应过期时间Expires、Cookie等等。
HTTP请求如果是GET方法,那么就只有请求头;如果是POST方法,在请求头之后还有一个body部分,包含请求提交的内容,HTTP会在请求头的Content-Length参数声明body的长度。
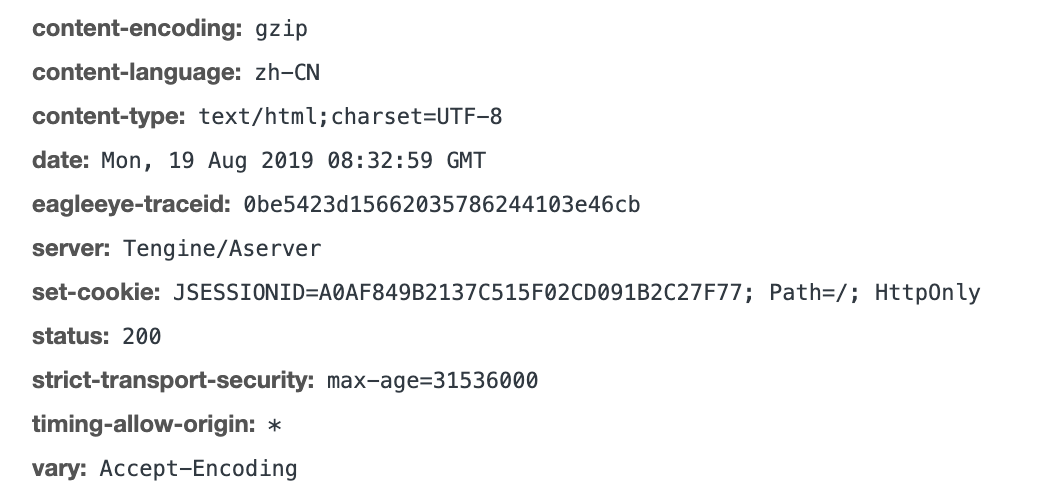 这是HTTP响应头的例子,响应头和请求头一样包含各种参数,而status状态码声明响应状态,状态码是200,表示响应正常。
这是HTTP响应头的例子,响应头和请求头一样包含各种参数,而status状态码声明响应状态,状态码是200,表示响应正常。
响应状态码是3XX,表示请求被重定向,常用的302,表示请求被临时重定向到新的URL,响应头中包含新的临时URL,客户端收到响应后,重新请求这个新的URL;状态码是4XX,表示客户端错误,常见的403,表示请求未授权,被禁止访问,404表示请求的页面不存在;状态码是5XX,表示服务器异常,常见的500请求未完成,502请求处理超时,503服务器过载。
如果响应正常,那么在响应头之后就是响应body,浏览器的响应body通常是一个HTML页面,App的响应body通常是个JSON字符串。
TCP
应用程序使用操作系统的socket接口进行网络编程,socket里封装了TCP协议。应用程序通过socket接口使用TCP协议完成网络编程,socket或者TCP在应用程序看就是一个底层通信协议,事实上,TCP仅仅是一个传输层协议,在传输层协议之下,还有网络层协议,网络层协议之下还有数据链路层协议,数据链路层协议之下还有物理层协议。

传输层协议TCP和网络层协议IP共同构成TCP/IP协议栈,成为互联网应用开发最主要的通信协议。OSI开放系统互联模型将网络协议定义了7层,TCP/IP协议栈将OSI顶部三层协议应用层、表示层、会话层合并为一个应用层,HTTP协议就是TCP/IP协议栈中的应用层协议。
物理层负责数据的物理传输,计算机输入输出的只能是0 1这样的二进制数据,但是在真正的通信线路里有光纤、电缆、无线各种设备。光信号和电信号,以及无线电磁信号在物理上是完全不同的,如何让这些不同的设备能够理解、处理相同的二进制数据,这就是物理层要解决的问题。
数据链路层就是将数据进行封装后交给物理层进行传输,主要就是将数据封装成数据帧,以帧为单位通过物理层进行通信,有了帧,就可以在帧上进行数据校验,进行流量控制。数据链路层会定义帧的大小,这个大小也被称为最大传输单元。
像HTTP要在传输的数据上添加一个HTTP头一样,数据链路层也会将封装好的帧添加一个帧头,帧头里记录的一个重要信息就是发送者和接受者的mac地址。mac地址是网卡的设备标识符,是唯一的,数据帧通过这个信息确保数据送达到正确的目标机器。
前面已经提到,网络层IP协议使得互联网应用根据IP地址就能访问到淘宝的数据中心,请求离开App后,到达运营服务商的交换机,交换机会根据这个IP地址进行路由转发,可能中间会经过很多个转发节点,最后数据到达淘宝的服务器。
网络层的数据需要交给链路层进行处理,而链路层帧的大小定义了最大传输单元,网络层的IP数据包必须要小于最大传输单元才能进行网络传输,这个数据包也有一个IP头,主要包括的就是发送者和接受者的IP地址。
IP协议不是一个可靠的通信协议,并不会确保数据一定送达。要保证通信的稳定可靠,需要传输层协议TCP。TCP协议在传输正式数据前,会先建立连接,这就是著名的TCP三次握手。
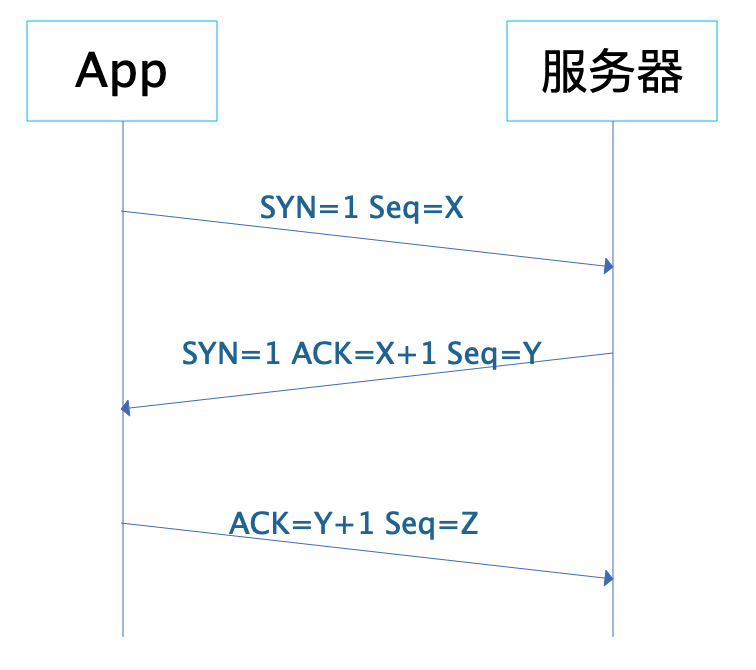 App和服务器之间发送三次报文才会建立一个TCP连接,报文中的SYN表示请求建立连接,ACK表示确认。App先发送 SYN=1,Seq=X的报文,表示请求建立连接,X是一个随机数;淘宝服务器收到这个报文后,应答SYN=1,ACK=X+1,Seq=Y的报文,表示同意建立连接;App收到这个报文后,检查ACK的值为自己发送的Seq值+1,确认建立连接,并发送ACK=Y+1的报文给服务器;服务器收到这个报文后检查ACK值为自己发送的Seq值+1,确认建立连接。至此,App和服务器建立起TCP连接,就可以进行数据传输了。
App和服务器之间发送三次报文才会建立一个TCP连接,报文中的SYN表示请求建立连接,ACK表示确认。App先发送 SYN=1,Seq=X的报文,表示请求建立连接,X是一个随机数;淘宝服务器收到这个报文后,应答SYN=1,ACK=X+1,Seq=Y的报文,表示同意建立连接;App收到这个报文后,检查ACK的值为自己发送的Seq值+1,确认建立连接,并发送ACK=Y+1的报文给服务器;服务器收到这个报文后检查ACK值为自己发送的Seq值+1,确认建立连接。至此,App和服务器建立起TCP连接,就可以进行数据传输了。
