从定性到量化:为何指标是非功能性需求的灵魂与尺度
在软件系统的构建过程中,区分“做什么”与“做得如何”至关重要。功能性需求定义了“做什么”,是系统的核心业务逻辑;而非功能性需求则定义了“做得如何”,是系统在特定约束下表现出的质量属性。本文将深入剖析,为何量化指标(Metrics)更多地与非功能性需求相关联,而非功能性需求。我们将通过需求定义的演进、技术发展的驱动力、生活化案例的类比以及具体的代码示例,揭示这一现象背后的深层逻辑,并阐述其对于构建现代高可用、高性能互联网架构的不可或缺性。
需求的维度——定性、定量与度量的精进
在深入探讨之前,我们必须清晰地理解三种不同层次的需求描述方式,这直接关系到后续的设计、测试和运维。

定性描述:模糊的愿景
-
示例:“The system should allow multiple users to login concurrently.”
-
解读:这是一个纯粹的非功能性需求(涉及性能与并发能力),但它采用了定性描述。它只指明了方向——“多用户”、“同时”,但没有提供任何可验证、可测量的标准。“多”是多少?10个还是10万个?系统在达到这个“多”的时候,应该表现出怎样的行为?
存在的问题:
-
不可验证:开发完成后,测试人员无法判定这个需求是否被满足。你说“多用户”我用了10个用户登录成功了,算满足吗?可能算,但产品经理可能期望的是1000个。
-
歧义性:“并发”可能被理解为同一秒内,也可能被理解为一分钟内。这种模糊性是项目延期、扯皮和失败的温床。
-
无法指导设计与采购:架构师无法根据“多用户”来决定需要多少台服务器、多大的数据库连接池。采购部门也无法确定需要购买多高性能的硬件。
带测量的定量描述:迈向精确的第一步
-
示例:“The system should allow 10000 users to login concurrently.”
-
解读:这里我们有了一个定量的数字——
10000。这是一个巨大的进步,它明确了一个容量目标。
进步与遗留问题:
-
可验证性:我们可以通过压力测试,模拟10000个用户同时点击登录按钮,来验证系统是否崩溃或能否成功处理。
-
指导性:架构师可以基于这个数字进行初步的容量规划。
-
遗留的模糊性:“并发”在这里依然是一个模糊的时间概念。是同一毫秒?还是一秒钟内?此外,我们只关注了“能否登录”,但没有关注“登录得怎么样”。系统在处理这10000个并发登录时,响应时间是多少?CPU使用率是否爆满?是否出现了大量错误?如果响应时间长达30秒,虽然技术上登录“成功”了,但用户体验是不可接受的。
带测量与指标的定量描述:工程化的成熟标志
-
示例:“The system should allow 10000 users to login concurrently every minute, with a 99.9% success rate and an average response time under 100ms.”
-
解读:这是需求描述的终极形态,也是非功能性需求的完整表达。
-
定量测量:
10000 users,every minute(明确了时间窗口)。 -
量化指标:
-
成功率:
99.9%(可靠性指标) -
响应时间:
average under 100ms(性能指标)
-
-
为什么这是灵魂所在?
现在,这个需求变得可测试、可监控、可保障。
-
测试:我们可以在预生产环境构造每分钟10000次登录请求的流量,持续运行一段时间,然后观察监控系统,看成功率是否稳定在99.9%以上,平均响应时间是否低于100ms。
-
监控:在线上的生产环境中,我们可以实时采集这些指标(成功率、响应时间)。一旦指标异常(如成功率跌至99%,或响应时间超过200ms),监控系统会自动告警,工程师可以立即介入。
-
指导架构设计:这个明确的目标直接决定了技术选型。例如,为了达到100ms的响应时间,我们可能需要在登录流程中引入缓存(Redis)来存储会话信息,而不是所有请求都访问慢速的关系型数据库。
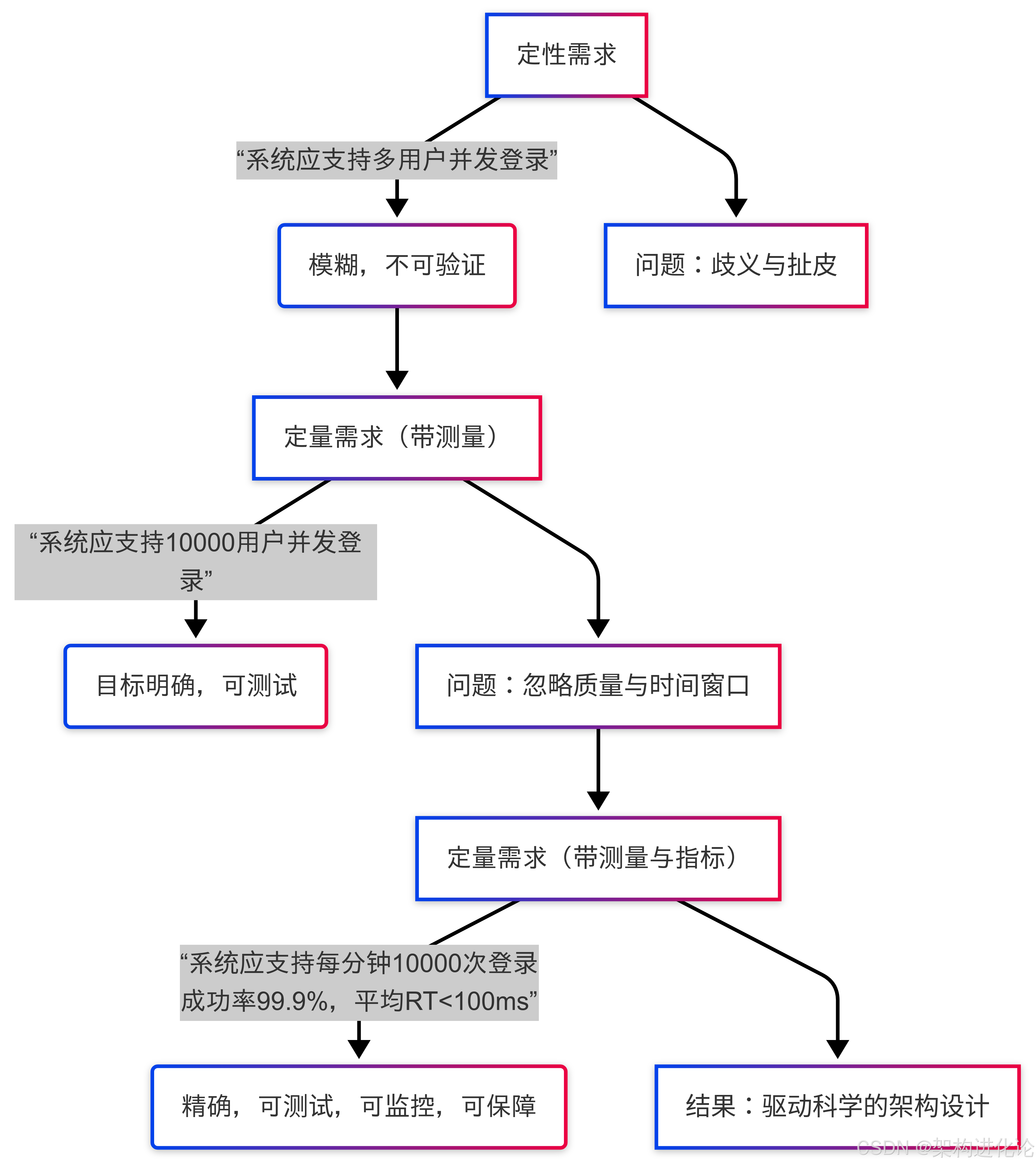
结论:功能性需求通常关注业务状态的正确性(如:“登录成功后,用户状态应变为‘已登录’”),其验证往往是通过断言结果是“是”或“否”来实现的。而非功能性需求(性能、可用性、扩展性等)本质上是关于程度和质量的,这就天然地需要指标这个可以度量“程度”和“质量”的工具来描述和约束。因此,指标更多地与非功能性需求相伴相生。
技术的演进——从单机怪兽到分布式巨兽的驱动力
为什么我们需要如此执着于为NFRs定义精确的指标?这背后是互联网业务形态和技术架构的深刻变革。
史前时代:单体应用与模糊感知
-
技术背景:早期的Web应用,如LAMP(Linux + Apache + MySQL + PHP)栈,通常部署在单台或少数几台服务器上。用户量有限,业务逻辑简单。
-
存在的问题:
-
“跑起来就行”:核心目标是实现功能。性能问题往往通过“堆硬件”来解决。因为系统简单,瓶颈相对容易通过经验判断(比如数据库慢查询)。
-
缺乏监控:对系统的健康状况了解甚少,通常是在用户投诉“网站很慢”之后,开发人员才通过查看日志来被动排查问题。
-
容量规划拍脑袋:对于用户增长,没有数据支撑,只能凭感觉预估。
-
Web 2.0时代:并发挑战与监控萌芽
-
技术驱动力:博客、社交网络、电商兴起。用户生成内容(UGC)导致读写压力激增。并发用户从几百上千上升到数万级别。
-
出现的问题:
-
瓶颈转移:数据库首先成为瓶颈,接着是应用服务器。简单的“堆硬件”成本高昂且效果递减。
-
技术解决方案:
-
缓存:引入Memcached、Redis,缓解数据库读压力。
-
读写分离:数据库主从复制,分担读流量。
-
负载均衡:使用Nginx、HAProxy将流量分发到多个应用服务器实例。
-
-
-
为什么需要指标?