TCP也会在数据包上添加TCP头,TCP头除了包含一些用于校验数据正确性和控制数据流量的信息外,还包含通信端口信息,一台机器可能同时有很多进程在进行网络通信。如何使数据到达服务器后能发送给正确的进程去处理,就需要靠通信端口进行标识了。HTTP默认端口是80,当然我们可以在启动HTTP应用服务器进程的时候,随便定义一个数字作为HTTP应用服务器进程的监听端口,但是App在请求的时候,必须在URL中包含这个端口,才能在构建的TCP包中记录这个端口,也才能在到达服务器后,被正确的HTTP服务器进程处理。
如果我们以POST方法提交一个搜索请求给淘宝服务器,那么最终在数据链路层构建出来的数据帧大概是这个样子,这里假设IP数据包的大小没有超过链路层的最大传输单元。

App要发送的数据只是key=“a”这样一个JSON字符串,每一层协议都会在上一层协议基础上添加一个头部信息,最后封装成一个链路层的数据帧在网络上传输,发送给淘宝的服务器。淘宝的服务器在收到这个数据帧后,在通信协议的每一层进行校验检查,确保数据准确后,将头部信息删除,再交给自己的上一层协议处理。HTTP应用服务器在最上层,负责HTTP协议的处理,最后将key=“a”这个JSON字符串交给淘宝工程师开发的应用程序处理。
LB(负载均衡)
HTTP请求到达淘宝数据中心的时候,事实上也并不是直接发送给搜索服务器处理。因为对于淘宝这样日活用户数亿的互联网应用而言,每时每刻都有大量的搜索请求到达数据中心,为了使这些海量的搜索请求都能得到及时处理,淘宝会部署一个由数千台服务器组成的搜索服务器集群,共同为这些高并发的请求提供服务。
因此,搜索请求到达数据中心的时候,首先到达的是搜索服务器集群的负载均衡服务器,也就是说,DNS解析出来的是负载均衡服务器的IP地址。然后,由负载均衡服务器将请求分发到搜索服务器集群中的某台服务器上。
负载均衡服务器的实现手段有很多种,淘宝这样规模的应用,通常使用Linux内核支持的链路层负载均衡。
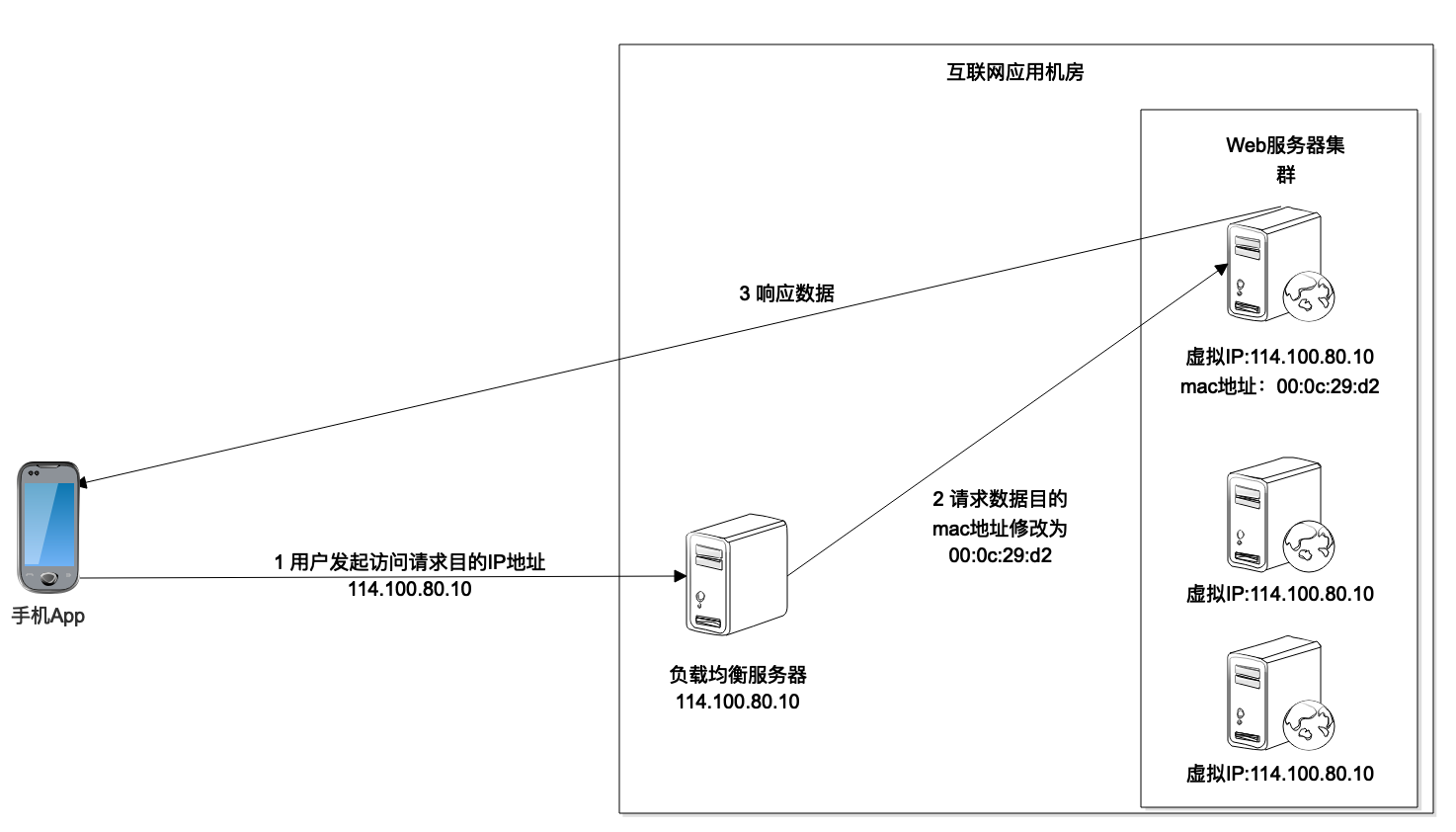
这种负载均衡模式也叫直接路由模式,在负载均衡服务器的Linux操作系统内核拿到数据包后,直接修改数据帧中的mac地址,将其修改为搜索服务器集群中某个服务器的mac地址,然后将数据重新发送回服务器集群所在的局域网,这个数据帧就会被某个真实的搜索服务器接收到。
负载均衡服务器和集群内的搜索服务器配置相同的虚拟IP地址,也就是说,在网络通信的IP层面,负载均衡服务器变更mac地址的操作是透明的,不影响TCP/IP的通信连接。所以真实的搜索服务器处理完搜索请求,发送应答响应的时候,就会直接发送回请求的App手机,不会再经过负载均衡服务器。
小结
事实上,这个搜索字符“a”的互联网之旅到这里还没有结束。淘宝搜索服务器程序在收到这个搜索请求的时候,首先在本地缓存中查找是否有对应的搜索结果。如果没有,会将这个搜索请求,也就是这个字符发送给一个分布式缓存集群查找是否有对应的搜索结果。如果还没有,才会将这个请求发送给一个更大规模的搜索引擎集群去查找。
这些分布式缓存集群或者搜索引擎集群都需要通过RPC远程过程调用的方式进行调用请求,也就是需要通过网络进行服务调用,这些网络服务也都是基于TCP协议进行编程的。
对于互联网应用,用户请求数据离开手机通过各种网络通信,最后到达数据中心的应用服务器进行最后的计算、处理,中间会经过许多环节,事实上,这些环节就构成了互联网系统的整体架构,所以通过网络通信,可以将整个互联网应用系统串起来,对理解互联网系统的技术架构很有帮助,在程序开发、运行过程中遇到各种网络相关问题,也可以快速分析问题原因,快速解决问题。
思考题
负载均衡就是将不同的网络请求数据分发到多台服务器上,每台服务器承担一部分请求负载压力,多台服务器共同承担外部并发请求的压力,除了文中提到的这种负载均衡实现方案,你还了解哪些方案呢?
05 文件系统原理:如何用1分钟遍历一个100TB的文件?
文件及硬盘管理是计算机操作系统的重要组成部分,让微软走上成功之路的正是微软最早推出的个人电脑PC操作系统,这个操作系统就叫DOS,即Disk Operating System,硬盘操作系统。我们每天使用电脑都离不开硬盘,硬盘既有大小的限制,通常大一点的硬盘也不过几T,又有速度限制,快一点的硬盘也不过每秒几百M。
文件是存储在硬盘上的,文件的读写访问速度必然受到硬盘的物理限制,那么如何才能1分钟完成一个100T大文件的遍历呢?
想要知道这个问题的答案,我们就必须知道文件系统的原理。
做软件开发时,必然要经常和文件系统打交道,而文件系统也是一个软件,了解文件系统的设计原理,可以帮助我们更好地使用文件系统,另外设计文件系统时的各种考量,也对我们自己做软件设计有诸多借鉴意义。
让我们先从硬盘的物理结构说起。
硬盘
硬盘是一种可持久保存、多次读写数据的存储介质。硬盘的形式主要两种,一种是机械式硬盘,一种是固态硬盘。
机械式硬盘的结构,主要包含盘片、主轴、磁头臂,主轴带动盘片高速旋转,当需要读写盘上的数据的时候,磁头臂会移动磁头到盘片所在的磁道上,磁头读取磁道上的数据。读写数据需要移动磁头,这样一个机械的动作,至少需要花费数毫秒的时间,这是机械式硬盘访问延迟的主要原因。
如果一个文件的数据在硬盘上不是连续存储的,比如数据库的B+树文件,那么要读取这个文件,磁头臂就必须来回移动,花费的时间必然很长。如果文件数据是连续存储的,比如日志文件,那么磁头臂就可以较少移动,相比离散存储的同样大小的文件,连续存储的文件的读写速度要快得多。
机械式硬盘的数据就存储在具有磁性特质的盘片上,因此这种硬盘也被称为磁盘,而固态硬盘则没有这种磁性特质的存储介质,也没有电机驱动的机械式结构。
其中主控芯片处理端口输入的指令和数据,然后控制闪存颗粒进行数据读写。由于固态硬盘没有了机械式硬盘的电机驱动磁头臂进行机械式物理移动的环节,而是完全的电子操作,因此固态硬盘的访问速度远快于机械式硬盘。
但是,到目前为止固态硬盘的成本还是明显高于机械式硬盘,因此在生产环境中,最主要的存储介质依然是机械式硬盘。如果一个场景对数据访问速度、存储容量、成本都有较高要求,那么可以采用固态硬盘和机械式硬盘混合部署的方式,即在一台服务器上既有固态硬盘,也有机械式硬盘,以满足不同文件类型的存储需求,比如日志文件存储在机械式硬盘上,而系统文件和随机读写的文件存储在固态硬盘上。
文件系统
作为应用程序开发者,我们不需要直接操作硬盘,而是通过操作系统,以文件的方式对硬盘上的数据进行读写访问。文件系统将硬盘空间以块为单位进行划分,每个文件占据若干个块,然后再通过一个文件控制块FCB记录每个文件占据的硬盘数据块。
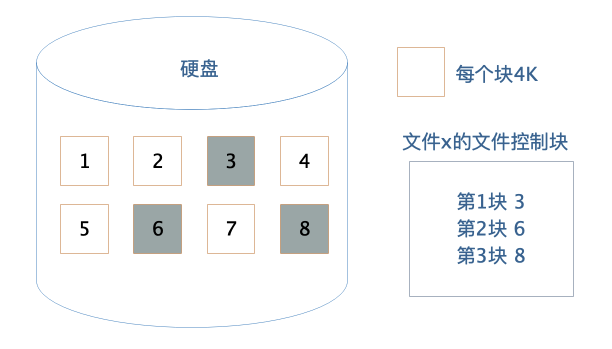
这个文件控制块在Linux操作系统中就是inode,要想访问文件,就必须获得文件的inode信息,在inode中查找文件数据块索引表,根据索引中记录的硬盘地址信息访问硬盘,读写数据。
inode中记录着文件权限、所有者、修改时间和文件大小等文件属性信息,以及文件数据块硬盘地址索引。inode是固定结构的,能够记录的硬盘地址索引数也是固定的,只有15个索引。其中前12个索引直接记录数据块地址,第13个索引记录索引地址,也就是说,索引块指向的硬盘数据块并不直接记录文件数据,而是记录文件数据块的索引表,每个索引表可以记录256个索引;第14个索引记录二级索引地址,第15个索引记录三级索引地址,如下图:
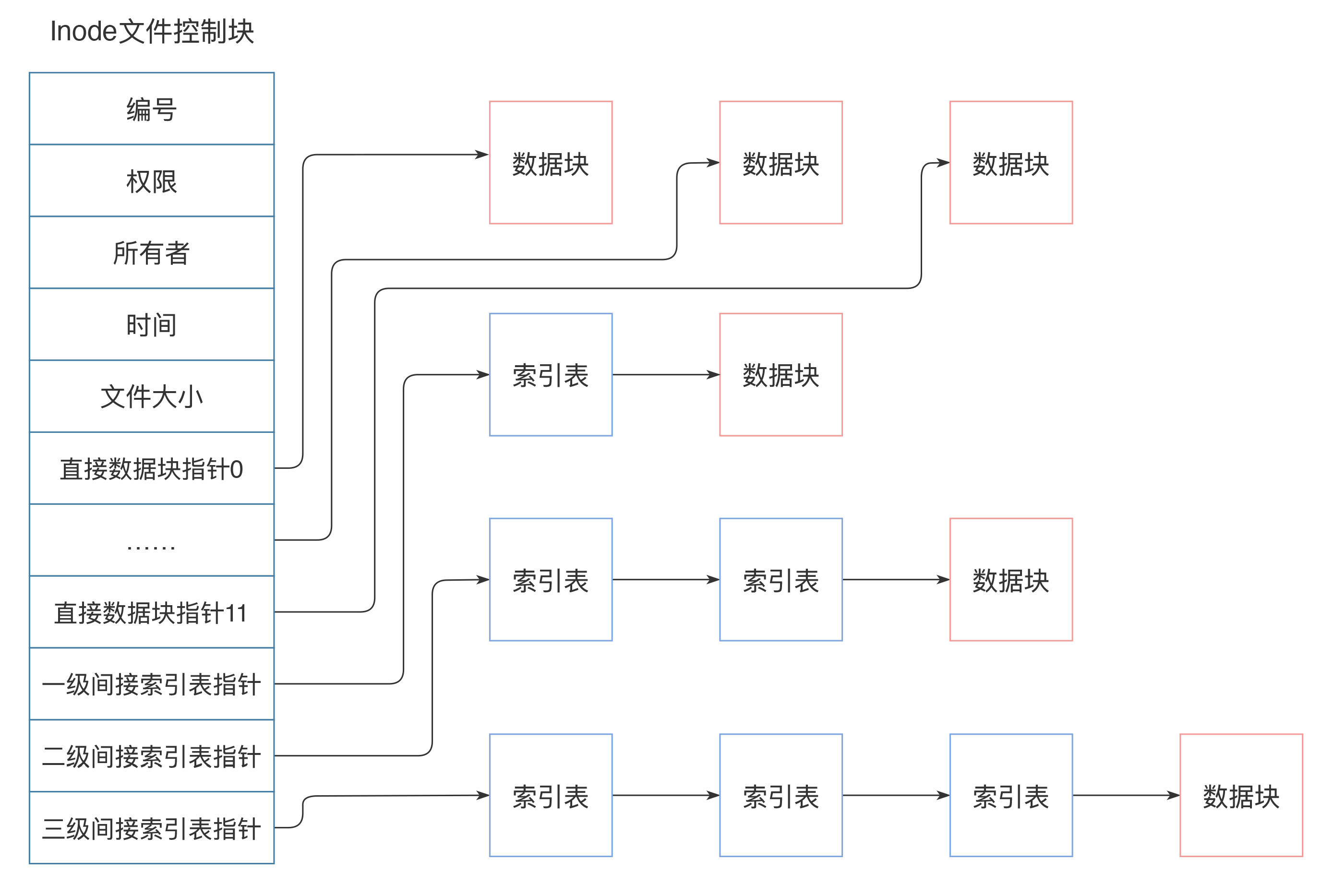 这样,每个inode最多可以存储12+256+256256+256256*256个数据块,如果每个数据块的大小为4k,也就是单个文件最大不超过70G,而且即使可以扩大数据块大小,文件大小也要受单个硬盘容量的限制。这样的话,对于我们开头提出的一分钟完成100T大文件的遍历,Linux文件系统是无法完成的。
这样,每个inode最多可以存储12+256+256256+256256*256个数据块,如果每个数据块的大小为4k,也就是单个文件最大不超过70G,而且即使可以扩大数据块大小,文件大小也要受单个硬盘容量的限制。这样的话,对于我们开头提出的一分钟完成100T大文件的遍历,Linux文件系统是无法完成的。
那么,有没有更给力的解决方案呢?