当系统从单体拆分为多个组件后,问题定位变得异常困难。一个用户请求慢,可能是负载均衡器、某个应用实例、缓存集群或数据库从库任何一个环节出了问题。没有指标,就如同在黑暗中摸索。此时,应用性能管理(APM)工具和系统监控(如Zabbix, Nagios)开始变得重要,它们负责采集各个维度的指标。
云原生与微服务时代:复杂性爆炸与指标驱动
-
技术背景:系统被拆分为数十甚至上百个微服务。每个服务独立开发、部署和扩展。容器化(Docker)和编排(Kubernetes)成为标配。
-
出现的问题:
-
分布式复杂性:一个外部请求可能内部调用几十个微服务。任何一个服务的抖动都可能导致整个请求链路的雪崩。
-
故障常态化:在如此大规模的分布式系统中,硬件故障、网络抖动、服务异常是常态,而非例外。
-
弹性伸缩:流量洪峰可能来自促销活动或社交媒体热点,系统需要能够自动快速扩容。
-
-
为什么指标成为生命线?
-
可观测性:指标(Metrics)、日志(Logs)和链路追踪(Traces)构成了可观测性的三大支柱。指标是其中最核心、用于宏观态势感知和告警的部分(扩展阅读:非功能需求:构建高可用架构的隐形基石、软件架构中的隐形支柱:如何避免非功能性需求陷阱、微服务可观测性的“1-3-5”理想:从理论到实践的故障恢复体系、微服务架构的可观测性三要素:从监控到洞察的架构演进)。
-
自动化决策:Kubernetes的Horizontal Pod Autoscaler(HPA)需要依赖CPU使用率、QPS等指标来决定是否扩容或缩容微服务实例。
-
智能告警:基于指标的智能阈值(如动态基线)可以更早、更准确地发现系统异常。
-
SLA/SLI/SLO:服务等级协议(SLA)是向客户做出的承诺,而服务等级指标(SLI)和服务等级目标(SLO)则是内部衡量和保障SLA的量化体系。所有这些,都建立在精确的指标之上。
-
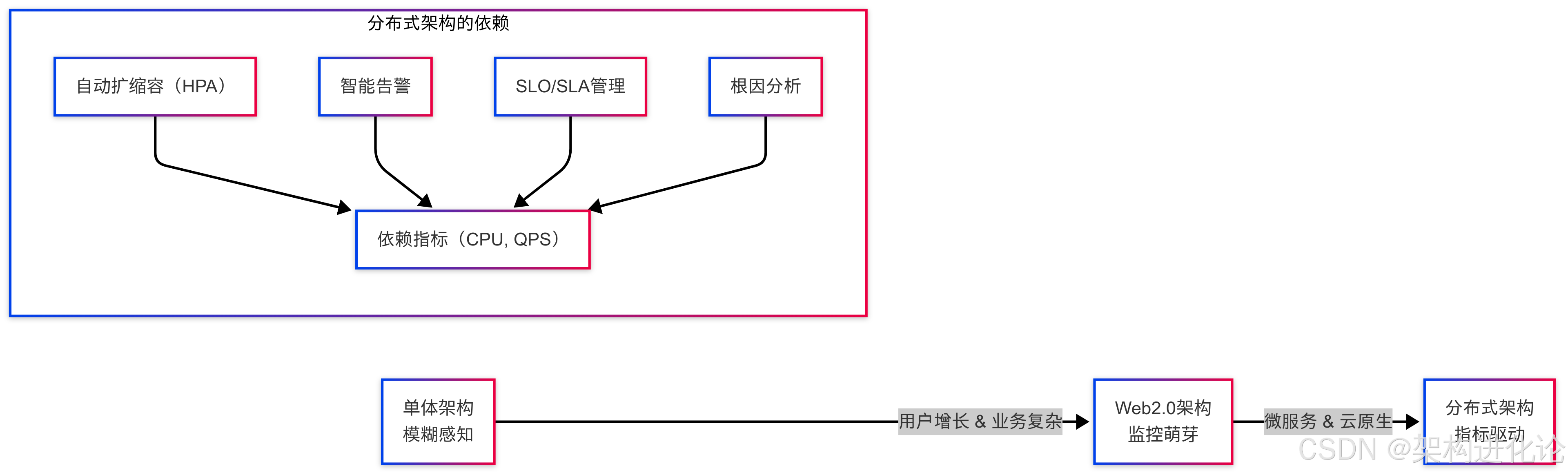
结论:技术的演进,从单体到分布式,使得系统的内在复杂性呈指数级增长。在这种环境下,依靠人的经验和模糊的定性描述来管理和运维系统是完全不可能的。量化指标成为了我们理解、掌控和管理这个复杂分布式系统的“仪表盘”和“神经中枢”,它使得自动化、智能化的运维成为可能。
生活化案例——从咖啡店到“双十一”
为了让这个概念更加通俗易懂,我们类比一个生活场景:经营一家咖啡店。
-
功能性需求 vs. 非功能性需求:
-
功能性需求:这家店要能制作咖啡、收银。这是核心业务,是“做什么”。
-
非功能性需求:制作咖啡的速度、一天能接待的顾客总量、服务的态度(可靠性)、在高峰期排长队时能否快速扩展人手。这是“做得如何”。
-
-
需求的三个层次演进:
-
定性描述:“我们店的出餐速度要快。” -> 这相当于“系统要支持并发登录”。多快?无法衡量。
-
带测量的定量描述:“我们店每分钟要能做出10杯咖啡。” -> 这相当于“系统要支持10000用户并发登录”。有了数字目标。但如果为了追求速度,咖啡师把咖啡做糊了或者忘了加糖,虽然数量达到了,但质量不合格。
-
带测量与指标的定量描述:“我们店每分钟要能做出10杯咖啡,且顾客满意度达到99%,平均出餐时间在2分钟以内。” -> 这才是完整的、健康运营的目标。这里的“顾客满意度”和“出餐时间”就是核心指标。
-
-
技术架构的映射:
-
单体时代:夫妻店,老板兼咖啡师和收银员。所有流程都在一个人身上,出了问题很容易找到原因(今天状态不好)。
-
Web 2.0时代:小店扩张,雇了专门的收银员、咖啡师和打包员。这时需要分工协作(负载均衡)。如果排队还是很长,你需要知道瓶颈在哪:是收银员操作太慢?还是咖啡机只有一台?此时,你需要开始“监控”每个环节的耗时(指标)。
-
云原生时代:你开了连锁品牌(星巴克模式)。你有中央厨房(后端微服务)、区域配送中心(消息队列)、和众多门店(网关/前端)。为了应对“双十一”这样的促销日(流量洪峰),你需要根据各门店的实时销售数据(指标)来动态调整中央厨房的生产和配送计划(自动伸缩)。任何一个环节(比如奶泡机坏了)的指标异常,都会触发总部的告警系统,以便迅速调度资源解决。
-
这个案例清晰地表明,没有精确的指标,就无法实现高效的运营和卓越的客户体验,无论是在咖啡店还是在软件系统里。
代码与实践——从理念到实现
让我们通过具体的代码示例,来看一看指标是如何被采集、暴露和使用的。
使用Micrometer采集JVM应用指标
Micrometer是一个流行的指标采集门面库,类似于SLF4J之于日志。它允许你使用统一的API,然后将指标数据发送到不同的监控后端,如Prometheus, Datadog等。
import io.micrometer.core.instrument.Counter;
import io.micrometer.core.instrument.MeterRegistry;
import io.micrometer.core.instrument.Timer;
import org.springframework.stereotype.Component;import java.util.concurrent.TimeUnit;@Component
public class LoginService {// 定义指标private final Counter loginAttemptsCounter;private final Counter loginSuccessCounter;private final Counter loginFailureCounter;private final Timer loginDurationTimer;/*** 构造函数,通过MeterRegistry注册指标* @param registry 指标注册中心(由Spring或其它DI框架自动注入)*/public LoginService(MeterRegistry registry) {// 计数器:记录登录尝试总次数loginAttemptsCounter = Counter.builder("login.attempts").description("Total number of login attempts").register(registry);// 