RAID
RAID,即独立硬盘冗余阵列,将多块硬盘通过硬件RAID卡或者软件RAID的方案管理起来,使其共同对外提供服务。RAID的核心思路其实是利用文件系统将数据写入硬盘中不同数据块的特性,将多块硬盘上的空闲空间看做一个整体,进行数据写入,也就是说,一个文件的多个数据块可能写入多个硬盘。
根据硬盘组织和使用方式不同,常用RAID有五种,分别是RAID 0、RAID 1、RAID 10、RAID 5和RAID 6。
 RAID 0将一个文件的数据分成N片,同时向N个硬盘写入,这样单个文件可以存储在N个硬盘上,文件容量可以扩大N倍,(理论上)读写速度也可以扩大N倍。但是使用RAID 0的最大问题是文件数据分散在N块硬盘上,任何一块硬盘损坏,就会导致数据不完整,整个文件系统全部损坏,文件的可用性极大地降低了。
RAID 0将一个文件的数据分成N片,同时向N个硬盘写入,这样单个文件可以存储在N个硬盘上,文件容量可以扩大N倍,(理论上)读写速度也可以扩大N倍。但是使用RAID 0的最大问题是文件数据分散在N块硬盘上,任何一块硬盘损坏,就会导致数据不完整,整个文件系统全部损坏,文件的可用性极大地降低了。
RAID 1则是利用两块硬盘进行数据备份,文件同时向两块硬盘写入,这样任何一块硬盘损坏都不会出现文件数据丢失的情况,文件的可用性得到提升。
RAID 10结合RAID 0和RAID 1,将多块硬盘进行两两分组,文件数据分成N片,每个分组写入一片,每个分组内的两块硬盘再进行数据备份。这样既扩大了文件的容量,又提高了文件的可用性。但是这种方式硬盘的利用率只有50%,有一半的硬盘被用来做数据备份。
RAID 5针对RAID 10硬盘浪费的情况,将数据分成N-1片,再利用这N-1片数据进行位运算,计算一片校验数据,然后将这N片数据写入N个硬盘。这样任何一块硬盘损坏,都可以利用校验片的数据和其他数据进行计算得到这片丢失的数据,而硬盘的利用率也提高到N-1/N。
RAID 5可以解决一块硬盘损坏后文件不可用的问题,那么如果两块文件损坏?RAID 6的解决方案是,用两种位运算校验算法计算两片校验数据,这样两块硬盘损坏还是可以计算得到丢失的数据片。
实践中,使用最多的是RAID 5,数据被分成N-1片并发写入N-1块硬盘,这样既可以得到较好的硬盘利用率,也能得到很好的读写速度,同时还能保证较好的数据可用性。使用RAID 5的文件系统比简单的文件系统文件容量和读写速度都提高了N-1倍,但是一台服务器上能插入的硬盘数量是有限的,通常是8块,也就是文件读写速度和存储容量提高了7倍,这远远达不到1分钟完成100T文件的遍历要求。
那么,有没有更给力的解决方案呢?
分布式文件系统
我们再回过头看下Linux的文件系统:文件的基本信息,也就是文件元信息记录在文件控制块inode中,文件的数据记录在硬盘的数据块中,inode通过索引记录数据块的地址,读写文件的时候,查询inode中的索引记录得到数据块的硬盘地址,然后访问数据。
如果将数据块的地址改成分布式服务器的地址呢?也就是查询得到的数据块地址不只是本机的硬盘地址,还可以是其他服务器的地址,那么文件的存储容量就将是整个分布式服务器集群的硬盘容量,这样还可以在不同的服务器上同时并行读取文件的数据块,文件访问速度也将极大的加快。
这样的文件系统就是分布式文件系统,分布式文件系统的思路其实和RAID是一脉相承的,就是将数据分成很多片,同时向N台服务器上进行数据写入。针对一片数据丢失就导致整个文件损坏的情况,分布式文件系统也是采用数据备份的方式,将多个备份数据片写入多个服务器,以保证文件的可用性。当然,也可以采用RAID 5的方式通过计算校验数据片的方式提高文件可用性。
我们以Hadoop分布式文件系统HDFS为例,看下分布式文件系统的具体架构设计。
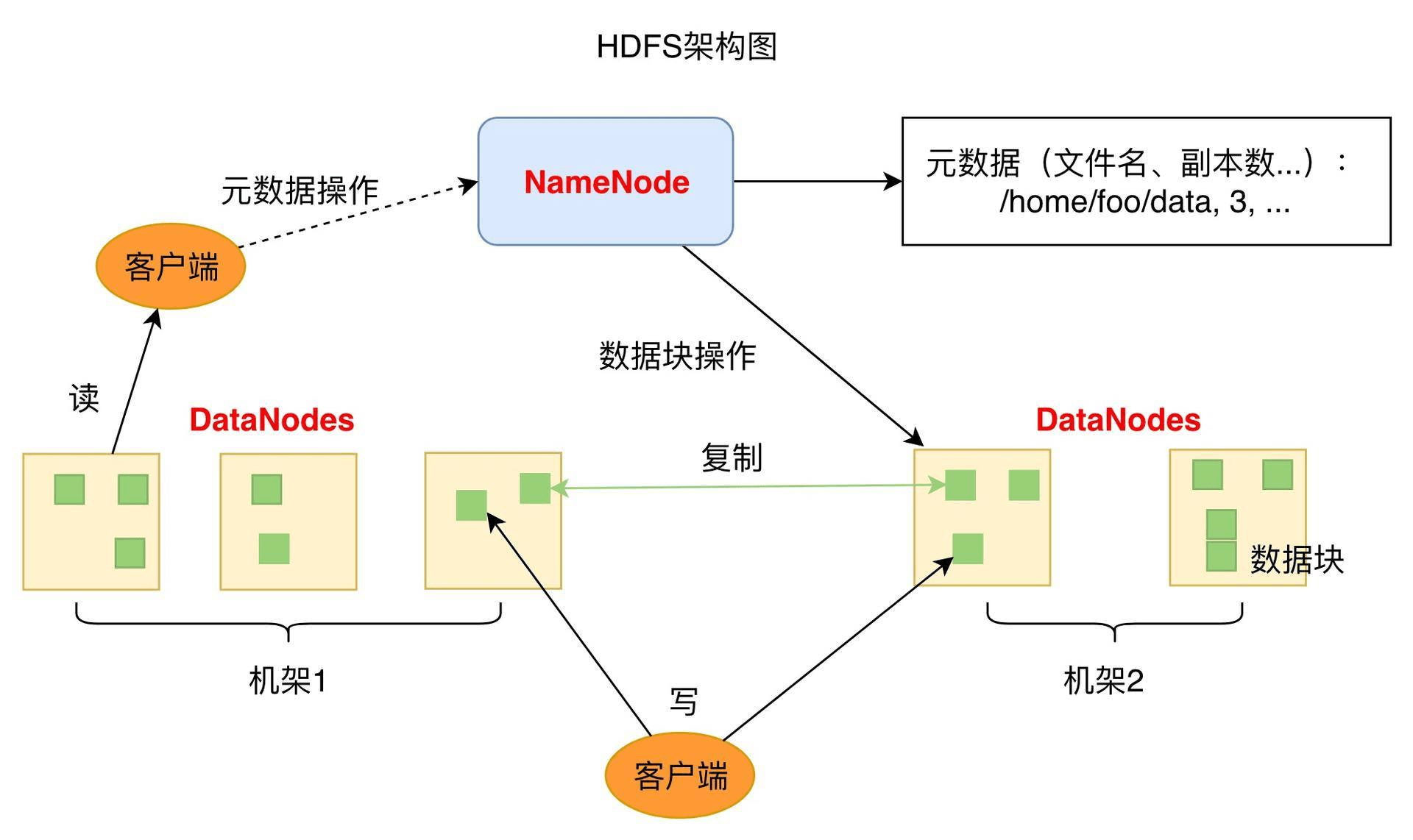
HDFS的关键组件有两个,一个是DataNode,一个是NameNode。
DataNode负责文件数据的存储和读写操作,HDFS将文件数据分割成若干数据块(Block),每个DataNode存储一部分数据块,这样文件就分布存储在整个HDFS服务器集群中。应用程序客户端(Client)可以并行对这些数据块进行访问,从而使得HDFS可以在服务器集群规模上实现数据并行访问,极大地提高了访问速度。在实践中,HDFS集群的DataNode服务器会有很多台,一般在几百台到几千台这样的规模,每台服务器配有数块硬盘,整个集群的存储容量大概在几PB到数百PB。
NameNode负责整个分布式文件系统的元数据(MetaData)管理,也就是文件路径名、访问权限、数据块的ID以及存储位置等信息,相当于Linux系统中inode的角色。HDFS为了保证数据的高可用,会将一个数据块复制为多份(缺省情况为3份),并将多份相同的数据块存储在不同的服务器上,甚至不同的机架上。这样当有硬盘损坏,或者某个DataNode服务器宕机,甚至某个交换机宕机,导致其存储的数据块不能访问的时候,客户端会查找其备份的数据块进行访问。
有了HDFS,可以实现单一文件存储几百T的数据,再配合大数据计算框架MapReduce或者Spark,可以对这个文件的数据块进行并发计算。也可以使用Impala这样的SQL引擎对这个文件进行结构化查询,在数千台服务器上并发遍历100T的数据,1分钟都是绰绰有余的。
小结
文件系统从简单操作系统文件,到RAID,再到分布式文件系统,其设计思路其实是具有统一性的。这种统一性一方面体现在文件数据如何管理,也就是如何通过文件控制块管理文件的数据,这个文件控制块在Linux系统中就是inode,在HDFS中就是NameNode。
另一方面体现在如何利用更多的硬盘实现越来越大的文件存储需求和越来越快的读写速度需求,也就是将数据分片后同时写入多块硬盘。单服务器我们可以通过RAID来实现,多服务器则可以将这些服务器组成一个文件系统集群,共同对外提供文件服务,这时候,数千台服务器的数万块硬盘以单一存储资源的方式对文件使用者提供服务,也就是一个文件可以存储数百T的数据,并在一分钟完成这样一个大文件的遍历。
思考题
在RAID 5的示意图中,P表示校验位数据,我们看到P不是单独存储在一块硬盘上,而是分散在不同的盘上,实际上,校验数据P的存储位置是螺旋式地落在所有硬盘上的,为什么要这样设计?