计数器:记录登录成功次数loginSuccessCounter = Counter.builder("login.successes").description("Total number of successful logins").tag("status", "success") // 使用标签区分状态,是Prometheus等系统的推荐做法.register(registry);// 计数器:记录登录失败次数loginFailureCounter = Counter.builder("login.failures").description("Total number of failed logins").tag("status", "failure").register(registry);// 计时器:记录登录操作的耗时分布loginDurationTimer = Timer.builder("login.duration").description("Time taken for login process").register(registry);}/*** 模拟登录业务方法* @param username 用户名* @param password 密码* @return 登录是否成功*/public boolean login(String username, String password) {// 1. 记录一次登录尝试loginAttemptsCounter.increment();// 2. 使用计时器记录整个登录过程的执行时间return loginDurationTimer.record(() -> {try {// 模拟业务逻辑处理耗时Thread.sleep((long) (Math.random() * 100));// 模拟登录验证(这里简化了,实际是数据库查询等)boolean isSuccess = isValidCredentials(username, password);// 3. 根据结果记录成功或失败计数器if (isSuccess) {loginSuccessCounter.increment();} else {loginFailureCounter.increment();}return isSuccess;} catch (InterruptedException e) {loginFailureCounter.increment();Thread.currentThread().interrupt();return false;}});}private boolean isValidCredentials(String username, String password) {// 简化的验证逻辑,实际中应查询数据库或调用认证服务return "admin".equals(username) && "123456".equals(password);}
}代码解读:
-
计数器(Counter):用于记录只会增加的数值,如请求次数、成功/失败次数。我们可以通过
login_successes_total / login_attempts_total来计算登录成功率。 -
计时器(Timer):用于记录耗时操作的持续时间,它会同时统计次数、总耗时,并计算平均值、最大值以及分位数(如P95, P99)等。这对于评估性能(如“平均响应时间低于100ms”)至关重要。
-
标签(Tag/Label):为指标添加维度信息。例如,我们可以为失败计数器添加一个
reason="wrong_password"或reason="user_locked"的标签,以便更精细地分析失败原因。
使用Prometheus和Grafana构建监控可视化
采集到的指标需要被收集、存储和展示。
-
暴露指标:Spring Boot Actuator集成了Micrometer,可以通过
/actuator/prometheus端点以Prometheus格式暴露指标。 -
抓取与存储:Prometheus服务器会定期来抓取这个端点的数据,并存入其时间序列数据库。
-
可视化与告警:Grafana连接Prometheus数据源,可以绘制出丰富的仪表盘。
示例PromQL查询(在Grafana中使用):
# 计算最近5分钟的登录成功率
rate(login_successes_total[5m]) / rate(login_attempts_total[5m]) * 100# 计算登录耗时的95分位数
histogram_quantile(0.95, rate(login_duration_seconds_bucket[5m]))通过这些查询,我们可以在Grafana仪表盘上实时看到两条曲线:登录成功率和P95响应时间。一旦成功率低于99.9%或P95响应时间超过100ms,Grafana就可以触发告警通知到我们的钉钉/Slack/邮件。
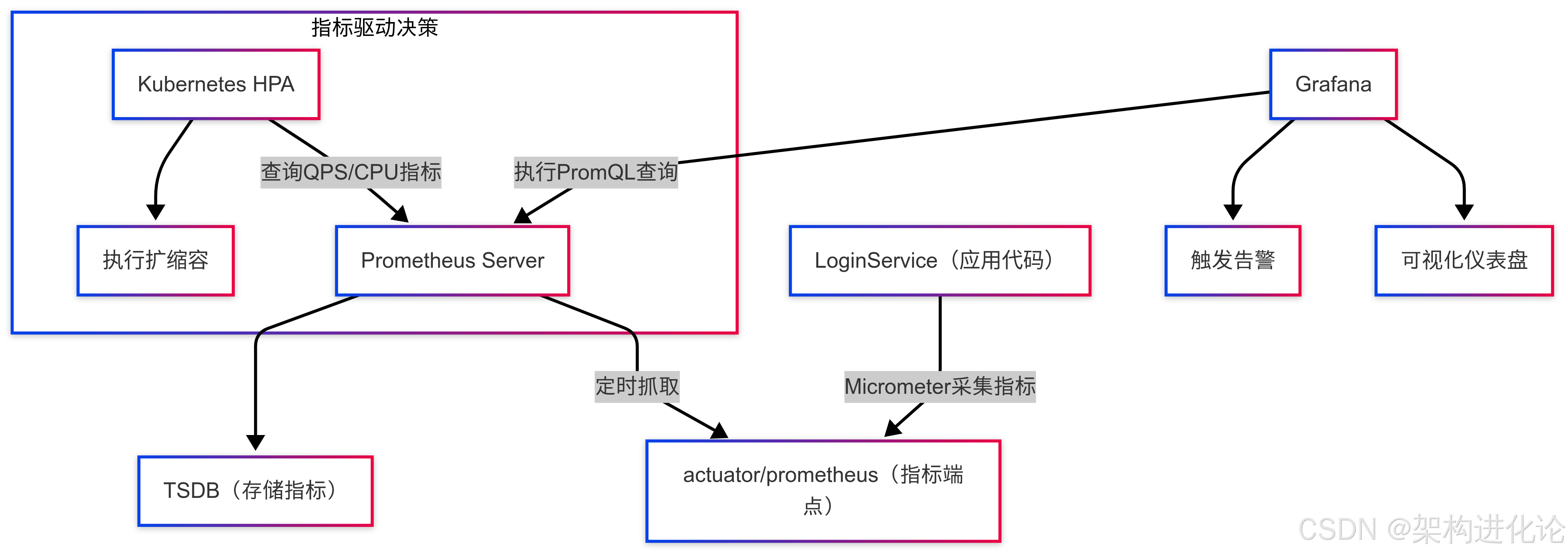
这个完整的链条展示了指标如何从一个抽象的非功能性需求(“要高成功率、要低延迟”),转化为代码中的埋点,最终成为运维人员屏幕上直观的、可行动的图表和告警。整个现代互联网的运维体系,就是构建在这样的指标驱动闭环之上的。
结论
指标之所以更多地用于非功能性需求,其根本原因在于二者本质上的契合:非功能性需求是关于质量和程度的,而指标是度量它们唯一科学的标尺。
我们从需求的演进过程看到,从模糊的定性描述到精确的“测量+指标”描述,是软件工程从作坊走向工业化、从艺术走向科学的必然路径。技术的演进,尤其是分布式微服务架构的普及,将系统的复杂性提升到了一个全新的高度,使得依靠指标进行精细化、自动化运维不再是“锦上添花”,而是“生死攸关”。
通过生活化的案例和具体的代码实践,我们揭示了指标如何贯穿于从需求定义、架构设计、代码开发到线上运维的整个软件生命周期。它就像人体的神经系统,不断感知系统的健康状况,并将信息传递到大脑(运维/研发团队),以便做出及时、正确的决策。
因此,作为一名专业的架构师,在项目伊始就应致力于将非功能性需求转化为可量化的指标,并将其视为与功能性需求同等重要、甚至在某些场景下更为重要的部分。因为一个功能完备但性能低下、频繁宕机的系统,在当今时代几乎没有商业价值。拥抱指标,就是拥抱确定性、可观测性和工程卓越性。