06 数据库原理:为什么PrepareStatement性能更好更安全?
做应用开发的同学常常觉得数据库由DBA运维,自己会写SQL就可以了,数据库原理不需要学习。其实即使是写SQL也需要了解数据库原理,比如我们都知道,SQL的查询条件尽量包含索引字段,但是为什么呢?这样做有什么好处呢?你也许会说,使用索引进行查询速度快,但是为什么速度快呢?
此外,我们在Java程序中访问数据库的时候,有两种提交SQL语句的方式,一种是通过Statement直接提交SQL;另一种是先通过PrepareStatement预编译SQL,然后设置可变参数再提交执行。
Statement直接提交的方式如下:
statement.executeUpdate("UPDATE Users SET stateus = 2 WHERE userID=233");
PrepareStatement预编译的方式如下:
PreparedStatement updateUser = con.prepareStatement("UPDATE Users SET stateus = ? WHERE userID = ?");
updateUser.setInt(1, 2);
updateUser.setInt(2,233);
updateUser.executeUpdate();
看代码,似乎第一种方式更加简单,但是编程实践中,主要用第二种。使用MyBatis等ORM框架时,这些框架内部也是用第二种方式提交SQL。那为什么要舍简单而求复杂呢?
要回答上面这些问题,都需要了解数据库的原理,包括数据库的架构原理与数据库文件的存储原理。
数据库架构与SQL执行过程
我们先看看数据库架构原理与SQL执行过程。
关系数据库系统RDBMS有很多种,但是这些关系数据库的架构基本上差不多,包括支持SQL语法的Hadoop大数据仓库,也基本上都是相似的架构。一个SQL提交到数据库,经过连接器将SQL语句交给语法分析器,生成一个抽象语法树AST;AST经过语义分析与优化器,进行语义优化,使计算过程和需要获取的中间数据尽可能少,然后得到数据库执行计划;执行计划提交给具体的执行引擎进行计算,将结果通过连接器再返回给应用程序。

应用程序提交SQL到数据库执行,首先需要建立与数据库的连接,数据库连接器会为每个连接请求分配一块专用的内存空间用于会话上下文管理。建立连接对数据库而言相对比较重,需要花费一定的时间,因此应用程序启动的时候,通常会初始化建立一些数据库连接放在连接池里,这样当处理外部请求执行SQL操作的时候,就不需要花费时间建立连接了。
这些连接一旦建立,不管是否有SQL执行,都会消耗一定的数据库内存资源,所以对于一个大规模互联网应用集群来说,如果启动了很多应用程序实例,这些程序每个都会和数据库建立若干个连接,即使不提交SQL到数据库执行,也就会对数据库产生很大的压力。
所以应用程序需要对数据库连接进行管理,一方面通过连接池对连接进行管理,空闲连接会被及时释放;另一方面微服务架构可以大大减少数据库连接,比如对于用户数据库来说,所有应用都需要连接到用户数据库,而如果划分一个用户微服务并独立部署一个比较小的集群,那么就只有这几个用户微服务实例需要连接用户数据库,需要建立的连接数量大大减少。
连接器收到SQL以后,会将SQL交给语法分析器进行处理,语法分析器工作比较简单机械,就是根据SQL语法规则生成对应的抽象语法树。
如果SQL语句中存在语法错误,那么在生成语法树的时候就会报错,比如,下面这个例子中SQL语句里的where拼写错误,MySQL就会报错。
mysql> explain select * from users whee id = 1;ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'id = 1' at line 1
因为语法错误是在构建抽象语法树的时候发现的,所以能够知道,错误是发生在哪里。上面例子中,虽然语法分析器不能知道whee是一个语法拼写错误,因为这个whee可能是表名users的别名,但是语法分析器在构建语法树到了id=1这里的时候就出错了,所以返回的报错信息可以提示,在'id = 1'附近有语法错误。
语法分析器生成的抽象语法树并不仅仅可以用来做语法校验,它也是下一步处理的基础。语义分析与优化器会对抽象语法树进一步做语义优化,也就是在保证SQL语义不变的前提下,进行语义等价转换,使最后的计算量和中间过程数据量尽可能小。
比如对于这样一个SQL语句,其语义是表示从users表中取出每一个id和order表当前记录比较,是否相等。
select f.id from orders f where f.user_id = (select id from users);
事实上,这个SQL语句在语义上等价于下面这条SQL语句,表间计算关系更加清晰。
select f.id from orders f join users u on f.user_id = u.id;
SQL语义分析与优化器就是要将各种复杂嵌套的SQL进行语义等价转化,得到有限几种关系代数计算结构,并利用索引等信息进一步进行优化。可以说,各个数据库最黑科技的部分就是在优化这里了。
语义分析与优化器最后会输出一个执行计划,由执行引擎完成数据查询或者更新。MySQL执行计划的例子如下:

执行引擎是可替换的,只要能够执行这个执行计划就可以了。所以MySQL有多种执行引擎(也叫存储引擎)可以选择,缺省的是InnoDB,此外还有MyISAM、Memory等,我们可以在创建表的时候指定存储引擎。大数据仓库Hive也是这样的架构,Hive输出的执行计划可以在Hadoop上执行。
使用PrepareStatement执行SQL的好处
好了,了解了数据库架构与SQL执行过程之后,让我们回到开头的问题,应用程序为什么应该使用PrepareStatement执行SQL?
这样做主要有两个好处。
一个是PrepareStatement会预先提交带占位符的SQL到数据库进行预处理,提前生成执行计划,当给定占位符参数,真正执行SQL的时候,执行引擎可以直接执行,效率更好一点。
另一个好处则更为重要,PrepareStatement可以防止SQL注入攻击。假设我们允许用户通过App输入一个名字到数据中心查找用户信息,如果用户输入的字符串是Frank,那么生成的SQL是这样的:
select * from users where username = 'Frank';
但是如果用户输入的是这样一个字符串:
Frank';drop table users;--
那么生成的SQL就是这样的:
select * from users where username = 'Frank';drop table users;--';
这条SQL提交到数据库以后,会被当做两条SQL执行,一条是正常的select查询SQL,一条是删除users表的SQL。黑客提交一个请求然后users表被删除了,系统崩溃了,这就是SQL注入攻击。
如果用Statement提交SQL就会出现这种情况。
但如果用PrepareStatement则可以避免SQL被注入攻击。因为一开始构造PrepareStatement的时候就已经提交了查询SQL,并被数据库预先生成好了执行计划,后面黑客不管提交什么样的字符串,都只能交给这个执行计划去执行,不可能再生成一个新的SQL了,也就不会被攻击了。
select * from users where username = ?;
数据库文件存储原理
回到文章开头提出的另一个问题,数据库通过索引进行查询能加快查询速度,那么,为什么索引能加快查询速度呢?
数据库索引使用B+树,我们先看下B+树这种数据结构。B+树是一种N叉排序树,树的每个节点包含N个数据,这些数据按顺序排好,两个数据之间是一个指向子节点的指针,而子节点的数据则在这两个数据大小之间。
如下图。
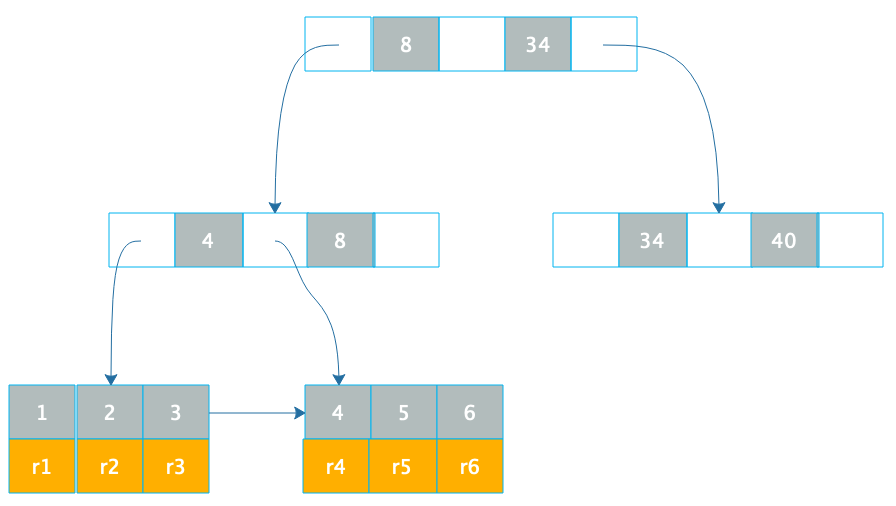
B+树的节点存储在磁盘上,每个节点存储1000多个数据,这样树的深度最多只要4层,就可存储数亿的数据。如果将树的根节点缓存在内存中,则最多只需要三次磁盘访问就可以检索到需要的索引数据。
B+树只是加快了索引的检索速度,如何通过索引加快数据库记录的查询速度呢?
数据库索引有两种,一种是聚簇索引,聚簇索引的数据库记录和索引存储在一起,上面这张图就是聚簇索引的示意图,在叶子节点,索引1和记录行r1存储在一起,查找到索引就是查找到数据库记录。像MySQL数据库的主键就是聚簇索引,主键ID和所在的记录行存储在一起。MySQL的数据库文件实际上是以主键作为中间节点,行记录作为叶子节点的一颗B+树。
另一种数据库索引是非聚簇索引,非聚簇索引在叶子节点记录的就不是数据行记录,而是聚簇索引,也就是主键,如下图。
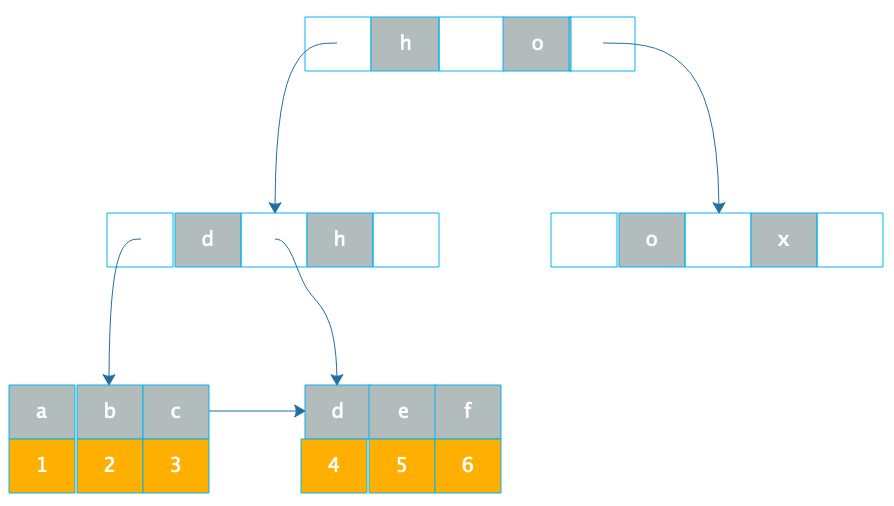 通过B+树在叶子节点找到非聚簇索引a,和索引a在一起存储的是主键1,再根据主键1通过主键(聚簇)索引就可以找到对应的记录r1,这种通过非聚簇索引找到主键索引,再通过主键索引找到行记录的过程也被称作回表。
通过B+树在叶子节点找到非聚簇索引a,和索引a在一起存储的是主键1,再根据主键1通过主键(聚簇)索引就可以找到对应的记录r1,这种通过非聚簇索引找到主键索引,再通过主键索引找到行记录的过程也被称作回表。
所以通过索引,可以快速查询到需要的记录,而如果要查询的字段上没有建索引,就只能扫描整张表了,查询速度就会慢很多。
数据库除了索引的B+树文件,还有一些比较重要的文件,比如事务日志文件。
数据库可以支持事务,一个事务对多条记录进行更新,要么全部更新,要么全部不更新,不能部分更新,否则像转账这样的操作就会出现严重的数据不一致,可能会造成巨大的经济损失。数据库实现事务主要就是依靠事务日志文件。
在进行事务操作时,事务日志文件会记录更新前的数据记录,然后再更新数据库中的记录,如果全部记录都更新成功,那么事务正常结束,如果过程中某条记录更新失败,那么整个事务全部回滚,已经更新的记录根据事务日志中记录的数据进行恢复,这样全部数据都恢复到事务提交前的状态,仍然保持数据一致性。
此外,像MySQL数据库还有binlog日志文件,记录全部的数据更新操作记录,这样只要有了binlog就可以完整复现数据库的历史变更,还可以实现数据库的主从复制,构建高性能、高可用的数据库系统,我将会在架构模块进一步为你讲述。
小结
做应用开发需要了解RDBMS的架构原理,但是关系数据库系统非常庞大复杂,对于一般的应用开发者而言,全面掌握关系数据库的各种实现细节,代价高昂,也没有必要。我们只需要掌握数据库的架构原理与执行过程,数据库文件的存储原理与索引的实现方式,以及数据库事务与数据库复制的基本原理就可以了。然后,在开发工作中针对各种数据库问题去思考,其背后的原理是什么,应该如何处理。通过这样不断地思考学习,不但能够让使用数据库方面的能力不断提高,也能对数据库软件的设计理念也会有更深刻的认识,自己软件设计与架构的能力也会得到加强。
思考题
索引可以提高数据库的查询性能,那么是不是应该尽量多的使用索引呢?如果不是,为什么?你还了解哪些改善数据库访问性能的技巧方法?
07 编程语言原理:面向对象编程是编程的终极形态吗?
软件架构师必须站在一个很高的高度去审视自己软件的架构,去理解自己的工作在更宏大的背景中的位置和作用,才能构建出一个经得起时间考验的软件系统。这个高度既包括技术的高度和深度,也包括对软件编程这件事认知的程度,比如对软件编程的历史和未来的理解,以及对自己工作的价值和使命感的理解。
计算机软件编程是个非常新兴的行业,程序员这一职业的出现不过半个多世纪,但是人类从事软件编程的探索却要久远得多,在计算机出现之前,甚至蒸汽机出现之前,人类就开始探索软件编程了。
最早开始编程探索的人是德国人莱布尼兹,早在1700年代,莱布尼兹就期望将各种事物都通过一种逻辑语言进行描述,然后用一种可执行演算规则的机器进行计算,就可以计算出事物的各种结果。这种思想其实和我们现代的软件编程与计算机已经差不多了,莱布尼兹为了实现这个想法,进行了大量的工作,获得了丰硕的成果,其中就包括了微积分和二进制。
但是人不能超越自己的时代,莱布尼兹制造可编程计算机的梦想并没有成功。又过了100年,法国人雅卡尔发明了一台可编程的织布机,这种织布机通过读取纸带上的打孔,进而控制织布机织出不同的图案。于是人们开始尝将打孔纸带用于计算机编程,19世纪中叶,当英国人Ada利用打孔纸带写出人类第一个软件程序的时候,距能够运行这个程序的计算机的发明还有100年的时间,而这个程序已经包含了循环和子程序。Ada因此被认为是人类第一个程序员,准确的说,是程序媛。科技发明受时代的限制,天才们的想象力和聪明才智却可以超越时代。
人类发明制造计算机器有非常悠久的历史,但是这些计算机器都是专门进行数值计算的,加减乘除、微分积分等等。而从莱布尼兹、Ada,到图灵、冯诺依曼,这些现代计算机的开创者们试图创造的是一种通用的计算机,这种计算机不是读取数值进行计算,而是读取数据进行计算,这些数据本身包含着计算的逻辑,这个数据就是程序。当冯诺依曼在ENIAC计算机上输入第一个程序的时候,标志着现代计算机的诞生,也意味着软件编程这一新兴的行业即将出现。信息时代、互联网时代接踵而至,人类开启了有史以来最大的一次科技革命。
现在我们编程已经习惯打开IDE,编写程序代码然后编译执行或者解释执行,认为编程就该如此。觉得那些不需要IDE,只需要写字板或者Vim就可以编程的人就是大牛了。事实上,最早的计算机编程非常麻烦,程序员需要将电线编来编去,输入数据,以控制计算机的执行,这也是编程这个词的由来。不过很快人们就将打孔纸带应用到计算机上,编程的效率极大提升。
接近我们现在理解的软件编程要追溯到1949年,随着第一台可存储程序的计算机的发明而出现,程序员终于可以写代码了。这个阶段的程序要需要牢记计算机指令的二进制编码,软件开发就是直接使用这些二进制指令进行编程,每个计算机指令后面要带操作数,操作数也是二进制编码,所有这些二进制就是程序的代码,由程序员输入到计算机中。
现在的程序员们光是听听早期软件编程这一番神操作怕是就崩溃了,早期的程序员也意识到这一点,宝贵的时间不应该浪费在记忆计算机指令的二进制编码上,于是他们发明了汇编语言。和使用机器指令二进制编码唯一的不同就是,汇编语言提供了机器指令助记符,编程的时候,机器指令二进制可以用助记符代替。但是软件编程依然需要使用计算机指令,一个指令一个指令进行编程。因此,机器指令二进制编程和汇编语言编程本质上都是面向机器的编程。汇编语言程序如下,这已经是PC时代的汇编语言程序了,早期计算机的汇编程序要更加古老。
2000: BMI $2009 ;若结果为负数,那么转地址2009
2002: BEQ $200C ;若 = 0,转 地址200C
2004: CLC ;这里说明 > 0
2005: ADC #$01
2007: TAY
2008: RTS
2009: LDY #$01
200B: RTS
200C: LDY #$00
200E: RTS
在计算机出现的早期,即使对程序员而言,计算机也是一个神奇的存在,同一台计算机,可以进行科学计算,也可以进行弹道轨迹计算,还可以进行财务核算计算。计算机强大、神奇且昂贵,程序员匍匐在计算机的脚下,使用计算机的指令进行编程,面向机器编程。但是随着计算机技术的不断发展和计算机的普及,程序员们逐渐意识到,计算机本身呆板而机械,真正强大、无所不能的是软件程序。程序员为了更高效地进行编程,应该采用一种对程序员更加友好的编程方式,一种更接近人类语言的编程语言,于是各种各样的高级编程语言出现了。
最早的高级编程语言是Fortran,这是一种专门用于科学计算的高级语言,诞生于1957年。但是真正主流的、被广泛使用的各种高级语言则诞生于1970年前后,其中就包括C语言,传说丹尼斯·里奇发明了C语言,然后为了验证C语言的特性,开发了一个Demo,就是Unix操作系统。
那个年代美国正陷于越战的泥潭,大量的美国青年魂断东南亚的丛林,更多的美国青年则在国内聚集起来,集会、示威、游行,他们要独立、自由、和平,他们有的人背着吉他,从一个城市流浪到另一个城市,而另一些人则坐在计算机终端前面,摆脱了对计算机指令的束缚,使用高级编程语言进行软件编程,用另一种方式表达独立和自由。这些高级语言使用人类语言作为编程指令,if…else…,while…break…,for…goto…,这些语句更符合人类的习惯和逻辑思维方式,由于这些语言关注逻辑处理过程,所以也被称作面向过程的编程语言。事实上,这些语言的本质是面向人的,因此这一时期爆发的各种编程语言本质上说是面向人的编程语言,准确的说,是面向程序员的编程语言。Basic编程语言示例:
INPUT "What is your name: ", UserName$
PRINT "Hello "; UserName$
DOINPUT "How many stars do you want: ", NumStarsStars$ = STRING$(NumStars, "*")PRINT Stars$DOINPUT "Do you want more stars? ", Answer$LOOP UNTIL Answer$ <> ""Answer$ = LEFT$(Answer$, 1)
LOOP WHILE UCASE$(Answer$) = "Y"
PRINT "Goodbye "; UserName$
高级编程语言的普及极大地释放了程序员的自主性,软件开发迎来黄金时期,程序员的第一个极客时代到来,比尔·盖茨、乔布斯都是在那个时代成长起来的。但是人的欲望是没有止境的,人能做到的越多,想得到的也就越多,越来越庞大的软件开发计划被不断地提了出来。
但是面向过程的复杂性随着软件规模的膨胀以更快的速度膨胀。面向过程的软件关注逻辑流程,更容易被设计成面条式程序,长长的过程调用执行,像一根面条。而大型项目最后由这样一根一根面条组成,就成了一个毛线团,最后谁也理不清了。于是很多大型软件的开发过程开始失控,最终以失败告终,人们遇到了软件危机。
软件危机使人们开始重新审视软件编程这件事情的本质,除了一部分科学计算或者其他特定目的的软件,大部分的软件是为了解决现实世界的问题,企业的库存管理、银行的账务处理等等。所以,软件编程的本质是程序员用代码的方式使现实世界的事务运行在计算机上,计算机软件是为了解决现实世界的问题而开发出来的,那么软件编程这件事情应该关注的重点是客观世界的事物本身,而不是程序员的思维方式或者计算机的指令。
如果软件编程的重点是客观世界的事物本身,那么编程语言如何才能更好地满足这一需求?于是,面向对象的编程语言应运而生。面向对象编程以对象作为软件编程的基本单位,提出一切皆对象,客观世界的用户、账号、商品是对象;创建、组合、关联这些对象的工厂、适配器、观察者也是对象;将所有这些对象分析、设计、开发出来,一个软件系统就完成了,这个软件系统灵活、强大,最重要的是可以根据需求变化快速更新维护。Java对象代码示例:
public class User {private String name;private Integer id;public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}
}
我们回顾一下现代编程技术的发展,发现大体经过面向机器编程,面向程序员编程,面向对象编程三个阶段,这正好对应马克思经济学关于劳动力的三个要素:劳动工具-计算机、劳动者-程序员、劳动对象-客观对象。编程从面向劳动工具进化到面向劳动者,再进化到面向对劳动对象。
面向对象编程似乎已经进化到编程这件事情哲学意义上的终点,是编程语言的终极形态。现实看起来也确实如此,最近三十年诞生的编程语言几乎全部都是面向对象的编程语言,面向对象一统天下。
但事实真的如此吗?回望历史我们站在上帝视角,一切都是如此清晰充满条理,凝望未来,我们还能如此笃定吗?
情况也许并非如此。事实上,现实中的面向对象编程几乎从未实现人们期望中的面向对象编程。上面举的Java的User对象示例就是典型,这是一个我们经常见到,却又非常不面向对象的对象。这个对象只有属性,没有行为,现实中的User对象显然不是这样。也许有部分企业和部分程序员做到了真正的面向对象编程,但是绝大多数程序员并没有做到,面向对象编程普及几十年了,如果大多数程序员依然做不到真正意义的面向对象编程,是程序员的问题还是编程语言的问题?
另一方面,一些新出现的面向对象编程语言对对象的态度似乎也有点暧昧,对象的边界和封装性开始模糊。go语言代码示例如下,这里NokiaPhone和iPhone都实现了Phone接口,但是并不是显式的。
type Phone interface {call()
}
type NokiaPhone struct {
}
func (nokiaPhone NokiaPhone) call() {fmt.Println("I am Nokia, I can call you!")
}
type IPhone struct {
}
func (iPhone IPhone) call() {fmt.Println("I am iPhone, I can call you!")
}
而随着科技的不断发展,特别是大数据,人工智能以及移动互联网的发展,面向数据的编程需求越来越多,能够更好迎合这一需求的编程模型开始得到青睐,比如函数式编程。而极客型的程序员对强类型的面向对象编程越来越不感冒,他们希望在编程的时候能够得到更多的自由,编程语言的重心似乎重新出现面向程序员的趋势。
随着计算机性能的不断增强,以及互联网应用对计算资源需求的不断增加,如何更好地利用CPU的多核以及分布式集群的多服务器特性,必须是软件编程以及架构设计时需要考虑的重要问题,软件编程越来越多需要考虑机器本身,相对应的,反应式编程得到越来越多的关注。
辩证唯物主义告诉我们,事物发展轨迹是波浪式前进,螺旋式上升,有的时候似乎重新回到过去,但是却有了本质的区别和进步。软件编程的进化史还在继续,你是否对未来充满期待和信心?
小结
今天我们回顾了编程技术的发展,通过这样的脉络梳理,你能更清楚目前面对对象编程的来源,更好地利用这一技术。如何利用面向对象编程的特性,进行真正的面向对象编程,而不是仅仅利用面向对象编程语言进行编程,我将在第16篇讲解。
思考题
不同的编程语言在不同的应用场景中,各有自己的优势和劣势,你觉得哪些编程语言更适合用在哪些地方,适合处理哪些问题?
答疑 Java Web程序的运行时环境到底是怎样的?
今天是第一模块的最后一讲。在这一讲中,我们主要讲了软件的基础原理,今天,我将会针对这一模块中大家提出的普遍问题进行总结和答疑,让我们整理一下,再接着学习下一个模块的内容。
问题一
@小美 既然一个JVM是一个进程,JVM上跑Tomcat,Tomcat上可以部署多个应用。这样的话,每个跑在Tomcat上的应用是一个线程吗?该怎么理解“如果一个应用crash了,其他应用也会crash”?
理解程序运行时的执行环境,直观感受程序是如何运行的,对我们开发和维护软件很有意义。我们以小美同学提的这个场景为例,看下Java Web程序的运行时环境是什么样的,来重新梳理下进程、线程、应用、Web容器、Java虚拟机和操作系统之间的关系。
我们用Java开发Web应用,开发完成,编译打包以后得到的是一个war包,这个war包放入Tomcat的应用程序路径下,启动Tomcat就可以通过HTTP请求访问这个Web应用了。
在这个场景下,进程是哪个?线程有哪些?Web程序的war包是如何启动的?HTTP请求如何被处理?Tomcat在这里扮演的是什么角色?JVM又扮演什么角色?
首先,我们是通过执行Tomcat的Shell脚本启动Tomcat的,而在Shell脚本里,其实启动的是Java虚拟机,大概是这样一个Shell命令:
java org.apache.catalina.startup.Bootstrap "$@" start
所以我们在Linux操作系统执行Tomcat的Shell启动脚本,Tomcat启动以后,其实在操作系统里看到的是一个JVM虚拟机进程。这个虚拟机进程启动以后,加载class进来执行,首先加载的就这个org.apache.catalina.startup.Bootstrap类,这个类里面有一个main()函数,是整个Tomcat的入口函数,JVM虚拟机会启动一个主线程从这个入口函数开始执行。
主线程从Bootstrap的main()函数开始执行,初始化Tomcat的运行环境,这时候就需要创建一些线程,比如负责监听80端口的线程,处理客户端连接请求的线程,以及执行用户请求的线程。创建这些线程的代码是Tomcat代码的一部分。
初始化运行环境之后,Tomcat就会扫描Web程序路径,扫描到开发的war包后,再加载war包里的类到JVM。因为Web应用是被Tomcat加载运行的,所以我们也称Tomcat为Web容器。
如果有外部请求发送到Tomcat,也就是外部程序通过80端口和Tomcat进行HTTP通信的时候,Tomcat会根据war包中的web.xml配置,决定这个请求URL应该由哪个Servlet处理,然后Tomcat就会分配一个线程去处理这个请求,实际上,就是这个线程执行相应的Servlet代码。
我们回到小美同学的问题,Tomcat启动的时候,启动的是JVM进程,这个进程首先是执行JVM的代码,而JVM会加载Tomcat的class执行,并分配一个主线程,这个主线程会从main函数开始执行。在主线程执行过程中,Tomcat的代码还会启动其他一些线程,包括处理HTTP请求的线程。
而我们开发的应用是一些class,被Tomcat加载到这个JVM里执行,所以,即使这里有多个应用被加载,也只是加载了一些class,我们的应用被加载进来以后,并没有增加JVM进程中的线程数,也就是web应用本身和线程是没有关系的。
而Tomcat会根据HTTP请求URL执行应用中的代码,这个时候,可以理解成每个请求分配一个线程,每个线程执行的都是我们开发的Web代码。如果Web代码中包含了创建新线程的代码,Tomcat的线程在执行代码时,就会创建出新的线程,这些线程也会被操作系统调度执行。
如果Tomcat的线程在执行代码时,代码抛出未处理的异常,那么当前线程就会结束执行,这时控制台看到的异常信息,其实就是线程堆栈信息,线程会把异常信息以及当前堆栈的方法都打印出来。事实上,这个异常最后还是会被Tomcat捕获,然后Tomcat会给客户端返回一个500错误。单个线程的异常不影响其他线程执行,也就是不影响其他请求的处理。
但是如果线程在执行代码的时候,抛出的是JVM错误,比如OutOfMemoryError,这个时候看起来是应用crash,事实上是整个进程都无法继续执行了,也就是进程crash了,进程内所有应用都不会被继续执行了。
从JVM的角度看,Tomcat和我们的Web应用是一样的,都是一些Java代码,但是Tomcat却可以加载执行Web代码,而我们的代码又不依赖Tomcat,这也是一个很有意思的话题。Tomcat是如何设计的,我将会在下个模块讲述。
问题二
@黄海峰 有点难以想象,“Hash表的时间复杂度为什么是O(1)”这个问题居然有阿里大厂的面试官觉得难。
这不是一个疑问,但其实是一个有意思的话题,我们花一点时间讨论下,也许会对你的职业规划有所启发。
文中这个故事大概发生在2009年,整整十年前,那个时候互联网还不像今天这样炙手可热,提供的薪水也不像今天这样有竞争力,也没有BAT这样的专有名词指代所谓的互联网巨头。那个时候,计算机专业优秀的毕业生向往的是微软、Oracle、IBM这样的外资IT巨头,退而求其次,国内好的IT公司是联想、用友这些企业。
事实上,那个时候在技术研发能力上,互联网公司的技术能力也是落后传统企业的,阿里巴巴最核心的数据存储依赖的是IBM、Oracle、EMC的解决方案,即所谓的IOE。
所以在十年前的人才市场上,国内互联网公司的形象一般是:技术落后、薪水一般、加班严重、没有名气。可以说在人才市场的竞争中,相比国内外的IT巨头是落于下风的。
我个人感觉,互联网公司的崛起大概是在七八年前,移动互联网开始出现,互联网的渗透率得到加速,BAT逐渐开始成为家喻户晓的名字,名气大涨。其次,经过前面时间的积累,互联网企业主导的各种分布式技术、大数据技术、移动互联网技术、云计算技术的风头超过传统IT巨头,阿里巴巴开始去IOE,打造自己的云计算平台,成为先进技术的代表者;最主要的还是互联网企业盈利能力大幅增加,能够提供市场上更有竞争力的薪水和股票。
于是互联网企业在人才市场上开始变得灼手可热,BAT这些企业开始被人称为“大厂”。我们今天感觉这些互联网巨头高高在上,人们纷纷向往。事实上,这个现象出现的时间非常短。今天这些企业有足够的名气和资源将自己营造得高高在上,可以在众多优秀的候选人中间挑来选去,仅仅在十年前,还不是这样的。
但是事情真正的吊诡之处还不在这里,当今这些互联网大厂的核心技术和业务模式在十几年前就已经奠定了,经过几年的摸索,大概在七八年前开始稳定成熟。也就是说,互联网企业的技术实力和商业能力是在这些企业还默默无闻的时候就发展起来的,而在这些企业成为明星之后,并没有什么突破性的进展。想想这些所谓的互联网大厂,最近几年,并没有什么值得称道的商业模式创新和技术创新。
也就是说,十多年前,可能是一些并不优秀的技术人员加入一个并不出名的公司,然后这些人开创出了一个杰出的事业。用马云的话说,就是“二流的人做一流的事”。然后公司开始挑选一流的人,但结果似乎只是在维持这个事业,并没有开创出更加杰出的事业。今天的BAT似乎成为当年的IBM,历史好像进入了某种循环。
如果这就是事情的真相,我想你或许可以从其中得到某些启发,重新考虑下未来的职业规划。也许你会发现,你可能不需要追逐当前所谓的热门技术,而应该好好想想需要为自己的未来准备些什么。
最后,在第一模块中,我在每一篇文章的下面都留了几道思考题,各位同学在评论区都有很好的答案。但只有[第五篇文章],我似乎没有看到比较准确的答案,我在这里回答一下。
RAID5中,校验位之所以螺旋式地落在所有硬盘上,主要原因是因为如果将校验位记录在同一块硬盘上,那么对于其他多块数据盘,任何一块硬盘修改数据,都需要修改这个校验盘上的校验数据,也就是说,对于有8块硬盘的RAID5阵列,校验盘的数据写入压力是其他数据盘的7倍。而硬盘的频繁写入会导致硬盘寿命缩短,校验盘会频繁损坏,存储的整体可用性和维护性都会变差。
所以,作为软件架构师,当你在进行软件设计的时候,你不光需要考虑软件本身,你还需要了解软件的各种约束,硬盘的特性约束是一种,当然还有其他一些约束,我会在专栏的后面模块中继续讲解如何在各种约束下,设计出符合期望的软件系统。